1. Multi meter
1.1 multi table description
In actual development, a project usually needs many tables to complete.
For example, the database of a mall project needs many tables: user table, classification table, commodity table, order table
1.2 disadvantages of single meter
1.2.1 data preparation
- Create a database db3
CREATE DATABASE db3 CHARACTER SET utf8;
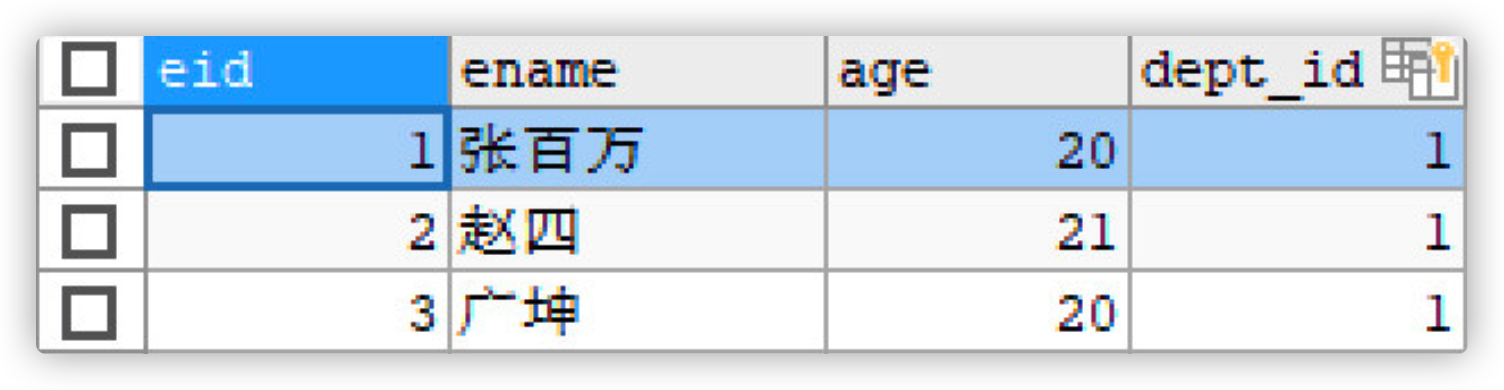
- Create an employee table emp in the database,
- Include the following Eid, ename, age and Dep_ name, dep_ location
- eid is the primary key and grows automatically. Add 5 pieces of data
-- establish emp Table primary key auto increment CREATE TABLE emp( eid INT PRIMARY KEY AUTO_INCREMENT, ename VARCHAR(20), age INT , dep_name VARCHAR(20), dep_location VARCHAR(20) ); -- Add data INSERT INTO emp (ename, age, dep_name, dep_location) VALUES ('Zhang million', 20, 'R & D department', 'Guangzhou'); INSERT INTO emp (ename, age, dep_name, dep_location) VALUES ('Zhao Si', 21, 'R & D department', 'Guangzhou'); INSERT INTO emp (ename, age, dep_name, dep_location) VALUES ('Guangkun', 20, 'R & D department', 'Guangzhou'); INSERT INTO emp (ename, age, dep_name, dep_location) VALUES ('Xiao bin', 20, 'Sales Department', 'Shenzhen'); INSERT INTO emp (ename, age, dep_name, dep_location) VALUES ('Yanqiu', 22, 'Sales Department', 'Shenzhen'); INSERT INTO emp (ename, age, dep_name, dep_location) VALUES ('Da Lingzi', 18, 'Sales Department', 'Shenzhen');
1.2.2 single table problems
- Redundancy, a large number of duplicate data in the same field
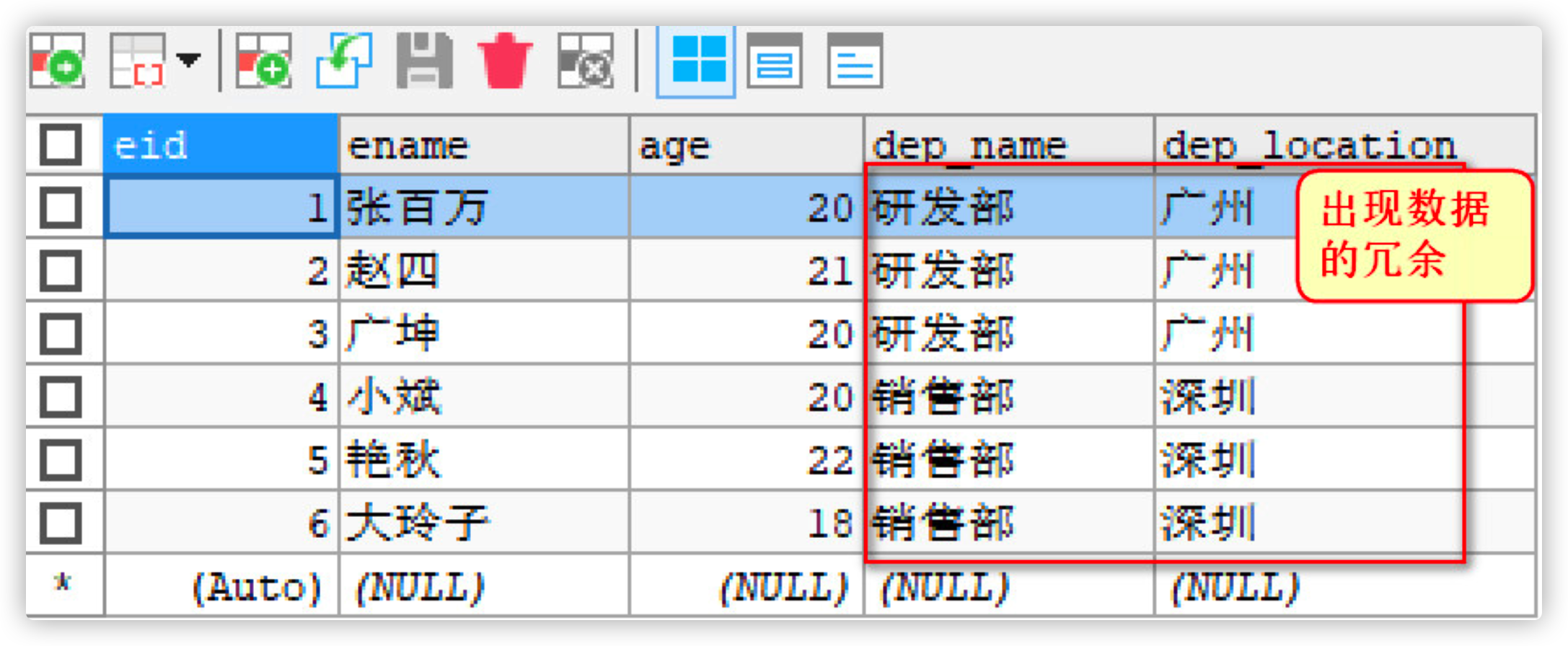
1.3 solutions
1.3.1 two tables are designed
- Multi table design
department table: id, dep_name, dep_location employee
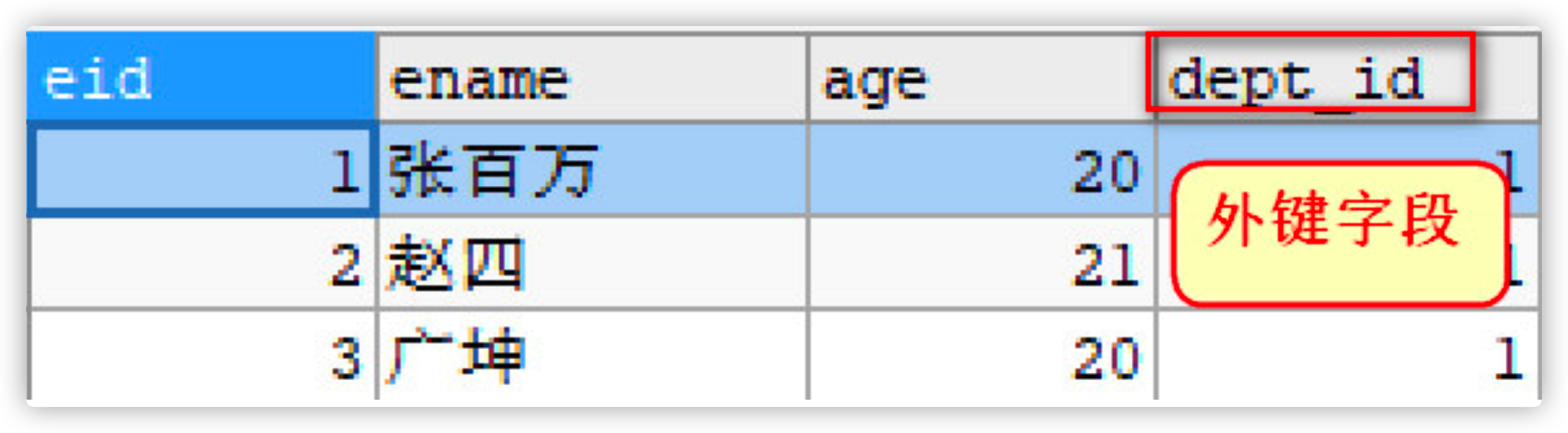
Employee table: eid, ename, age, dep_id - Delete the emp table and recreate two tables
-- Create department table -- a party,Main table CREATE TABLE department( id INT PRIMARY KEY AUTO_INCREMENT, dep_name VARCHAR(30), dep_location VARCHAR(30) ); -- Create employee table -- Many parties ,From table CREATE TABLE employee( eid INT PRIMARY KEY AUTO_INCREMENT, ename VARCHAR(20), age INT, dept_id INT ); - Add department table data
-- Add 2 departments INSERT INTO department VALUES(NULL, 'R & D department','Guangzhou'),(NULL, 'Sales Department', 'Shenzhen'); SELECT * FROM department;
- Add employee table data
-- Add employee,dep_id Indicates the Department of the employee INSERT INTO employee (ename, age, dept_id) VALUES ('Zhang million', 20, 1); INSERT INTO employee (ename, age, dept_id) VALUES ('Zhao Si', 21, 1); INSERT INTO employee (ename, age, dept_id) VALUES ('Guangkun', 20, 1); INSERT INTO employee (ename, age, dept_id) VALUES ('Xiao bin', 20, 2); INSERT INTO employee (ename, age, dept_id) VALUES ('Yanqiu', 22, 2); INSERT INTO employee (ename, age, dept_id) VALUES ('Da Lingzi', 18, 2); SELECT * FROM employee;
Table 1.3.2 relationship analysis
- Relationship between department table and employee table

- There is a field dept in the employee table_ ID corresponds to the primary key in the Department table. This field in the employee table is called a foreign key
- The employee table with foreign keys is called the slave table, and the table with the primary key corresponding to the foreign key is called the master table
1.3.3 problems in multi meter design
- When we are in Dept of employee table_ If you enter a nonexistent Department id in the id, the data can still be added. Obviously, this is unreasonable
-- Insert a piece of data without Department INSERT INTO employee (ename,age,dept_id) VALUES('unknown',35,3);
- In fact, we should ensure that the dept added to the employee table_ ID, which must exist in the Department table
