In this article, we will use the "sweep" framework to crawl all the used car information on taoche.com. I took 17W + data and put it into mongodb. Source code + data link: https://github.com/lixi5338619/taochewang_scrapy Let's start by explaining how to crawl the data we want:
Clear climbing target:
First, go to the official website: https://www.taoche.com/
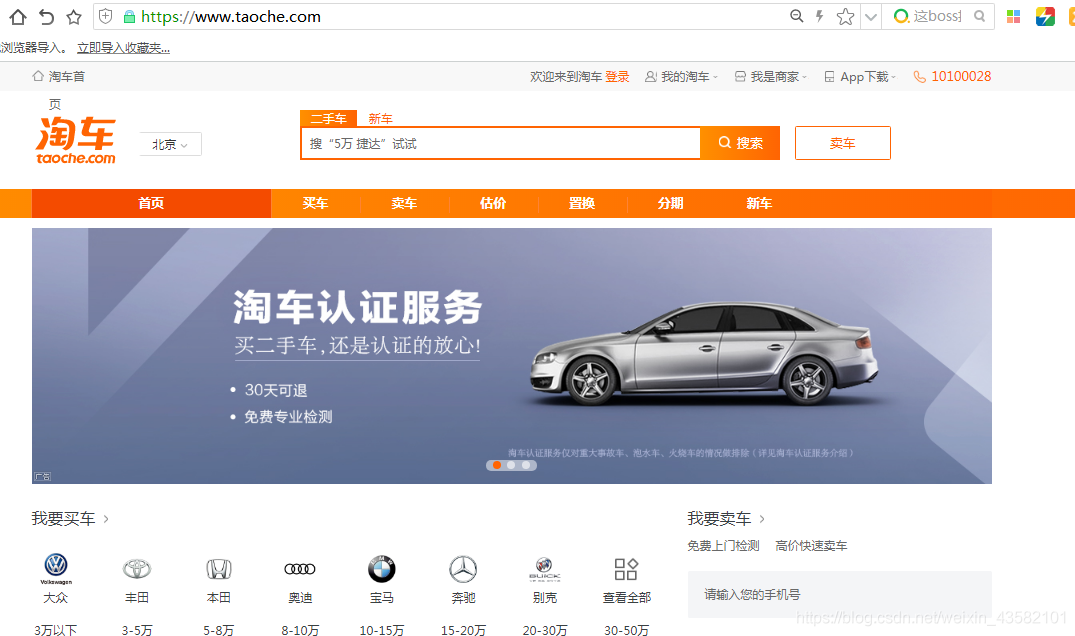
After entering the official website, we found that the amount of data we want to obtain is very large. We should not only get all city links and model links, but also have links to the details page.
We click to see all:
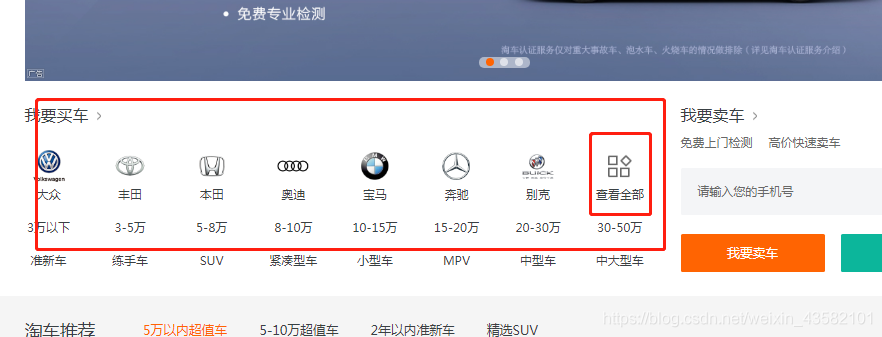
To get the url of all models from A to Z.


