1. DQL operation sheet
1.1 create database and copy tables
- Create a new db2 database
CREATE DATABASE db2 CHARACTER SET utf8;
- Copy the emp table in the db1 database to the current db2 database
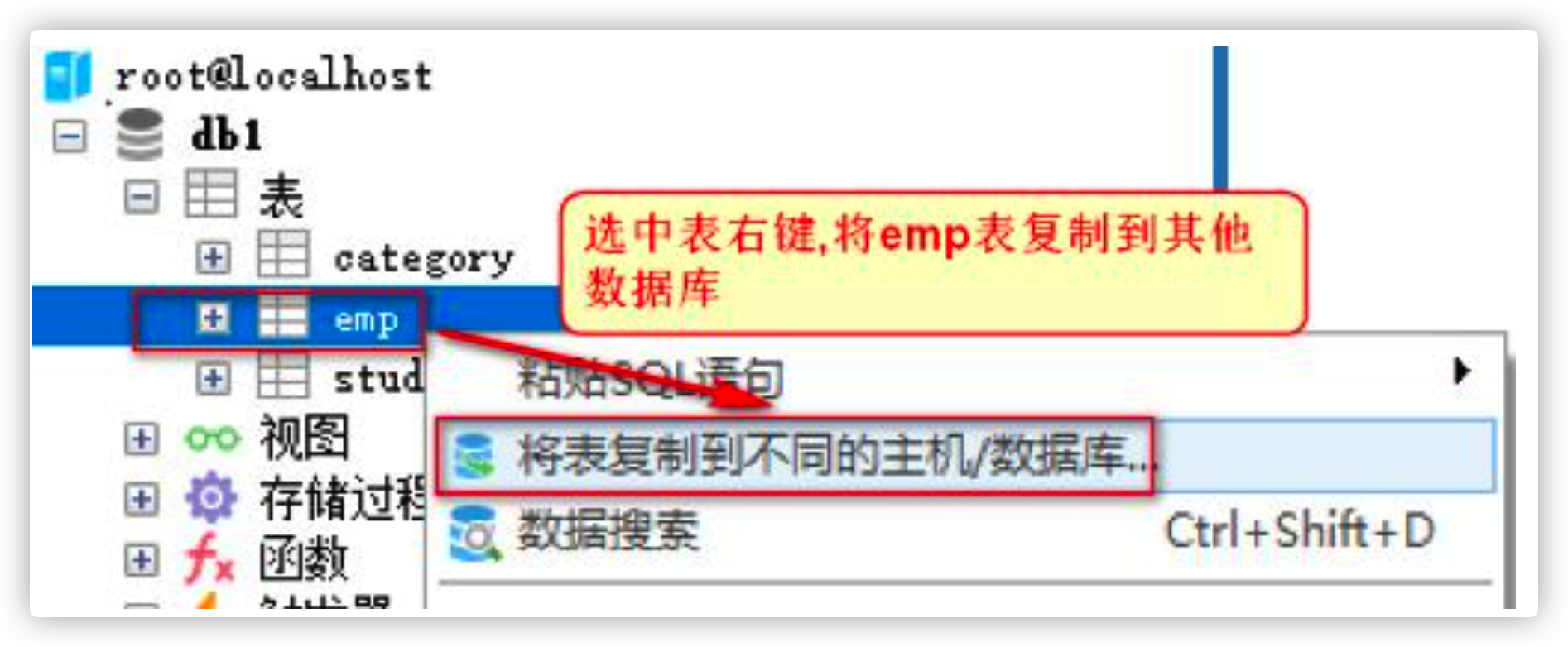
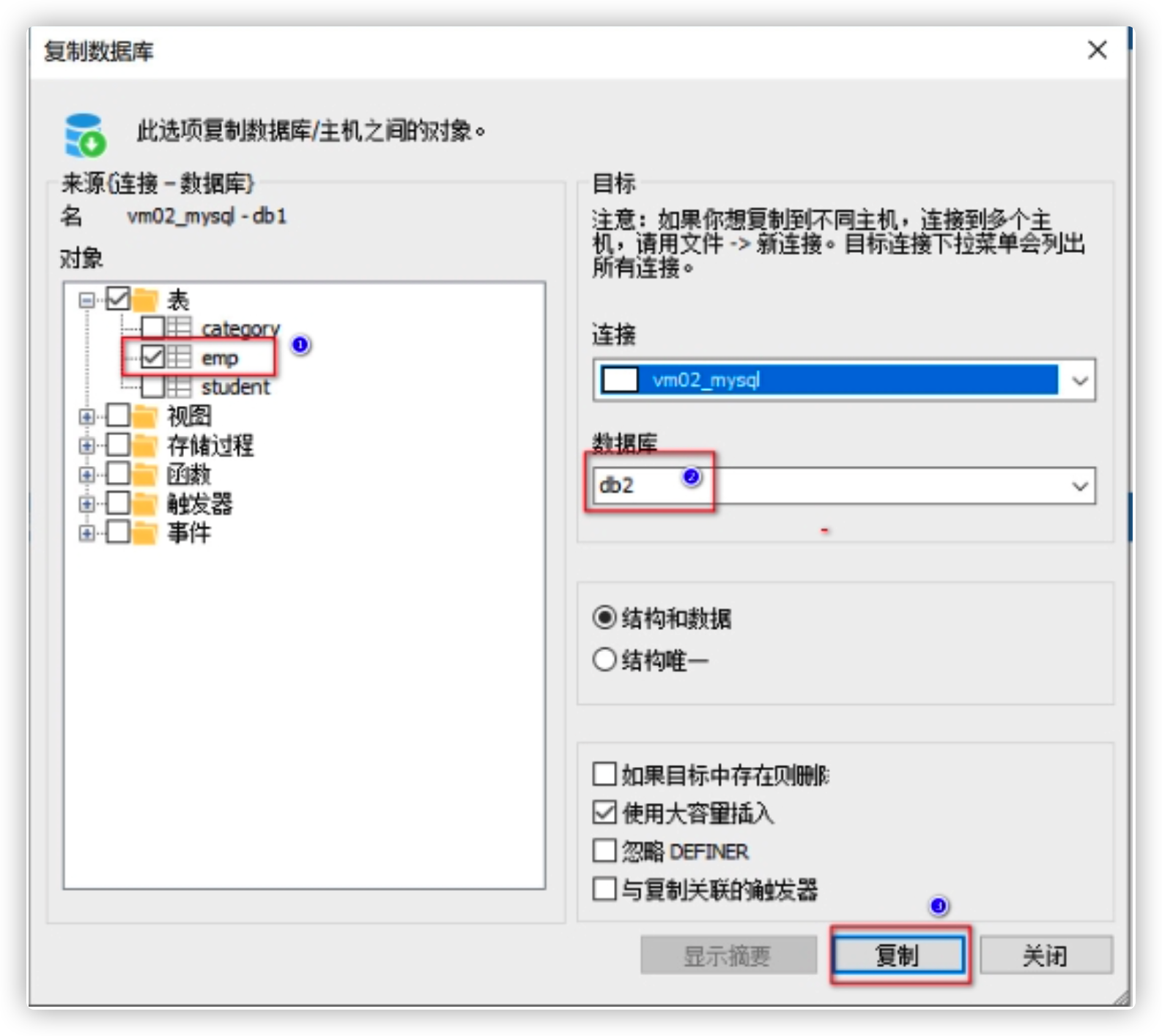
1.2 sorting
- The sorting effect of the query can only be displayed through the order clause, and the sorting effect will not be displayed through the by clause
Grammatical structure
SELECT Field name FROM Table name [WHERE field = value] ORDER BY Field name [ASC / DESC] -- ASC Indicates ascending sort(default) -- DESC Indicates descending sort
1.2.1 sorting method
- Single column sorting
Sorting by only one field is single column sorting
Demand 1:
Use the salary field to sort the emp table data (ascending / descending)
-- Default ascending sort ASC SELECT * FROM emp ORDER BY salary; -- Descending sort SELECT * FROM emp ORDER BY salary DESC;
- Combinatorial sorting
Sort multiple fields at the same time. If the first field is the same, sort according to the second field, and so on
Demand 2:
On the basis of salary sorting, id is used for sorting. If the salary is the same, id is used for descending sorting
-- Combinatorial sorting SELECT * FROM emp ORDER BY salary DESC, eid DESC;
1.3 aggregate function
The previous queries are horizontal queries, which are judged according to the conditions row by row. The query using aggregate function is vertical query, which calculates the value of a column and then returns a single value (in addition, the aggregate function will ignore null values.);
Grammatical structure
SELECT Aggregate function(Field name) FROM Table name;
Let's learn five aggregate functions
| Aggregate function | effect |
|---|---|
| Count (field) | Count the number of record rows whose specified column is not NULL. Sum (field) calculate the numerical sum of the specified column |
| Max (field) | Calculates the maximum value for the specified column |
| Min (field) | Calculates the minimum value for the specified column |
| AVG (field) | Calculates the average value of the specified column |
Demand 1:
#1. Query the total number of employees #2 view the average value of total salary, maximum salary, minimum salary and salary of employees #3. Query the number of employees whose salary is greater than 4000 #4. Query the number of all employees whose department is' teaching department ' #5. Query the average salary of all employees in the 'marketing department'
SQL implementation
#1. Query the total number of employees -- Number of records in the statistical table count() SELECT COUNT(eid) FROM emp; -- Use a field SELECT COUNT(*) FROM emp; -- use * SELECT COUNT(1) FROM emp; -- Use 1,And * Same effect -- The following one SQL The total number of entries obtained is not accurate,because count Function ignored null value -- So be careful not to use with null Statistics for columns SELECT COUNT(dept_name) FROM emp; #2 view the average value of total salary, maximum salary, minimum salary and salary of employees -- sum Function summation, max Function maximization, min Function minimization, avg Function averaging SELECT SUM(salary) AS 'Total salary', MAX(salary) AS 'ceiling on wages', MIN(salary) AS 'minimum wages', AVG(salary) AS 'average wages' FROM emp; #3. Query the number of employees whose salary is greater than 4000 SELECT COUNT(*) FROM emp WHERE salary > 4000; #4. Query the number of all employees whose department is' teaching department ' SELECT COUNT(*) FROM emp WHERE dept_name = 'Teaching Department'; #5. Query the average salary of all employees in the 'marketing department' SELECT AVG(salary) AS 'Average salary of marketing department' FROM emp WHERE dept_name = 'Marketing Department';
1.4 grouping
- Grouping query refers to the use of GROUP BY statement to group the queried information, and the same data is used as a group
Syntax format
SELECT Grouping field/Aggregate function FROM Table name GROUP BY Grouping field [HAVING condition];
Requirement 1: grouping by gender field
-- Group operations by gender SELECT * FROM emp GROUP BY sex; -- Note that this is meaningless
Analysis: GROUP BY grouping process
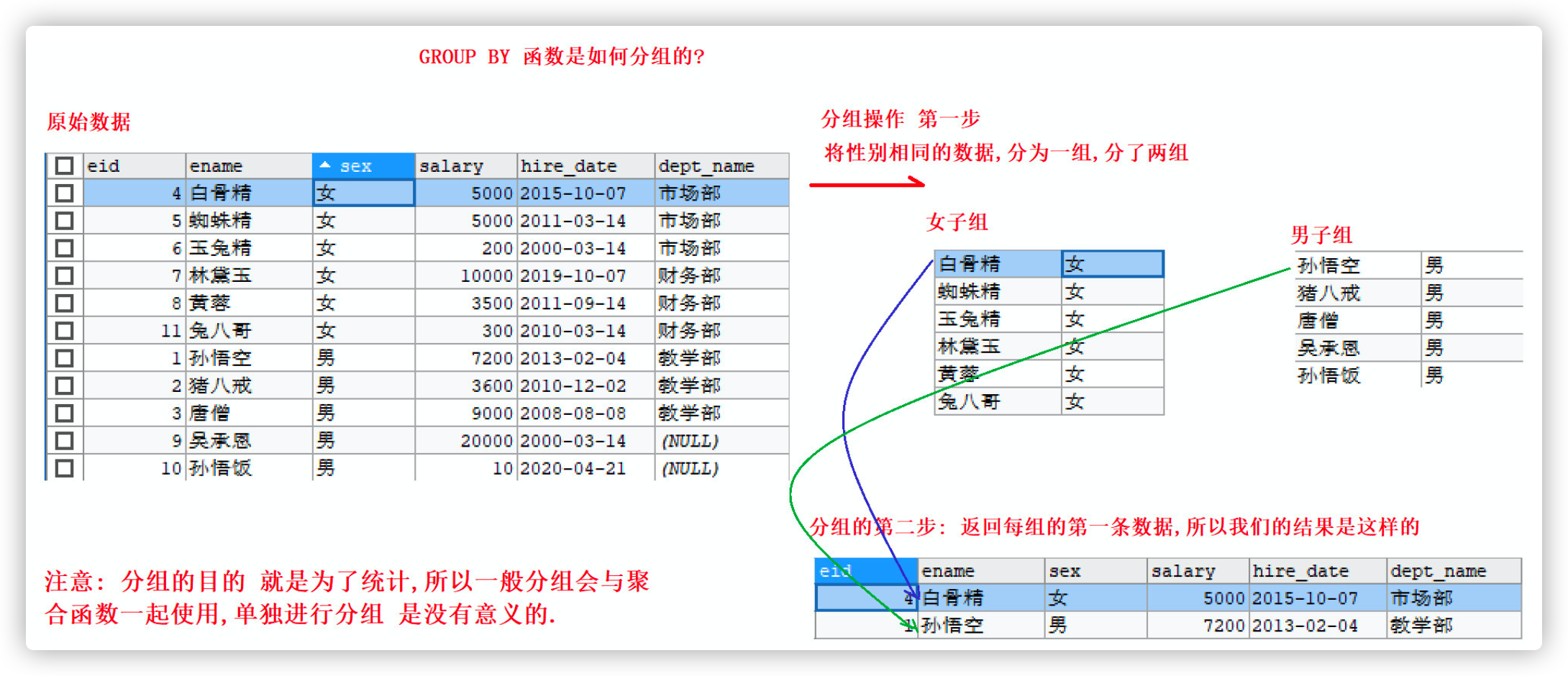
be careful:
When grouping, you can query the fields to be grouped, Or use aggregate functions for statistical operations. Querying other fields is meaningless
Demand: group by gender field to find the average salary of each group
SELECT sex, AVG(salary) FROM emp GROUP BY sex;
Demand 2:
#1. Query all department information #2. Query the average salary of each department #3. Query the average salary of each department. The Department name cannot be null
SQL implementation
#1. How many departments are there SELECT dept_name AS 'Department name' FROM emp GROUP BY dept_name; #2. Query the average salary of each department SELECT dept_name AS 'Department name', AVG(salary) AS 'Average salary' FROM emp GROUP BY dept_name; #3. Query the average salary of each department. The Department name cannot be null SELECT dept_name AS 'Department name', AVG(salary) AS 'Average salary' FROM emp WHERE dept_name IS NOT NULL GROUP BY dept_name;
Demand 3:
# Query departments with average salary greater than 6000
analysis:
- You need to filter the data after grouping and use the keyword having
- The having sub statement in grouping operation is used to filter data after grouping. Its function is similar to where condition.
SQL implementation:
# Query departments with average salary greater than 6000
-- You need to filter again after grouping,use having SELECT
dept_name ,
AVG(salary)
FROM emp WHERE dept_name IS NOT NULL GROUP BY dept_name HAVING AVG(salary) >
6000 ;
- The difference between where and having
| Filtering mode | characteristic |
|---|---|
| where | Where to filter before grouping. Aggregate functions cannot be written after where |
| having | Having is the filtering after grouping. Aggregation functions can be written after having |
1.5 limit keyword
Function of limit keyword
- Limit means limit. It is used to limit the number of rows of query results returned (you can specify how many rows of data to query through limit)
- limit syntax is a dialect of MySql, which is used to complete paging
Grammatical structure
SELECT Field 1,Field 2... FROM Table name LIMIT offset , length;
Parameter description
- limit offset , length; Keyword can accept one or two parameters that are 0 or positive integers
- offset starting line number, counting from 0. If omitted, it defaults to 0
- length returns the number of rows
Demand 1:
# Query the first 5 data in emp table # Query the emp table from item 4 to Item 6
SQL implementation
# Query the first 5 data in emp table -- Starting value of parameter 1,The default is 0 , Parameter 2 number of entries to query SELECT * FROM emp LIMIT 5; SELECT * FROM emp LIMIT 0 , 5; # Query the emp table from item 4, query item 6 -- the starting value starts from 0 by default SELECT * FROM emp LIMIT 3 , 6;
Requirement 2: paging operation, displaying 3 pieces of data per page
SQL implementation
-- Paging operation displays 3 pieces of data per page SELECT * FROM emp LIMIT 0,3; -- Page 1 SELECT * FROM emp LIMIT 3,3; -- Page 2-1=1 1*3=3 SELECT * FROM emp LIMIT 6,3; -- Page 3 -- Paging formula start index =(Current page -1)* Number of entries per page -- limit yes MySql Dialects in
2. SQL constraints
-
Function of constraint: further restrict the data in the table, so as to ensure the correctness, effectiveness and integrity of the data Incorrect data that violates the constraint cannot be inserted into the table
-
Common constraints
| Constraint name | Constraint keyword |
|---|---|
| Primary key | primary key |
| only | unique |
| Non empty | not null |
| Foreign key | foreign key |
2.1 primary key constraints
Features: non repeatable, unique and non empty
Function: used to represent every record in the database
2.1.1 add primary key constraint
Syntax format
Field name field type primary key
- Requirement: create a table with primary key
# Method 1: create a table with primary key
CREATE TABLE emp2(
-- Set unique non empty primary key
eid INT PRIMARY KEY,
ename VARCHAR(20),
sex CHAR(1)
);
-- Delete table
DROP TABLE emp2;
-- Method 2: create a table with primary key
CREATE TABLE emp2(
eid INT ,
ename VARCHAR(20),
sex CHAR(1),
-- Specify the primary key as eid field
PRIMARY KEY(eid)
);
-- Method 3: create a table with primary key
CREATE TABLE emp2(
eid INT ,
ename VARCHAR(20),
sex CHAR(1)
)
-- No primary key is specified during creation,Then pass DDL Statement
ALTER TABLE emp2 ADD PRIMARY KEY(eid);
DESC view table structure
-- View table details DESC emp2;

