This chapter is a practical project. Don't introduce too much. Direct start project description:
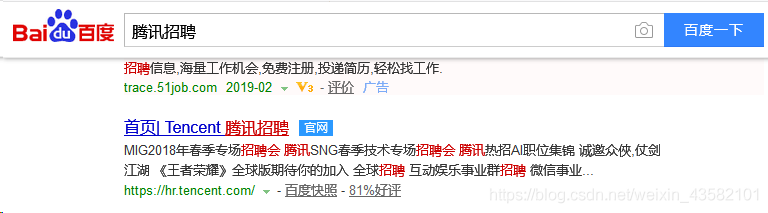
After entering the official website
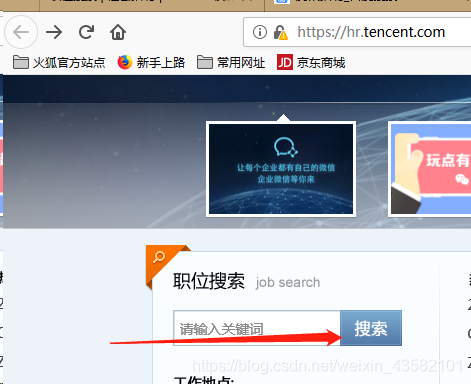
You can see the address
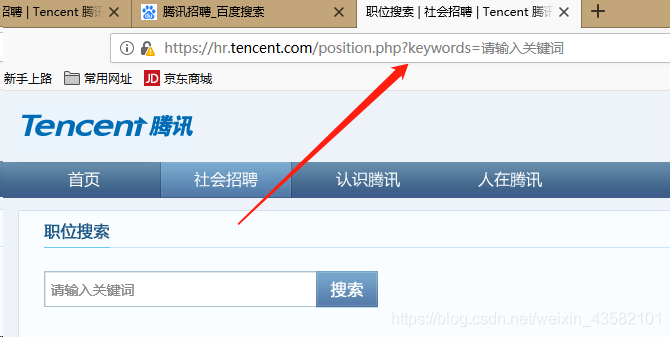
Since the address we need is

To create a Scrapy project:
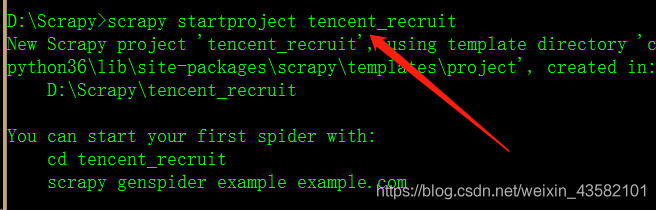
In Tecent_ Find the spiders folder under the recruit folder, Open the cmd window here and enter the command: scratch genspider catch_ positon tencent.com Create a crawler file named "catch_positon"

Clear climb target We open the "tencent_recruit" project just created in pycharm. Locate the items.py file
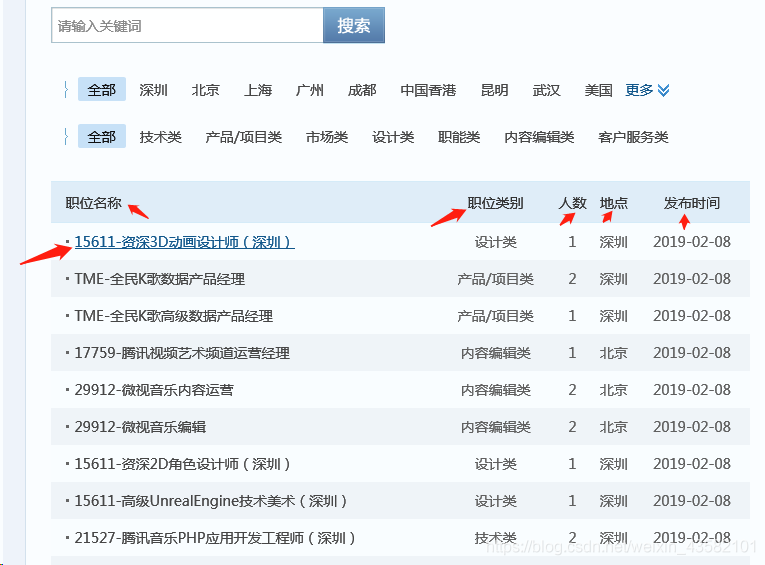
According to the target web page, we determine the crawling target as
- "Position name"
- "Position details connection"
- "Position type"
- "Number of recruits"
- "Place of work"
- Publish on.