as well as
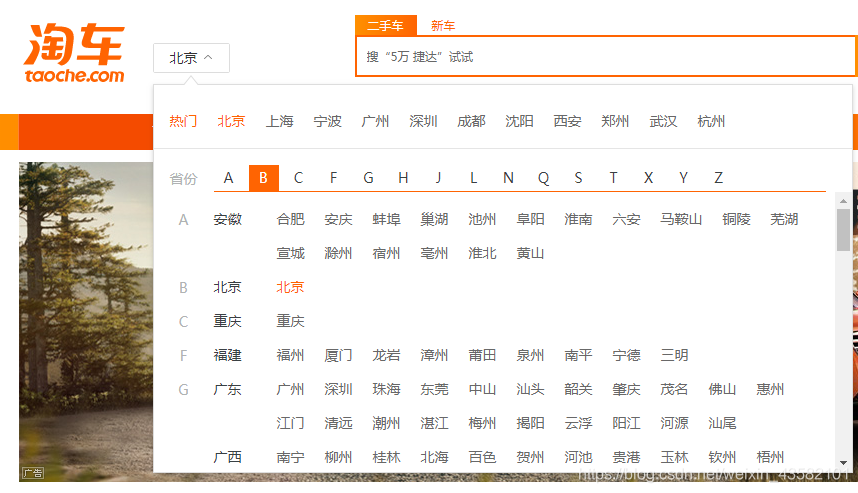
Here is a list of all cities.
After obtaining, we can enter the details of each vehicle on each page through the url of each vehicle model in each city to obtain our data.
Start task
First, we create our scratch project under a certain path:
scrapy startproject taochewang
Then create the crawler file;
cd taochewang scrapy genspier taoche taoche.com
In order to fully reflect the multithreading ability of the sweep framework, I constructed a page in advance to parse all the city and vehicle information in the home page. The following figure shows my project structure:
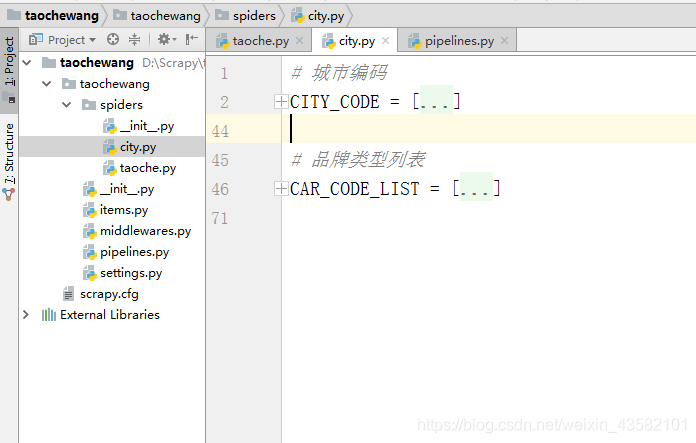
The following is the city information and model information:
# City Code
CITY_CODE = ['shijiazhuang', 'tangshan', 'qinhuangdao', 'handan', 'xingtai', 'baoding', 'zhangjiakou',
'chengde', 'cangzhou', 'langfang', 'hengshui', 'taiyuan', 'datong', 'yangquan', 'changzhi', 'jincheng',
'shuozhou', 'jinzhong', 'yuncheng', 'xinzhou', 'linfen', 'lvliang', 'huhehaote', 'baotou', 'wuhai',
'chifeng', 'tongliao', 'eerduosi', 'hulunbeier', 'bayannaoer', 'wulanchabu', 'xinganmeng',
'xilinguolemeng', 'alashanmeng', 'changchun', 'jilin', 'hangzhou', 'ningbo', 'wenzhou', 'jiaxing',
'huzhou', 'shaoxing', 'jinhua', 'quzhou', 'zhoushan', 'tz', 'lishui', 'bozhou', 'chizhou', 'xuancheng',
'nanchang', 'jingdezhen', 'pingxiang', 'jiujiang', 'xinyu', 'yingtan', 'ganzhou', 'jian', 'yichun', 'jxfz',
'shangrao', 'xian', 'tongchuan', 'baoji', 'xianyang', 'weinan', 'yanan', 'hanzhong', 'yl', 'ankang',
'shangluo', 'lanzhou', 'jiayuguan', 'jinchang', 'baiyin', 'tianshui', 'wuwei', 'zhangye', 'pingliang',
'jiuquan', 'qingyang', 'dingxi', 'longnan', 'linxia', 'gannan', 'xining', 'haidongdiqu', 'haibei',
'huangnan', 'hainanzangzuzizhizho', 'guoluo', 'yushu', 'haixi', 'yinchuan', 'shizuishan', 'wuzhong',
'guyuan', 'zhongwei', 'wulumuqi', 'kelamayi', 'shihezi', 'tulufandiqu', 'hamidiqu', 'changji', 'boertala',
'bazhou', 'akesudiqu', 'xinjiangkezhou', 'kashidiqu', 'hetiandiqu', 'yili', 'tachengdiqu', 'aletaidiqu',
'xinjiangzhixiaxian', 'changsha', 'zhuzhou', 'xiangtan', 'hengyang', 'shaoyang', 'yueyang', 'changde',
'zhangjiajie', 'yiyang', 'chenzhou', 'yongzhou', 'huaihua', 'loudi', 'xiangxi', 'guangzhou', 'shaoguan',
'shenzhen', 'zhuhai', 'shantou', 'foshan', 'jiangmen', 'zhanjiang', 'maoming', 'zhaoqing', 'huizhou',
'meizhou', 'shanwei', 'heyuan', 'yangjiang', 'qingyuan', 'dongguan', 'zhongshan', 'chaozhou', 'jieyang',
