1 Introduction
1. What is it
Hadoop is an open source software of apache for big data storage and computing.
2. What can I do
a big data storage b distributed computing c (computer) resource scheduling
3. Features
High performance, low cost, high efficiency and reliability. It is universal and simple to use
4. Version
4.1 open source community version
Fast update iteration, low compatibility and stability
https://hadoop.apache.org/
4.2 commercial release
5. Composition
HDFS (distributed file storage)
MapReduce (distributed data processing, components at the code level)
YARN (resource management task scheduling in 2.0)
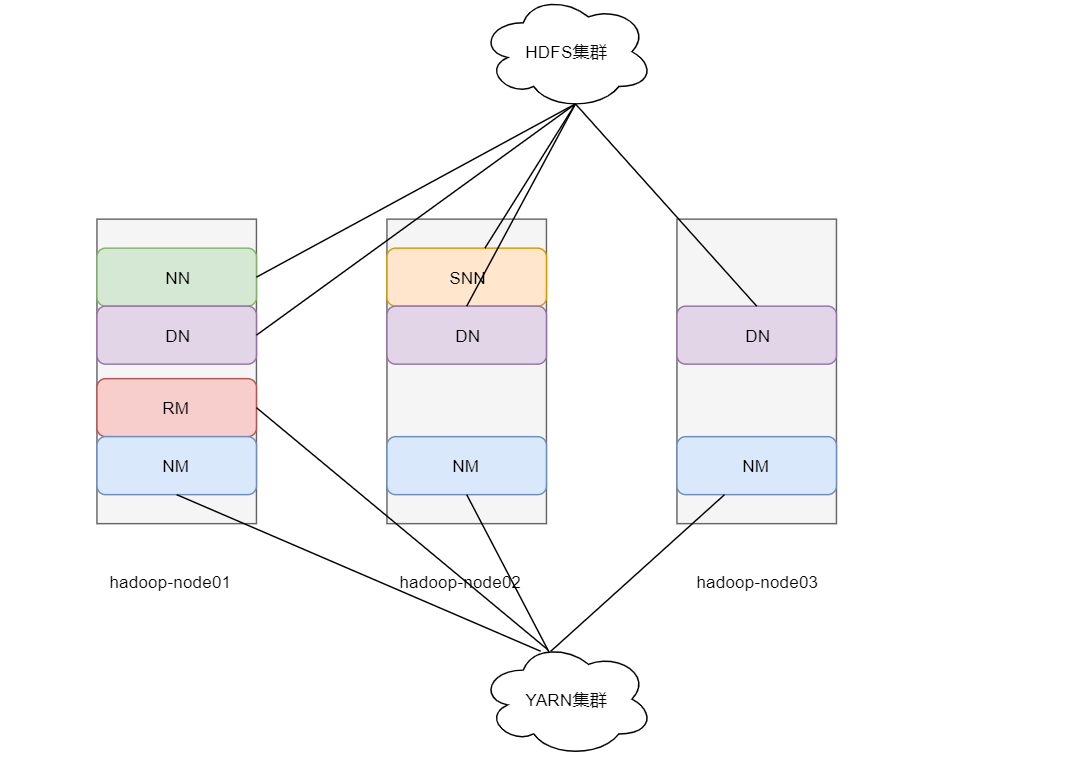
6.Hadoop cluster
Hadoop cluster = HDFS + YARN
HDFS cluster
Protagonist NameNode From role DataNode Primary role secondary role SecondaryNameNode
YARN cluster
Protagonist RecourceManager From role NodeManager
It can be seen that in the experimental deployment, the HDFS cluster has a set of NN plus three slave DN S plus an auxiliary role SNN
One master RM and three slave NM S in the YARN cluster
2 deployment
1 set host
hostnamectl set-hostname hadoop-node01 hostnamectl set-hostname hadoop-node02 hostnamectl set-hostname hadoop-node03
2. Set hosts
It is suggested to set it on the host computer
cat /etc/hosts
192.168.67.200 hadoop-node01 192.168.67.201 hadoop-node02 192.168.67.202 hadoop-node03
3 turn off the firewall
systemctl stop firewalld systemctl disable firewalld
4ssh password free login
All operations are performed at node 1. This operation is mainly used for remote operation between linux hosts
#node1 generates public and private keys (all the way enter) ssh-keygen #Node1 configure password free login to node1 node2 node3 ssh-copy-id node1 ssh-copy-id node2 ssh-copy-id node3