Accordingly, we write“ items.py ”Determine the climb target.
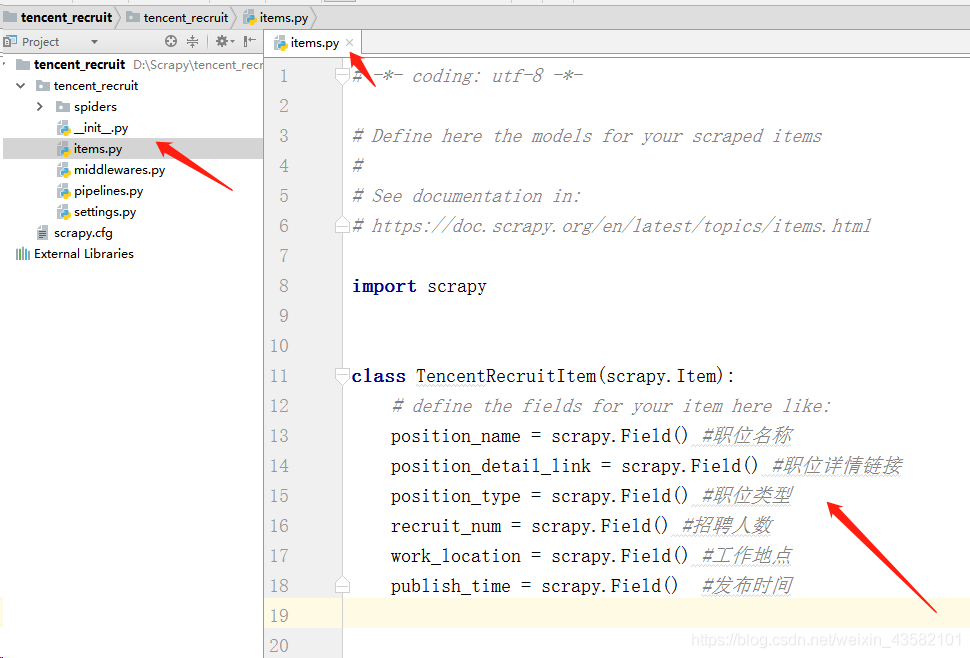
import scrapy
class TencentRecruitItem(scrapy.Item):
# define the fields for your item here like:
position_name = scrapy.Field() #Job title
position_detail_link = scrapy.Field() #Job details link
position_type = scrapy.Field() #Position type
recruit_num = scrapy.Field() #Number of recruits
work_location = scrapy.Field() #Duty station
publish_time = scrapy.Field() #Release timeWriting crawler files
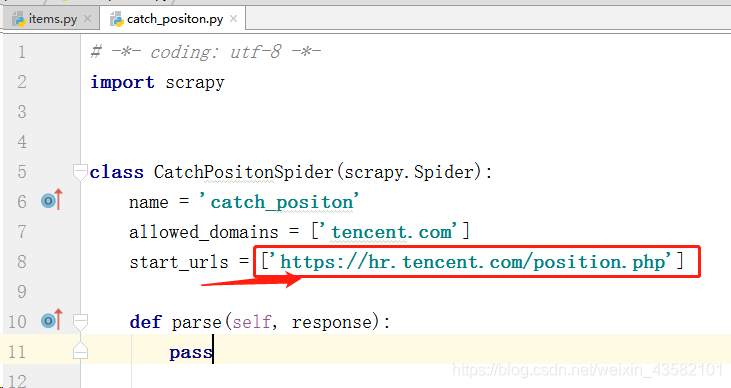
Double click the "catch_position. Py" we created to write the crawler file.