Solution:
- Using foreign key constraints, constrain dept_id, which must be the id existing in the Department table
1.4 foreign key constraints
1.4.1 what is a foreign key
- Foreign key refers to the field in the slave table corresponding to the primary key of the primary table, such as dept in the employee table_ ID is the foreign key
- Using foreign key constraints can generate a corresponding relationship between two tables, so as to ensure the integrity of the reference of the master-slave table
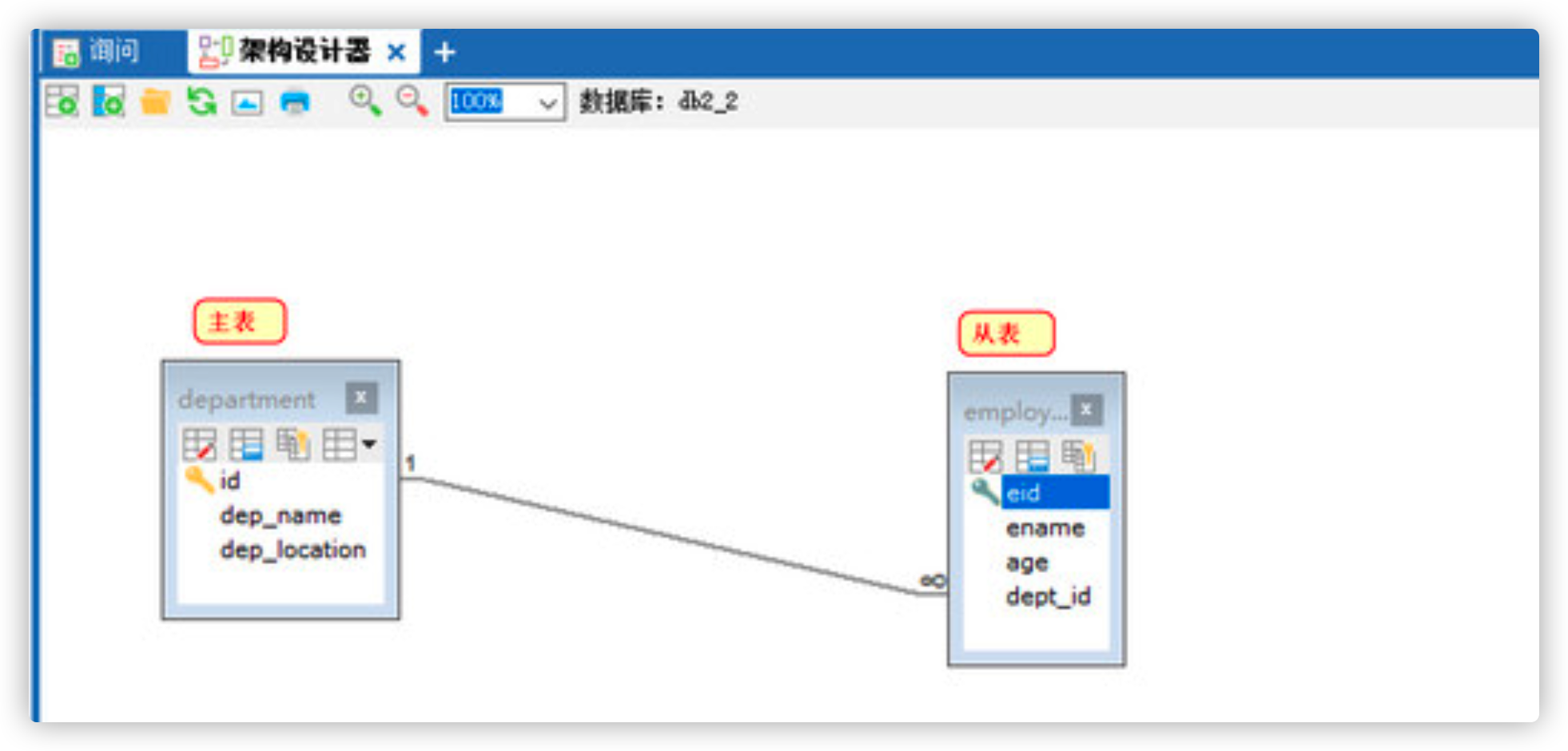
- Master and slave tables in multi table relationships
- Primary table: the table where the primary key id is located. It is a table that restricts others
- Slave table: there are many tables with foreign keys, and the tables are constrained

1.4.2 creating foreign key constraints
Syntax format:
- Add foreign keys when creating a new table
[CONSTRAINT] [Foreign key constraint name] FOREIGN KEY(Foreign key field name) REFERENCES Main table name(Primary key field name)
- Add foreign key to existing table
ALTER TABLE From table ADD [CONSTRAINT] [Foreign key constraint name] FOREIGN KEY (Foreign key field name) REFERENCES Main table(Primary key field name);
a. Re create the employee table and add foreign key constraints
-- Delete first employee surface
DROP TABLE employee;
-- Recreate employee surface,Add foreign key constraint
CREATE TABLE employee(
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
age INT,
dept_id INT,
-- Add foreign key constraint
CONSTRAINT emp_dept_fk FOREIGN KEY(dept_id) REFERENCES department(id)
);
b. Insert data
-- Add data normally (The foreign key of the slave table corresponds to the primary table primary key)
INSERT INTO employee (ename, age,dept_id) VALUES ('Zhang million', 20, 1);
INSERT INTO employee (ename, age,dept_id) VALUES ('Zhao Si', 21, 1);
INSERT INTO employee (ename, age,dept_id) VALUES ('Guangkun', 20, 1);
INSERT INTO employee (ename, age,dept_id) VALUES ('Xiao bin', 20, 2);
INSERT INTO employee (ename, age,dept_id) VALUES ('Yanqiu', 22, 2);
INSERT INTO employee (ename, age,dept_id) VALUES ('Da Lingzi', 18, 2);
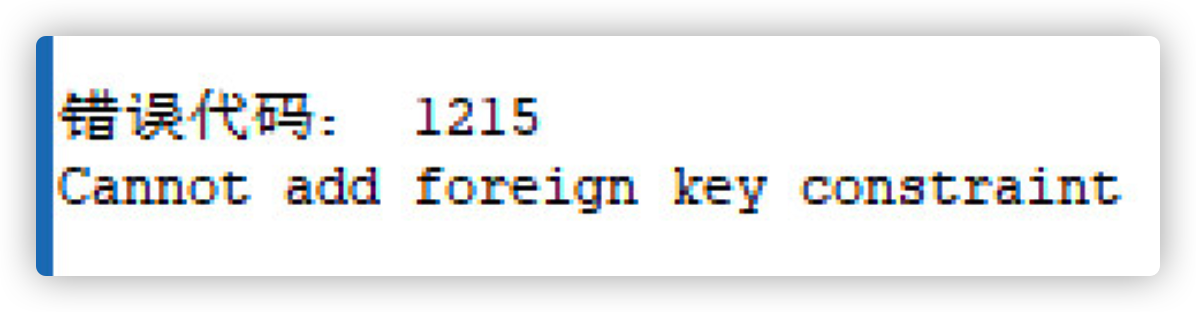
-- Insert a piece of problematic data (department id non-existent)
-- Cannot add or update a child row: a foreign key constraint fails
INSERT INTO employee (ename, age, dept_id) VALUES ('error', 18, 3);
- Adding foreign key constraints will produce mandatory foreign key data inspection, so as to ensure the integrity and consistency of data,
1.4.3 delete foreign key constraint
Syntax format
alter table From table drop foreign key Foreign key constraint name
Delete foreign key constraint
-- delete employee Foreign key constraints in tables,Foreign key constraint name emp_dept_fk ALTER TABLE employee DROP FOREIGN KEY emp_dept_fk;
Then add the foreign key back
Syntax format
ALTER TABLE From table ADD [CONSTRAINT] [Foreign key constraint name] FOREIGN KEY (Foreign key field name) REFERENCES Main table(Primary key field name); -- Foreign key names can be omitted, The system will automatically generate a ALTER TABLE employee ADD FOREIGN KEY (dept_id) REFERENCES department (id);
1.4.4 precautions for foreign key constraints
- The foreign key type of the slave table must be consistent with the primary key type of the primary table, otherwise the creation fails
- When adding data, you should first add the data in the main table
-- Add a new Department INSERT INTO department(dep_name,dep_location) VALUES('Marketing Department','Beijing'); -- Add an employee who belongs to the marketing department INSERT INTO employee(ename,age,dept_id) VALUES('Lao Hu',24,3); - When deleting data, you should first delete the data from the table
