From easy to difficult, this article involves Ajax form data submission and md5 decryption There are three translation networks. What we want to achieve is to find the interface of translation and build our own translation software. First
Crawl Baidu translation:
Open Baidu translation to get our url
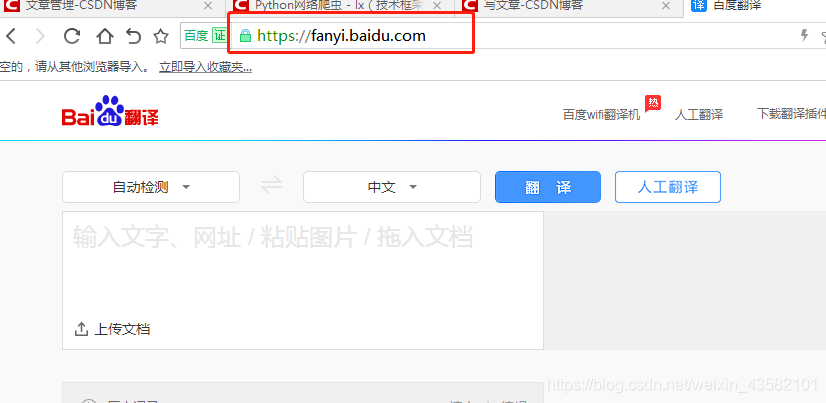
Let's first determine our url: After trying to find

The data is updated synchronously with our input
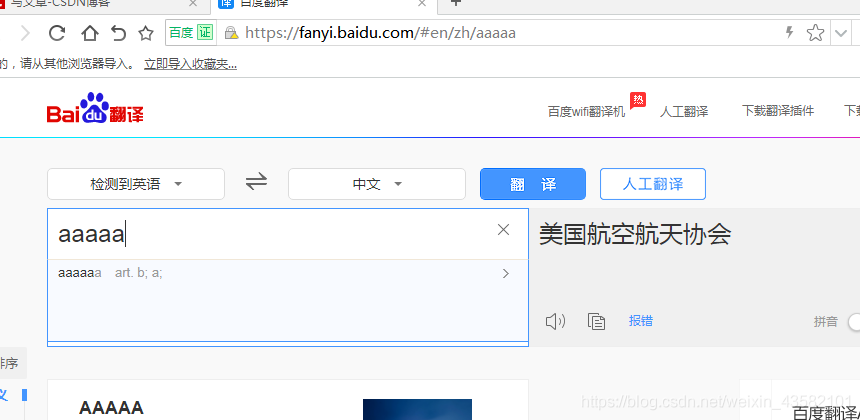
This search box is an ajax request form
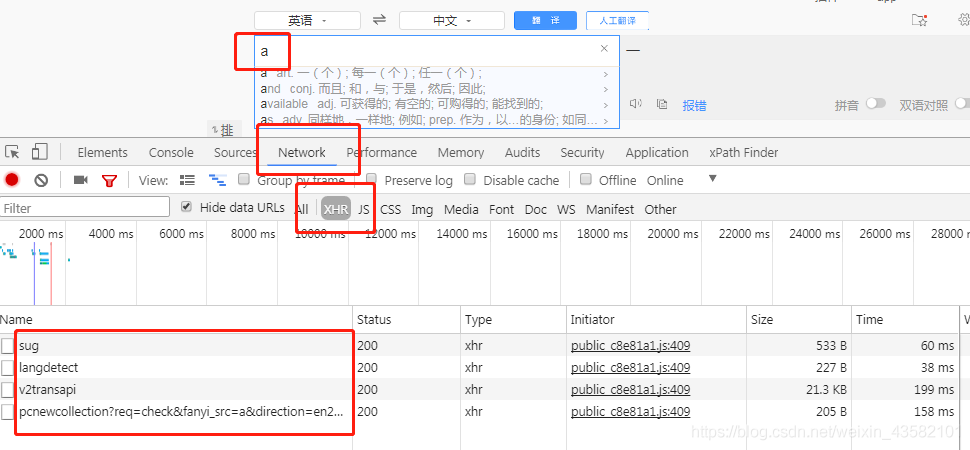
Let's open the network Found several (XHR) as shown in the figure, that is, XML httpresponse Open sug

It is found that there is a formData at the bottom of sug. The a inside is the a we entered in the box. To confirm, we changed the search value again.

This shows that the url of sug is the url we are looking for.