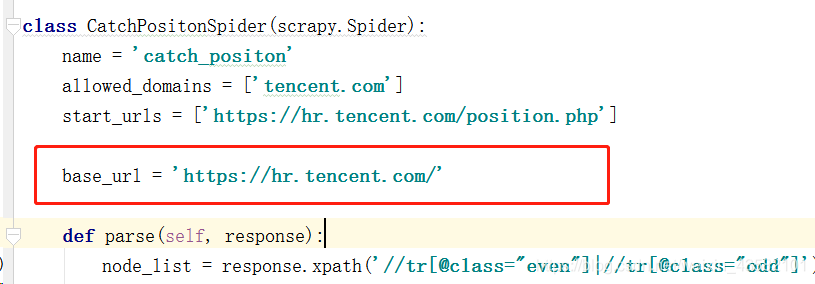
First, change the "start_urls" field value to our target web address.
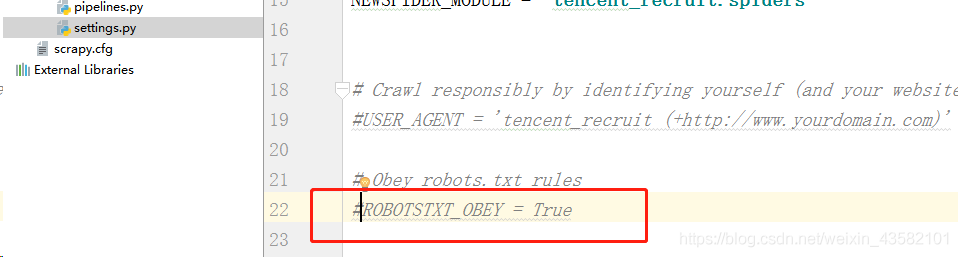
"In" settings.py "Add" # "before the" ROBOTSTXT_OBEY "protocol in line 22 (line 22 in pycharm, and the number of lines may be different in different editors).
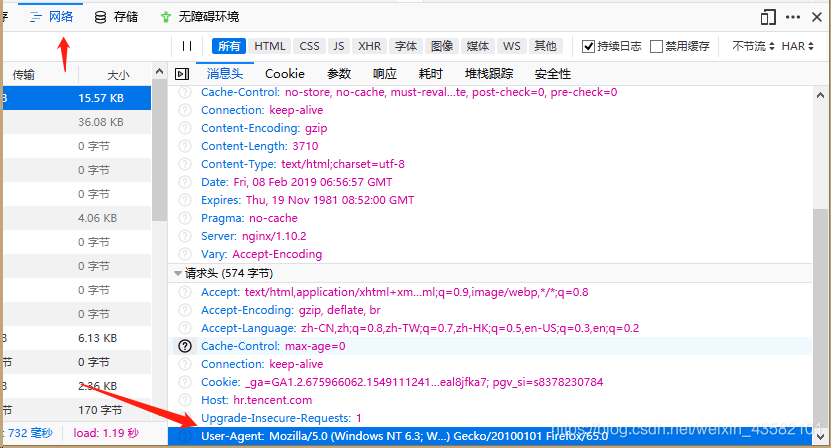
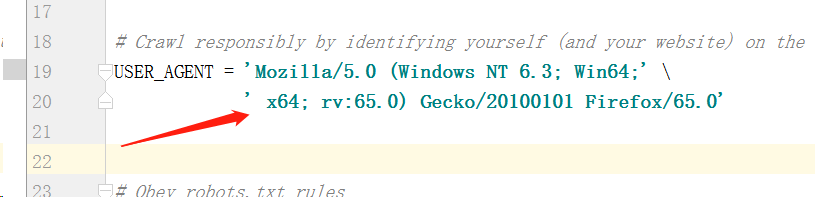
Remove the "#" comment before "USER_AGENT" in line 19 (line 19 in pycharm, and the number of lines may be different in different editors), and change its value to the value seen in F12 in the browser.