-- When deleting data, you should first delete the data from the table -- report errors Cannot delete or update a parent row: a foreign key constraint fails -- Reason for error reporting: this data in the main table cannot be deleted,Because there is a reference to this data in the slave table DELETE FROM department WHERE id = 3; -- Delete the associated data from the table first DELETE FROM employee WHERE dept_id = 3; -- Then delete the data of the main table DELETE FROM department WHERE id = 3;
1.4.5 cascade deletion (understand)
If you want to delete the data of the primary table as well as the data of the secondary table, you can use cascade deletion
cascading deletion ON DELETE CASCADE
- Delete the employee table, recreate it, add it, and delete it
-- Recreate add cascade operation CREATE TABLE employee( eid INT PRIMARY KEY AUTO_INCREMENT, ename VARCHAR(20), age INT, dept_id INT, CONSTRAINT emp_dept_fk FOREIGN KEY(dept_id) REFERENCES department(id) -- Add cascade delete ON DELETE CASCADE ); -- Add data INSERT INTO employee (ename, age, dept_id) VALUES ('Zhang million', 20, 1); INSERT INTO employee (ename, age, dept_id) VALUES ('Zhao Si', 21, 1); INSERT INTO employee (ename, age, dept_id) VALUES ('Guangkun', 20, 1); INSERT INTO employee (ename, age, dept_id) VALUES ('Xiao bin', 20, 2); INSERT INTO employee (ename, age, dept_id) VALUES ('Yanqiu', 22, 2); INSERT INTO employee (ename, age, dept_id) VALUES ('Da Lingzi', 18, 2); -- Delete the record with department number 2 DELETE FROM department WHERE id = 2;
The record with the foreign key value of 2 in the employee table has also been deleted
2. Multi table relation design
In actual development, a project usually needs many tables to complete. For example, a mall project requires multiple tables such as category, products and orders. And there is a certain relationship between the data of these tables. Next, let's learn the knowledge of multi table relationship design
Three relationships between tables
- One to many relationship: the most common relationship is student to class and employee to department
- Many to many relationships: students and courses, users and roles
- One to one relationship: less used because one-to-one relationships can be synthesized into a table
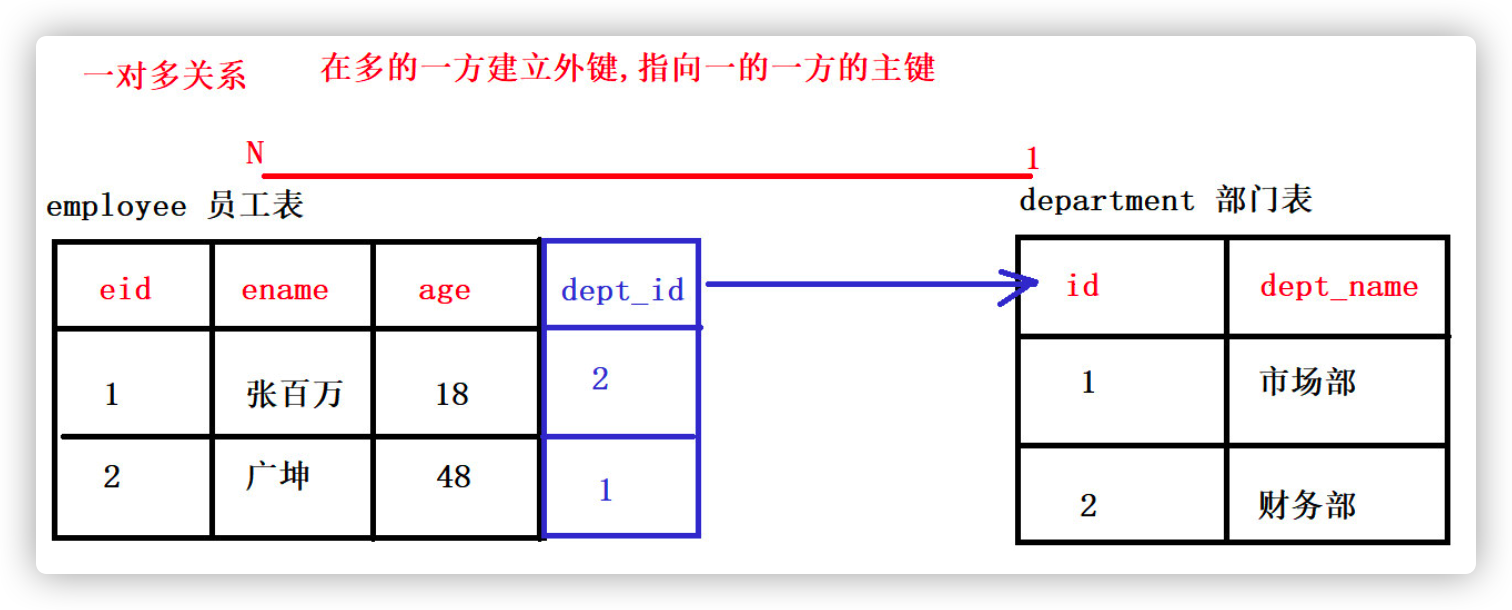
2.1 one to many relationship (common)
- One to many relationship (1:n)
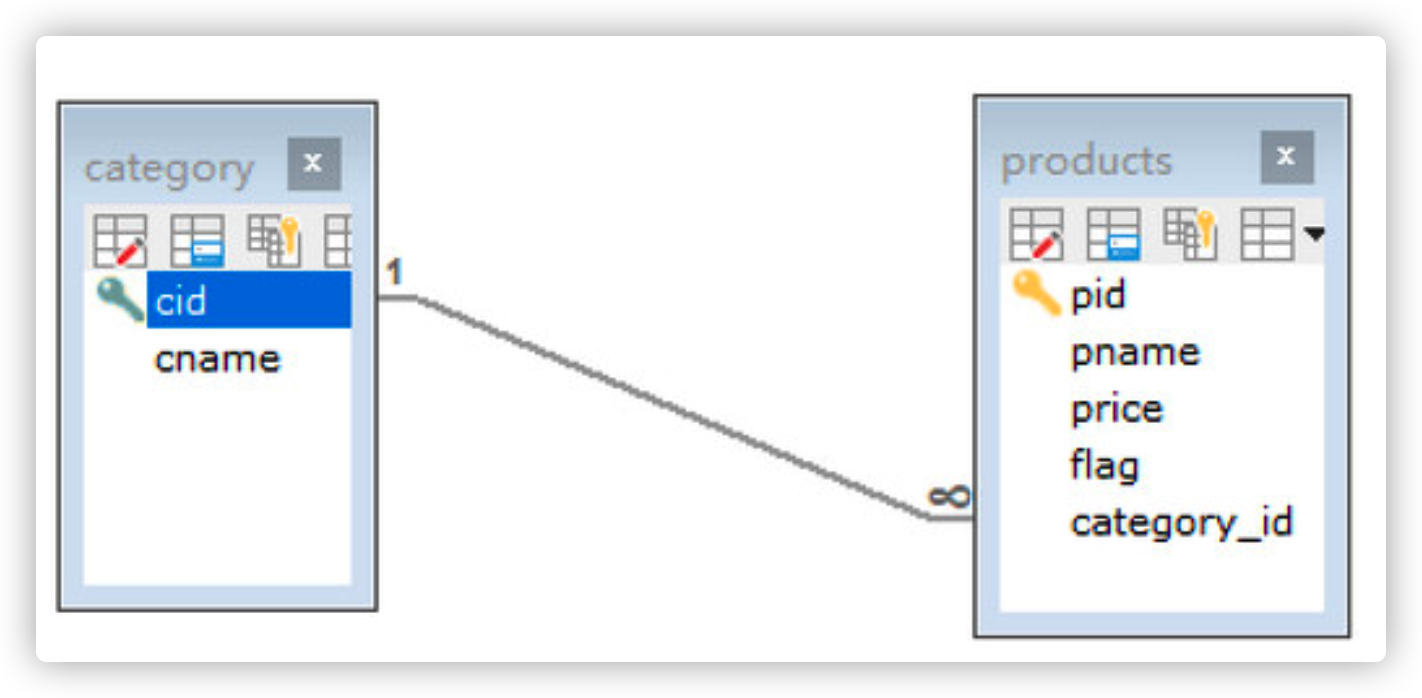
For example: classes and students, departments and employees, customers and orders, categories and goods - One to many table creation principle
When creating a field from a table (multi-party), the field is used as a foreign key to point to the primary key of the primary table (one party)
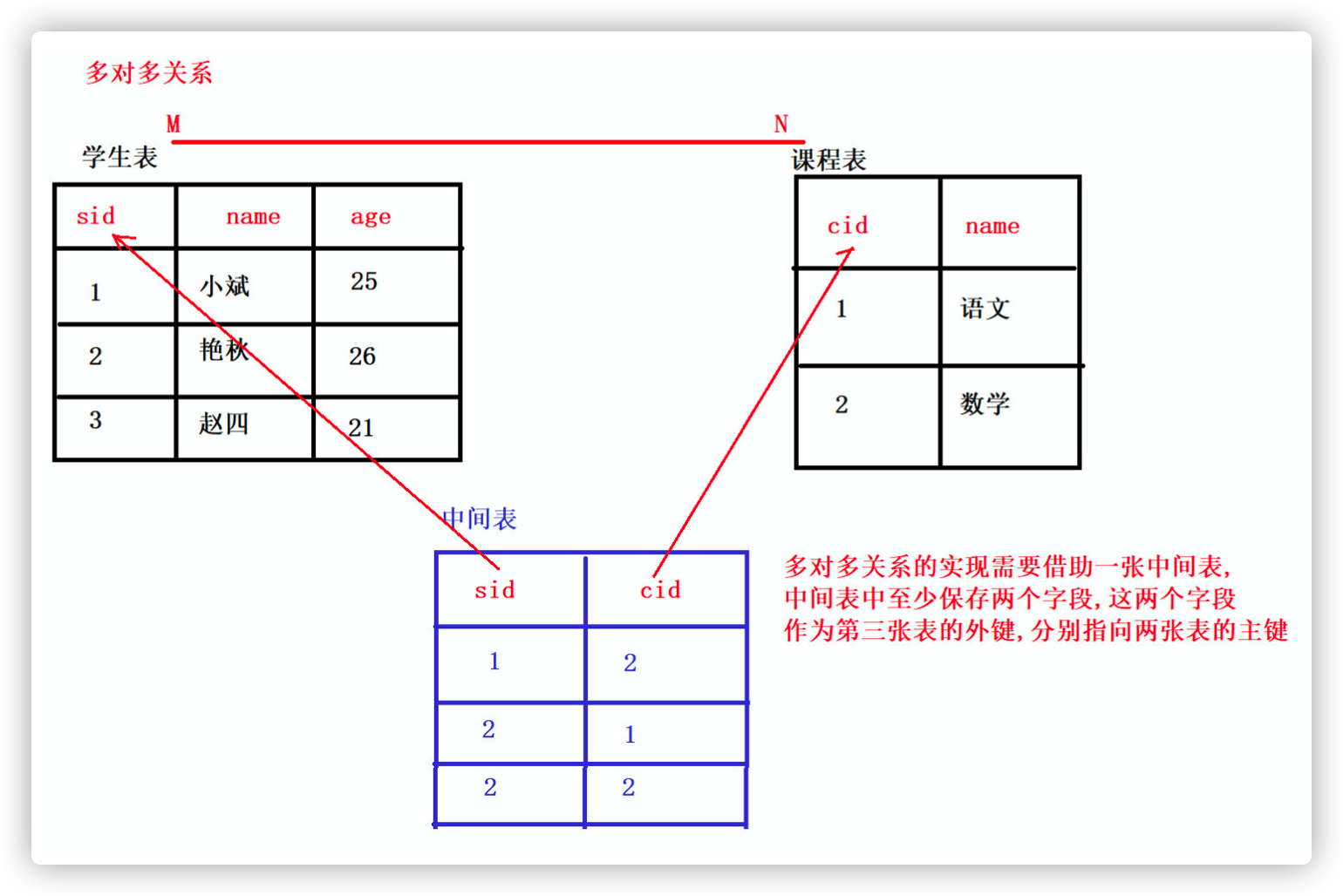
2.2 many to many relationship (common)
- Many to many (m:n)
For example: teachers and students, students and courses, users and roles - n many to many relationship table building principle
The third table needs to be created. There are at least two fields in the middle table. These two fields are used as foreign keys to point to the primary key of each party.
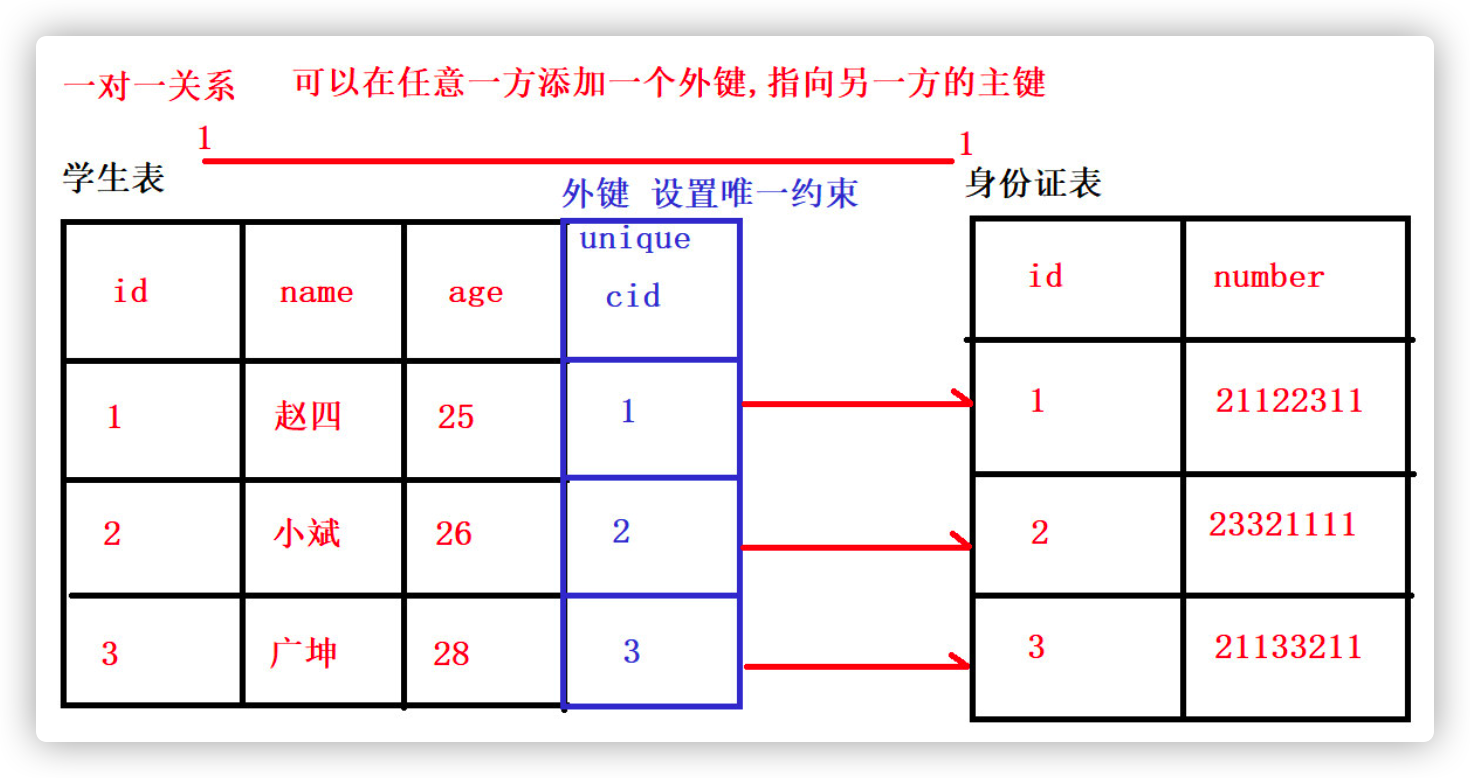
2.3 one to one relationship (understanding)
- One to one (1:1)
It is not widely used in practical development Because one-to-one can be created into a table. - One-to-one table building principle
The foreign key is UNIQUE. The primary key of the primary table and the foreign key (UNIQUE) of the secondary table form the primary foreign key relationship. The foreign key is UNIQUE
2.4 design Provincial & municipal table
-
Analysis: the relationship between provinces and cities is one to many, and a province contains multiple cities