5 time synchronization
ntpdate does not have this command. You can use yum to install it
ntpdate ntp5.aliyun.com
6 create working directory
mkdir -p /export/server software installation directory
mkdir -p /export/data software data storage directory
mkdir -p /export/software installation package storage directory
7 install jdk1 on the first machine eight
Configure environment variables and take effect
[root@localhost server]# vi /etc/profile [root@localhost server]# source /etc/profile
export JAVA_HOME=/export/server/jdk1.8.0_241 export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
Remote copy to the other two machines on node one
scp -r /export/server/jdk1.8.0_241/ root@hadoop-node02:/export/server/
Environment variable files can also be copied. Remember to take effect
scp -r /etc/profile root@hadoop-node02:/etc/profile
8Hadoop installation
directory structure
-
bin basic management script
-
sbin startup script
-
etc configuration
-
jar packages and samples compiled by share
9 modify configuration
hadoop-env.sh
#Add last file export JAVA_HOME=/export/server/jdk1.8.0_241 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
core-site.xml
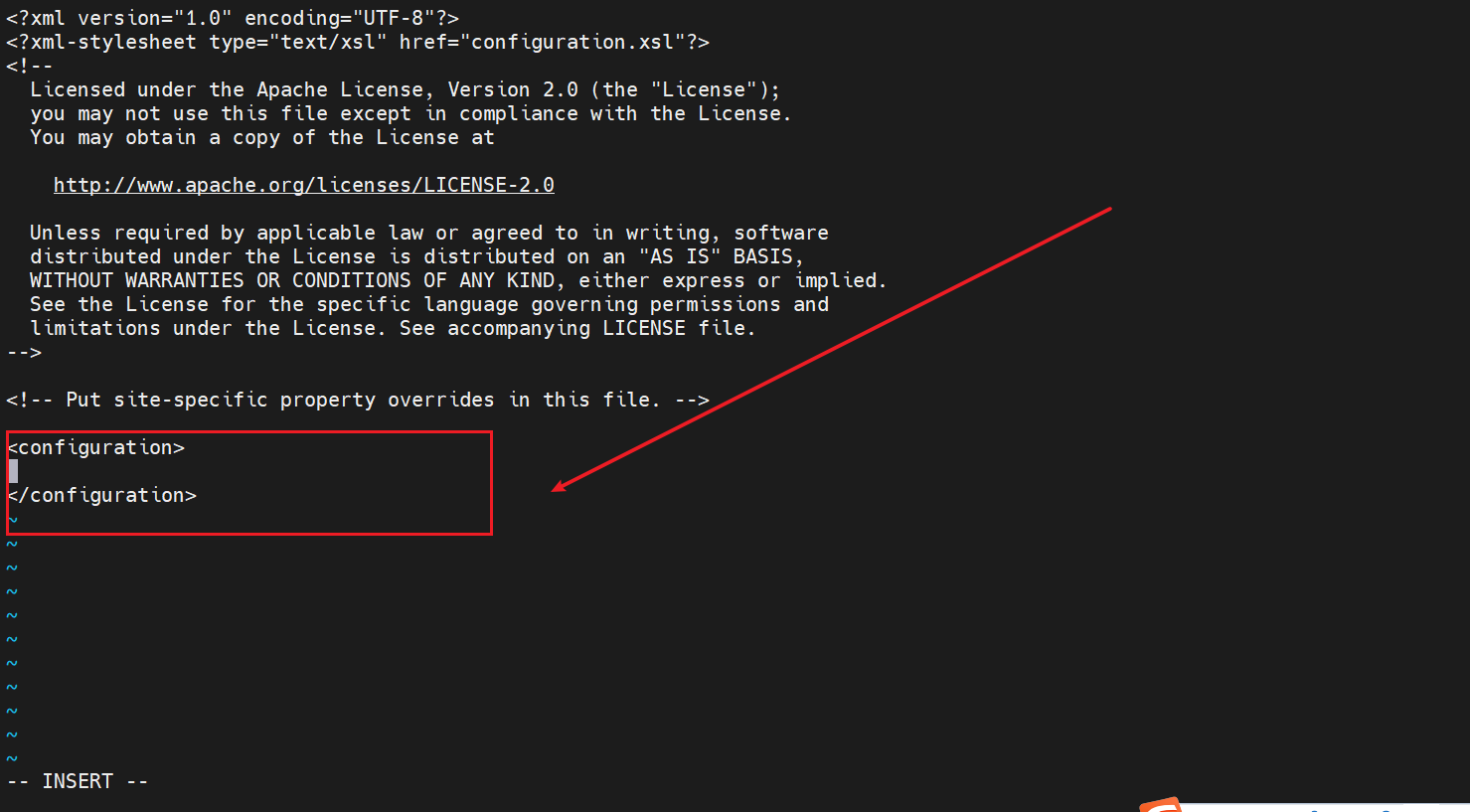
<!-- Set the default file system Hadoop support file,HDFS,GFS,ali|Amazon Cloud and other file systems -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-node01:8020</value>
</property>
<!-- set up Hadoop Local save data path -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.0</value>
</property>