- Test the uniqueness and non emptiness of the primary key
# Insert a piece of data normally INSERT INTO emp2 VALUES(1,'Song Jiang','male'); # Insert a piece of data. The primary key is empty -- Column 'eid' cannot be null Primary key cannot be empty INSERT INTO emp2 VALUES(NULL,'Li Kui','male'); # Insert a piece of data. The primary key is 1 -- Duplicate entry '1' for key 'PRIMARY' Primary key cannot be duplicate INSERT INTO emp2 VALUES(1,'Sun erniang','female');
- Which fields can be used as primary keys?
- The primary key is usually designed for business, and a primary key id is designed for each table
- The primary key is used for databases and programs and has nothing to do with the final customer. Therefore, the primary key has no meaning or relationship. As long as it can be guaranteed not to be repeated, for example, the ID card can be used as the primary key
2.1.2 delete primary key constraint
- Delete the primary key constraint in the table (understand)
-- use DDL Statement to delete the primary key in a table ALTER TABLE emp2 DROP PRIMARY KEY; DESC emp2;
2.1.3 auto increment of primary key
Note: if the primary key is added by ourselves, it is likely to be repeated. We usually want the database to automatically generate the value of the primary key field every time we insert a new record
keyword: AUTO_INCREMENT Indicates automatic growth(The field type must be an integer type)
- Create a table with self incrementing primary key
-- Create a table with self incrementing primary key CREATE TABLE emp2( -- keyword AUTO_INCREMENT,The primary key type must be an integer type eid INT PRIMARY KEY AUTO_INCREMENT, ename VARCHAR(20), sex CHAR(1) );
- Add auto increment of data observation primary key
INSERT INTO emp2(ename,sex) VALUES('Zhang San','male');
INSERT INTO emp2(ename,sex) VALUES('Li Si','male');
INSERT INTO emp2 VALUES(NULL,'Emerald flower','female');
INSERT INTO emp2 VALUES(NULL,'Yanqiu','female');
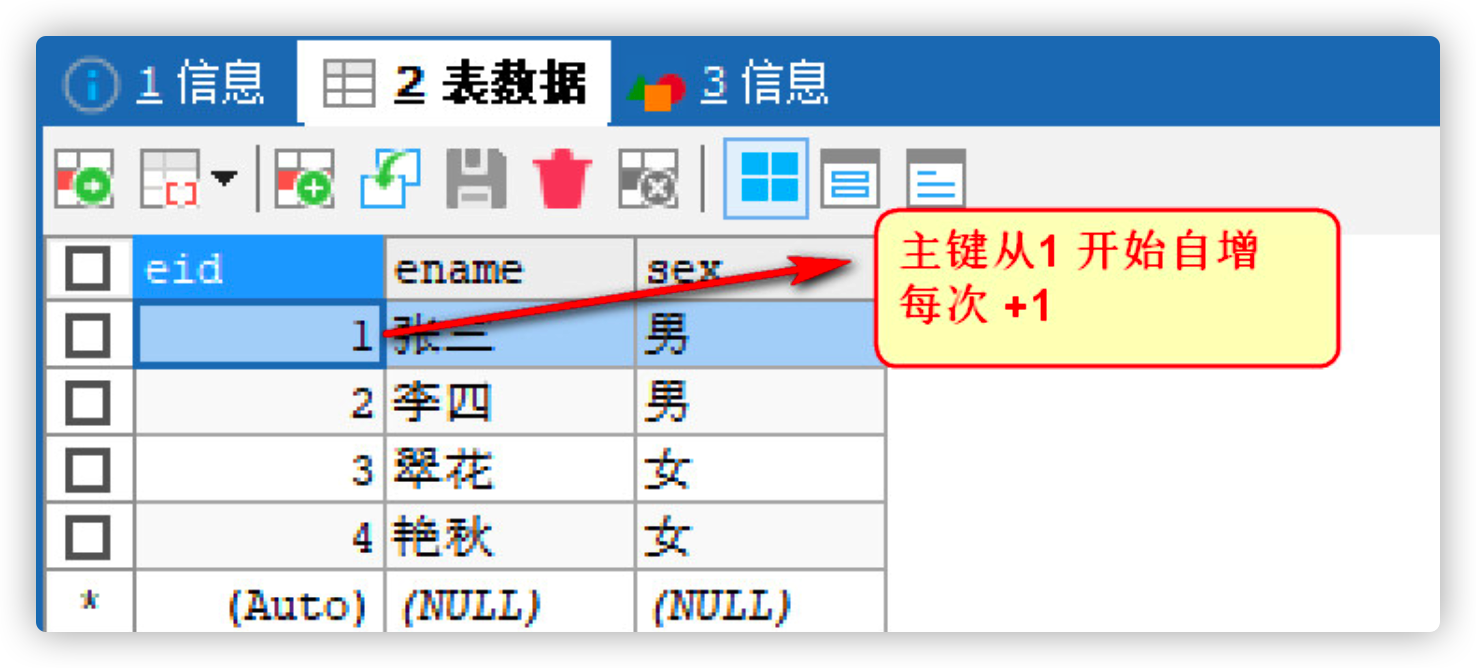
2.1.4 modify the starting value of primary key auto increment
Auto by default_ The starting value of increment is 1. If you want to modify the starting value, please use the following method
-- Create a table with self incrementing primary key,User defined self incrementing real value
CREATE TABLE emp2(
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
sex CHAR(1)
)AUTO_INCREMENT=100;
-- insert data,Observe the starting value of the primary key
INSERT INTO emp2(ename,sex) VALUES('Zhang million','male');
INSERT INTO emp2(ename,sex) VALUES('Yanqiu','female');
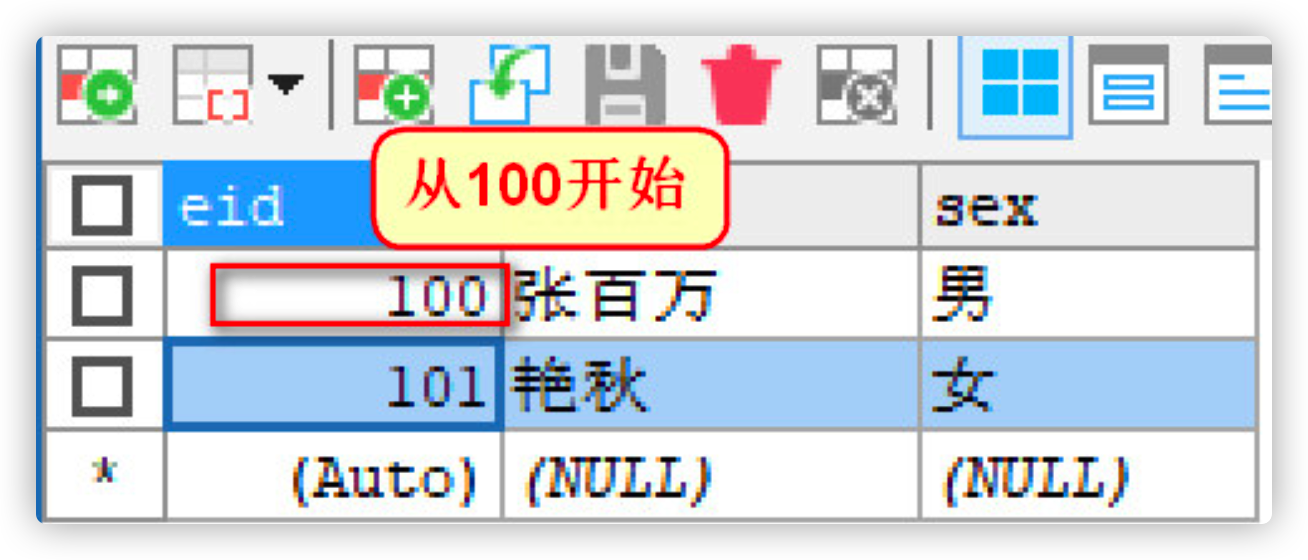
2.1.5 impact of delete and TRUNCATE on self growth
- There are two ways to delete all data in a table
| How to clear table data | characteristic |
|---|---|
| DELETE | It only deletes all data in the table and has no effect on auto increment |
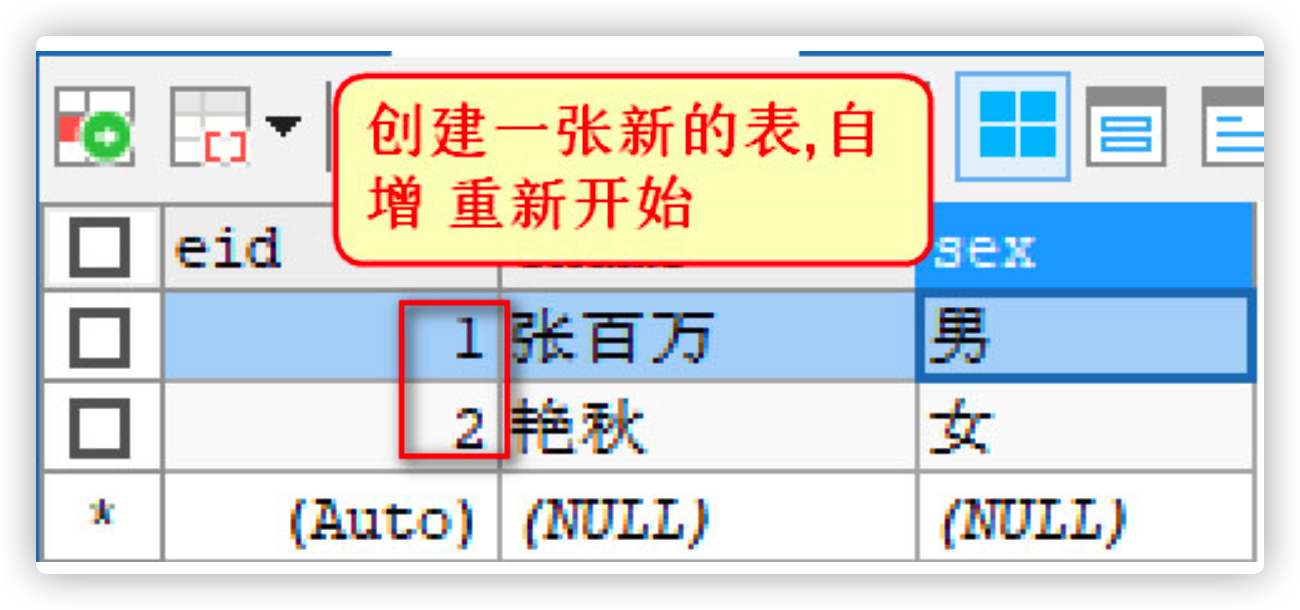
| TRUNCATE | truncate is to delete the entire table, and then create a new self incremented primary key of the table, starting from 1 again |
Test 1: delete delete all data in the table
-- At present, the final primary key value is 101
SELECT * FROM emp2;
-- delete Delete data in table,It has no effect on self increment
DELETE FROM emp2;
-- Insert data view primary key
INSERT INTO emp2(ename,sex) VALUES('Zhang million','male');
INSERT INTO emp2(ename,sex) VALUES('Yanqiu','female');
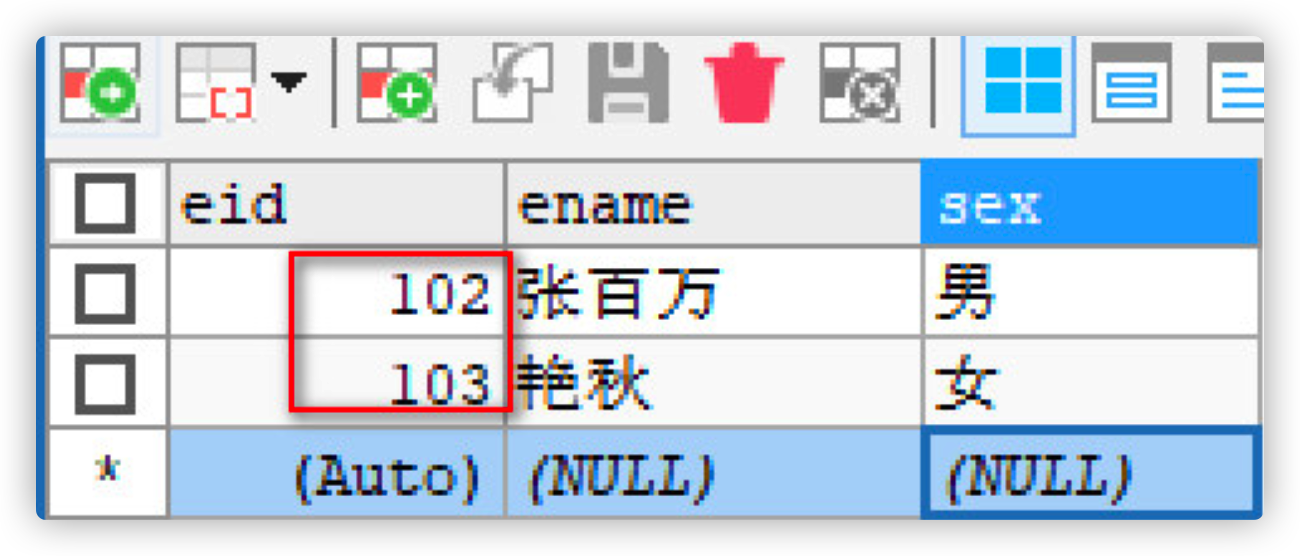
Test 2: truncate delete data in the table
-- use truncate Delete all data in the table,
TRUNCATE TABLE emp2;
-- Insert data view primary key
INSERT INTO emp2(ename,sex) VALUES('Zhang million','male');
INSERT INTO emp2(ename,sex) VALUES('Yanqiu','female');
2.2 non null constraints
Characteristics of non empty constraint: a column cannot be empty
Syntax format
Field name field type not null
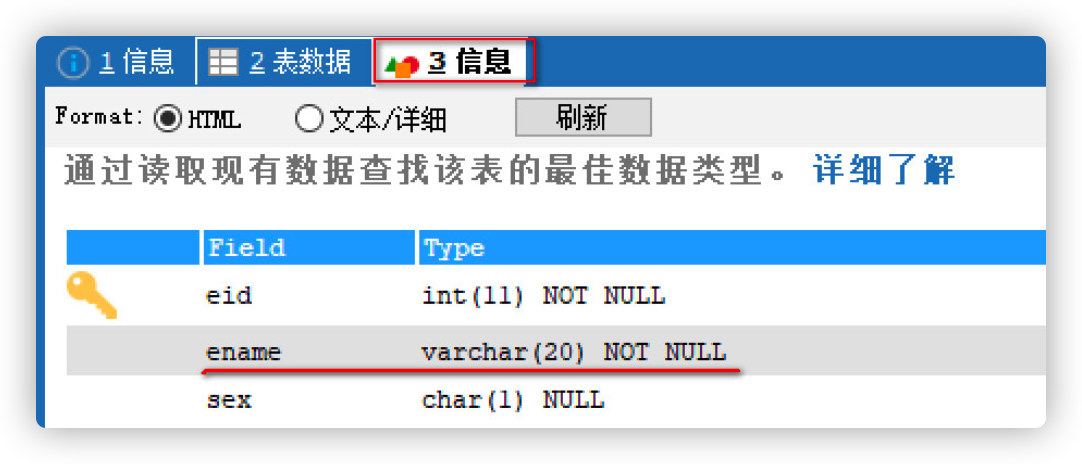
Requirement 1: add a non empty constraint to the ename field
# Non NULL constraint CREATE TABLE emp2( eid INT PRIMARY KEY AUTO_INCREMENT, -- Add non empty constraint, ename Field cannot be empty ename VARCHAR(20) NOT NULL, sex CHAR(1) );
2.3 unique constraints
Unique constraint features: the value of a column in the table cannot be repeated (no unique judgment is made for null)
Syntax format
Field name field type unique
- Add unique constraint
#Create the emp3 table to add unique constraints to the ename field
CREATE TABLE emp3(
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20) UNIQUE,
sex CHAR(1)
);
- Test unique constraints
-- Add a piece of data to the test unique constraint
INSERT INTO emp3 (ename,sex) VALUES('Million Zhang','male');