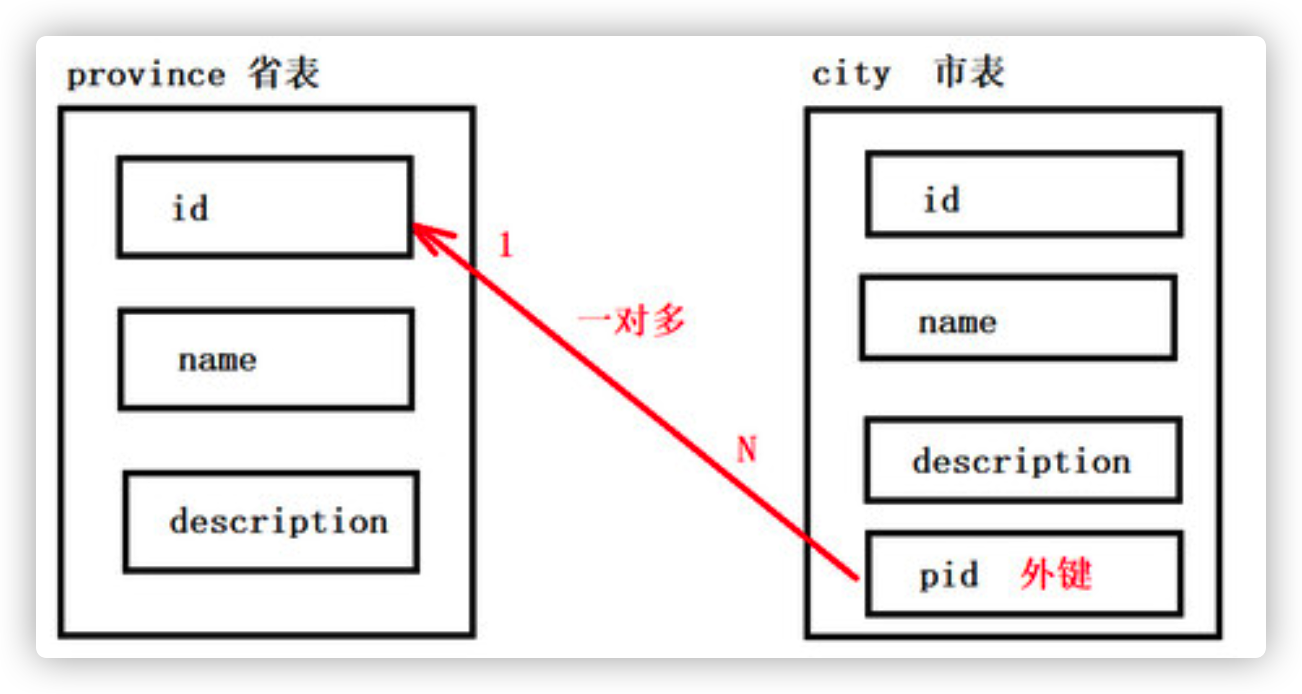
-
SQL implementation
#Create a provincial table (primary table, note: be sure to add primary key constraints) CREATE TABLE province( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(20), description VARCHAR(20) ); #Create city table (slave table, note: the foreign key type must be consistent with the primary key of the primary table) CREATE TABLE city( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(20), description VARCHAR(20), pid INT, -- Add foreign key constraint CONSTRAINT pro_city_fk FOREIGN KEY (pid) REFERENCES province(id) ); -
View table relationships
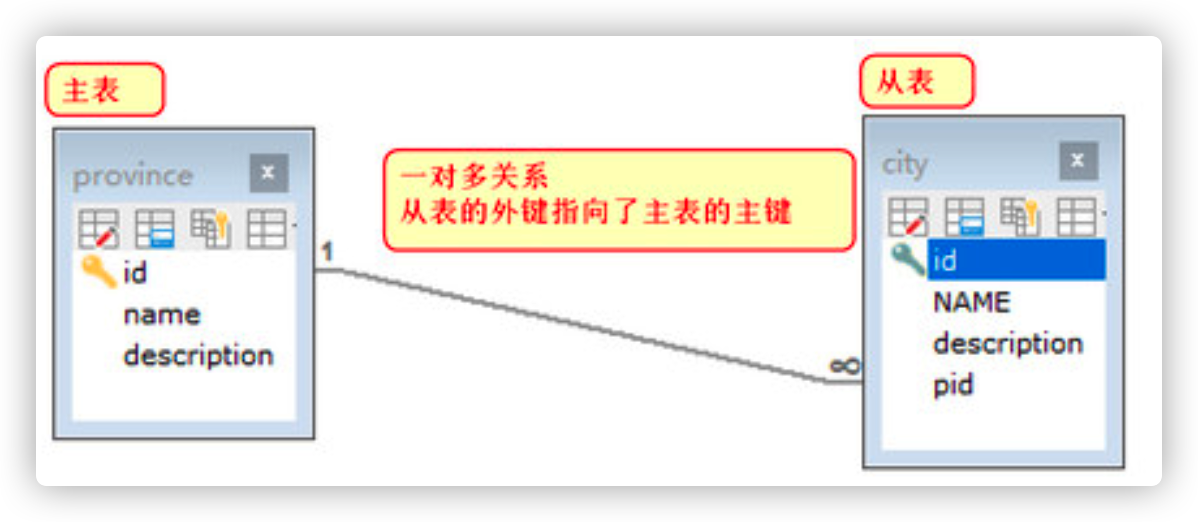
2.5 design actors and roles table
-
Analysis: actors and roles have a many to many relationship. An actor can play multiple roles, and a role can also be played by different actors
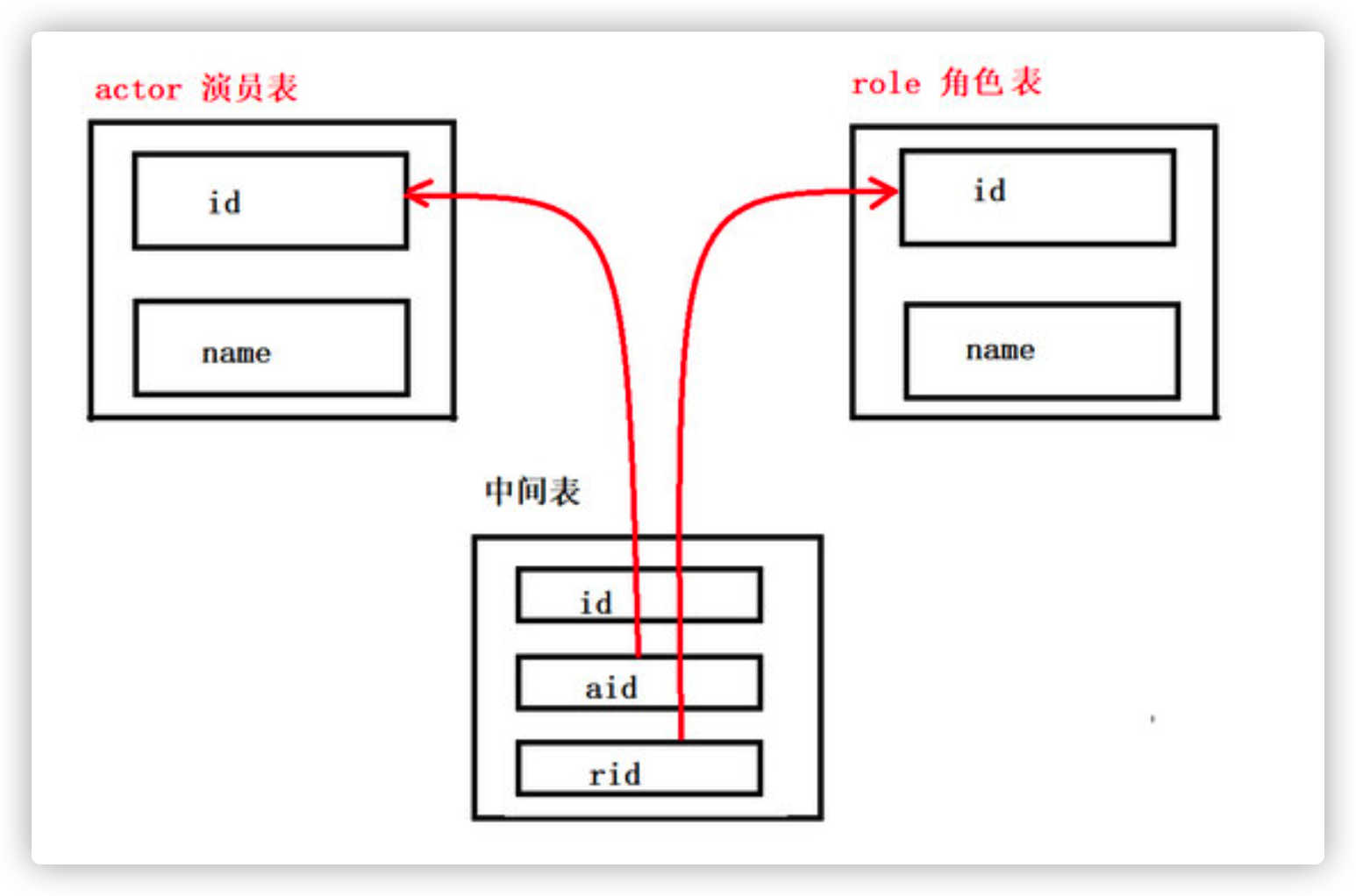
-
SQL implementation
#Create cast CREATE TABLE actor( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(20) ); #Create role table CREATE TABLE role( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(20) ); #Create intermediate table CREATE TABLE actor_role( -- The primary key of the intermediate table id INT PRIMARY KEY AUTO_INCREMENT, -- point actor Foreign key of table aid INT, -- point role Foreign key of table rid INT ); -
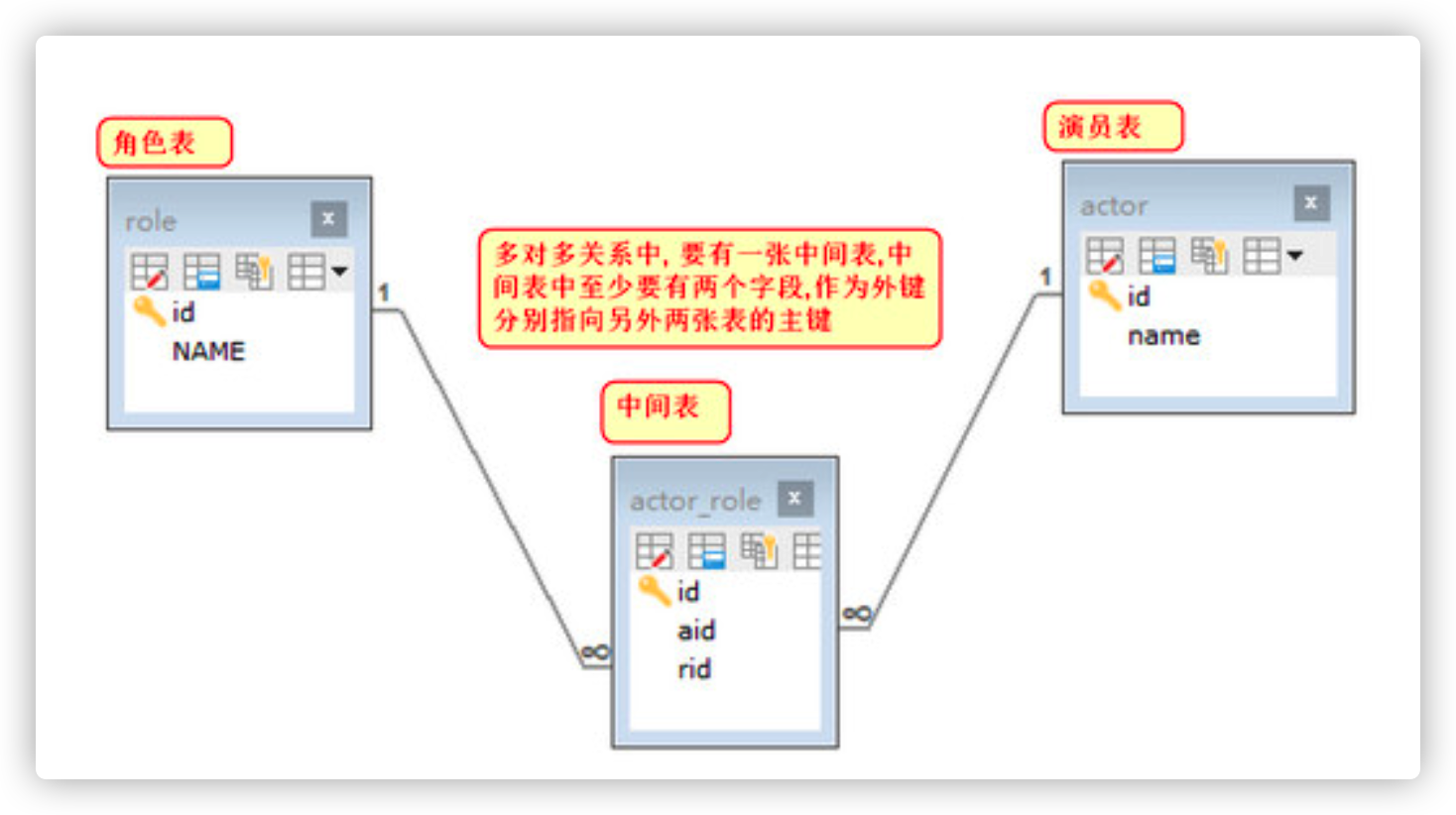
Add foreign key constraint
-- For intermediate table aid field,Add a foreign key constraint to point to the primary key of the actor table ALTER TABLE actor_role ADD FOREIGN KEY(aid) REFERENCES actor(id); -- For intermediate table rid field, Add a foreign key constraint to point to the primary key of the role table ALTER TABLE actor_role ADD FOREIGN KEY(rid) REFERENCES role(id);
-
View table relationships
3. Multi table query
3.1 what is multi table query
DQL: query multiple tables to obtain the required data
For example, if we want to query the goods under the household appliance classification, we need to query the two tables of classification and goods
3.2 data preparation
- Create db3_2 Database
-- establish db3_2 database,Specify encoding CREATE DATABASE db3_2 CHARACTER SET utf8;
- Create classification table and commodity table
#Classification table (main table of one party) CREATE TABLE category ( cid VARCHAR(32) PRIMARY KEY , cname VARCHAR(50) ); #Commodity list (multi-party slave list) CREATE TABLE products( pid VARCHAR(32) PRIMARY KEY , pname VARCHAR(50), price INT, flag VARCHAR(2), #Whether to put on the shelf is marked as: 1 means to put on the shelf and 0 means to get off the shelf category_id VARCHAR(32), -- Add foreign key constraint FOREIGN KEY (category_id) REFERENCES category (cid) );
- insert data
#Classified data
INSERT INTO category(cid,cname) VALUES('c001','household electrical appliances');
INSERT INTO category(cid,cname) VALUES('c002','Shoes and clothes');
INSERT INTO category(cid,cname) VALUES('c003','Cosmetics');
INSERT INTO category(cid,cname) VALUES('c004','automobile');
#Commodity data
INSERT INTO products(pid, pname,price,flag,category_id) VALUES('p001','Millet TV',5000,'1','c001');
INSERT INTO products(pid, pname,price,flag,category_id) VALUES('p002','Gree air conditioner',3000,'1','c001');
INSERT INTO products(pid, pname,price,flag,category_id) VALUES('p003','Midea refrigerator',4500,'1','c001');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p004','Basketball shoes',800,'1','c002');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p005','Sports pants',200,'1','c002');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p006','T Shirt',300,'1','c002');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p007','pizex',2000,'1','c002');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p008','Fairy water',800,'1','c003');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p009','Dabao',200,'1','c003');