'yunfu', 'nanning', 'liuzhou', 'guilin', 'wuzhou', 'beihai', 'fangchenggang', 'qinzhou', 'guigang',
'yulin', 'baise', 'hezhou', 'hechi', 'laibin', 'chongzuo', 'haikou', 'sanya', 'sanshashi', 'qiongbeidiqu',
'qiongnandiqu', 'hainanzhixiaxian', 'chengdu', 'zigong', 'panzhihua', 'luzhou', 'deyang', 'mianyang',
'guangyuan', 'suining', 'neijiang', 'leshan', 'nanchong', 'meishan', 'yibin', 'guangan', 'dazhou', 'yaan',
'bazhong', 'ziyang', 'aba', 'ganzi', 'liangshan', 'guiyang', 'liupanshui', 'zunyi', 'anshun',
'tongrendiqu', 'qianxinan', 'bijiediqu', 'qiandongnan', 'qiannan', 'kunming', 'qujing', 'yuxi', 'baoshan',
'zhaotong', 'lijiang', 'puer', 'lincang', 'chuxiong', 'honghe', 'wenshan', 'xishuangbanna', 'dali',
'dehong', 'nujiang', 'diqing', 'siping', 'liaoyuan', 'tonghua', 'baishan', 'songyuan', 'baicheng',
'yanbian', 'haerbin', 'qiqihaer', 'jixi', 'hegang', 'shuangyashan', 'daqing', 'yc', 'jiamusi', 'qitaihe',
'mudanjiang', 'heihe', 'suihua', 'daxinganlingdiqu', 'shanghai', 'tianjin', 'chongqing', 'nanjing', 'wuxi',
'xuzhou', 'changzhou', 'suzhou', 'nantong', 'lianyungang', 'huaian', 'yancheng', 'yangzhou', 'zhenjiang',
'taizhou', 'suqian', 'lasa', 'changdudiqu', 'shannan', 'rikazediqu', 'naqudiqu', 'alidiqu', 'linzhidiqu',
'hefei', 'wuhu', 'bengbu', 'huainan', 'maanshan', 'huaibei', 'tongling', 'anqing', 'huangshan', 'chuzhou',
'fuyang', 'sz', 'chaohu', 'luan', 'fuzhou', 'xiamen', 'putian', 'sanming', 'quanzhou', 'zhangzhou',
'nanping', 'longyan', 'ningde', 'jinan', 'qingdao', 'zibo', 'zaozhuang', 'dongying', 'yantai', 'weifang',
'jining', 'taian', 'weihai', 'rizhao', 'laiwu', 'linyi', 'dezhou', 'liaocheng', 'binzhou', 'heze',
'zhengzhou', 'kaifeng', 'luoyang', 'pingdingshan', 'jiyuan', 'anyang', 'hebi', 'xinxiang', 'jiaozuo',
'puyang', 'xuchang', 'luohe', 'sanmenxia', 'nanyang', 'shangqiu', 'xinyang', 'zhoukou', 'zhumadian',
'henanzhixiaxian', 'wuhan', 'huangshi', 'shiyan', 'yichang', 'xiangfan', 'ezhou', 'jingmen', 'xiaogan',
'jingzhou', 'huanggang', 'xianning', 'qianjiang', 'suizhou', 'xiantao', 'tianmen', 'enshi',
'hubeizhixiaxian', 'beijing', 'shenyang', 'dalian', 'anshan', 'fushun', 'benxi', 'dandong', 'jinzhou',
'yingkou', 'fuxin', 'liaoyang', 'panjin', 'tieling', 'chaoyang', 'huludao', 'anhui', 'fujian', 'gansu',
'guangdong', 'guangxi', 'guizhou', 'hainan', 'hebei', 'henan', 'heilongjiang', 'hubei', 'hunan', 'jl',
'jiangsu', 'jiangxi', 'liaoning', 'neimenggu', 'ningxia', 'qinghai', 'shandong', 'shanxi', 'shaanxi',
'sichuan', 'xizang', 'xinjiang', 'yunnan', 'zhejiang', 'jjj', 'jzh', 'zsj', 'csj', 'ygc']
