[TOC]
A primer
Data types are used to record the state of things, and the state of things is constantly changing (e.g., an increase in a person's age (operation int type), modification of a single person's name (operation str type), addition of students to the student list (operation list type), etc.). This means that we need to frequently operate on data when developing programs to improve our development efficiencyPython has a series of methods built into each data type for these common operations.The theme of this chapter is to take you to more detail about them, as well as the detailed definition and type conversion of each data type.
Illustration: Fig. 01
Two-digit type int and float
##2.1 Definition
# 1. Definition: # Definition of 1.1 integer int age=10 # Essential age = int(10) # 1.2 Definition of floating-point floats salary=3000.3 # Essential salary=float(3000.3) # Note: Name + brackets means calling a function, such as # print(...) calls the print function # int(...) calls the ability to create integer data # float(...) calls the ability to create floating-point data
##2.2 Type Conversion
# 1. Data Type Conversion
# 1.1 int converts a string of pure integers directly to integers, which can cause errors if it contains any other non-integer symbols
>>> s = '123'
>>> res = int(s)
>>> res,type(res)
(123, <class 'int'>)
>>> int('12.3') # Error demonstration: The string contains non-integer symbols.
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: '12.3'
# 1.2 float s can also be used for data type conversion
>>> s = '12.3'
>>> res=float(s)
>>> res,type(res)
(12.3, <class 'float'>)2.3 Use
Number types are mainly used for mathematical and comparative operations, so there is no built-in method for number types to master except for their use with operators.
Illustration: Fig. 02
#Three Strings
##3.1 Definition:
# Definition: Contains a string of characters within a single quotation mark \double quotation mark three quotation marks
name1 = 'jason' # Essential: name = str('any form of content')
name2 = "lili" # Essential: name = str("any form of content")
name3 = """ricky""" # Essential: name = str("""any form of content"")##3.2 Type Conversion
# Data type conversion: str() can convert any data type to a string type, for example
>>> type(str([1,2,3])) # list->str
<class 'str'>
>>> type(str({"name":"jason","age":18})) # dict->str
<class 'str'>
>>> type(str((1,2,3))) # tuple->str
<class 'str'>
>>> type(str({1,2,3,4})) # set->str
<class 'str'>##3.3 Use
Priority Operations for ###3.3.1
Illustration: Fig. 03
>>> str1 = 'hello python!'
# 1. Value by index (forward, reverse):
# 1.1 Forward fetch (left to right)
>>> str1[6]
p
# 1.2 Reverse take (minus sign means right to left)
>>> str1[-4]
h
# 1.3 For str, values can only be taken by index, not changed
>>> str1[0]='H' # Error TypeError
# 2. Slices (regardless of end, step size)
# 2.1 Remove all characters indexed from 0 to 8
>>> str1[0:9]
hello pyt
# 2.2 step: 0:9:2, the third parameter 2 represents the step, which starts at 0 and adds one 2 at a time, so the characters of index 0, 2, 4, 6, 8 are taken out
>>> str1[0:9:2]
hlopt
# 2.3 Reverse Section
>>> str1[::-1] # -1 means right-to-left values
!nohtyp olleh
# 3. Length len
# 3.1 Gets the length of the string, that is, the number of characters, but any existing within quotation marks counts as a character)
>>> len(str1) # Spaces are also characters
13
# 4. Membership operations in and not in
# 4.1 int: Determine if hello is inside str1
>>> 'hello' in str1
True
# 4.2 not in: Determine if tony is not in str1
>>> 'tony' not in str1
True
# 5.strip removes the character specified at the beginning and end of the string (removing spaces by default)
# 5.1 No character is specified within parentheses, removing leading and trailing spaces by default
>>> str1 = ' life is short! '
>>> str1.strip()
life is short!
# Remove characters specified at the beginning and end of brackets
>>> str2 = '**tony**'
>>> str2.strip('*')
tony
# 6. Divide split
# 6.1 No characters are specified within parentheses. Spaces are used as the slicing symbol by default
>>> str3='hello world'
>>> str3.split()
['hello', 'world']
# 6.2 If a delimiter is specified within parentheses, the string is cut according to the character specified within the parentheses
>>> str4 = '127.0.0.1'
>>> str4.split('.')