3.3 Cartesian product
Cross connect query will not be used because it will produce Cartesian product
- Syntax format
SELECT Field name FROM Table 1, Table 2;
- Query commodity table and classification table with cross connection
SELECT * FROM category , products;
- Observe the query result and produce Cartesian product (the result is unusable)
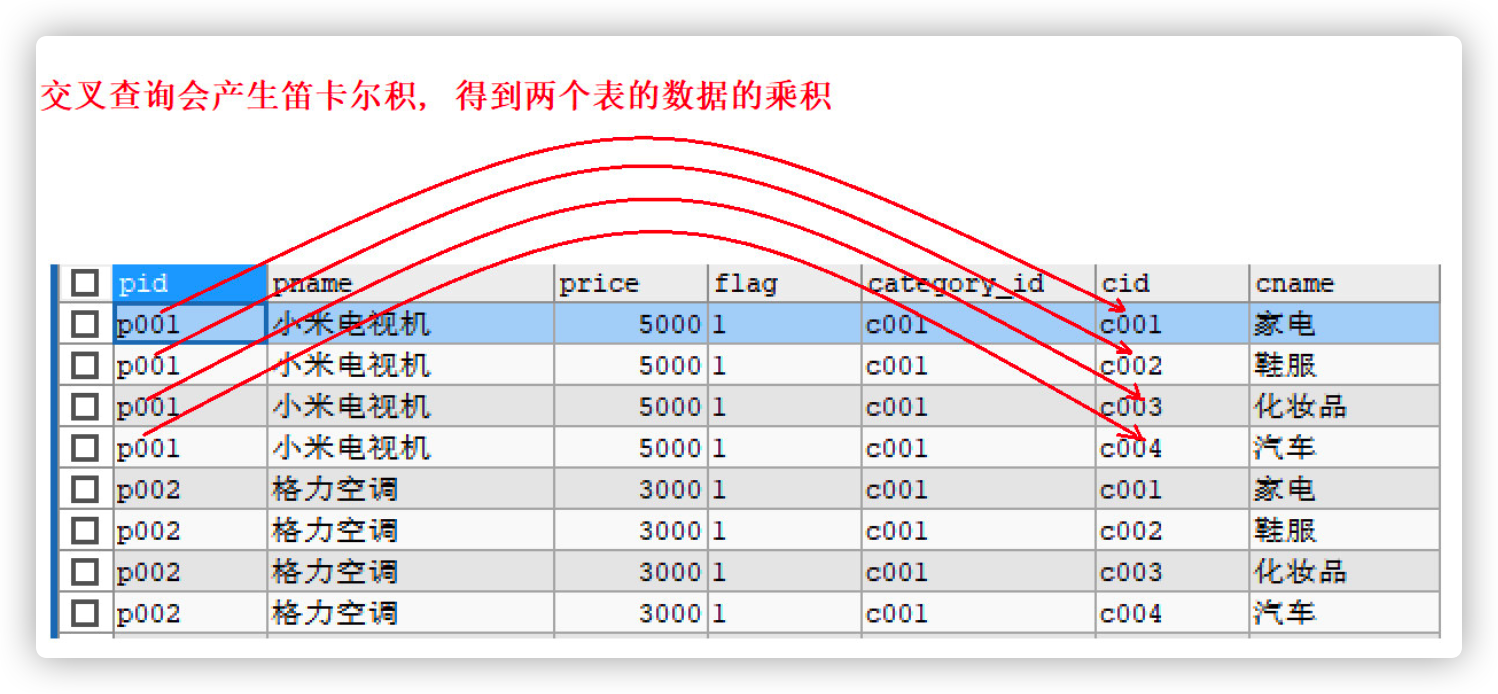
- Cartesian product
Suppose set A={a, b}, set B={0, 1, 2}, then the Cartesian product of two sets is {(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}.

3.4 classification of multi table query
3.4.1 internal connection query
- Features of internal connection:
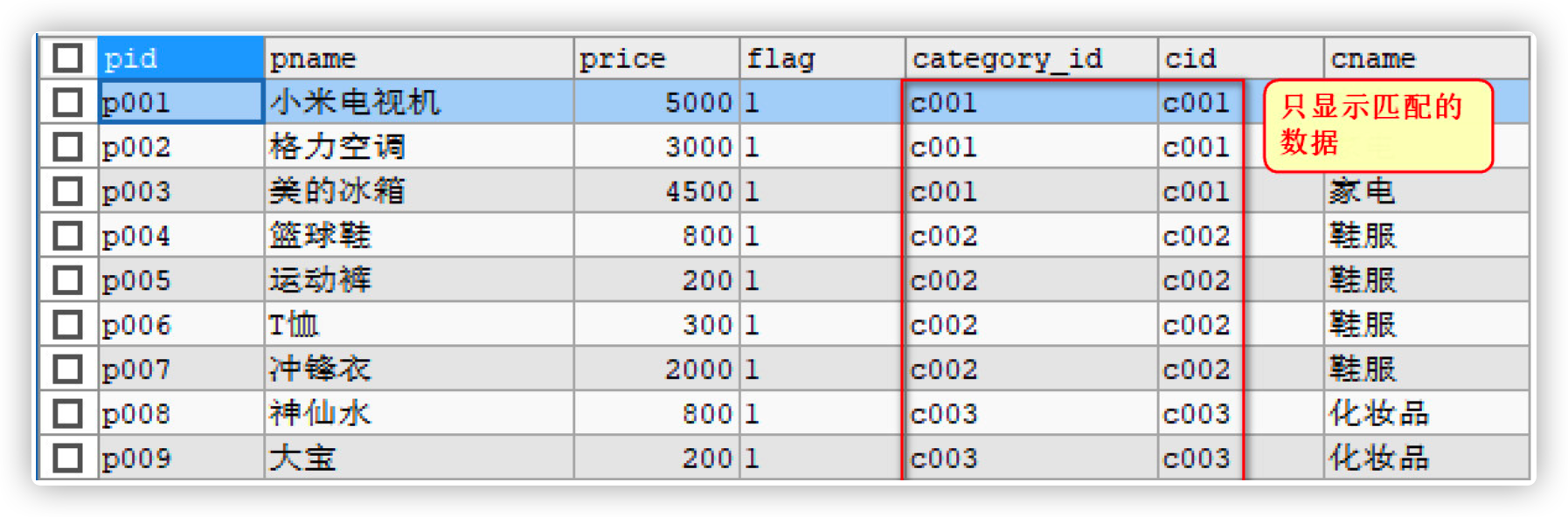
- Match the data in the two tables according to the specified conditions. If it is matched, it will be displayed. If it is not matched, it will not be displayed
- For example, the matching can be done by the way that the foreign key of the slave table equals the primary key of the primary table
- Match the data in the two tables according to the specified conditions. If it is matched, it will be displayed. If it is not matched, it will not be displayed
3.4.1.1 implicit inner connection
Write multiple table names directly after the from clause. Use where to specify the connection conditions. This connection method is implicit
Use the where condition to filter useless data
Syntax format
SELECT Field name FROM Left table, Right table WHERE Connection conditions;
Query all commodity information and corresponding classification information
# Implicit inner connection SELECT * FROM products,category WHERE category_id = cid;
Query the commodity name and price in the commodity table, as well as the classification information of commodities
You can alias the table, Convenient for our inquiry(There are hints)
SELECT
p.`pname`,
p.`price`,
c.`cname`
FROM products p , category c WHERE p.`category_id` = c.`cid`;
Query the category of Gree air conditioner
#Query the category of Gree air conditioner SELECT p.`pname`,c.`cname` FROM products p , category c WHERE p.`category_id` = c.`cid` AND p.`pid` = 'p002';

3.4.1.2 explicit inner connection
Using inner join... on is an explicit inner join
Syntax format
SELECT Field name FROM Left table [INNER] JOIN Right table ON condition -- inner Can be omitted
Query all commodity information and corresponding classification information
# Explicit inner join query SELECT * FROM products p INNER JOIN category c ON p.category_id = c.cid;
Query the name and price of goods with a price greater than 500 under the classification of shoes and clothing
# Query the name and price of goods with a price greater than 500 under the classification of shoes and clothing -- A few things we need to make sure -- 1.Query several tables products & category -- 2.Join condition of table.Foreign key = Primary key of primary table -- 3.Query criteria cname = 'Shoes and clothes' and price > 500 -- 4.Fields to query pname price SELECT p.pname, p.price FROM products p INNER JOIN category c ON p.category_id = c.cid WHERE p.price > 500 AND cname = 'Shoes and clothes';
3.4.2 external connection query
3.4.2.1 left outer connection
- Left outer join is used for left outer join. Outer can be omitted
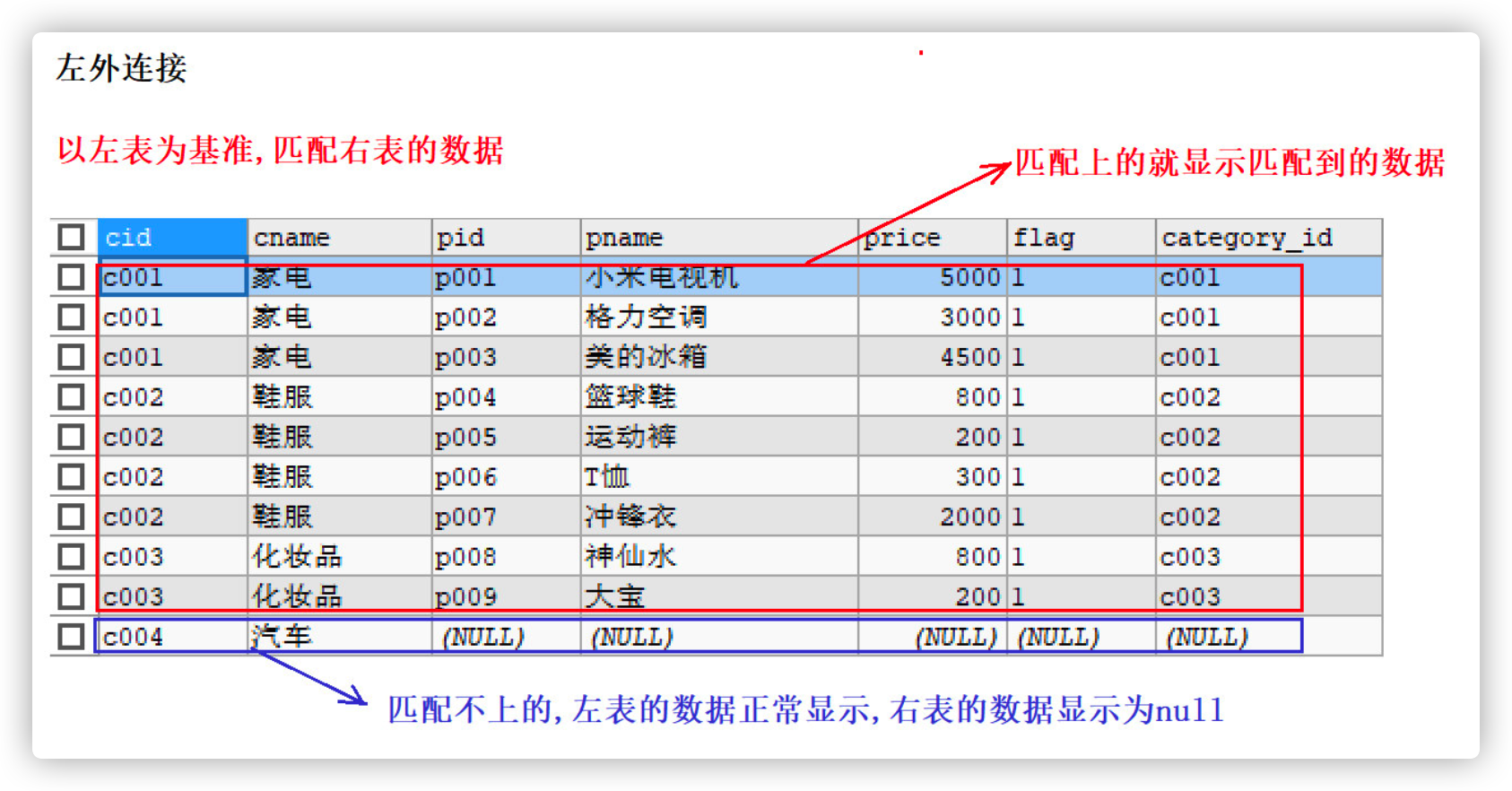
- Characteristics of left outer connection
- Take the left table as the benchmark to match the data in the right table. If it matches, the matched data will be displayed
- If no match is found, the data in the left table is displayed normally, and the display on the right is null