<!-- set up HDFS web UI User identity -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- integration hive User agent settings -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- File system trash can save time -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
hdfs-site.xml
<!-- set up SNN Process running machine location information -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-node02:9868</value>
</property>
mapred-site.xml
<!-- set up MR Program default running mode: yarn Cluster mode local Local mode -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR Program history service address -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-node01:10020</value>
</property>
<!-- MR Program history server web End address -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-node01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
yarn-site.xml
<!-- set up YARN Cluster main color running machine position -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- Will physical memory restrictions be imposed on the container -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- Whether virtual memory limits will be imposed on the container. -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- Enable log aggregation -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- set up yarn Historical server address -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop-node01:19888/jobhistory/logs</value>
</property>
<!-- The historical log is kept for 7 days -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
vi workers
hadoop-node01 hadoop-node02 hadoop-node03
10 distribute installation packages to other machines
cd /export/server scp -r hadoop-3.3.0 root@hadoop-node02:$PWD scp -r hadoop-3.3.0 root@hadoop-node03:$PWD
11 add Hadoop to environment variable
vim /etc/profile export HADOOP_HOME=/export/server/hadoop-3.3.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin source /etc/profile
After entering hadoop, you can see the relevant commands (take a snapshot here)
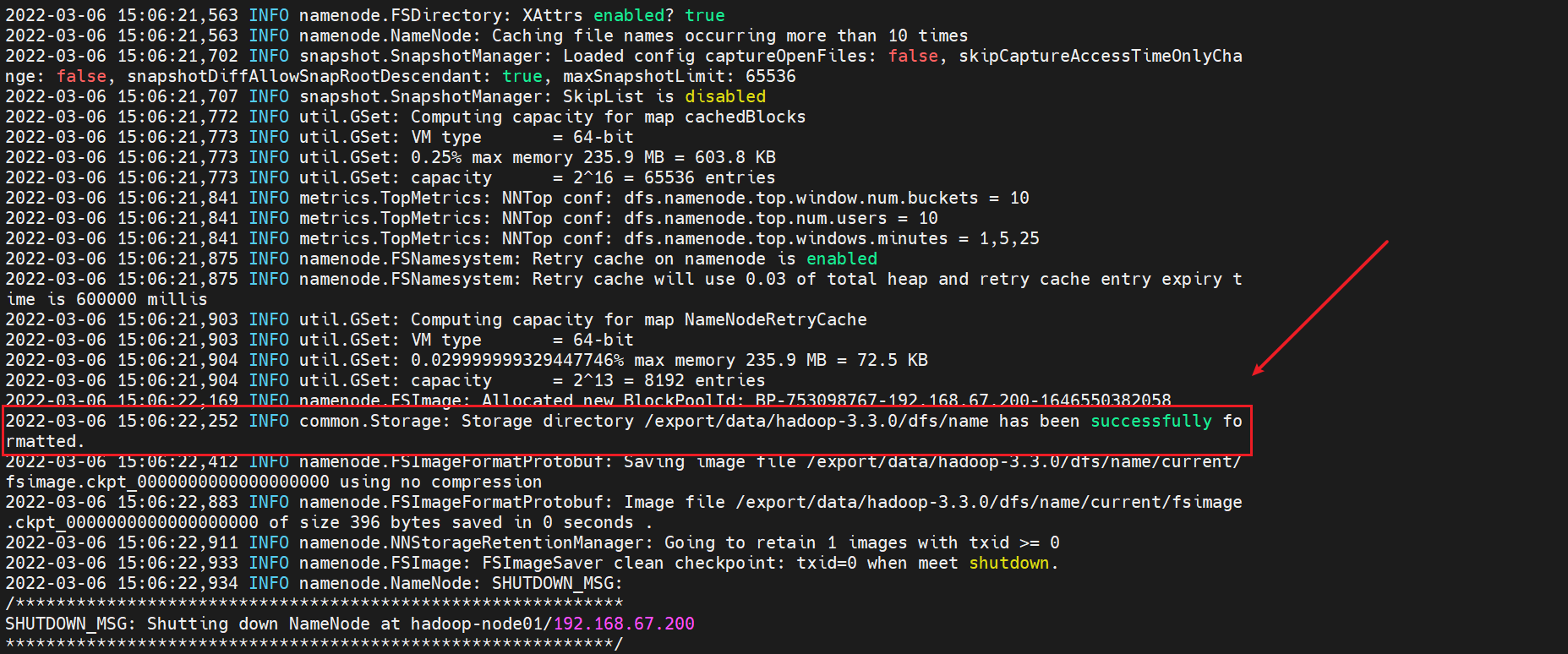
12HDFS system initialization (format)
The initialization command can only be started once on a node
hdfs namenode -format
Initialization succeeded
13 start the service at node 1
Start HDFS service
start-dfs.sh
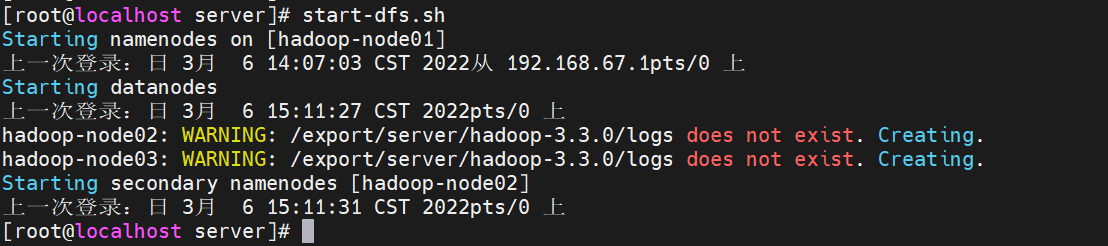
Verify that the service started successfully
node1
[root@localhost server]# jps 3732 Jps 3445 DataNode 3323 NameNode
node2
[root@localhost ~]# jps 14880 DataNode 14993 SecondaryNameNode 15116 Jps
node3
[root@localhost ~]# jps 2680 Jps 2618 DataNode
Start the YARN service only on the first machine
start-yarn.sh

Verify that the service started successfully
node01
[root@localhost server]# jps 4321 Jps 3987 NodeManager 3445 DataNode 3864 ResourceManager 3323 NameNode
node02
[root@localhost ~]# jps 14880 DataNode 14993 SecondaryNameNode 15475 NodeManager 15615 Jps
node03
[root@localhost ~]# jps 2738 NodeManager 2618 DataNode 2828 Jps
3 system UI and simple use
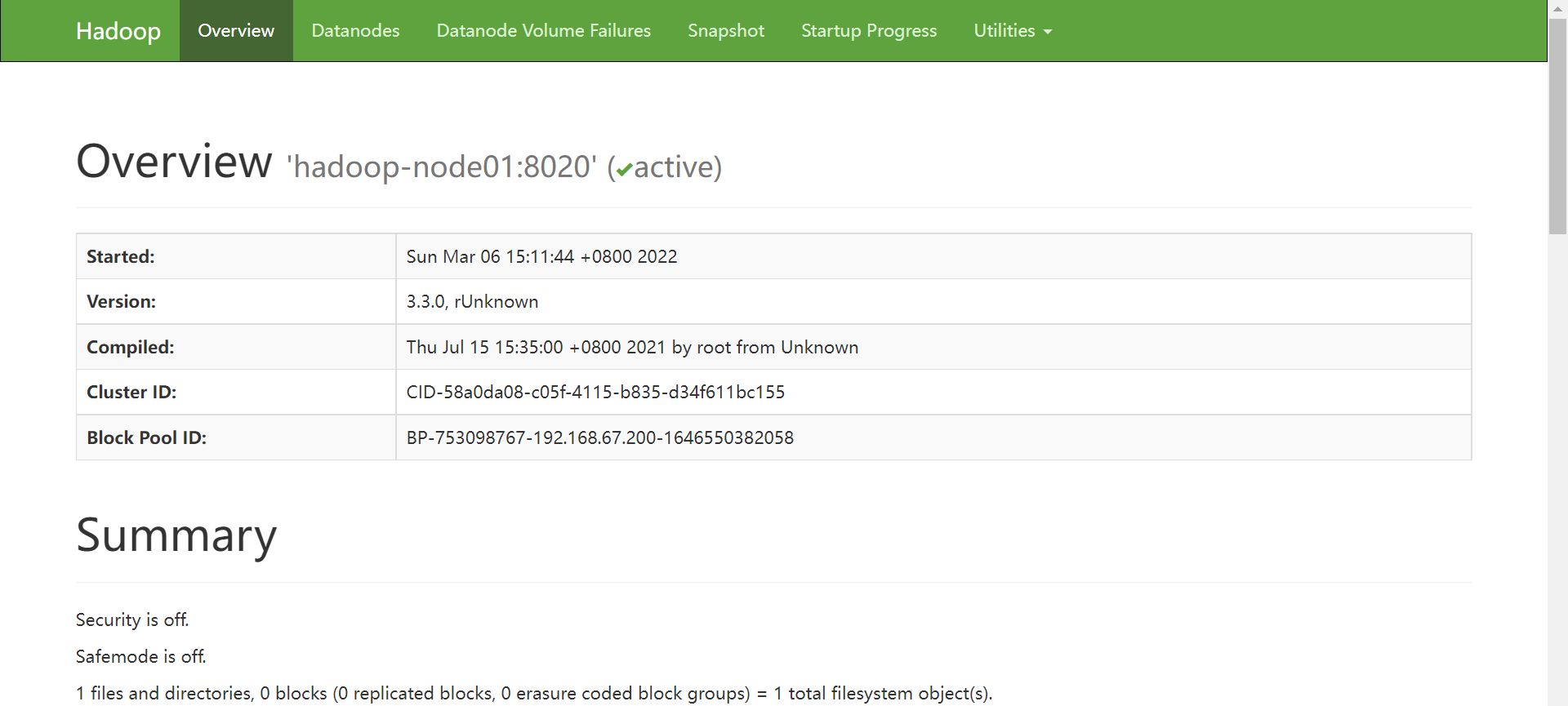
HDFS
http://hadoop-node01:9870/
Browse file system
YARN 8088
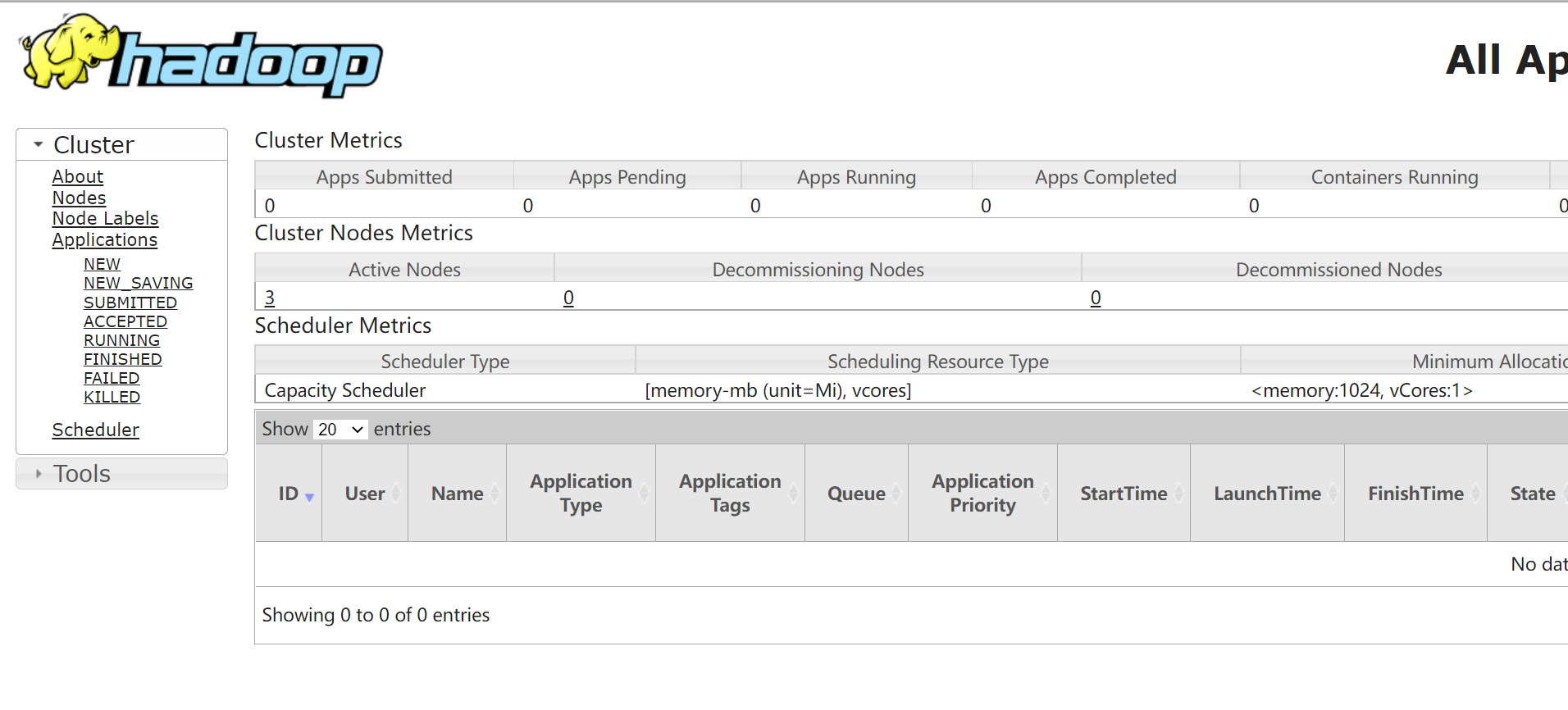
4 basic system operation
HDFS
[root@localhost server]# hadoop fs -ls / [root@localhost server]# hadoop fs -mkdir /hellohdfs [root@localhost server]# ls hadoop-3.3.0 hadoop-3.3.0-Centos7-64-with-snappy.tar.gz hadoop-3.3.0-src.tar.gz jdk1.8.0_241 jdk-8u241-linux-x64.tar.gz [root@localhost server]# echo hello > hello.txt [root@localhost server]# hadoop fs -put hello.txt /hellohdfs
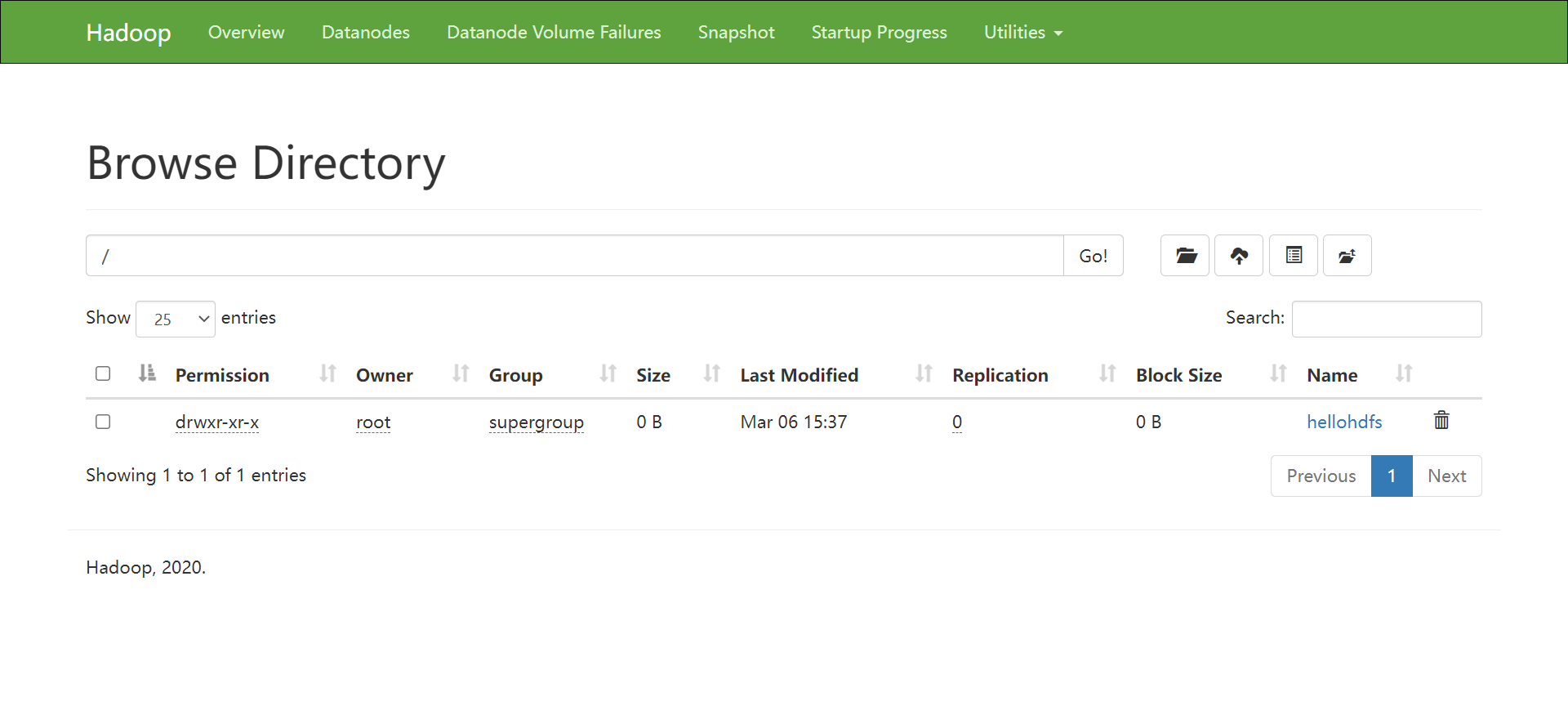