# Brand type list
CAR_CODE_LIST = ['southeastautomobile', 'sma', 'audi', 'hummer', 'tianqimeiya', 'seat', 'lamborghini', 'weltmeister',
'changanqingxingche-281', 'chevrolet', 'fiat', 'foday', 'eurise', 'dongfengfengdu', 'lotus-146', 'jac',
'enranger', 'bjqc', 'luxgen', 'jinbei', 'sgautomotive', 'jonwayautomobile', 'beijingjeep', 'linktour',
'landrover', 'denza', 'jeep', 'rely', 'gacne', 'porsche', 'wey', 'shenbao', 'bisuqiche-263',
'beiqihuansu', 'sinogold', 'roewe', 'maybach', 'greatwall', 'chenggongqiche', 'zotyeauto', 'kaersen',
'gonow', 'dodge', 'siwei', 'ora', 'lifanmotors', 'cajc', 'hafeiautomobile', 'sol', 'beiqixinnengyuan',
'dorcen', 'lexus', 'mercedesbenz', 'ford', 'huataiautomobile', 'jmc', 'peugeot', 'kinglongmotor',
'oushang', 'dongfengxiaokang-205', 'chautotechnology', 'faw-hongqi', 'mclaren', 'dearcc',
'fengxingauto', 'nissan', 'saleen', 'ruichixinnengyuan', 'yulu', 'isuzu', 'zhinuo',
'alpina', 'renult', 'kawei', 'cadillac', 'hanteng', 'defu', 'subaru', 'huasong', 'casyc', 'geely',
'xpeng', 'jlkc', 'sj', 'nanqixinyatu1', 'horki', 'venucia', 'xinkaiauto', 'traum',
'shanghaihuizhong-45', 'zhidou', 'ww', 'riich', 'brillianceauto', 'galue', 'bugatti',
'guagnzhouyunbao', 'borgward', 'qzbd1', 'bj', 'changheauto', 'faw', 'saab', 'fuqiautomobile', 'skoda',
'citroen', 'mitsubishi', 'opel', 'qorosauto', 'zxauto', 'infiniti', 'mazda', 'arcfox-289',
'jinchengautomobile', 'kia', 'mini', 'tesla', 'gmc-109', 'chery', 'daoda-282', 'joylongautomobile',
'hafu-196', 'sgmw', 'wiesmann', 'acura', 'yunqueqiche', 'volvo', 'lynkco', 'karry', 'chtc', 'gq',
'redstar', 'everus', 'kangdi', 'chrysler', 'cf', 'maxus', 'smart', 'maserati', 'dayu', 'besturn',
'dadiqiche', 'ym', 'huakai', 'buick', 'leapmotor', 'koenigsegg', 'bentley',
'rolls-royce', 'iveco', 'dongfeng-27', 'haige1', 'ds', 'landwind', 'volkswagen', 'sitech', 'toyota',
'polarsunautomobile', 'zhejiangkaersen', 'ladaa', 'lincoln', 'weilaiqiche', 'li', 'ferrari', 'jetour',
'honda', 'barbus', 'morgancars', 'ol', 'sceo', 'hama', 'dongfengfengguang', 'mg-79', 'ktm',
'changankuayue-283', 'suzuki', 'yudo', 'yusheng-258', 'fs', 'bydauto', 'jauger', 'foton', 'pagani',
'shangqisaibao', 'guangqihinomotors', 'polestar', 'fujianxinlongmaqichegufenyouxiangongsi',
'alfaromeo', 'shanqitongjia1', 'xingchi', 'lotus', 'hyundai', 'kaiyi', 'isuzu-132', 'bmw', 'ssangyong',
'astonmartin']You can put it in spiders according to my directory. Let's start building items. Enter items.py , I only wrote 4 pieces of data here. You can add or modify them.