Then write our crawler file catch_positon.py
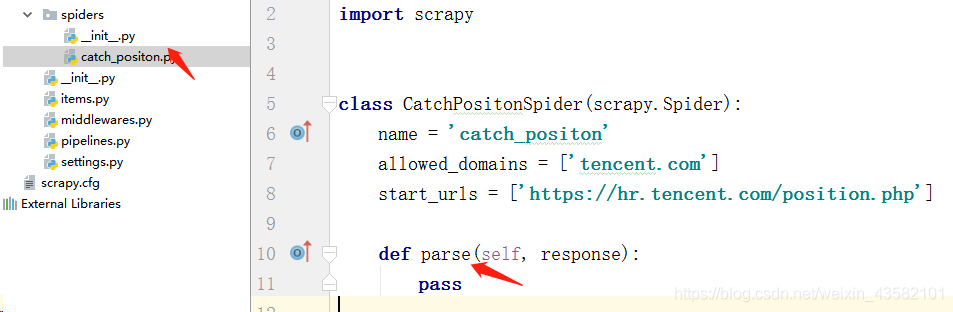
Change the content of parse to:
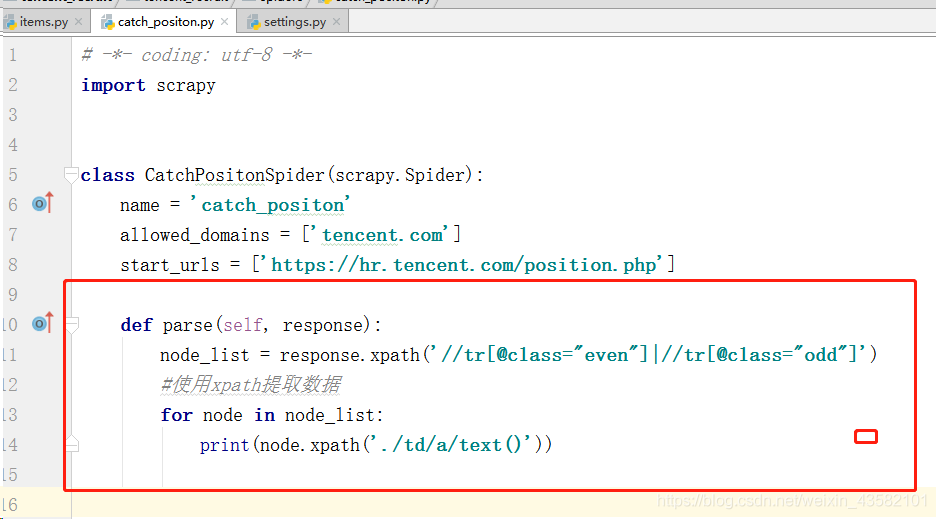
def parse(self, response):
node_list = response.xpath('//tr[@class="even"]|//tr[@class="odd"]')
#Extracting data using xpath
for node in node_list:
print(node.xpath('./td/a/text()'))Enter: scratch crawl catch_position on the cmd command line to run the crawler for testing.

It can be seen that there is only one data in each row of the extracted data list, so we use "extract_first()" to take the first element.
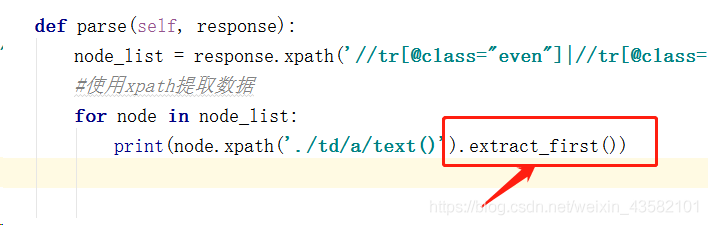
Note: "extract()[0]" and "extract_first()" can get the first element. Once there is no data, "extract()[0]" will report an error. The small mark range overflow will terminate the program, while "extract_first()" will directly return "null" to indicate a null value and will not interrupt the program. Therefore, we often use "extract_first()" when getting the first element.