YARN
cd /export/server/hadoop-3.3.0/share/hadoop/mapreduce
Case 1: calculating pi
hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 2 2
[root@localhost mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 2 2
Number of Maps = 2
Samples per Map = 2
Wrote input for Map #0
Wrote input for Map #1
Starting Job
2022-03-06 15:44:32,206 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at hadoop-node01/192.168.67.200:8032
2022-03-06 15:44:34,363 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1646551219840_0001
2022-03-06 15:44:35,119 INFO input.FileInputFormat: Total input files to process : 2
2022-03-06 15:44:35,395 INFO mapreduce.JobSubmitter: number of splits:2
2022-03-06 15:44:36,376 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1646551219840_0001
2022-03-06 15:44:36,377 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-03-06 15:44:37,306 INFO conf.Configuration: resource-types.xml not found
2022-03-06 15:44:37,308 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-03-06 15:44:39,455 INFO impl.YarnClientImpl: Submitted application application_1646551219840_0001
2022-03-06 15:44:39,947 INFO mapreduce.Job: The url to track the job: http://hadoop-node01:8088/proxy/application_1646551219840_0001/
2022-03-06 15:44:39,948 INFO mapreduce.Job: Running job: job_1646551219840_0001
2022-03-06 15:45:10,432 INFO mapreduce.Job: Job job_1646551219840_0001 running in uber mode : false
2022-03-06 15:45:10,437 INFO mapreduce.Job: map 0% reduce 0%
2022-03-06 15:45:41,275 INFO mapreduce.Job: map 100% reduce 0%
2022-03-06 15:45:57,587 INFO mapreduce.Job: map 100% reduce 100%
2022-03-06 15:45:58,682 INFO mapreduce.Job: Job job_1646551219840_0001 completed successfully