The discovery url is: https://fanyi.baidu.com/sug After determining our url, we start building our Request. When the interface is available, I will send the code directly.
from urllib import request,parse #Import urllib Library
import json #Import json
def translateall(word): #Define a function called translation
#Simulate browser settings request header
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64)"
" AppleWebKit/537.36 (KHTML, like Gecko)"
" Chrome/63.0.3239.132 Safari/537.36"
}
#The parameters in data are the parameters we want to pass in
data = {
'kw':word
}
data_str = parse.urlencode(data) #Convert and splice data with parse
url = 'https://fanyi.baidu.com/sug'
req = request.Request(url = url , headers= headers, data = bytes(data_str,encoding='utf-8')) #Construct request body
response = request.urlopen(req).read().decode('utf-8') #Request page information
# print(response)
obj = json.loads(response) #Decode the json format
# print(obj)
# print(obj['data'])
for item in obj['data']: #Then intercept the data we need
item = item['k']+item['v']
print("------------------------------------------------------------------------------")
print(item)
if __name__ == '__main__':
while True:
word = input("Please enter a word:")
translateall(word)

The case is simple. Next, let's climb down Kingsoft Ciba.
Climb Jinshan Ciba:
First, let's determine the url of the information page we want to get. Open Kingsoft Ciba web page. Kingsoft Ciba is very similar to Baidu translation. Let me make a long story short. Focus on the third item. Okay,

Observe page information

Open network
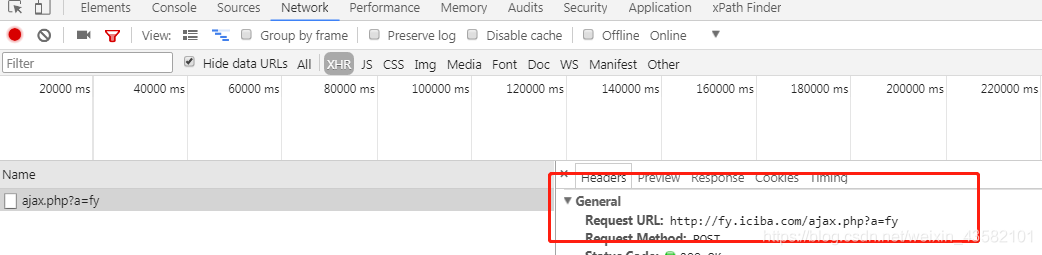
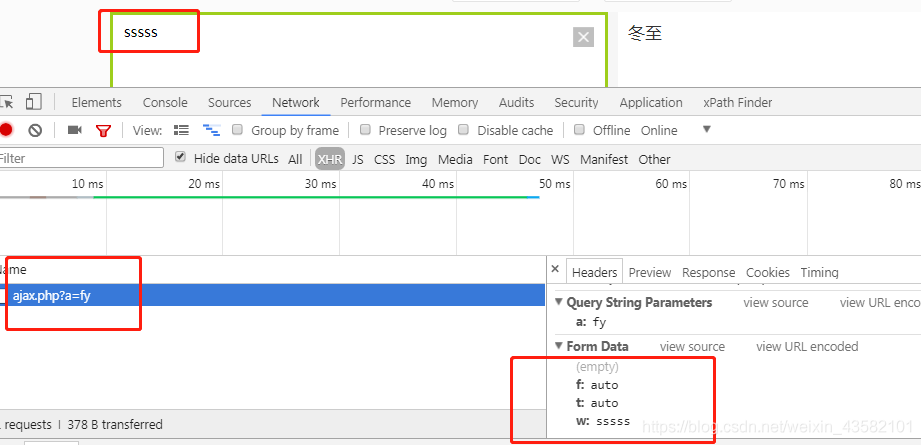
Interface url found. Send the code directly. This is too similar to the first one. The third case is the focus.
from urllib import request,parse
import json
class Translateall():
def __init__(self,word):
self.word = word
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64)"
" AppleWebKit/537.36 (KHTML, like Gecko)"
" Chrome/63.0.3239.132 Safari/537.36"
}
self.data = {
'f': 'auto',
'a': 'auto',
'w': word
}
def translateall(self):
data_str = parse.urlencode(self.data)
url = 'http://fy.iciba.com/ajax.php?a=fy'
req=request.Request(url =url,headers= self.headers,data= bytes(data_str,encoding='utf-8'))
response = request.urlopen(req).read().decode('utf-8')
obj = json.loads(response)
if obj['status']==0:
item = obj['content']['word_mean']
print(word,":",item)
elif obj['status'] ==1:
item = obj['content']['out']
print(word,":",item)
else:
return word
def run(self):
self.translateall()
if __name__ == '__main__':
while True:
print("----------------Welcome to Kingsoft Ciba------------------")
word = input("Please enter a word:")
trans=Translateall(word).run()Crawling Youdao Dictionary:
It's very difficult to get Youdao dictionary. Let me analyze step by step how to obtain the data we want. Open the official website.

To find our interface.

url found: We need to get the data through this url.