- Syntax format
SELECT Field name FROM Left table LEFT [OUTER] JOIN Right table ON condition
-- Left outer connection query SELECT * FROM category c LEFT JOIN products p ON c.`cid`= p.`category_id`;
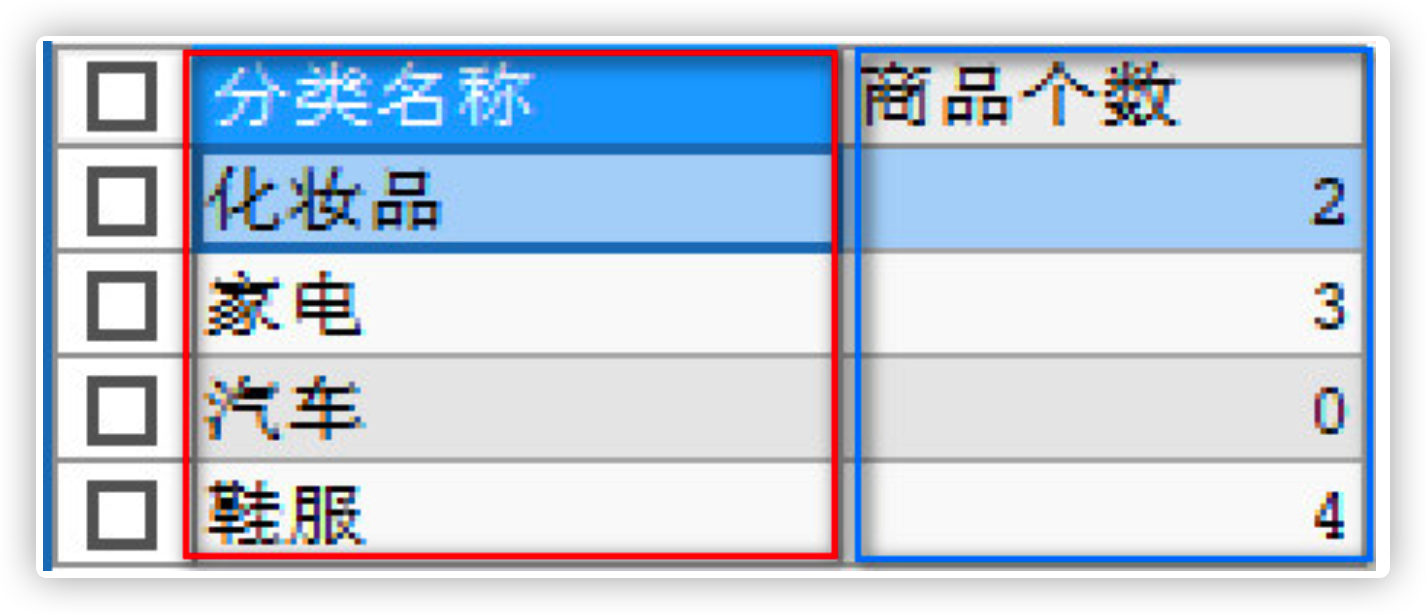
- Left outer connection to query the number of products under each category
# Query the number of goods under each category /* 1.Connection conditions: main table Primary key = from table Foreign key 2.Query criteria: each category needs grouping 3.Fields to query: category name, number of goods under category */ SELECT c.`cname` AS 'Classification name', COUNT(p.`pid`) AS 'Number of goods' FROM category c LEFT JOIN products p ON c.`cid` = p.`category_id` GROUP BY c.`cname`;
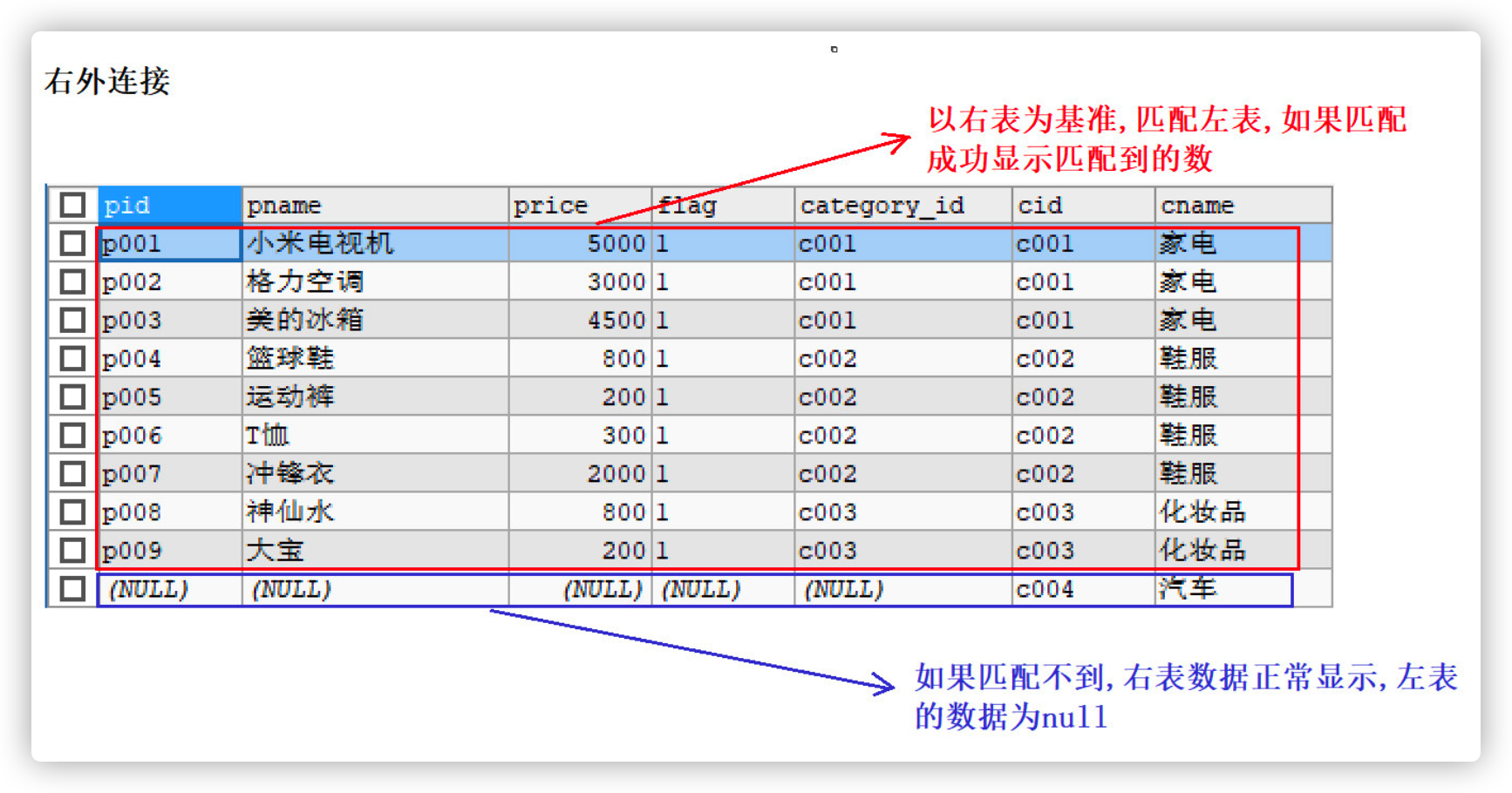
3.4.2.2 right outer connection
- Right outer join is used for right outer join, and outer can be omitted
- Characteristics of right external connection
- Take the right table as the benchmark to match the data in the left table. If it can be matched, the matched data will be displayed
- If no match is found, the data in the right table is displayed normally, and the left display is null
- Syntax format
SELECT Field name FROM Left table RIGHT [OUTER ]JOIN Right table ON condition
-- Right outer connection query SELECT * FROM products p RIGHT JOIN category c ON p.`category_id` = c.`cid`;
3.4.3 summary of various connection modes
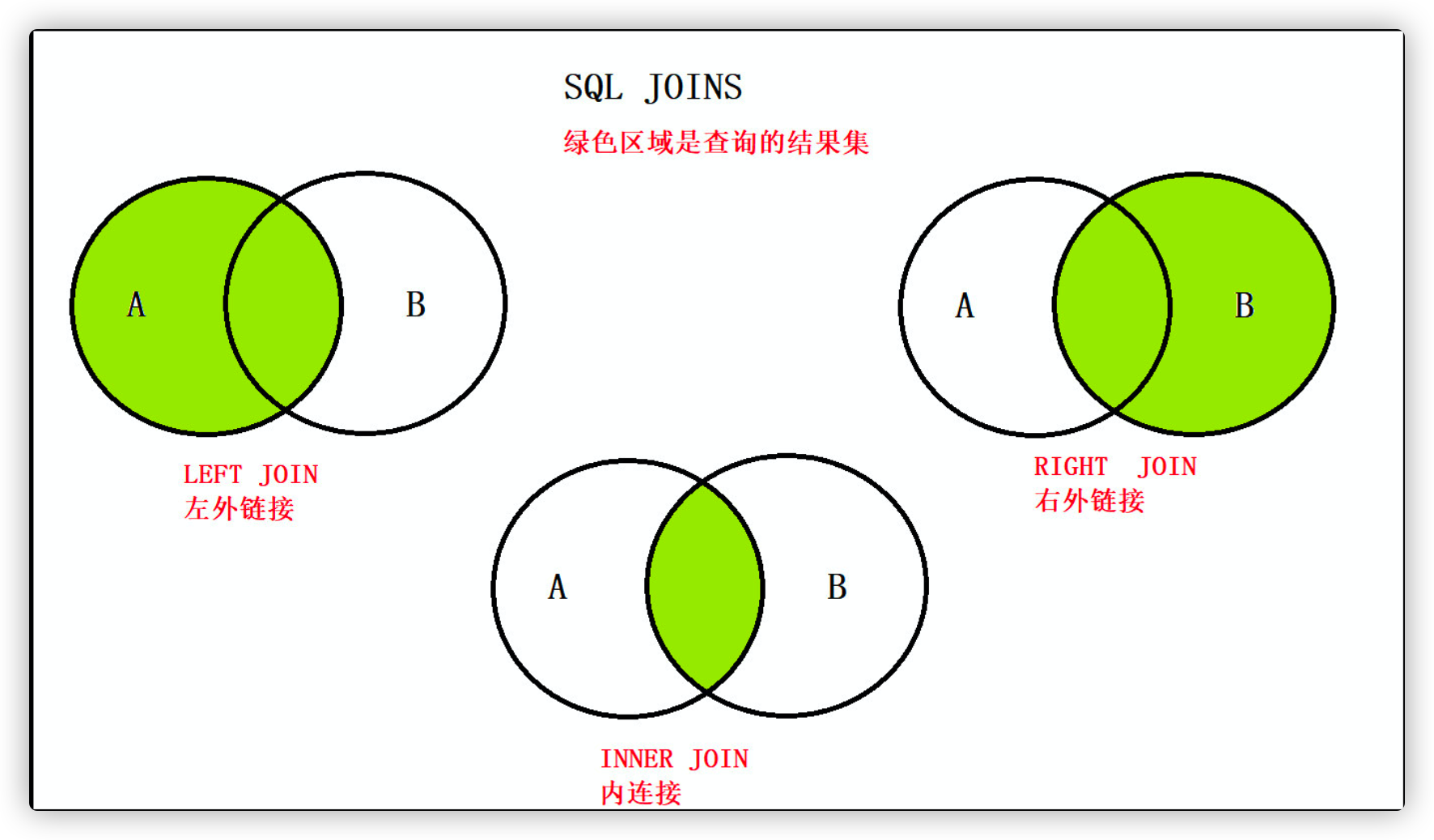
- Inner join: inner join, which only obtains the data of the intersection part of two tables
- Left outer join: left join, which queries all the data in the left table and the parts that intersect with the right table based on the left table
- Right outer join: right join, based on the right table, queries all the data in the right table and the parts that intersect with the left table
4. Subquery
4.1 what is a subquery
- Subquery concept
- The result of a select query statement as part of another select statement
- Characteristics of sub query
- Subqueries must be placed in parentheses
- Sub queries are generally used as query criteria of parent queries
- Sub query common classification
- Query results of query type: where as the parent and child of query type
- from sub query: the results of the sub query are provided to the parent query as a table
- exists sub query: the results of the sub query are single column and multiple rows, similar to an array. The parent query uses the IN function to contain the results of the sub query
4.2 sub query results are used as query criteria
Syntax format
SELECT Query field FROM surface WHERE field=(Subquery);
- Query the commodity information with the highest price through sub query
# Query the commodity information with the highest price through sub query -- 1.Find the highest price first SELECT MAX(price) FROM products; -- 2.Make the highest price a condition,Get product information SELECT * FROM products WHERE price = (SELECT MAX(price) FROM products);
- Query the commodity name and commodity price under cosmetics classification
#Query the commodity name and commodity price under cosmetics classification -- First find out the classification of cosmetics id SELECT cid FROM category WHERE cname = 'Cosmetics'; -- According to classification id ,Go to the commodity table to query the corresponding commodity information SELECT p.`pname`, p.`price` FROM products p WHERE p.`category_id` = (SELECT cid FROM category WHERE cname = 'Cosmetics'); - Query commodity information that is less than the average price
-- 1.Query average price SELECT AVG(price) FROM products; -- 1866 -- 2.Query goods with less than average price SELECT * FROM products WHERE price < (SELECT AVG(price) FROM products);
