Important thing to say: every word is knocked by pickup hand. I hope you can read and understand pickup's thoughts when writing a blog word by word. I hope you have something to gain, thank you!
This is the first article about redis, because redis plays an important role in our work. Later, I will write about the persistence of redis, the master-slave architecture, the sentinel mode, the cluster mode, the core principle of redis, the cache design and performance optimization of redis, the new features of redis6, and the C source code of redis.
Today, let's talk about the five data structures of redis and the high-performance principle of single thread
Redis installation
redis Chinese official website address
Download address: http://redis.io/download Installation steps: # Install gcc yum install gcc # Download redis-5.0.3 tar. Gz in the / usr/local folder and unzip it wget http://download.redis.io/releases/redis-5.0.3.tar.gz tar xzf redis-5.0.3.tar.gz cd redis-5.0.3 # Enter the extracted redis-5.0.3 directory for compilation and installation make # Modify configuration daemonize yes #Background start protected-mode no #If the protection mode is turned off and turned on, only the local machine can access redis # bind needs to be commented out #bind 127.0.0.1 (bind is bound to the ip of the network card of the machine. If multiple network cards can be configured with multiple ip, it represents which network card ip of the machine the client is allowed to access. Bind can not be configured in the intranet. Just comment it out.) # Start service src/redis-server redis.conf # Verify that the startup was successful ps -ef | grep redis # Enter redis client src/redis-cli # Exit client quit # Exit redis service: (1)pkill redis-server (2)kill Process number (3)src/redis-cli shutdown
Core data structure and usage
String structure
String common operations
SET key value //Save string key value pair MSET key value [key value ...] //Batch store string key value pairs SETNX key value //Store a nonexistent string key value pair GET key //Gets a string key value MGET key [key ...] //Batch get string key values DEL key [key ...] //Delete a key EXPIRE key seconds //Set the expiration time of a key (seconds)
Atomic addition and subtraction
INCR key //Add 1 to the numeric value stored in the key DECR key //Subtract 1 from the numeric value stored in the key INCRBY key increment //Add increment to the value stored by key DECRBY key decrement //Subtract increment from the value stored in the key
Application scenario
String should be the most common data type used in our work. Some common commands are listed above. Let's take a look at their usage scenarios.
- Single value cache
SET key value GET key
This is the simplest way to save a string and get it
- Object cache
SET user:1 value(json Format data)
MSET user:1:name zhuge user:1:balance 1888
MGET user:1:name user:1:balance
If we want to store an object's data, we usually convert an object's data into json and store it in redis, and MSET is the command for batch storage. If there are many data objects that need io interaction with redis every time they are stored, then I can save them in batches with MSET.
- Distributed lock
SETNX product:10001 true //A return of 1 indicates that the lock was obtained successfully SETNX product:10001 true //A return of 0 indicates that the lock acquisition failed . . . Perform business operations DEL product:10001 //Release the lock after executing the service SET product:10001 true ex 10 nx //Prevent accidental program termination from causing deadlock
SETNX is the abbreviation of "SET if Not eXists".
It is used for distributed locks. If it can be saved successfully, it means that the lock has been obtained. If it fails to add the lock, it means that the lock has been occupied by others.
In fact, distributed locks are far from so simple. If only the data is saved and the expiration time is not set, if the program that obtains the lock is stuck, all subsequent businesses will not get the lock, resulting in system crash. If the expiration time is set, there will also be a problem when deleting the lock, that is, when the first thread is locked, the code execution time is relatively long, and the lock automatically expires, the second thread can be locked. After the second thread is locked, when the code execution of the first thread completes deleting the lock, the lock of the second thread will be deleted, Because the lock of the first thread has automatically expired and deleted, and so on. Later, I will talk about some problems that will occur and the current solutions of some large manufacturers for redis distributed locks.
- Counter
INCR article:readcount:{article id}
GET article:readcount:{article id}
When the reading number is displayed in the place shown in the figure below, each person only needs to click the article once to execute INCR operation and add 1