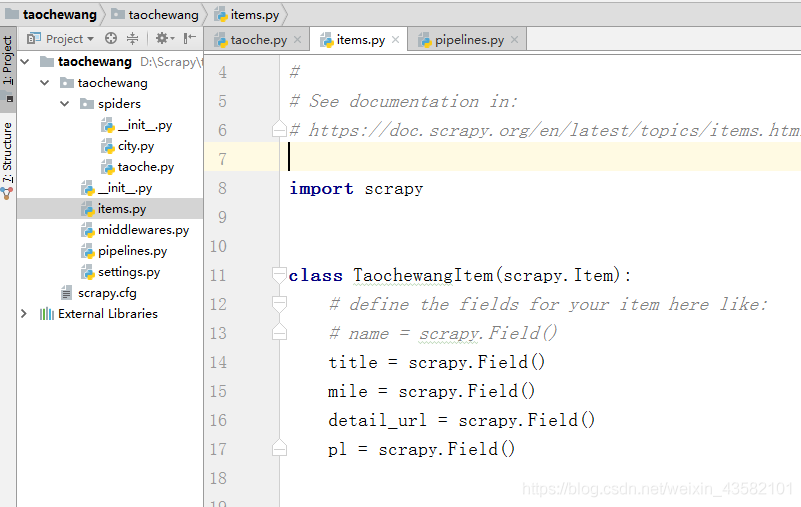
import scrapy
class TaochewangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
mile = scrapy.Field()
detail_url = scrapy.Field()
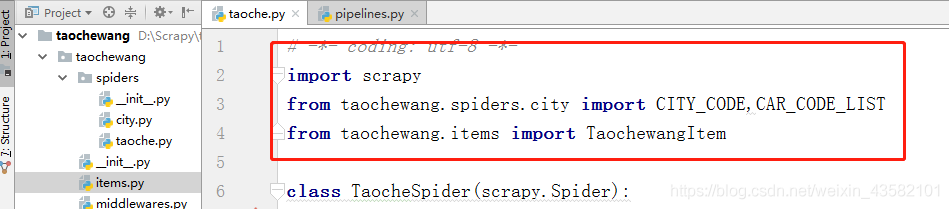
pl = scrapy.Field()After writing the items, we start to write the crawler file: Enter taoche.py. First import the city and model information in our city file. Then import TaochewangItem in items
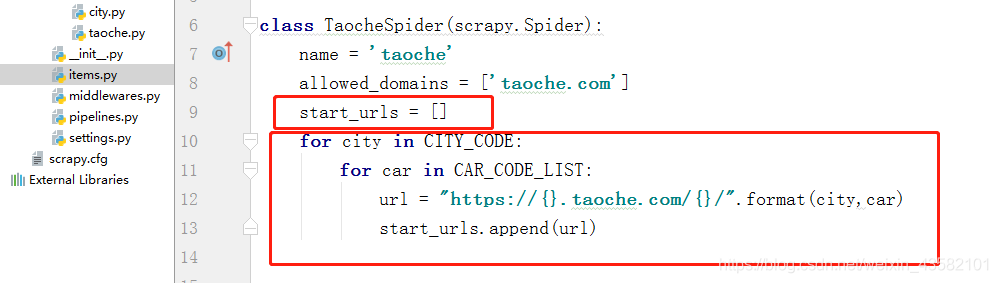
Then we need to start_urls is changed to empty, and our city model list is iterated to form a url to be added to start_urls to implement our multithreading.