-- Add a ename Duplicate data
-- Duplicate entry 'Zhang million' for key 'ename' ename Cannot repeat
INSERT INTO emp3 (ename,sex) VALUES('Zhang million','female');
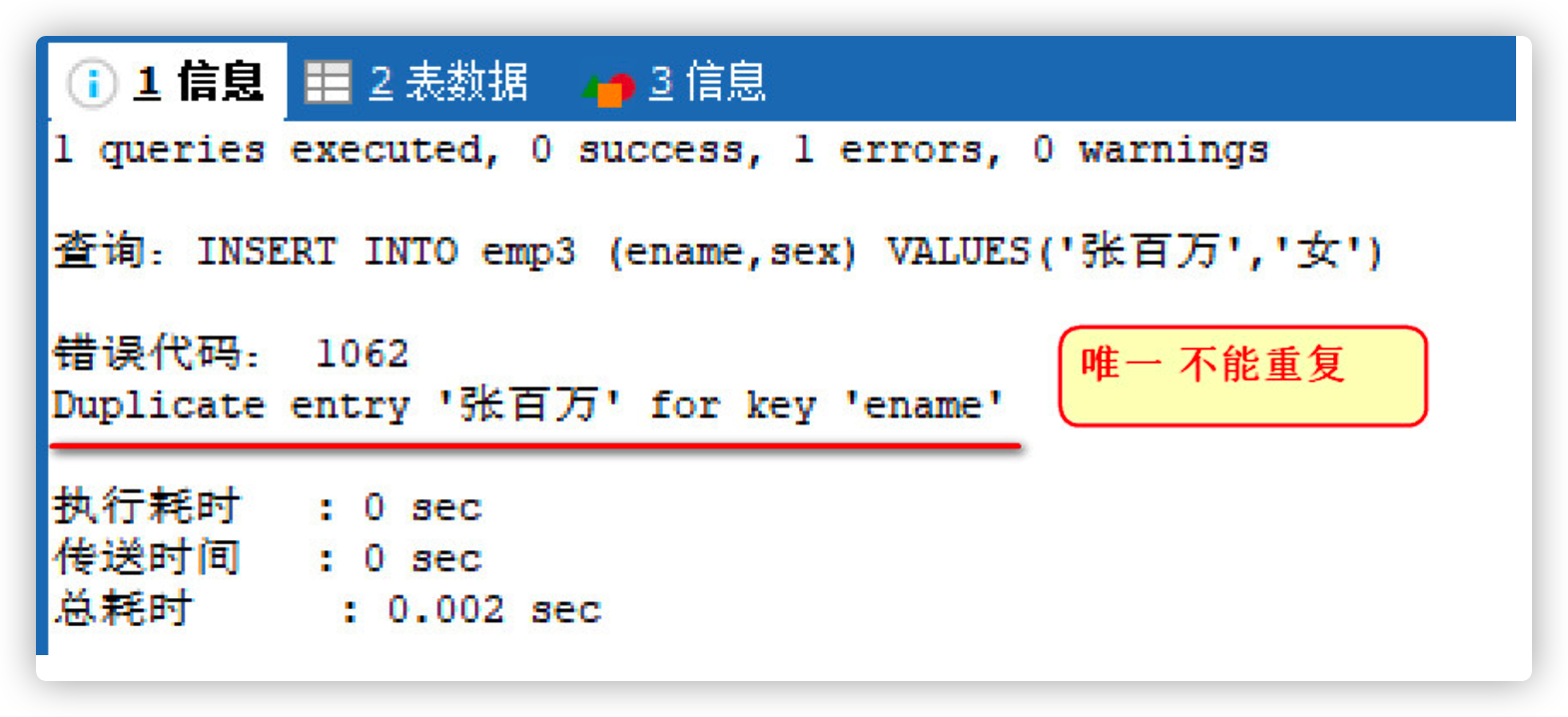
The difference between primary key constraint and unique constraint:
- The primary key constraint is unique and cannot be empty
- Unique constraint, but can be empty
- There can only be one primary key in a table, but there can be multiple unique constraints
2.4 foreign key constraints
FOREIGN KEY indicates the FOREIGN KEY constraint, which will be learned in multiple tables.
2.5 default value
The default value constraint is used to specify the default value of a column
Syntax format
Field name field type DEFAULT Default value
- Create emp4 table, and the gender field defaults to female
-- Create a table with default values CREATE TABLE emp4( eid INT PRIMARY KEY AUTO_INCREMENT, -- by ename Add default values to fields ename VARCHAR(20) DEFAULT 'awesome', sex CHAR(1) );
- Test add data using default values
-- Add data using default values
INSERT INTO emp4(ename,sex) VALUES(DEFAULT,'male');
INSERT INTO emp4(sex) VALUES('female');
-- Do not use default values
INSERT INTO emp4(ename,sex) VALUES('Yanqiu','female');
3. Database transactions
3.1 what is a transaction
The transaction is a whole, which is composed of one or more SQL statements. These SQL statements either execute successfully or fail. As long as one SQL is abnormal, the whole operation will be rolled back and the whole business execution will fail
For example, in the bank transfer business, Zhang San transfers 500 yuan to Li Si. The database must be operated at least twice, Zhang san-500 and Li Si + 500. If there is a problem in any step, the whole operation must be rolled back, so as to ensure that the user and the bank have no loss
- RollBACK
That is, if a fault occurs during the operation of the transaction and the transaction cannot continue to be executed, the system cancels all completed operations on the database in the transaction and rolls back to the state at the beginning of the transaction. (implemented before submission)
3.2 simulated transfer operation
- Create account table
-- Create account table
CREATE TABLE account(
-- Primary key
id INT PRIMARY KEY AUTO_INCREMENT,
-- full name
NAME VARCHAR(10),
-- balance
money DOUBLE
);
-- Add two users
INSERT INTO account (NAME, money) VALUES ('tom', 1000), ('jack', 1000);
- Simulate tom to transfer 500 yuan to jack. At least two statements should be executed for a transfer operation:
-- tom account -500 element UPDATE account SET money = money - 500 WHERE NAME = 'tom'; -- jack account + 500 element UPDATE account SET money = money + 500 WHERE NAME = 'jack';
Note:
Suppose that when the tom account is - 500 yuan, the server crashes. jack's account does not have + 500 yuan, so there is a problem with the data. We need to ensure the integrity of the whole transaction, either successful or failed At this time, we have to learn how to operate transactions
3.3 MySql transaction operation
- There are two ways to perform transaction operations in MYSQL:
- Manually commit transactions
- Auto commit transaction
3.3.1 manually commit transactions
Syntax format
| function | sentence |
|---|---|
| Open transaction | start transaction; Or BEGIN; |
| Commit transaction | commit; |
| Rollback transaction | rollback; |
START TRANSACTION --This statement explicitly marks the starting point of a transaction. COMMIT --Means to commit a transaction, that is, to commit all operations of the transaction. Specifically, --That is, all updates to the database in the transaction are written to the physical database on the disk, and the transaction ends normally. ROLLBACK --It means revoking a transaction, that is, a fault occurs during the operation of the transaction, and the transaction cannot be continued, --The system cancels all completed operations on the database in the transaction and rolls back to the state at the beginning of the transaction
Manually commit transaction flow
- Successful execution: start transaction - > execute multiple SQL statements - > commit transaction successfully
- Execution failure: start transaction - > execute multiple SQL statements - > rollback of transaction
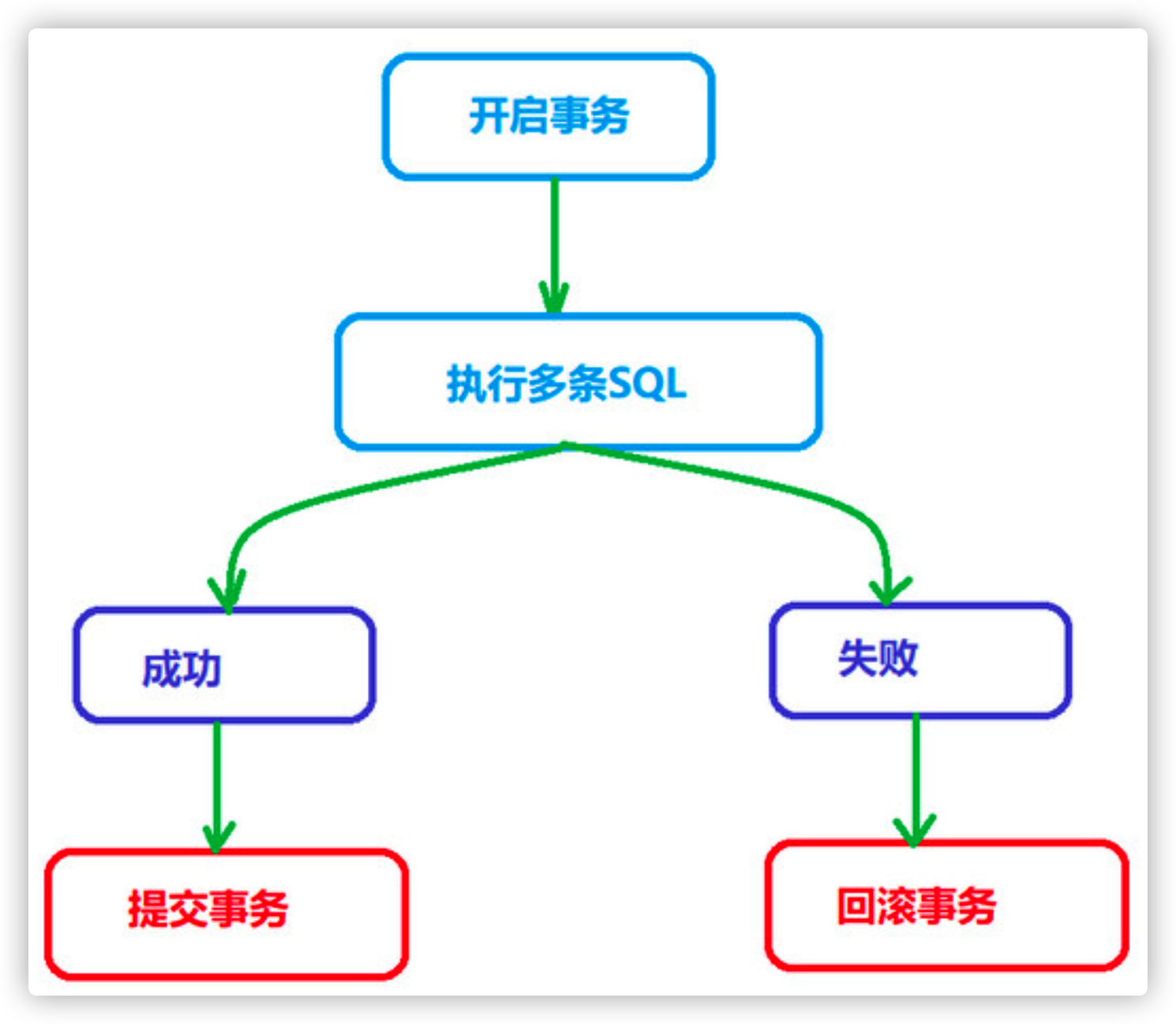
Successful case demonstration
Simulated Zhang San gave Li sizhuan 500 yuan
- Command line login database
- Using db2 database
USE db2;
-
Execute the following SQL
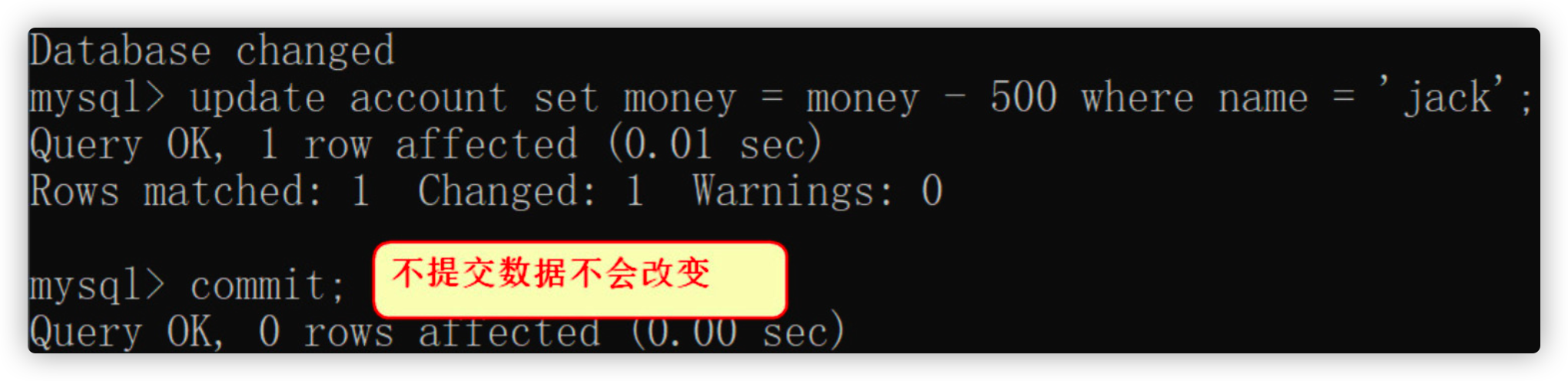
3.1 start transactionstart transaction;