2022-03-06 15:45:59,575 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=50
FILE: Number of bytes written=795297
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=536
HDFS: Number of bytes written=215
HDFS: Number of read operations=13
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=52488
Total time spent by all reduces in occupied slots (ms)=13859
Total time spent by all map tasks (ms)=52488
Total time spent by all reduce tasks (ms)=13859
Total vcore-milliseconds taken by all map tasks=52488
Total vcore-milliseconds taken by all reduce tasks=13859
Total megabyte-milliseconds taken by all map tasks=53747712
Total megabyte-milliseconds taken by all reduce tasks=14191616
Map-Reduce Framework
Map input records=2
Map output records=4
Map output bytes=36
Map output materialized bytes=56
Input split bytes=300
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=56
Reduce input records=4
Reduce output records=0
Spilled Records=8
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=1004
CPU time spent (ms)=4930
Physical memory (bytes) snapshot=504107008
Virtual memory (bytes) snapshot=8212619264
Total committed heap usage (bytes)=263778304
Peak Map Physical memory (bytes)=198385664
Peak Map Virtual memory (bytes)=2737340416
Peak Reduce Physical memory (bytes)=109477888
Peak Reduce Virtual memory (bytes)=2741846016
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=236
File Output Format Counters
Bytes Written=97
Job Finished in 88.0 seconds
Estimated value of Pi is 4.00000000000000000000
Case 2: word statistics
hadoop fs -mkdir -p /wordcount/input
hadoop fs -put mywords.txt /wordcount/input
hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /wordcount/input /wordcount/output