We import the items class
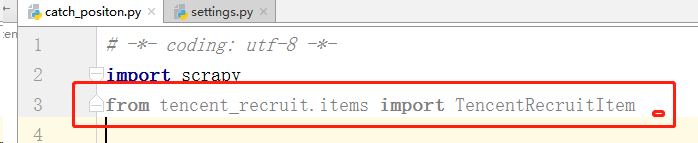
Instantiate the item class and assign the corresponding data to the corresponding item.

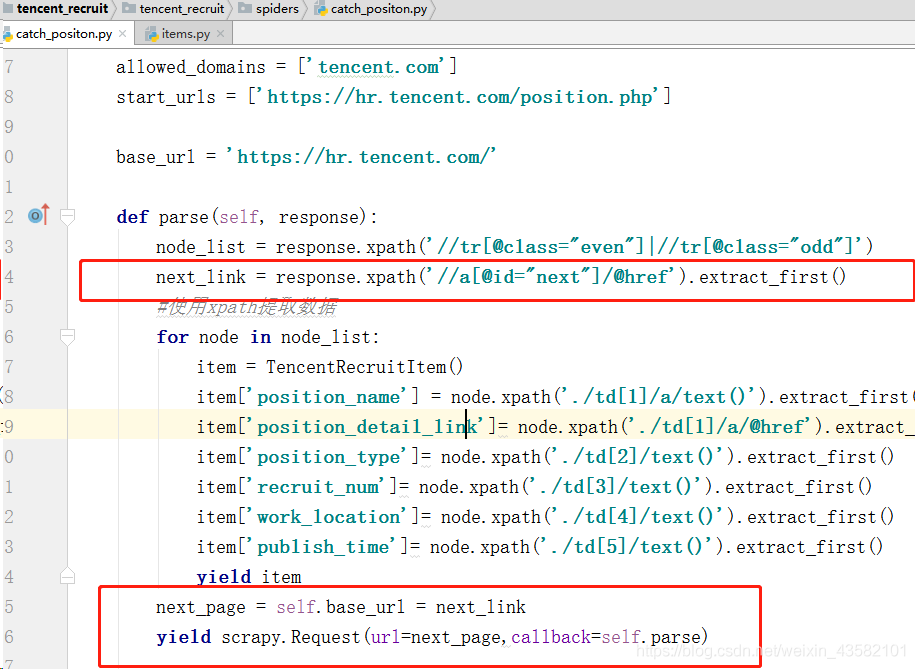
def parse(self, response):
node_list = response.xpath('//tr[@class="even"]|//tr[@class="odd"]')
#Extracting data using xpath
for node in node_list:
item = TencentRecruitItem()
item['position_name'] = node.xpath('./td[1]/a/text()').extract_first()
item['position_detail_link']= node.xpath('./td[1]/a/@href').extract_first()
item['position_type']= node.xpath('./td[2]/text()').extract_first()
item['recruit_num']= node.xpath('./td[3]/text()').extract_first()
item['work_location']= node.xpath('./td[4]/text()').extract_first()
item['publish_time']= node.xpath('./td[5]/text()').extract_first()
yield itemWe have successfully extracted the data on the first page of "Tencent Recruitment". Next, let's analyze the web page and crawl all the recruitment information. Press F12, click Select element and select "next page", you can see the corresponding web page code automatically located by the browser for us.
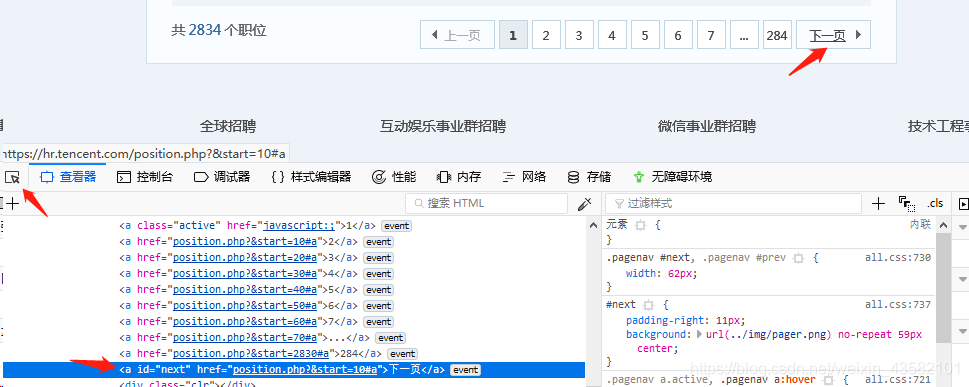
We click the corresponding a tag link in the code and find that we directly come to the second page. According to this law, we can get the idea of crawling all recruitment information
Write pipeline files and store data Double click“ pipelines.py ", enter the pipeline file and write it.