3.2 tom account - 500
update account set money = money - 500 where name = 'tom'

3.3 jack account + 500
update account set money = money + 500 where name = 'jack';

-
At this time, we use sqlYog to view the table and find that the data has not changed
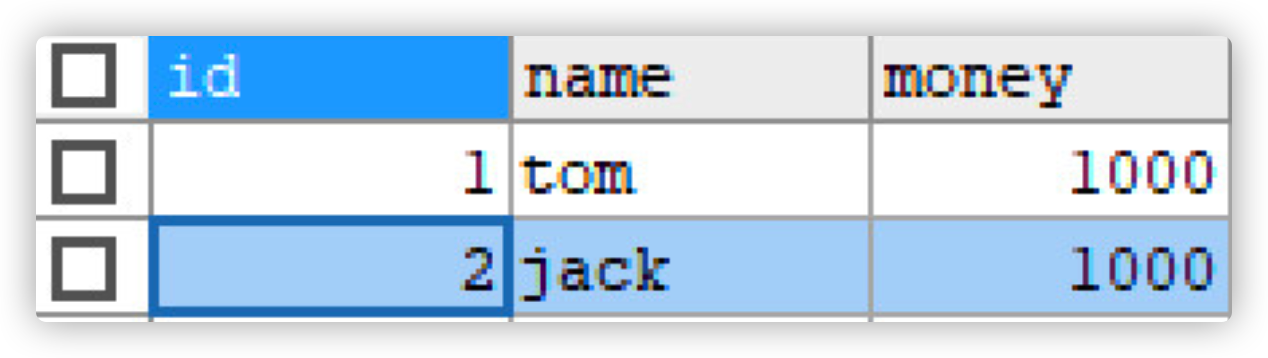
-
Execute the commit transaction on the console
commit;

-
Using sqlYog again, it is found that the data changes after the transaction is committed
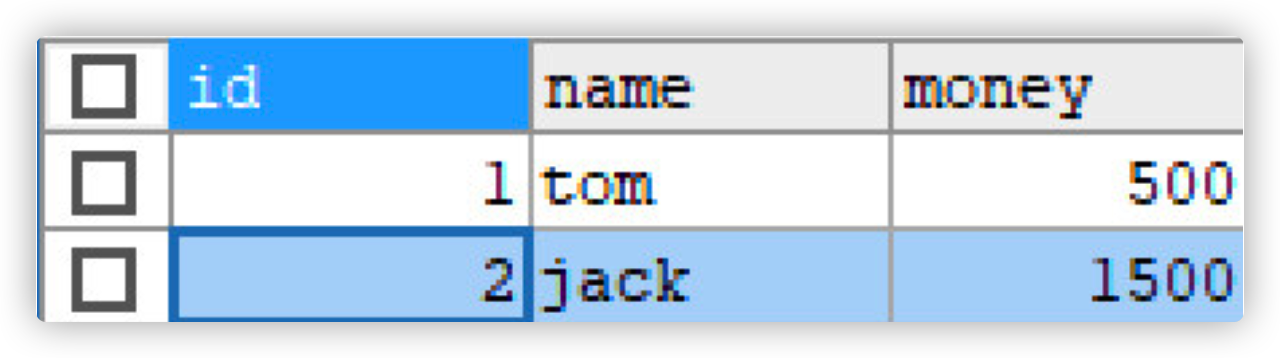
Transaction rollback demo
If there is an error in the execution of an sql statement in the transaction, and we do not have a manual commit, the whole transaction will be rolled back automatically
- Command line start transaction
start transaction;
- Insert two pieces of data
INSERT INTO account VALUES(NULL,'Zhang million',3000); INSERT INTO account VALUES(NULL,'Have money',3500);
- Close the window directly without committing the transaction, rollback occurs, and the data has not changed
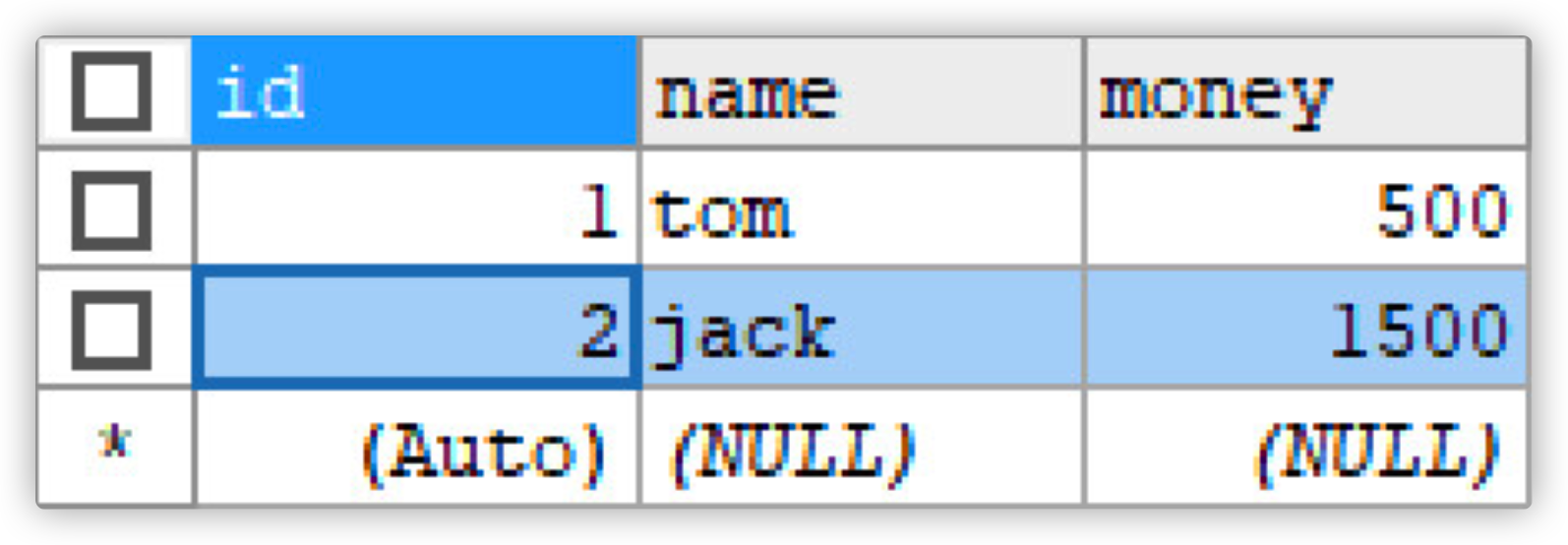
Note:
If there is no problem with the SQL statement in the transaction, commit commits the transaction and changes the data of the database data. If there is a problem with the SQL statement in the transaction, rollback rolls back the transaction and returns to the state when the transaction was started.
3.3.2 auto commit transactions
MySQL defaults that each DML (addition, deletion and modification) statement is a separate transaction. Each statement will automatically start a transaction. After the statement is executed, the transaction will be submitted automatically. MySQL starts to submit the transaction automatically by default
MySQL automatically commits transactions by default
Auto commit transaction demo
- Add tom account amount + 500 yuan