[root@localhost mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /wordcount/input /wordcount/output
2022-03-06 15:52:46,025 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at hadoop-node01/192.168.67.200:8032
2022-03-06 15:52:48,220 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1646551219840_0002
2022-03-06 15:52:49,299 INFO input.FileInputFormat: Total input files to process : 1
2022-03-06 15:52:49,673 INFO mapreduce.JobSubmitter: number of splits:1
2022-03-06 15:52:50,671 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1646551219840_0002
2022-03-06 15:52:50,672 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-03-06 15:52:51,504 INFO conf.Configuration: resource-types.xml not found
2022-03-06 15:52:51,505 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-03-06 15:52:51,755 INFO impl.YarnClientImpl: Submitted application application_1646551219840_0002
2022-03-06 15:52:52,019 INFO mapreduce.Job: The url to track the job: http://hadoop-node01:8088/proxy/application_1646551219840_0002/
2022-03-06 15:52:52,036 INFO mapreduce.Job: Running job: job_1646551219840_0002
2022-03-06 15:53:17,361 INFO mapreduce.Job: Job job_1646551219840_0002 running in uber mode : false
2022-03-06 15:53:17,380 INFO mapreduce.Job: map 0% reduce 0%
2022-03-06 15:53:41,194 INFO mapreduce.Job: map 100% reduce 0%
2022-03-06 15:54:08,530 INFO mapreduce.Job: map 100% reduce 100%
2022-03-06 15:54:09,601 INFO mapreduce.Job: Job job_1646551219840_0002 completed successfully
2022-03-06 15:54:10,177 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=3367
FILE: Number of bytes written=536181
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=4681