After adding the url, we begin to write the parsing function. The xml file can be obtained directly through response. So we go directly to get the paging content,
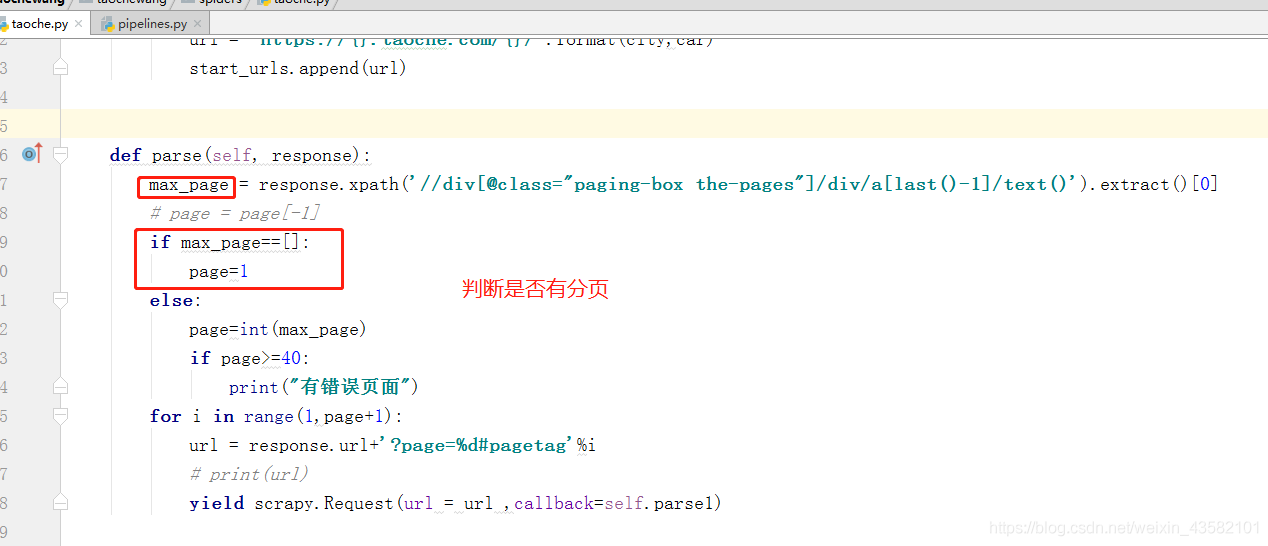
After we get the url of the page, we create a parse1 function, suspend parse with the yield method, pass in the url and call back the parse1 method.
Now you have got the url of each page of each model in each city.
Let's start writing the parse1 function.
We need to use this function to obtain the information of each vehicle model in the paged list and the url of its details page. I won't talk about the process of parsing the page. When we get the exact data information, To suspend the data through the meta = {'data': item} method and callback in yield, and then request the data of the detail page. Don filer = false is used to remove duplicate URLs.

Let's write the final parsing function, parse2 The process has been completed. In order to save trouble, I only took one data on the details page. You can update it here.
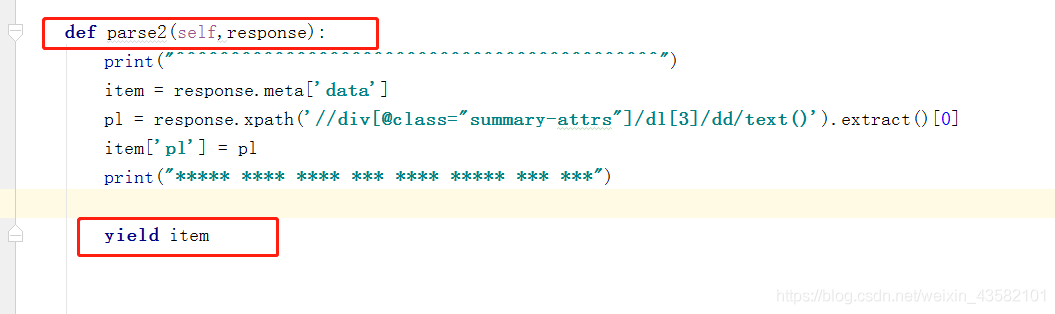
The crawler file taoche parsing data has been completed.
We're going to process data in the pipeline.