- Using SQLYog to view the database: it is found that the data has changed
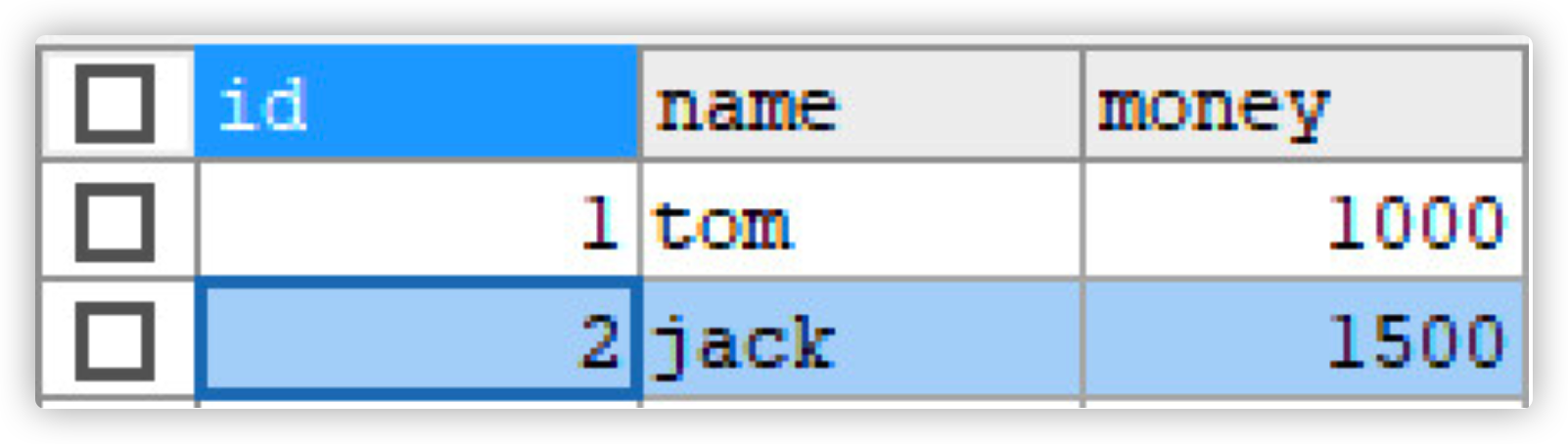
Cancel auto submit
- MySQL commits transactions automatically by default and manually
- Log in to mysql and view the autocommit status.
SHOW VARIABLES LIKE 'autocommit';

on: Auto submit
off: submit manually
-
Change autocommit to off;
SET @@autocommit=off;
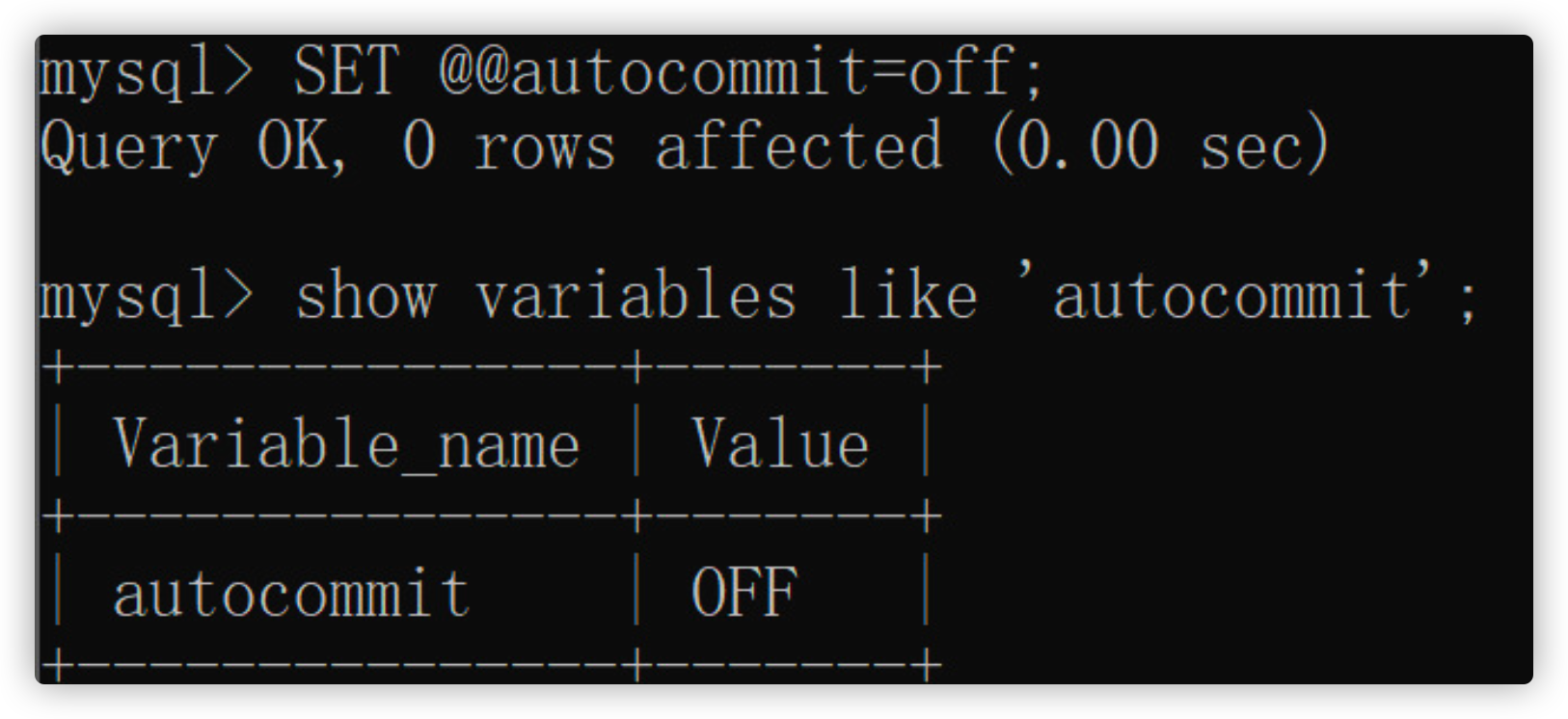
-
The modification again takes effect after submission
The amount of jack account - 500 yuan
-- Select database use db2; -- Modify data update account set money = money - 500 where name = 'jack'; -- Manual submission commit;
3.4 four characteristics of transaction ACID
| features | meaning |
|---|---|
| Atomicity | Each transaction is a whole and cannot be split. All SQL statements in the transaction either succeed or fail. |
| uniformity | The state of the database before transaction execution is consistent with that after transaction execution. For example, the total amount of two persons before the transfer is 2000, and the total amount of two persons after the transfer is also 2000 |
| Isolation | Transactions should not interact with each other and remain isolated during execution |
| persistence | Once the transaction is successfully executed, the modifications to the database are persistent. Even if you shut down, the data should be saved |
3.5 Mysql transaction isolation level (understand)
3.5.1 concurrent data access
A database may have multiple access clients, which can access the database concurrently The same data in the database may be accessed by multiple transactions at the same time. If isolation measures are not taken, it will lead to various problems and destroy the integrity of the data
3.5.2 problems caused by concurrent access
The ideal state of transactions in operation: all transactions remain isolated and do not affect each other. Because of concurrent operations, multiple users access the same data at the same time. Problems that may cause concurrent access
| Concurrent access problem | explain |
|---|---|
| Dirty reading | One transaction read uncommitted data from another transaction |
| Non repeatable reading | The content of data read twice in a transaction is inconsistent, which requires that the data read multiple times in a transaction is consistent This is a problem caused by the update operation |
| Unreal reading | In a transaction, the data state represented by the result of a select operation cannot support subsequent business operations The data status obtained by query is inaccurate, resulting in unreal reading |
3.5.3 four isolation levels
By setting the isolation level, the above three concurrency problems can be prevented MySQL database has four isolation levels, the lowest level above and the highest level below.
- ✔ There will be problems
- ✘ no problem
| level | name | Isolation level | Dirty reading | Non repeatable reading | Unreal reading | Default isolation level of database |
|---|---|---|---|---|---|---|
| 1 | Read uncommitted | read uncommitted | ✔️ | ✔️ | ✔️ | |
| 2 | Read committed | read committed | ✘ | ✔️ | ✔️ | Oracle and SQL Server |
| 3 | Repeatable reading | repeatable read | ✘ | ✘ | ✔️ | MySQL |
| 4 | Serialization | serializable | ✘ | ✘ | ✘ |
3.5.4 commands related to isolation level
- View isolation level
select @@tx_isolation;
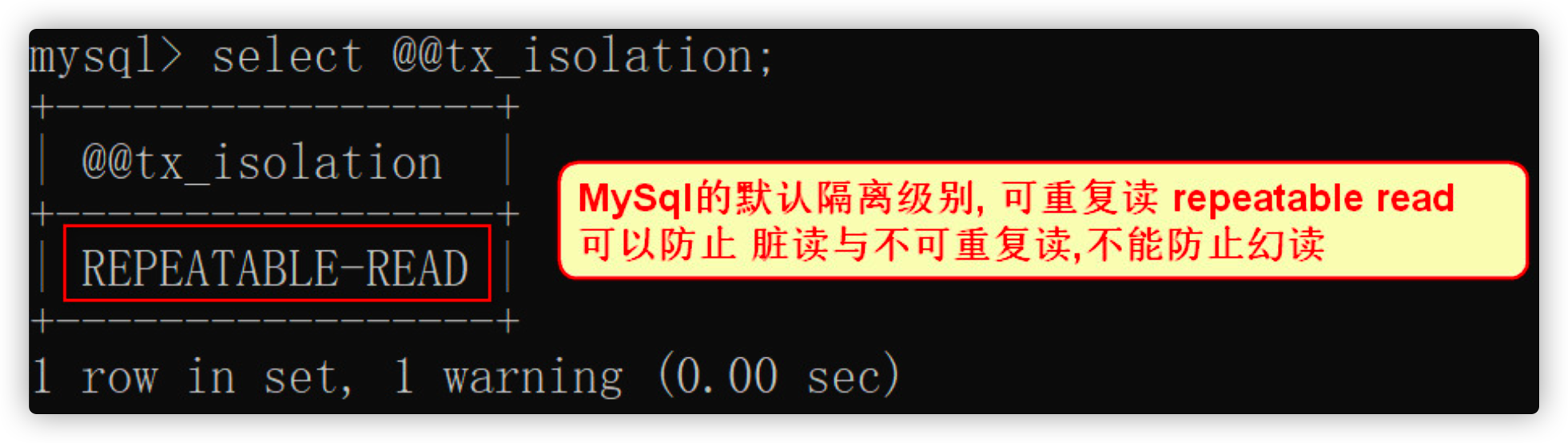
- To set the transaction isolation level, you need to exit MySQL and log in again to see the change of the isolation level
For example, change the isolation level to read uncommittedset global transaction isolation level Level name; read uncommitted Read uncommitted read committed Read committed repeatable read Repeatable reading serializable Serialization
set global transaction isolation level read uncommitted;
3.6 isolation problem demonstration
3.6.1 dirty reading demonstration
Dirty read: one transaction reads uncommitted data from another transaction
a. Open a window to log in to MySQL and set the global isolation level to the lowest
- Login is MySQL
- Using db2 database
use db2;
- Set the isolation level to minimum read uncommitted
set global transaction isolation level read uncommitted;