HDFS: Number of bytes written=2551
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=18564
Total time spent by all reduces in occupied slots (ms)=23913
Total time spent by all map tasks (ms)=18564
Total time spent by all reduce tasks (ms)=23913
Total vcore-milliseconds taken by all map tasks=18564
Total vcore-milliseconds taken by all reduce tasks=23913
Total megabyte-milliseconds taken by all map tasks=19009536
Total megabyte-milliseconds taken by all reduce tasks=24486912
Map-Reduce Framework
Map input records=86
Map output records=428
Map output bytes=5358
Map output materialized bytes=3367
Input split bytes=118
Combine input records=428
Combine output records=204
Reduce input groups=204
Reduce shuffle bytes=3367
Reduce input records=204
Reduce output records=204
Spilled Records=408
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=583
CPU time spent (ms)=4690
Physical memory (bytes) snapshot=285466624
Virtual memory (bytes) snapshot=5475692544
Total committed heap usage (bytes)=139329536
Peak Map Physical memory (bytes)=190091264
Peak Map Virtual memory (bytes)=2733432832
Peak Reduce Physical memory (bytes)=95375360
Peak Reduce Virtual memory (bytes)=2742259712
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=4563
File Output Format Counters
Bytes Written=2551
After execution, HDFS will automatically generate the output directory
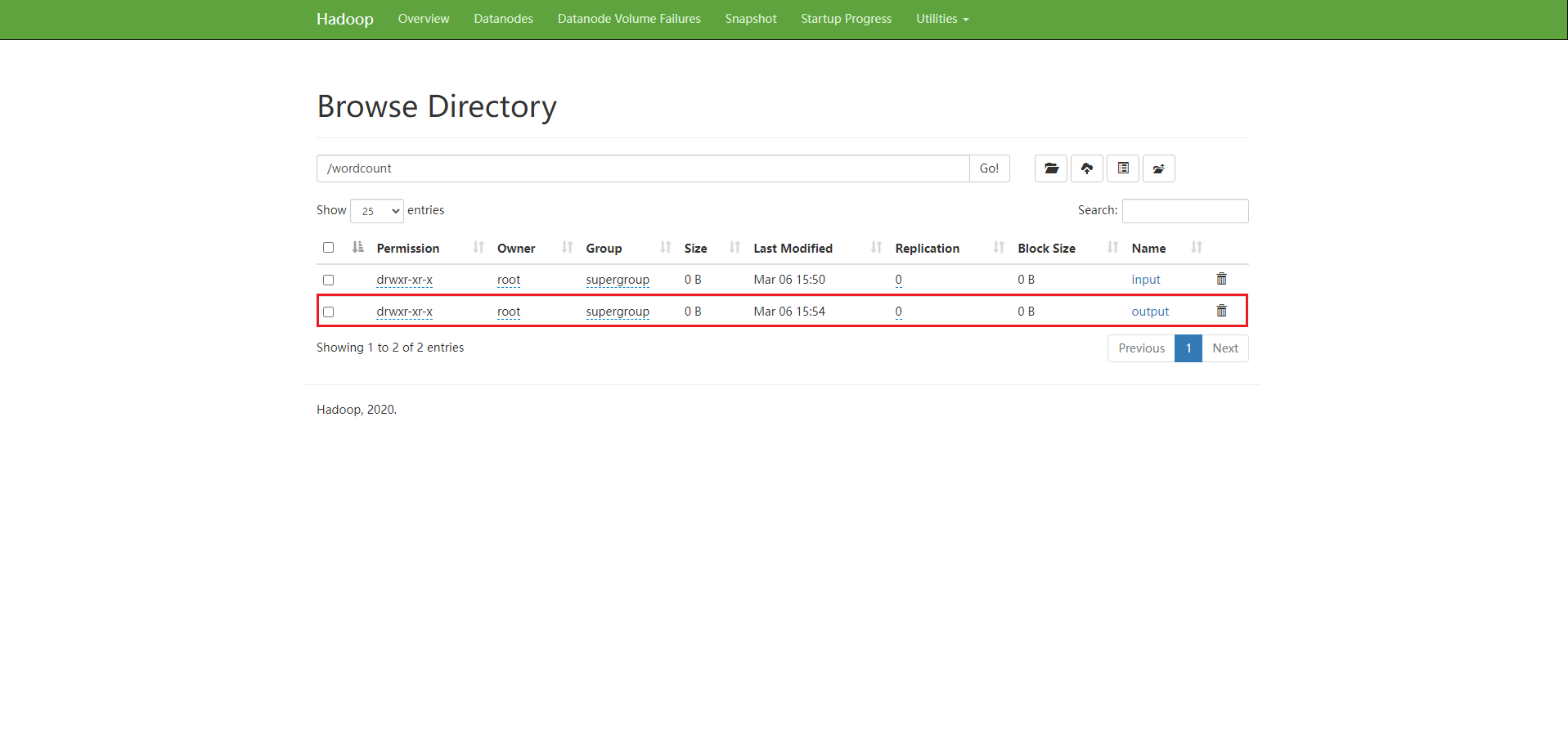
Enter directory
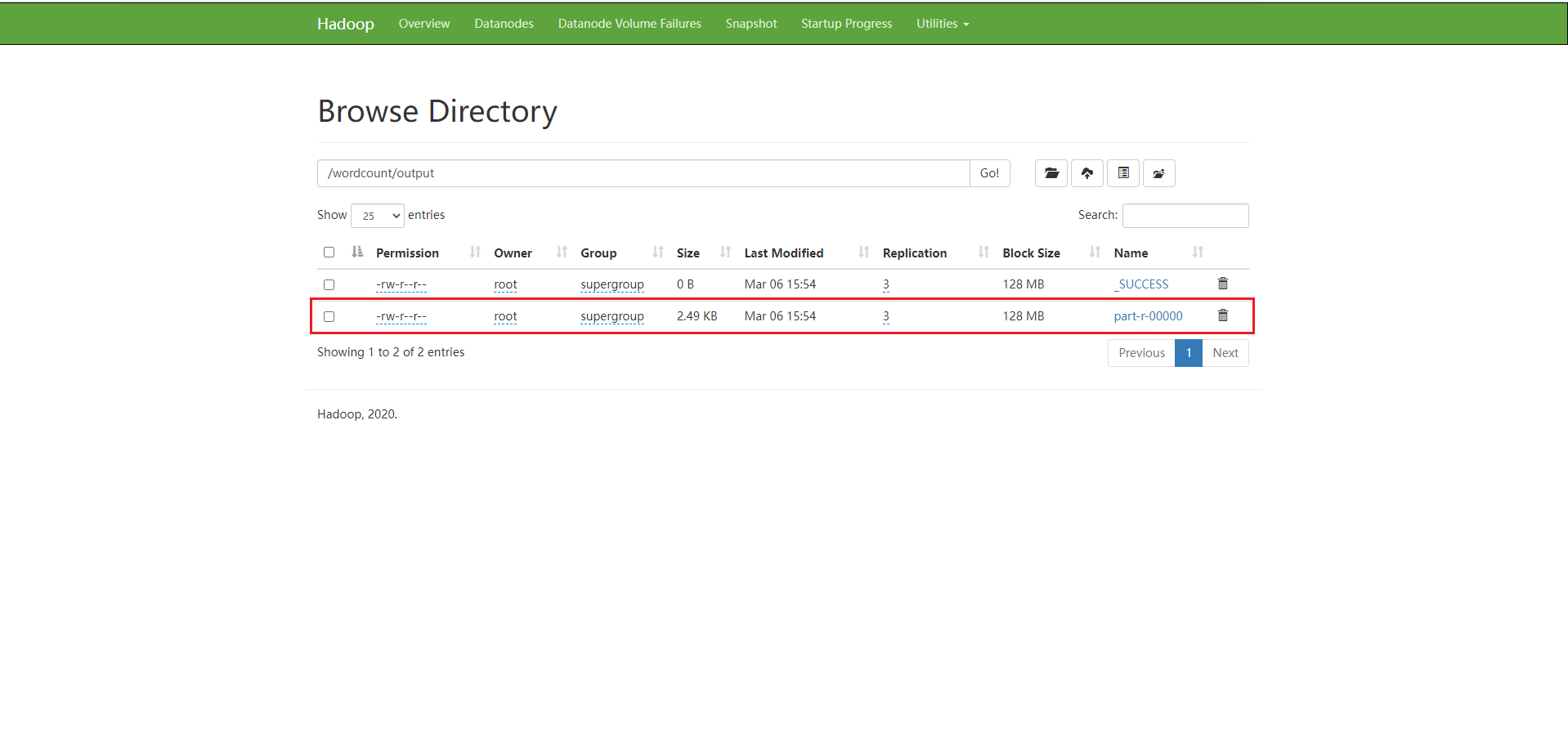
After downloading the file, open it with notepad + +

Note: if you use a virtual machine, you need to fill in the virtual machine ip and domain name mapping in the host hosts file when using it with the host, otherwise the download will fail.