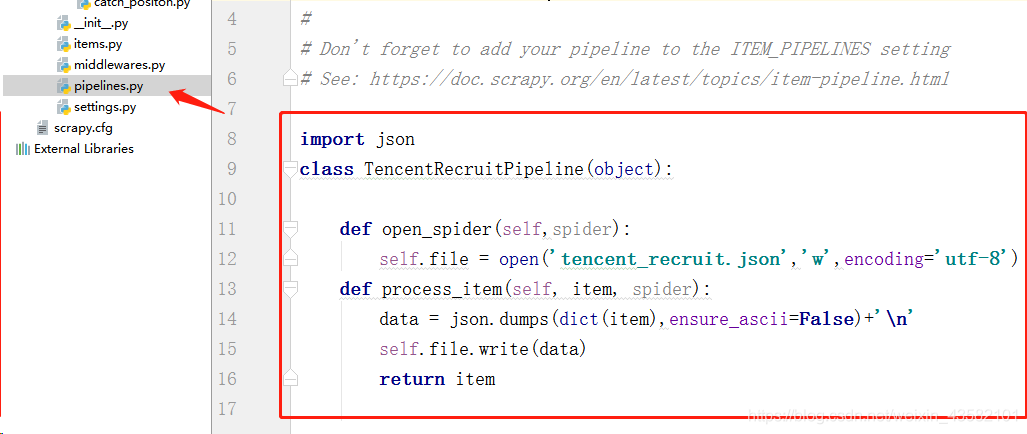
import json
class TencentRecruitPipeline(object):
def open_spider(self,spider):
self.file = open('tencent_recruit.json','w',encoding='utf-8')
def process_item(self, item, spider):
data = json.dumps(dict(item),ensure_ascii=False)+'\n'
self.file.write(data)
return itemDefine the close_spider function to close the file at the end of the crawler.
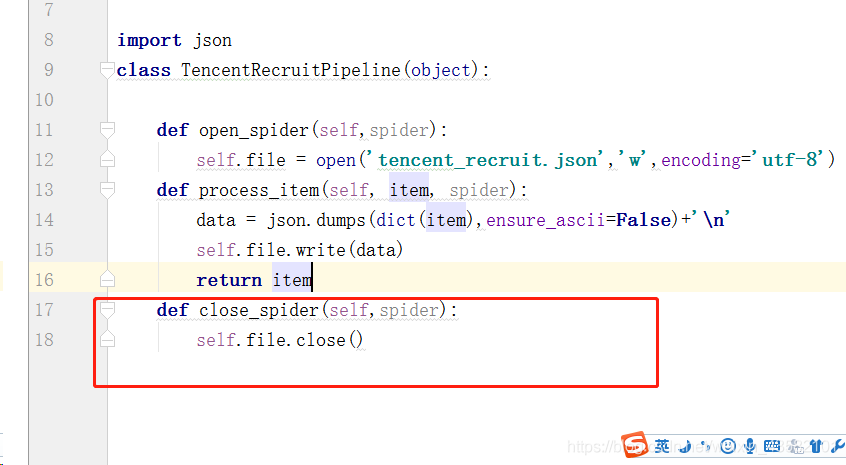
Finally, to“ settings.py "Register the pipeline in. Find line 69 (line 69 in pycharm, and the number of lines may be different in different editors). Remove the" # "comment in the corresponding part of" ITEM_PIPELINES ".

So far, run the crawler file. You can successfully obtain Tencent recruitment information.