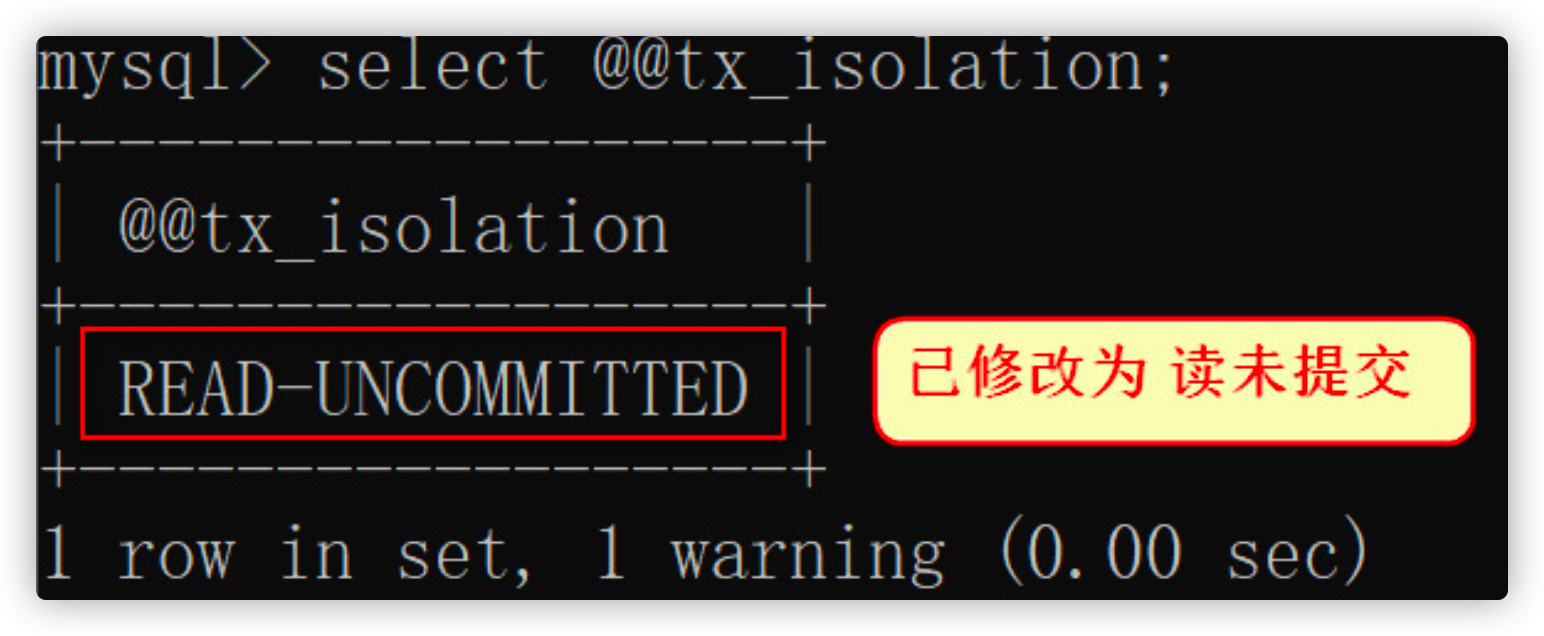
b. Close the window, open A new window A, and query the isolation level again
- Open new window A
- Query isolation level
select @@tx_isolation;
c. Open a new window B
- Login database
- Select database
use db2;
- Open transaction
start transaction;
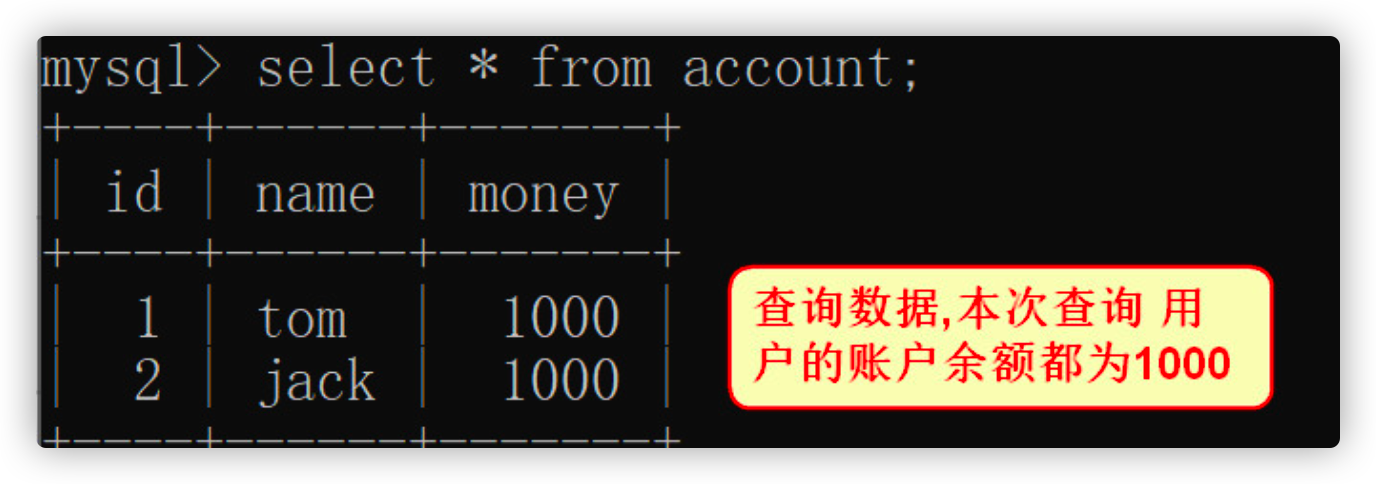
- query
select * from account;
d. A window execution
- Select database
use db2;
- Open transaction
start transaction;

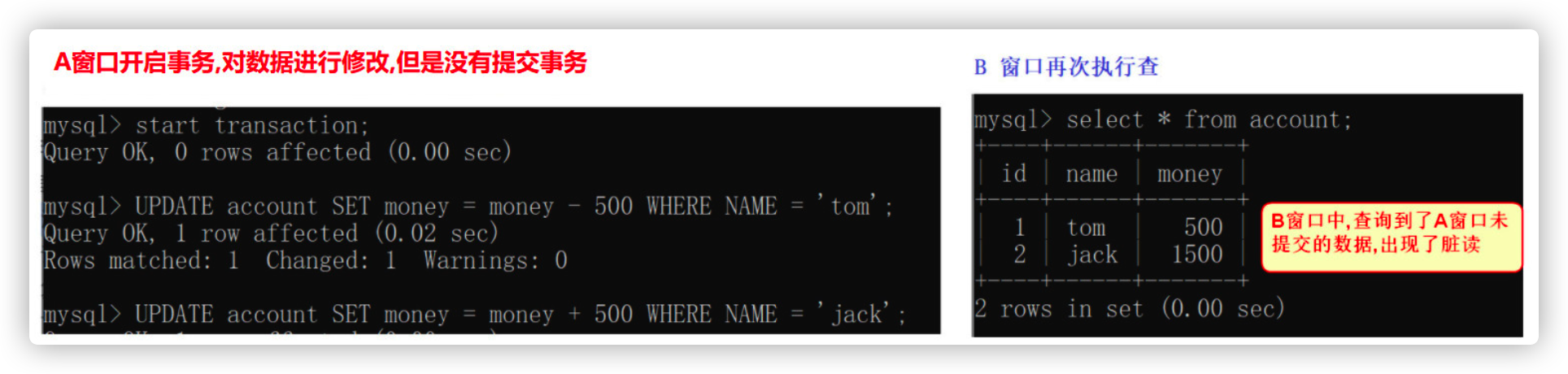
- Perform modification
-- tom account -500 element UPDATE account SET money = money - 500 WHERE NAME = 'tom'; -- jack account + 500 element UPDATE account SET money = money + 500 WHERE NAME = 'jack';
e. B window query data
- Query account information
select * from account;
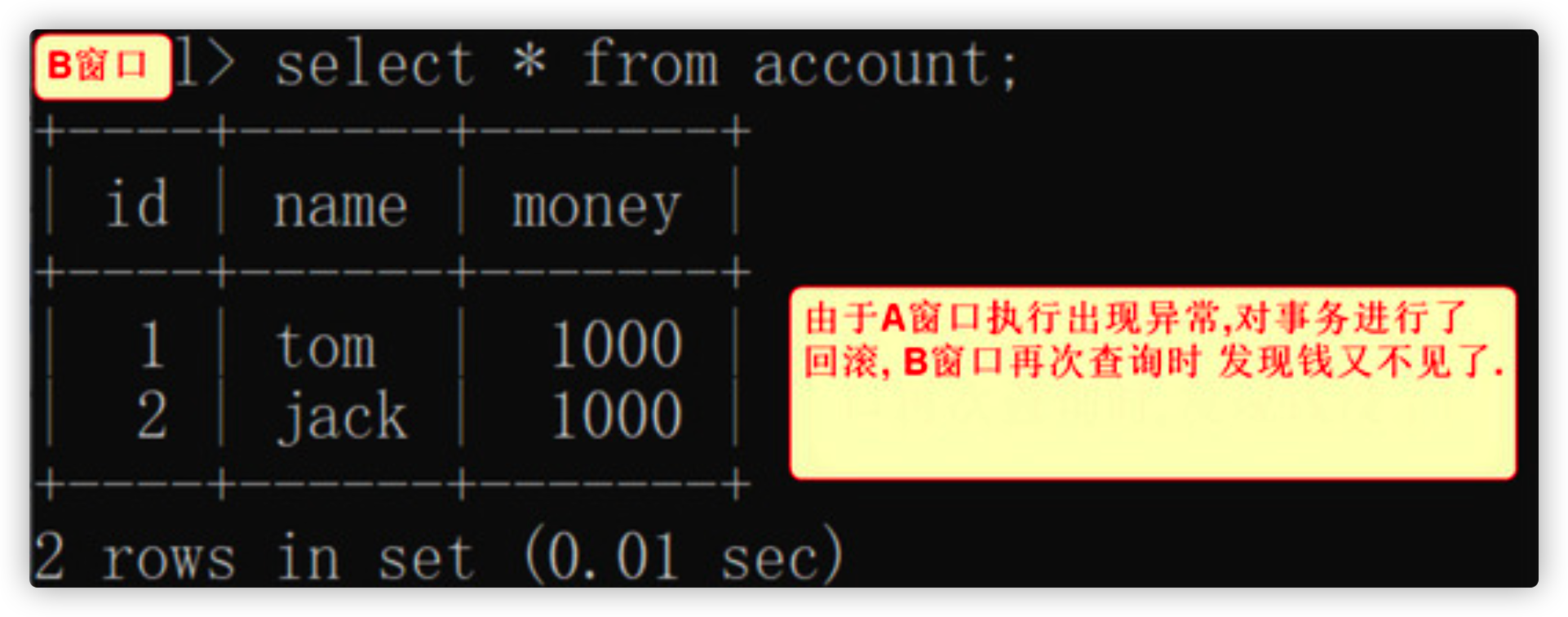
f. Transfer exception in window A, rollback
rollback;

g. Query the account again in window B
select * from account;
3.6.2 solving dirty reading problems
- Dirty reading is very dangerous. For example, when Zhang San buys goods from Li Si, Zhang San opens the business, transfers 500 yuan to Li Si's account, and then calls Li Si to say that the money has been transferred. Li Siyi inquired that the money had arrived and delivered it to Zhang San. Zhang San rolls back the transaction after receiving the goods, and Li Si's checks that the money is gone.
- Solution
- Raise the global isolation level to read committed
- Set the global isolation level to read committed in window A
set global transaction isolation level read committed;
- Reopen window A to check whether the setting is successful
select @@tx_isolation;
- Open window B. after selecting the database in windows A and B, start the transaction
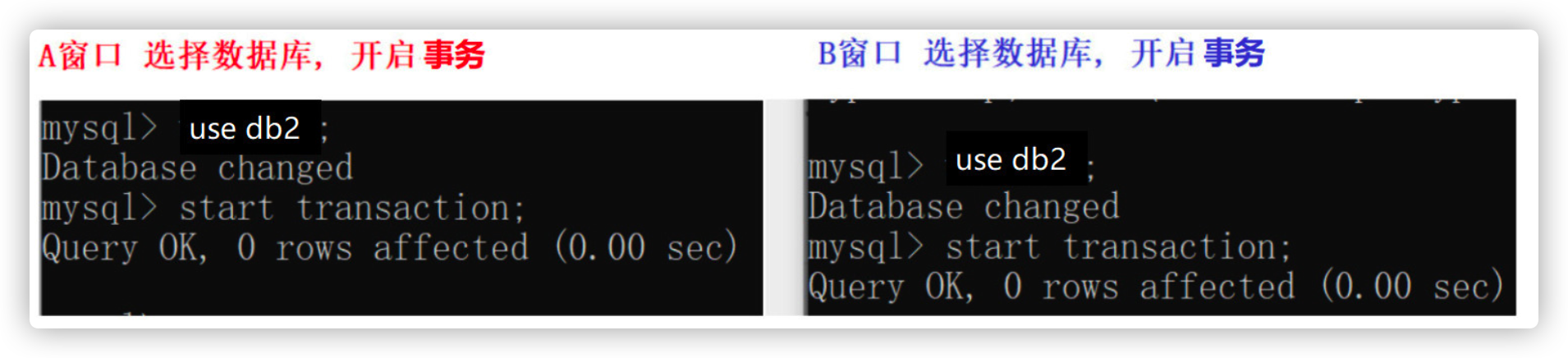
- Window A only updates the accounts of two people and does not submit transactions
-- tom account -500 element UPDATE account SET money = money - 500 WHERE NAME = 'tom'; -- jack account + 500 element UPDATE account SET money = money + 500 WHERE NAME = 'jack';
- No uncommitted data was found in window B
mysqlselect * from account;