Piping and settings settings
In the pipeline, I dropped all the data here into mongodb. If not, you can install or save it to csv and txt. The db operation is very simple.
pip install pymongo
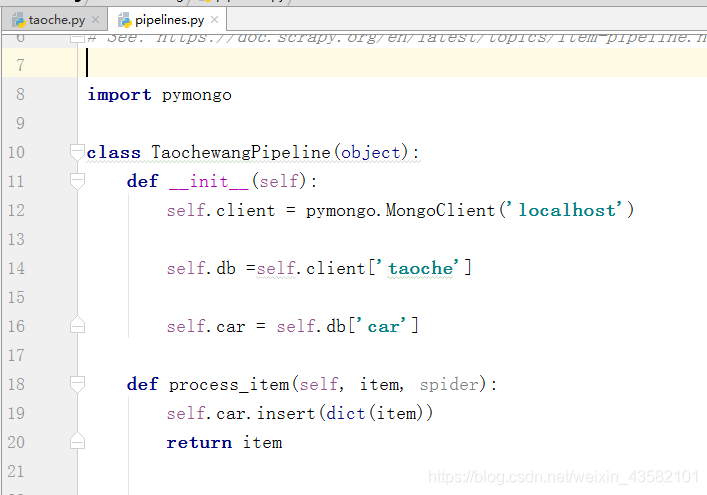
self.client = pymongo.MongoClient('localhost')Connect mongo
self.db =self.client['taoche']
Connect taoche
self.car = self.db['car']
Connection collection.
self.car.insert(dict(item))
Inserts data into the collection.
Finally, we need to set several data in settings:
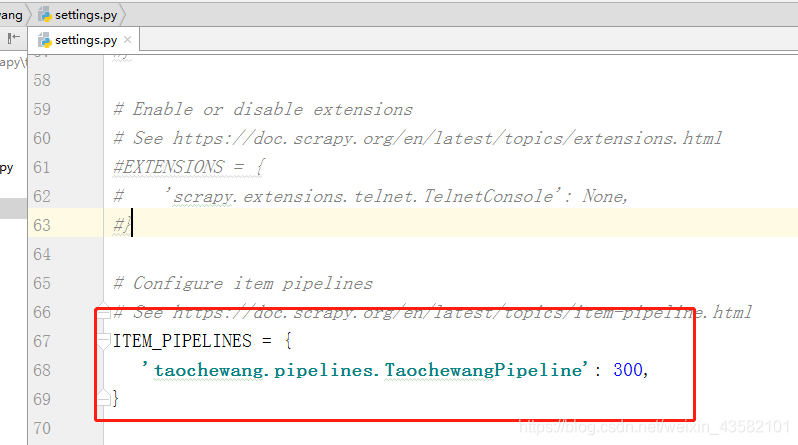
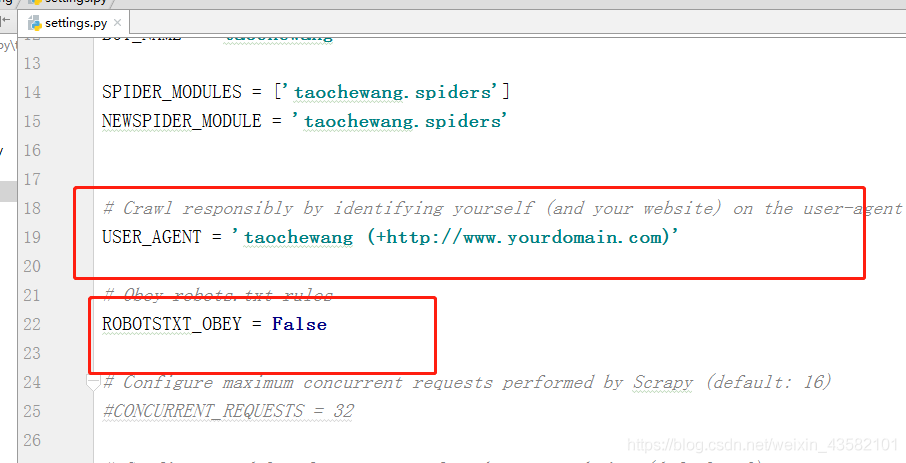
Open the pipeline, close the protocol, and open the request header. Then run scratch crawl taoche Wait and get the data. The project is completed.