4.3 The results of sub query are used as a table
Syntax format
SELECT Query field FROM (Subquery)Table alias WHERE condition;
- Query the information of commodities with price greater than 500, including commodity name, commodity price and category name of commodities
Note: when the sub query is used as a table, it needs to be aliased, otherwise the fields in the table cannot be accessed.-- 1. Query the data of the classification table first SELECT * FROM category; -- 2.Use the above query statement as a table SELECT p.`pname`, p.`price`, c.cname FROM products p -- When a subquery is used as a table, it must be aliased to access the fields in the table INNER JOIN (SELECT * FROM category) c ON p.`category_id` = c.cid WHERE p.`price` > 500;
4.4 sub query results are single column and multiple rows
- The result of the sub query is similar to an array. The parent query uses the IN function to contain the result of the sub query
Syntax format
SELECT Query field FROM surface WHERE field IN (Subquery);
- Query the categories (names) of goods with a price less than 2000
# Query the categories (names) of goods with a price less than 2000 -- First query the price of goods with a price less than 2000,classification ID SELECT DISTINCT category_id FROM products WHERE price < 2000; -- According to the classification id information,Query classification name -- report errors: Subquery returns more than 1 row -- The result of subquery is greater than one row SELECT * FROM category WHERE cid = (SELECT DISTINCT category_id FROM products WHERE price < 2000);
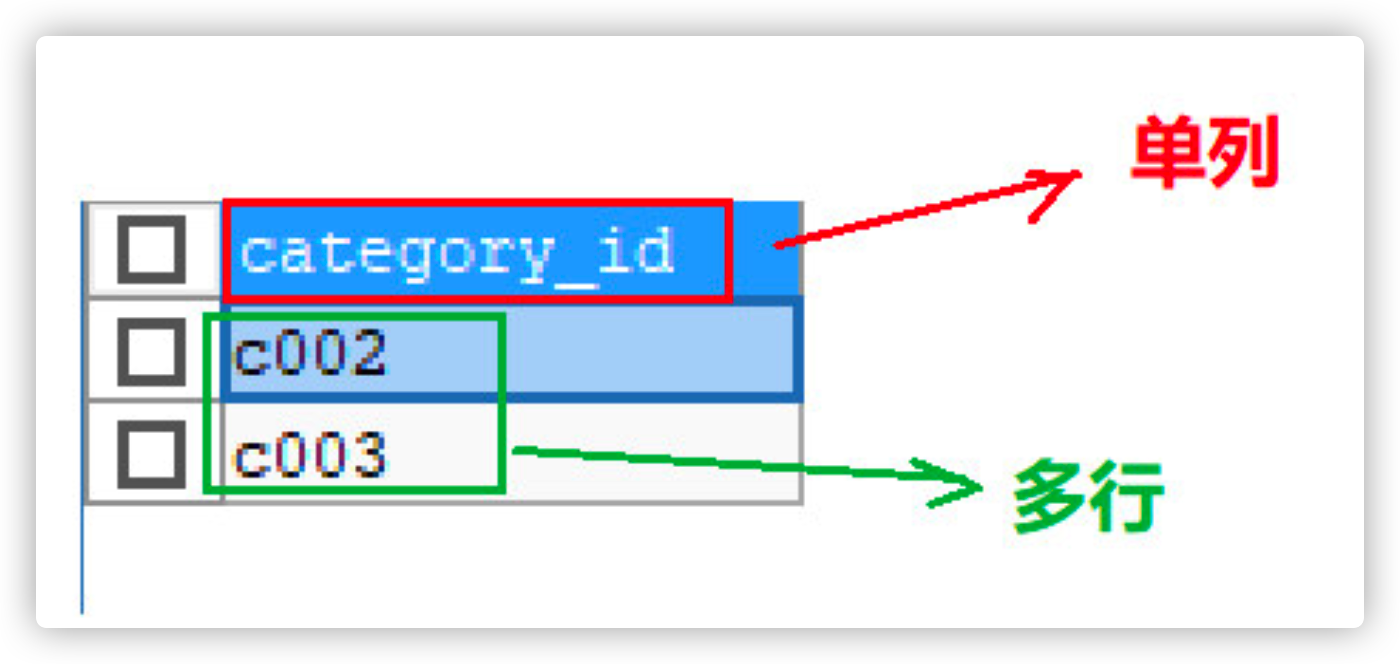
- Use the in function, in (C002, C003)
-- The subquery obtains single column and multiple rows of data SELECT * FROM category WHERE cid IN (SELECT DISTINCT category_id FROM products WHERE price < 2000);
- Query all commodity information under household appliances and shoes and clothing
# Query all commodity information under household appliances and shoes and clothing -- First query the classification of household appliances and shoes and clothing ID SELECT cid FROM category WHERE cname IN ('household electrical appliances','Shoes and clothes'); -- according to cid Query commodity information under classification SELECT * FROM products WHERE category_id IN (SELECT cid FROM category WHERE cname IN ('household electrical appliances','Shoes and clothes'));
4.5 sub query summary
- If the subquery finds a field (single column), it is used as a condition after where
- If the subquery finds multiple fields (columns), it will be used as a table (alias)
5. Database design
5.1 three paradigms of database (space saving)
- Concept: the three paradigms are the rules for designing databases
- In order to establish a database with less redundancy and reasonable structure, certain rules must be followed when designing the database. In relational databases, such rules are called paradigms. A paradigm is a summary that meets a certain design requirement. If we want to design a relational database with reasonable structure, we must meet a certain paradigm
- The paradigm that meets the minimum requirements is the first paradigm (1NF). It is called the second paradigm (2NF) to further meet more specification requirements on the basis of the first paradigm, and so on. Generally speaking, the database only needs to meet the third paradigm (3NF)
5.1.1 first paradigm 1NF
-
Concept:
- Atomicity, so that the column cannot be split
- The first paradigm is the most basic paradigm. The fields in the database table are single attribute and cannot be subdivided. If each field in the data table is the smallest data unit that cannot be subdivided, it meets the first normal form.