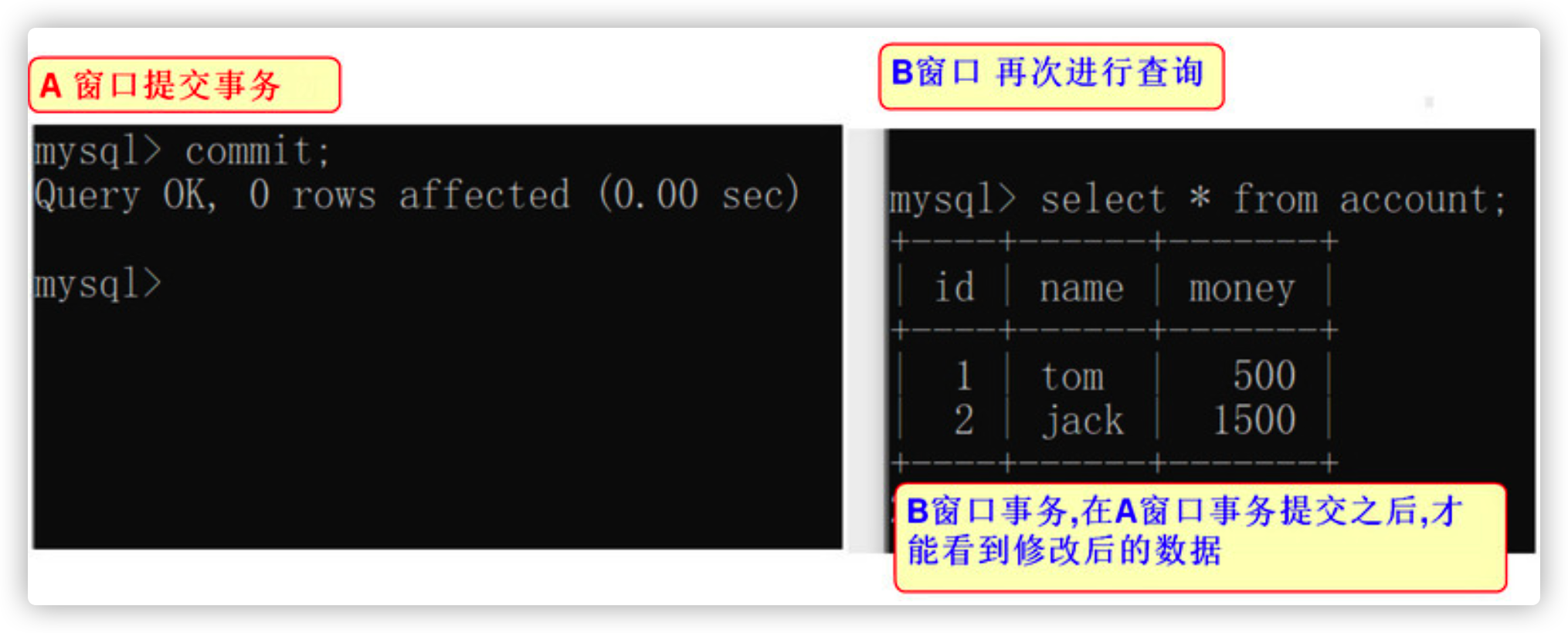
- A window commit submit data
commit;
- View data in window B
select * from account;
3.6.3 non repeatable presentation
Non repeatable reading: in the same transaction, the query operation is performed, but the data content read each time is different
-
Recover data (change data back to initial state)
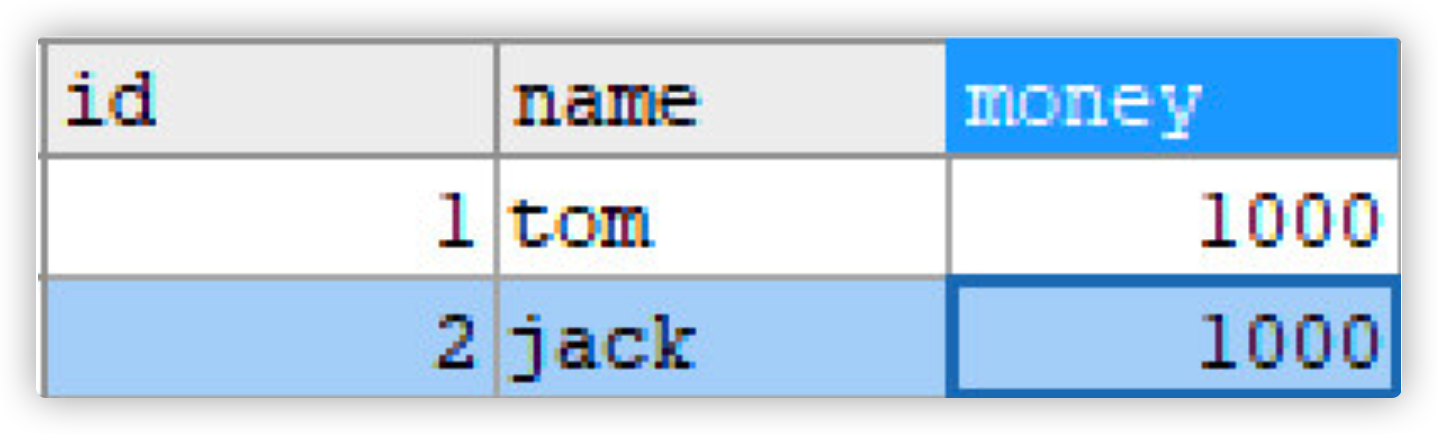
-
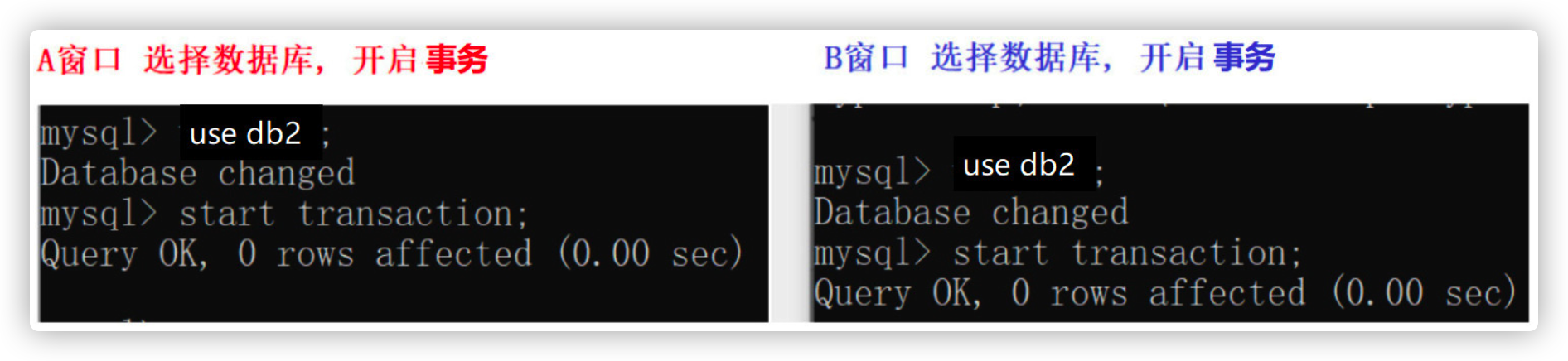
Open two windows A and B, select the database and start the transaction
use db2; start transaction;
-
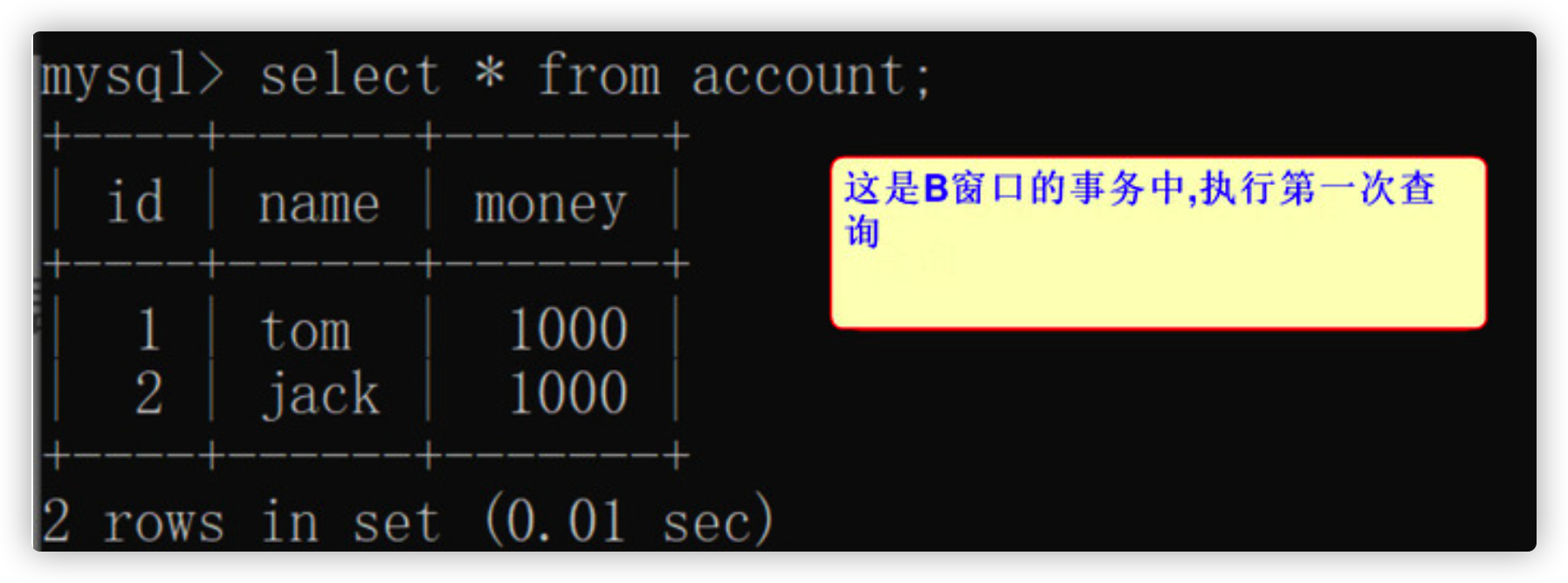
After the transaction is opened in window B, perform a data query first
select * from account;
-
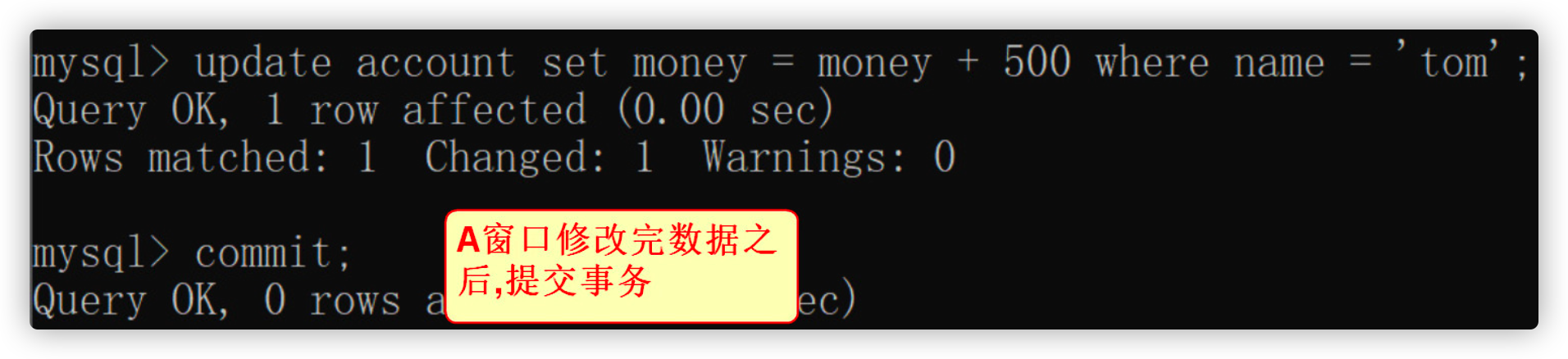
After opening the transaction in window A, add the account of user tom + 500, and then submit the transaction
-- Modify data update account set money = money + 500 where name = 'tom'; -- Commit transaction commit;
-
Query data again in window B
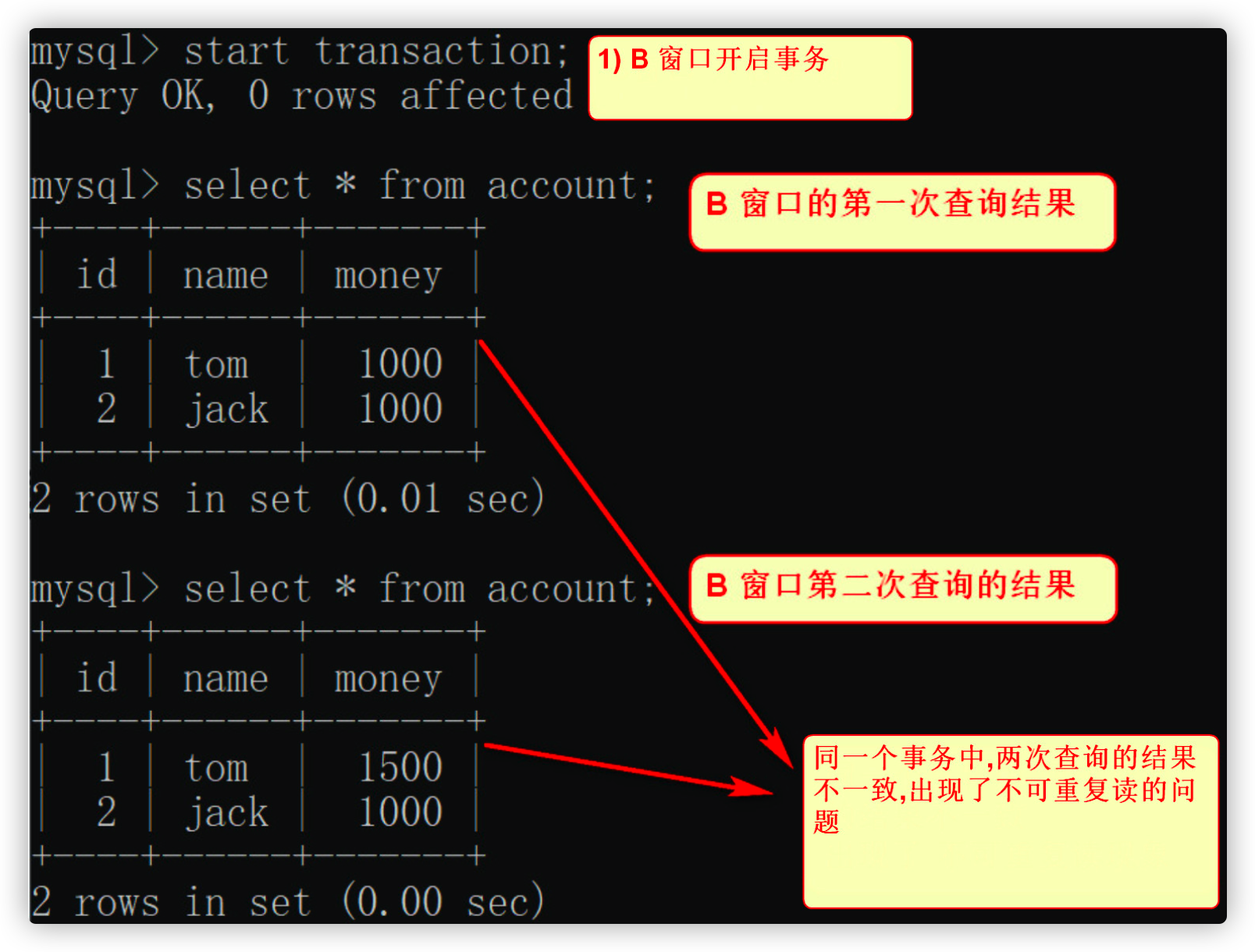
- The results of the two queries are different. Which one is right?
- I don't know which one will prevail. Many people think that this situation is right. There is no need to be confused. Of course, the latter shall prevail. We can consider such a situation:
For example, the bank program needs to output the query results to the computer screen and send text messages to customers respectively. The results are inconsistent in two queries for different output destinations in a transaction, resulting in inconsistent results in the file and screen, and the bank staff don't know which one should prevail
- I don't know which one will prevail. Many people think that this situation is right. There is no need to be confused. Of course, the latter shall prevail. We can consider such a situation:
3.6.4 solve the problem of non repeatable reading
- Raise the global isolation level to repeatable read
- Recover data
UPDATE account SET money = 1000
- Open window A and set the isolation level to repeatable read
-- View transaction isolation level select @@tx_isolation; -- Set the transaction isolation level to repeatable read set global transaction isolation level repeatable read;