There is a lot of data in Formdata. By constantly inputting keywords, we can observe different data in formdata
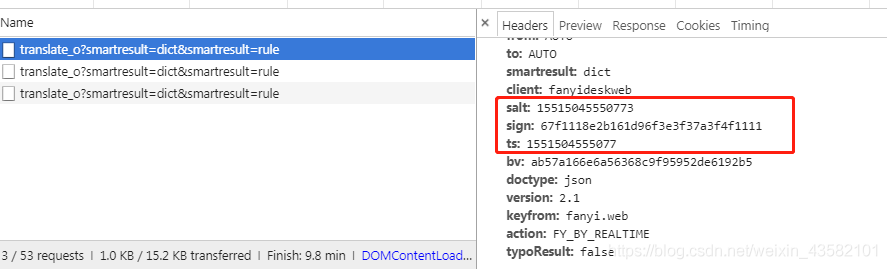
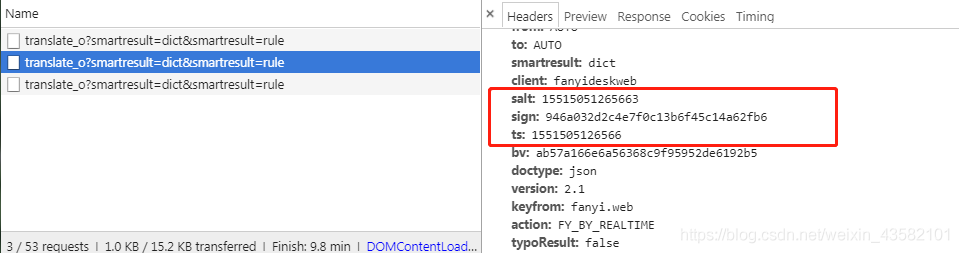
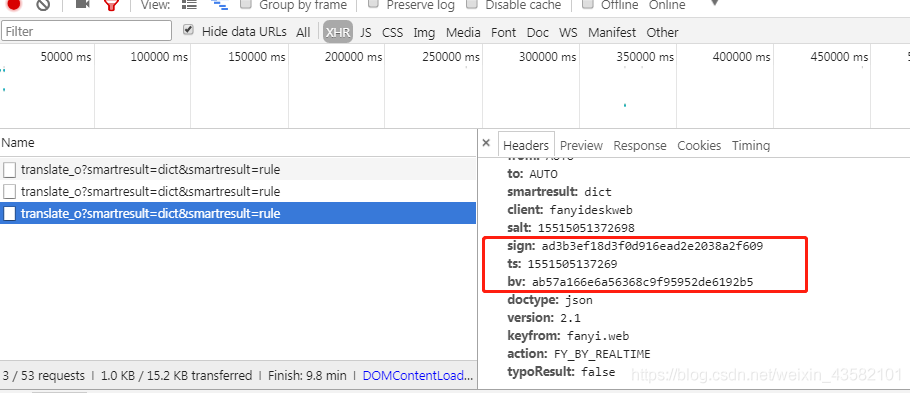
It is found that three of the data are changing all the time. If we want to construct data, we must know what these three pieces of information are. Don't panic. Don't worry when looking for rules. Extract the information separately.

Through observation, it is found that the ts of each column is very similar to its salt. Just one short.

Then the first number of salt in each column is the same. From experience, this is likely to be a timestamp. Let's print the current time.

Isn't it very similar

It seems to be a changed timestamp. Then our salt is: salt = int(time.time() *10000)
ts is one less than salt. ts is: ts= int(time.time() *1000)
There is another piece of data that we need to parse.

First of all, these three sign s seem to have nothing to do with each other except the same length. Let's lenth check the length and find that they are all 32 bits. This type of is very similar to the hash encryption in md5 so let's try. Construct a hash function. Let's write our code to try:
from urllib import request,parse
import hashlib,time,json
def getMD5(value):
aa = hashlib.md5()
aa.update(bytes(value,encoding="utf-8"))
sign = aa.hexdigest()
return sign
def fanyi():
salt = int(time.time() *10000)
ts = int(time.time() * 1000)
value = "fanyideskweb" + word + str(salt) + "p09@Bn{h02_BIEe]$P^nG"
url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
data= {
"i":word,
"from":"AUTO",
"to":"AUTO",
"smartresult":"dict",
"client":"fanyideskweb",
"salt":salt,
"sign":getMD5(value),
"ts":ts,
"bv":"5933be86204903bb334bf023bf3eb5ed",
"doctype":"json",
"version":"2.1",
"keyfrom":"fanyi.web",
"action":"FY_BY_REALTIME",
"typoResult":"false"
}
data_str = parse.urlencode(data)
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
# "Accept - Encoding":"gzip, deflate, br",
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': len(data_str),
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie': 'OUTFOX_SEARCH_USER_ID=42474381@10.168.1.241; JSESSIONID=aaawRmNTElH3Q4_wUlzKw; OUTFOX_SEARCH_USER_ID_NCOO=1959109122.590772; ___rl__test__cookies=1550905970008',
'Host': 'fanyi.youdao.com',
'Origin': 'http://fanyi.youdao.com',
'Referer': 'http://fanyi.youdao.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
req = request.Request(url=url,data=bytes(data_str,encoding='utf-8'),headers=headers)
content = request.urlopen(req).read().decode('utf-8')
content = json.loads(content)
try:
sss = content["translateResult"][0][0]
ddd = content["smartResult"]["entries"]
print(' ',sss["src"],":",sss["tgt"])
# print(' ',str(ddd).replace('\\r\\n','...').replace("\''",''))
for i in ddd:
print(' ',i)
except Exception as e:
print(word)
print()
if __name__ == '__main__':
while True:
print("--------------------Welcome to Youdao dictionary------------------")
word = input("Please enter a word:")
fanyi()
ok