INCR increments the numeric value stored in the key by one. If the key does not exist, the value of the key will be initialized to 0 before performing the INCR operation. If the value contains the wrong type, or the value of string type cannot be expressed as a number, an error is returned. The value of this operation is limited to 64 bit signed digital representation. Note: This is a string operation. Because Redis does not have a special integer type, the string stored in the key is interpreted as a decimal 64 bit signed integer to perform INCR operation.
Scenario 1: counter
Counter is the most intuitive mode of Redis's atomic auto increment operation. Its idea is quite simple: send an INCR command to Redis whenever an operation occurs. For example, in a web application, if you want to know the daily hits of users in a year, just take the user ID and relevant date information as the key, and perform a self increment operation every time the user clicks the page. For example, if the user name is peter and the click time is March 22, 2012, execute the command INCR peter:: March 22, 2012
Scenario 2: speed limiter
A speed limiter is a specialized calculator that limits the rate at which an operation can be performed. The typical usage of the speed limiter is to limit the number of requests to expose the API. The following is an example of the implementation of the speed limiter, which limits the maximum number of API requests to ten per second for each IP address:
FUNCTION LIMIT_API_CALL(ip) ts = CURRENT_UNIX_TIME() keyname = ip+":"+ts current = GET(keyname) IF current != NULL AND current > 10 THEN ERROR "too many requests per second" END IF current == NULL THEN MULTI INCR(keyname, 1) EXPIRE(keyname, 1) EXEC ELSE INCR(keyname, 1) END PERFORM_API_CALL()
-
Web Cluster session sharing
spring session + redis realize session sharing -
Global serial number of distributed system
INCRBY orderId 1000 //redis batch generates serial numbers to improve performance
Such a scenario can be used to generate self incrementing IDs and use them in the database.
Format: incrby key increment adds increment to the value stored by the key. If the key does not exist, the value of the key will be initialized to 0 before executing the INCRBY command. If the value contains the wrong type, or the value of string type cannot be expressed as a number, an error is returned. The value of this operation is limited to 64 bit signed digital representation.
Example code:
# key exists and is a numeric value redis> SET rank 50 OK redis> INCRBY rank 20 (integer) 70 redis> GET rank "70" # When key does not exist redis> EXISTS counter (integer) 0 redis> INCRBY counter 30 (integer) 30 redis> GET counter "30" # When key is not a numeric value redis> SET book "long long ago..." OK redis> INCRBY book 200 (error) ERR value is not an integer or out of range
Of course, there will also be disadvantages here, that is, if it is order data, if there are hundreds of millions of data IDs to be generated in an hour, using redis also consumes performance and memory. We can use snowflake algorithm and some open source leaf generators such as meituan.
Hash structure
Common operations of Hash
HSET key field value //Store the key value of a hash table key HSETNX key field value //Store the key value of a non-existent hash table key HMSET key field value [field value ...] //Store multiple key values in a hash table key for batch operation HGET key field //Get the field key value corresponding to the hash table key HMGET key field [field ...] //Batch obtain multiple field key values in hash table key HDEL key field [field ...] //Delete the field key value in the hash table key HLEN key //Returns the number of field s in the hash table key HGETALL key //Returns all key values in the hash table key HINCRBY key field increment //Add increment to the value of the field key in the hash table key
In fact, Hash is to maintain an array, and then there may be many linked lists on this array to store data.
Hash application scenario
- Object cache
HMSET user {userId}:name zhuge {userId}:balance 1888
HMSET user 1:name zhuge 1:balance 1888
HMGET user 1:name 1:balance
A hash operation can be regarded as a database table and a user table. If you want to store user information, you only need to store it in the user slot, that is, the user table, according to the user id.