- Reopen windows a and B, select the database, and start the transaction at the same time
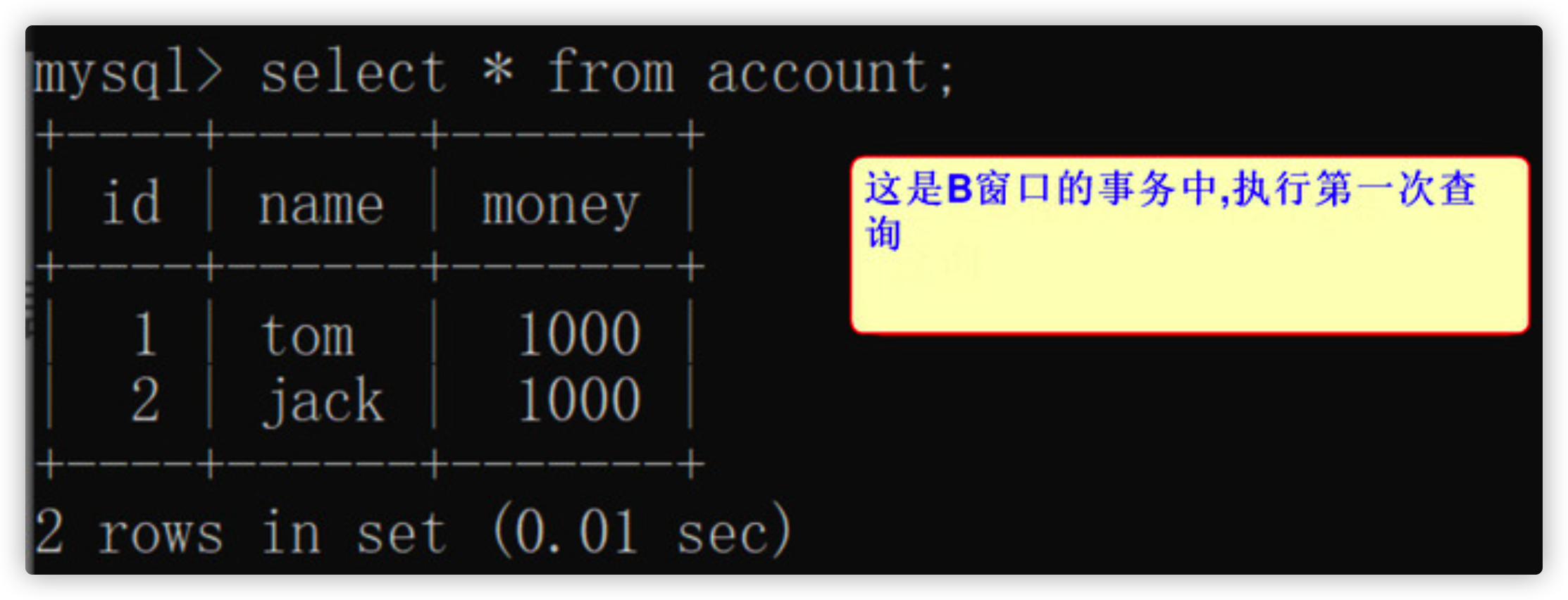
- First query window B
select * from account;
- A window updates the data and then commits the transaction
-- Modify data update account set money = money + 500 where name = 'tom'; -- Commit transaction commit;
- Query again in window B
select * from account;

- In order to ensure the consistency of multiple query data in the same transaction, the repeatable read isolation level must be used
3.6.5 unreal reading demonstration
Unreal reading: select whether a record exists or not. If it does not exist, it is ready to insert the record. However, when executing insert, it is found that the record already exists and cannot be inserted. At this time, unreal reading occurs.
- Open the A / b window and select the database to start the transaction
- Window A performs A query operation first
-- Suppose you want to add another one id Data for 3,Before adding, judge whether it exists select * from account where id = 3;

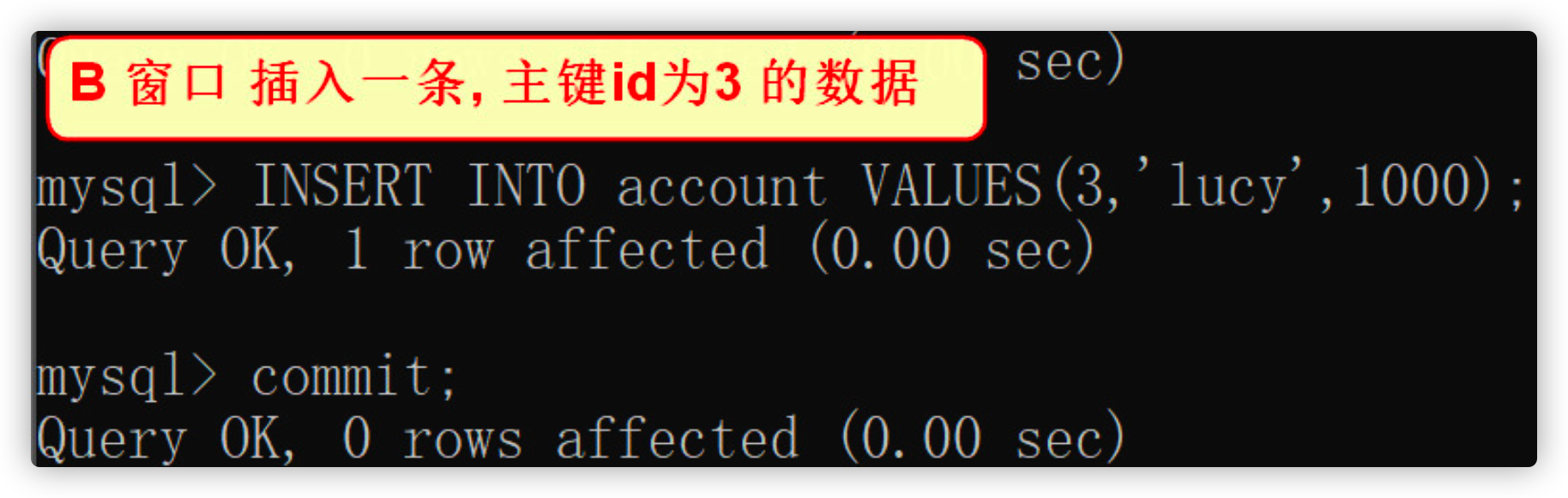
- Insert a data submission transaction in window B
INSERT INTO account VALUES(3,'lucy',1000); commit;
- An error is found when inserting window A Appear unreal reading

Damn it, the results I just read should support my operation. Why not now
3.6.6 solving unreal reading problems
- Set the transaction isolation level to the highest SERIALIZABLE to block unreal reads
If a transaction uses SERIALIZABLE - SERIALIZABLE isolation level, before the transaction is committed, other threads can only wait until the current operation is completed. This will be very time-consuming and affect the performance of the database. The database will not use this isolation level
- Recover data
DELETE FROM account WHERE id = 3;
- Open window A to raise the data isolation level to the highest level
set global transaction isolation level SERIALIZABLE;

- Open a / b window and select database to start transaction
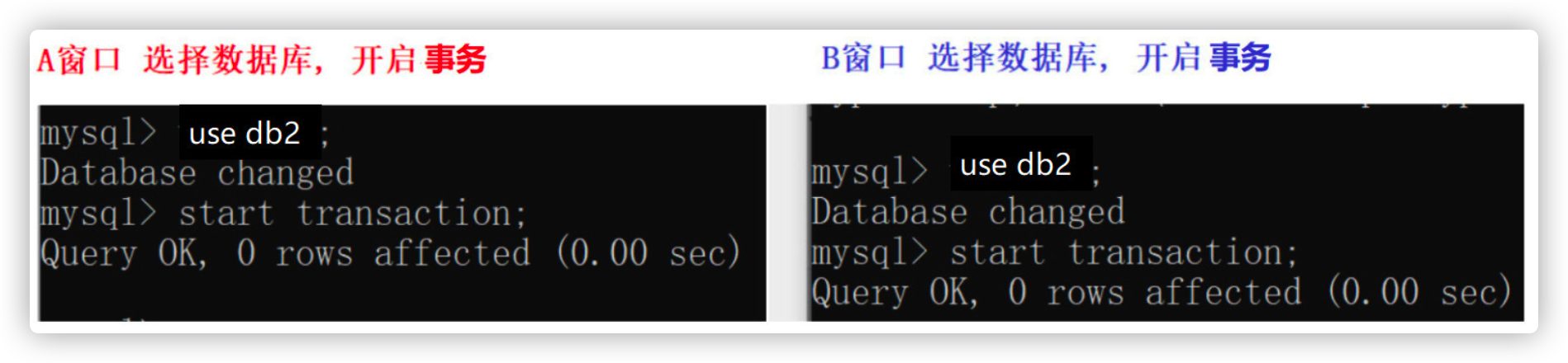
- Window A performs A query operation first
SELECT * FROM account WHERE id = 3;
- Insert a piece of data in window B
INSERT INTO account VALUES(3,'lucy',1000);

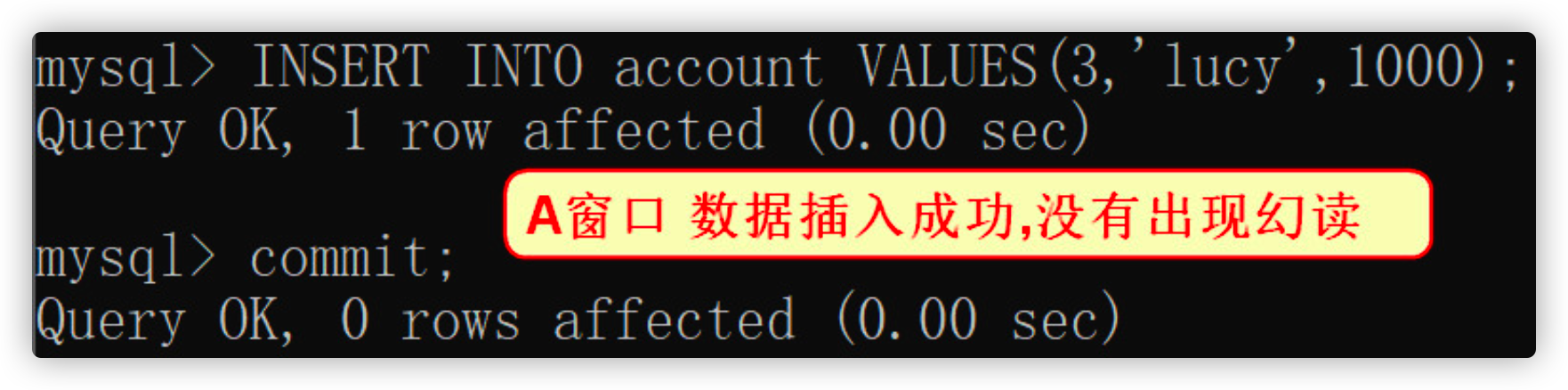
- A window executes the insert operation, and the commit transaction data is inserted successfully
INSERT INTO account VALUES(3,'lucy',1000); commit;
- Window B executes the transaction after window A commits the transaction, but the primary key conflicts and an error occurs

Summary:
serializable serialization can completely solve unreal reading, but transactions can only be queued for execution, which seriously affects the efficiency. The database will not use this isolation level