-
Example:
In the address information table, the column contray can still be split, which does not conform to the first normal form
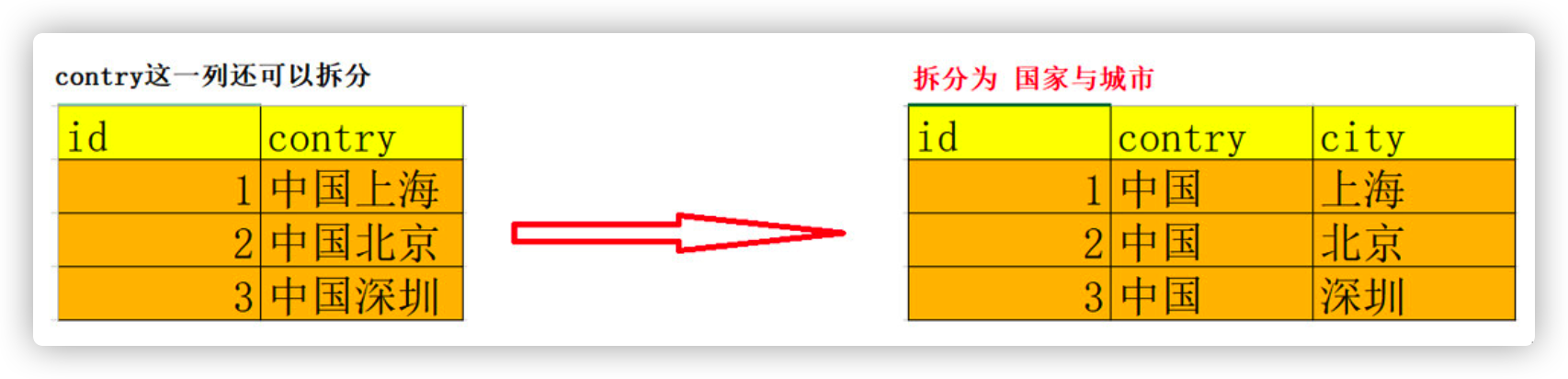
5.1.2 second paradigm 2NF
- Concept:
- Building on the first paradigm, the goal is to ensure that each column in the table is related to the primary key.
- A table can only describe one thing
- Example:
- In fact, there are two things described in the student information table, one is the student information and the other is the course information
- If placed in a table, it will lead to data redundancy. If you delete the student information, the score information will also be deleted
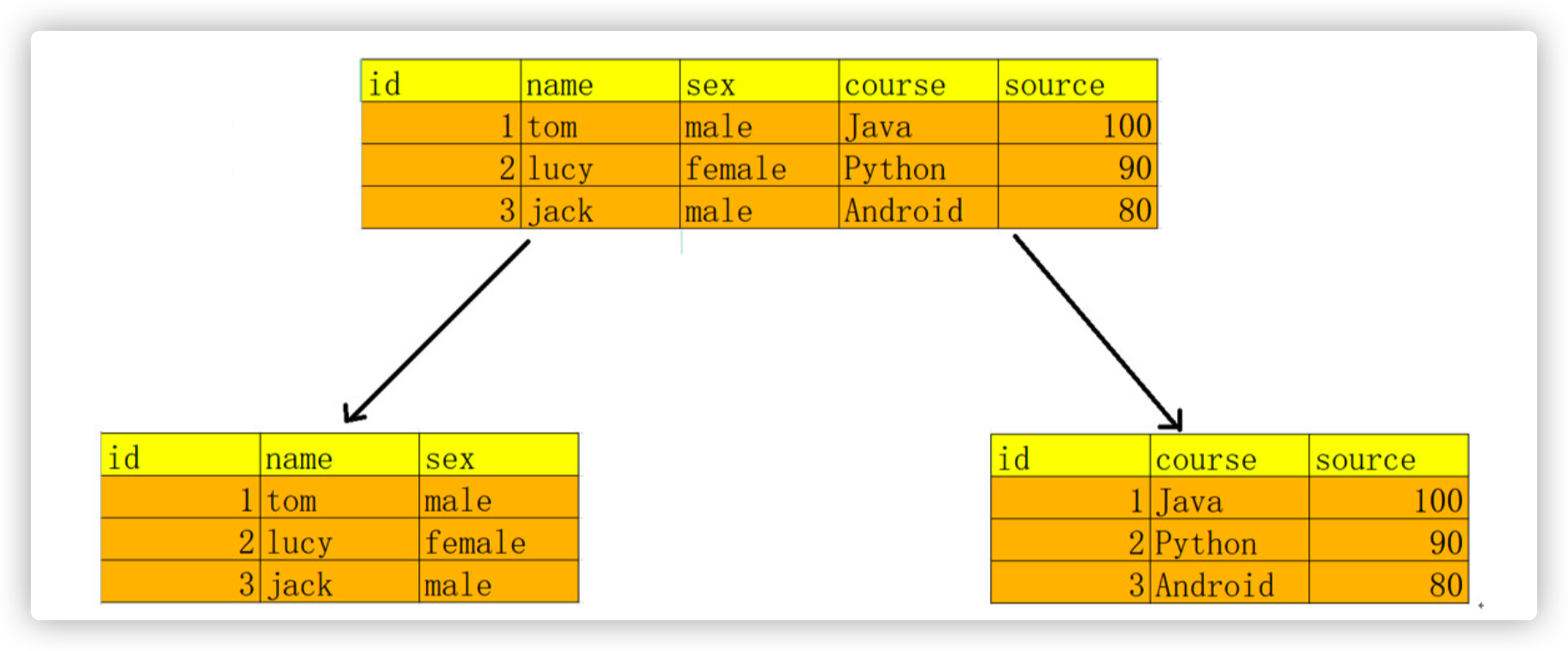
5.1.3 the third paradigm 3NF
- Concept:
- Eliminate transitive dependencies
- If the information of the table can be deduced, it should not be stored in a separate field
- Examples
- The total amount can be calculated through the number and price fields. Do not record it in the table (the space is the most economical)
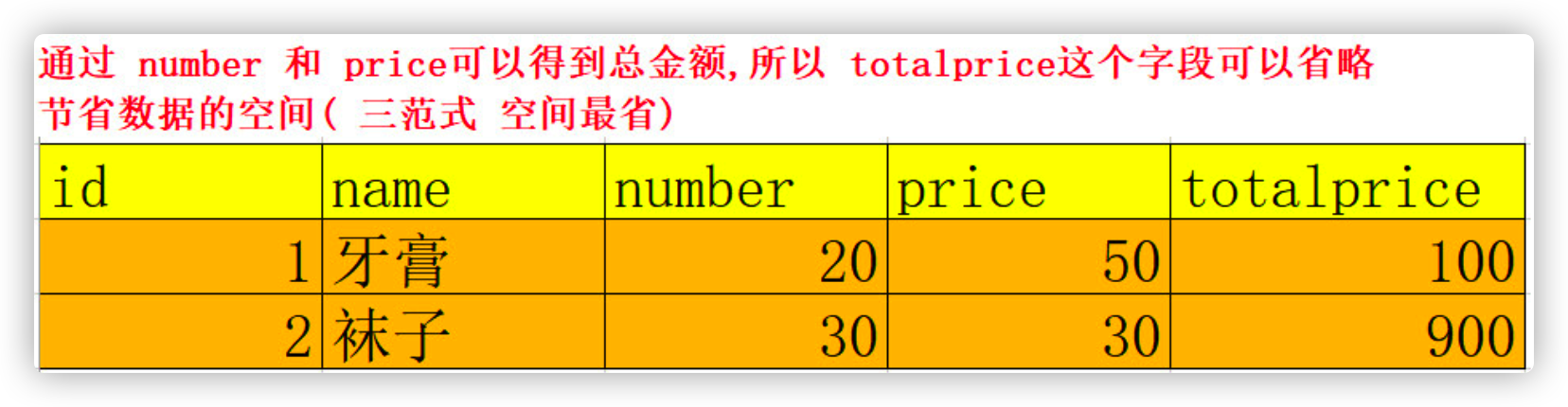
- The total amount can be calculated through the number and price fields. Do not record it in the table (the space is the most economical)
5.2 database anti three paradigms
5.2.1 concept
- Anti normalization refers to improving the read performance of the database by adding redundant or duplicate data
- Waste storage space and save query time (space for time)
5.2.2 what are redundant fields?
- When designing a database, a field belongs to one table, but it appears in another or more tables at the same time, and is completely equivalent to its meaning representation in the original table, then this field is a redundant field
5.2.3 examples of anti three paradigms
- There are two tables, user table and order table. The user table has the field name, and the order table also has the field name.
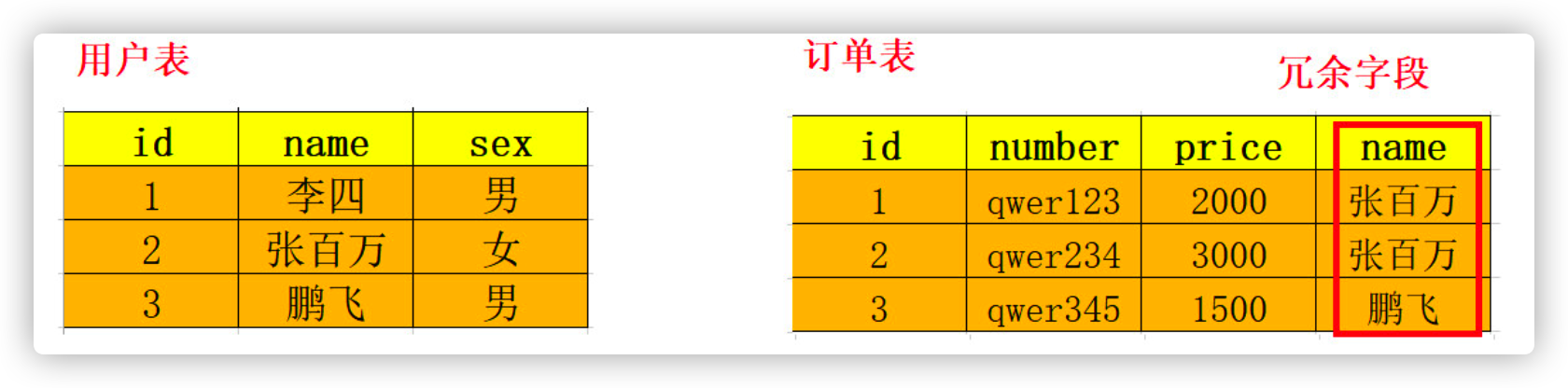
- Usage scenario
- When you need to query all the data of the "order table" and only need the name field of the "user table", you need to join the user table without redundant fields. Assuming that the amount of data in the table is very large, this connection query will consume the performance of the system
- At this time, redundant fields can be used. If there are redundant fields, we can check a table
5.2.4 summary
To create a relational database design, we have two options:
- Try to follow the rules of paradigm theory and minimize redundant fields to make the database design look exquisite, elegant and intoxicating.
- Reasonably add the lubricant of redundant fields to reduce join s and make the database execution performance higher and faster.