Such storage can save costs and storage space, but everything has advantages and disadvantages. If data is stored in this way, it will form the BigKey problem that Redis can't accept, which will greatly affect the performance. What is the solution? We can consider using cluster mode partitioned storage. The usage of 16384 slot partitioned storage will be described later.
- E-commerce shopping cart
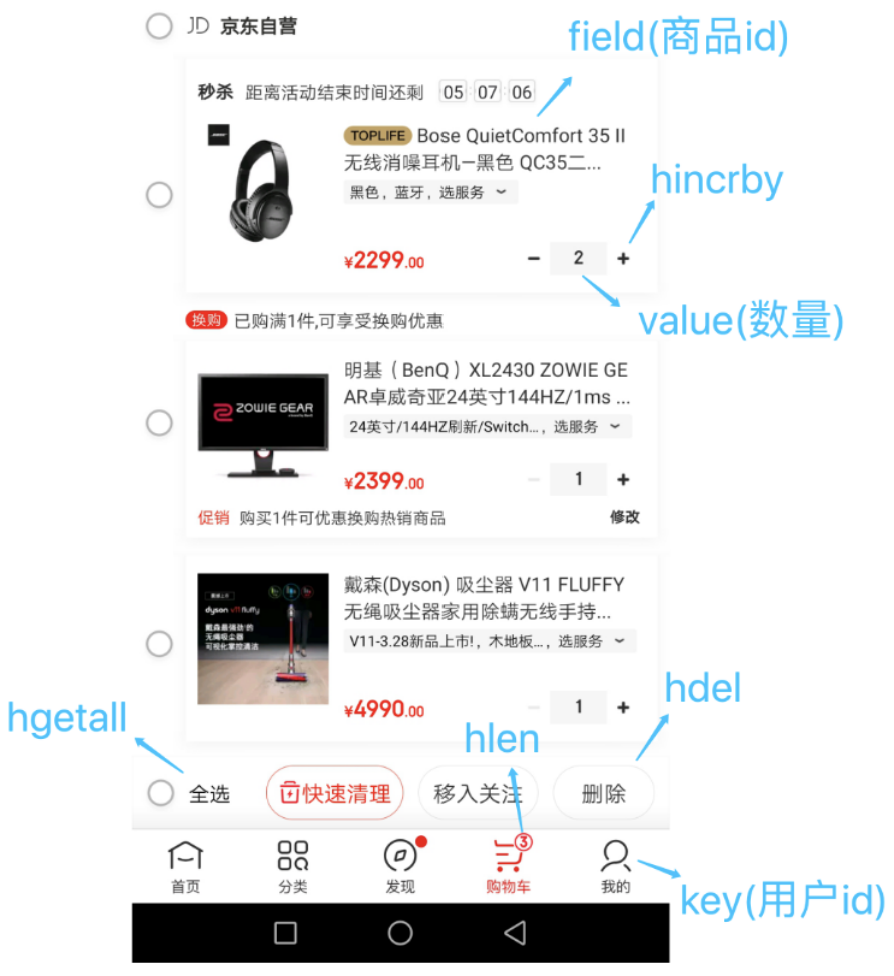
1)To user id by key 2)commodity id by field 3)The quantity of goods is value
- Shopping cart operation
Add item: hset cart:1001 10088 1 Increase quantity: hincrby cart:1001 10088 1 Total number of goods: hlen cart:1001 Delete item: hdel cart:1001 10088 Get all items in the shopping cart: hgetall cart:1001
I think using Hash to store shopping cart data is a better choice than String. I will write about the principle of redis's own internal sub packaged data structure in the later stage.
Advantages and disadvantages of Hash structure
- advantage
1)Similar data are classified, integrated and stored to facilitate data management 2)comparison string Operation consumes memory and cpu Smaller 3)comparison string More space saving storage
- shortcoming
1)Expiration function cannot be used in field It can only be used in key upper 2)Redis Cluster architecture is not suitable for large-scale use
List structure
List is no stranger to programmers. Its bottom layer is actually an array maintained.
List common operations

LPUSH key value [value ...] //Insert one or more values value into the header (leftmost) of the key list RPUSH key value [value ...] //Insert one or more values value at the end of the key list (rightmost) LPOP key //Removes and returns the header element of the key list RPOP key //Removes and returns the last element of the key list LRANGE key start stop //Returns the elements within the specified interval in the list key. The interval is specified by offset start and stop BLPOP key [key ...] timeout //Pop up an element from the header of the key list. If there is no element in the list, block and wait Timeout seconds. If timeout=0, it will block and wait all the time BRPOP key [key ...] timeout //Pop up an element from the end of the key list. If there is no element in the list, block and wait Timeout seconds. If timeout=0, it will block and wait all the time
List application scenario
- Common data structures
Stack(Stack) = LPUSH + LPOP
We know that the feature of stack is first in and last out, so we can use the feature of List to store data with LPUSH, so that the data is always increasing to the left, and we use LPOP to get data from the leftmost, so that the latest stored data can be taken out at the earliest. Similarly, using RPUSH+RPOP can also be used as the data structure of stack. Learning must be comprehensive
Queue(Queue)= LPUSH + RPOP
The queue is first in first out. Like our daily chasing girls, those who meet first and know first must have priority.
Blocking MQ(Blocking queue)= LPUSH + BRPOP
Pop up an element from the header of the key list. If there is no element in the list, wait for timeout seconds. If timeout=0, it will be blocked all the time. Just keep getting data and wait without data, which is similar to the spin acquisition data of our code.
- Microblog, wechat public account and wechat circle of friends message flow

- Microblog messages and wechat public account messages

Tiantian pays attention MacTalk,The spare wheel said the car was too big V
1)MacTalk Tweet, message ID 10018
LPUSH msg:{Sweet-ID} 10018
2)The spare tire said that the car sent microblogs and messages ID Is 10086
LPUSH msg:{Sweet-ID} 10086
3)View the latest microblog messages
LRANGE msg:{Sweet-ID} 0 4
This means that the V you are concerned about has published articles. When you open the official account, you will get the latest released data. Sometimes you may default to the latest two, so you can get paging data with LRANGE key start stop.
Set structure
I think the biggest function of Set is to take intersection, union and so on.... Let's be specific
Set common operations
SADD key member [member ...] //Store elements into the set key, and ignore them if they exist, if key New if none exists SREM key member [member ...] //Delete element from set key SMEMBERS key //Get all elements in the set key SCARD key //Gets the number of elements of the set key SISMEMBER key member //Judge whether the member element exists in the set key SRANDMEMBER key [count] //Select count elements from the set key, and the elements will not be deleted from the key SPOP key [count] //Select count elements from the set key, and delete the elements from the key
Set operation
SINTER key [key ...] //Intersection operation SINTERSTORE destination key [key ..] //Store the intersection results in the new set destination SUNION key [key ..] //Union operation SUNIONSTORE destination key [key ...] //Store the union result in the new set destination SDIFF key [key ...] //Difference set operation SDIFFSTORE destination key [key ...] //Save the difference set result into the new set destination
Set application scenario
- Wechat lottery applet

1)Click to participate in the lottery to join the collection
SADD key {userlD}
2)View all users participating in the raffle
SMEMBERS key
3)extract count Winners
SRANDMEMBER key [count] / SPOP key [count]
It is emphasized here that count data can be extracted from SRANDMEMBER key [count] and SPOP key [count]. You can draw the first prize and the second prize in the lottery. You only need to modify the count value. Is it particularly convenient and simple to use redis? SPOP key [count] will delete the winner and can no longer participate in the lucky draw. SRANDMEMBER is the winner and can continue the lucky draw
- Wechat microblog likes, collections, labels

1) give the thumbs-up
SADD like:{news ID} {user ID}
2) Cancel like
SREM like:{news ID} {user ID}
3) Check whether the user likes it
SISMEMBER like:{news ID} {user ID}
4) Get the list of users who like
SMEMBERS like:{news ID}
5) Number of users getting likes
SCARD like:{news ID}
There is nothing to explain in this place. The code should be understandable. Play advanced below
- Collection operation

SINTER set1 set2 set3 --> { c } intersect
SUNION set1 set2 set3 --> { a,b,c,d,e } De fetch Union
SDIFF set1 set2 set3 --> { a } Taking the difference between the first set and other sets can also be regarded as a unique element in the first set. Nonexistent collection key Treat as an empty set.
- Collection operation to realize microblog and wechat attention model
This is the common people we may know, common friends, etc
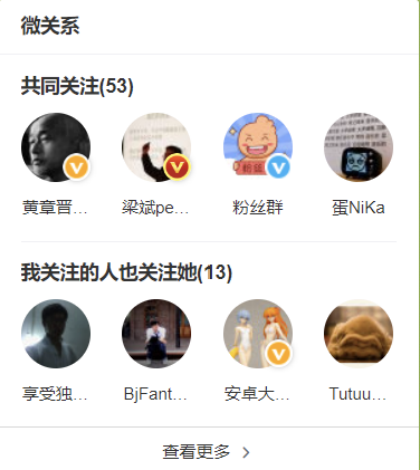

1) People who pay attention:
shiguangSet-> {bingan, xushu}
2) Sweet attention:
tiantianSet--> {shiguang, baiqi, bingan, xushu}
3) People concerned about biscuits:
binganSet-> {shiguang, tiantian, baiqi, xushu, xunyu)
4) Both Shiguang and Tiantian are concerned:
SINTER shiguangSet tiantianSet--> {bingan, xushu}
5) The people I care about also care about him(Sweet):
SISMEMBER binganSet tiantian
SISMEMBER xushuSet tiantian
6) Someone I might know:
SDIFF tiantianSet shiguangSet->(shiguang, baiqi}
ZSet ordered set structure
ZSet common operations
ZADD key score member [[score member]...] //Add elements with scores to the ordered set key ZREM key member [member ...] //Delete element from ordered set key ZSCORE key member //Returns the score of the element member in the ordered set key ZINCRBY key increment member //Add increment to the score of the element member in the ordered set key ZCARD key //Returns the number of elements in the ordered set key ZRANGE key start stop [WITHSCORES] //Obtain the elements of the ordered set key from the start subscript to the stop subscript in positive order ZREVRANGE key start stop [WITHSCORES] //Get the elements of the ordered set key from the start subscript to the stop subscript in reverse order
Zset set operation
ZUNIONSTORE destkey numkeys key [key ...] //Union calculation ZINTERSTORE destkey numkeys key [key ...] //Intersection calculation
Zset application scenario
- Zset set operation implementation Leaderboard

1)Click news ZINCRBY hotNews:20190819 1 Guard Hong Kong 2)Top ten on display day ZREVRANGE hotNews:20190819 0 9 WITHSCORES 3)Seven day search list calculation ZUNIONSTORE hotNews:20190813-20190819 7 hotNews:20190813 hotNews:20190814... hotNews:20190819 4)Show the top ten in seven days ZREVRANGE hotNews:20190813-20190819 0 9 WITHSCORES
Redis's single thread and high performance
- Is Redis single threaded?
The single thread of Redis mainly means that the network IO and key value pair reading and writing of Redis are completed by one thread, which is also the main process of Redis providing external key value storage services. However, other Redis functions, such as persistence, asynchronous deletion and cluster data synchronization, are actually executed by additional threads. - Why can Redis single thread be so fast?
Because all its data is in memory, all operations are memory level operations, and single thread avoids the loss of multi-threaded switching performance. Because Redis is a single thread, Redis instructions should be used carefully. For those time-consuming instructions (such as keys), be careful. If you are not careful, Redis may get stuck. - How does Redis single thread handle so many concurrent client connections?
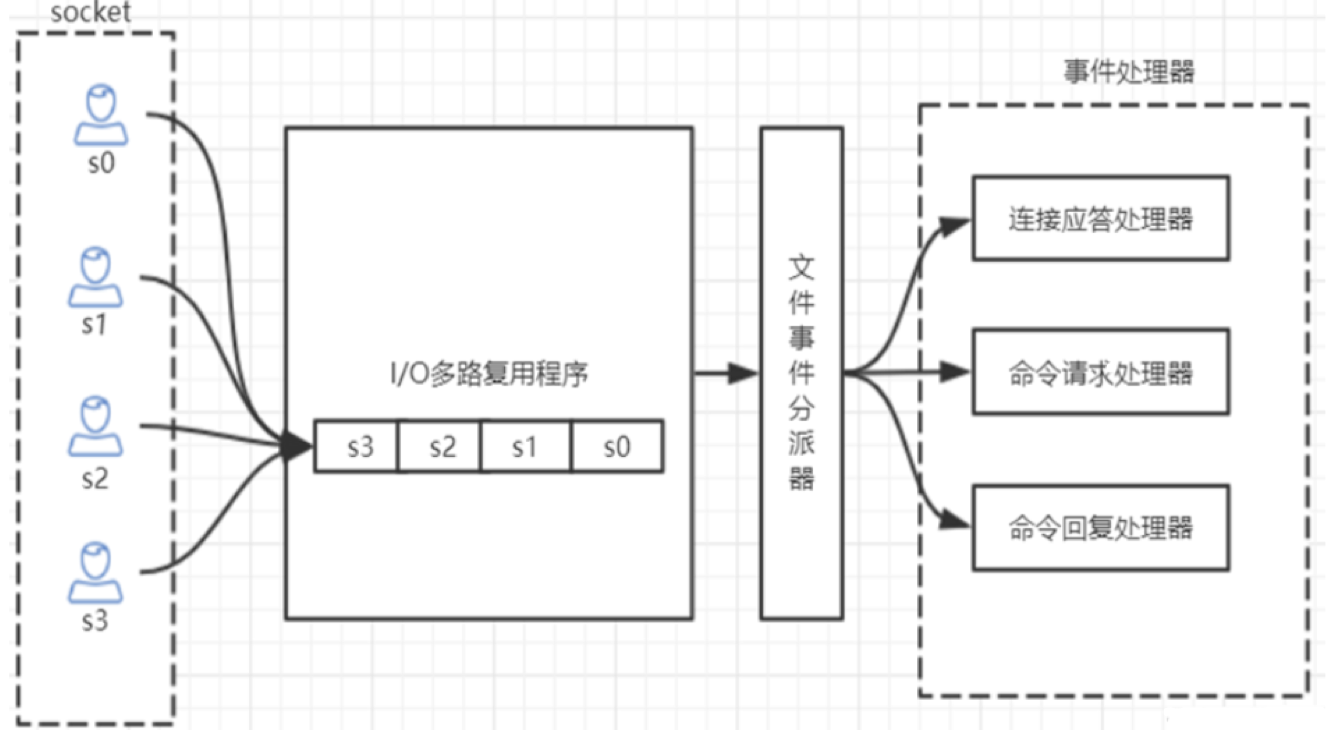
Redis's IO multiplexing: redis uses epoll to realize IO multiplexing. It puts connection information and events into the queue and then into the file event dispatcher. The event dispatcher distributes events to the event processor.
Later, if I have a chance, I will write Netty's multiplexing and eopll model separately
Welcome to read. If you have any questions, please put forward them in time. We will make progress and grow together!