['127', '0', '0', '1'] # Note: The split cut results in a list data type
# 7. Cycle
>>> str5 = 'How are you today?'
>>> for line in str5: # Take out each character in the string in turn
... print(line)
...
//this
//day
//you
//good
//Are you?
?3.3.2 Operations to master
Illustration: Fig. 06
1.strip, lstrip, rstrip
>>> str1 = '**tony***'
>>> str1.strip('*') # Remove specified characters from left and right sides
'tony'
>>> str1.lstrip('*') # Remove only the specified character on the left
tony***
>>> str1.rstrip('*') # Remove only the specified character on the right
**tony2.lower(),upper()
>>> str2 = 'My nAme is tonY!' >>> str2.lower() # Lowercase all English strings my name is tony! >>> str2.upper() # Capitalize all English strings MY NAME IS TONY!
3.startswith,endswith
>>> str3 = 'tony jam'
# startswith() determines whether a string begins with a character specified in parentheses, resulting in a Boolean value of True or False
>>> str3.startswith('t')
True
>>> str3.startswith('j')
False
# endswith() determines whether a string ends with a character specified in parentheses, resulting in a Boolean value of True or False
>>> str3.endswith('jam')
True
>>> str3.endswith('tony')
False4. Format the output format
Previously, we used%s to format the output of a string. When passing a value, it must exactly correspond to the position of%s one-to-one, while the string's built-in method format provides a location-independent way of passing values.
Case:
# Form brackets can completely disrupt the order when passing parameters, but still pass values to the specified parameters by name='tony'is passed to {name}
>>> str4 = 'my name is {name}, my age is {age}!'.format(age=18,name='tony')
>>> str4
'my name is tony, my age is 18!'
>>> str4 = 'my name is {name}{name}{name}, my age is {name}!'.format(name='tony', age=18)
>>> str4
'my name is tonytonytony, my age is tony!'Other ways to use format (Learn)
# Similar to the usage of%s, the value passed in will correspond to {} one-to-one by location
>>> str4 = 'my name is {}, my age is {}!'.format('tony', 18)
>>> str4
my name is tony, my age is 18!
# Consider multiple values passed in by format as a list and use {index} to take values
>>> str4 = 'my name is {0}, my age is {1}!'.format('tony', 18)
>>> str4
my name is tony, my age is 18!
>>> str4 = 'my name is {1}, my age is {0}!'.format('tony', 18)
>>> str4
my name is 18, my age is tony!
>>> str4 = 'my name is {1}, my age is {1}!'.format('tony', 18)
>>> str4
my name is 18, my age is 18!5.split,rsplit 
# split slices strings in left-to-right order, specifying the number of times to slice
>>> str5='C:/a/b/c/d.txt'
>>> str5.split('/',1)
['C:', 'a/b/c/d.txt']
# rsplit is just the opposite of split, cut right to left, you can specify the number of cuts
>>> str5='a|b|c'
>>> str5.rsplit('|',1)
['a|b', 'c']6.join
# Remove multiple strings from an iterative object and stitch them together according to the specified separator. The result of stitching is a string
>>> '%'.join('hello') # Remove multiple strings from the string'hello'and stitch them together using% as a delimiter
'h%e%l%l%o'
>>> '|'.join(['tony','18','read']) # Remove multiple strings from the list and stitch them together using * as a separator
'tony|18|read'7.replace
# Replace old characters in strings with new ones
>>> str7 = 'my name is tony, my age is 18!' # Change tony's age from 18 to 73
>>> str7 = str7.replace('18', '73') # Syntax: replace('old content','New content')
>>> str7
my name is tony, my age is 73!
# Number of modifications that can be specified
>>> str7 = 'my name is tony, my age is 18!'
>>> str7 = str7.replace('my', 'MY',1) # Change only one my to MY
>>> str7
'MY name is tony, my age is 18!'8.isdigit
# Determines whether a string is made up of pure numbers and returns True or False >>> str8 = '5201314' >>> str8.isdigit() True >>> str8 = '123g123' >>> str8.isdigit() False
3.3.3 Understanding Operations
Illustration: Fig. 05
# 1.find,rfind,index,rindex,count
# 1.1 find: Finds the starting index of a substring within a specified range, returns the number 1 if found, and -1 if not found
>>> msg='tony say hello'
>>> msg.find('o',1,3) # Find the index for the character o in characters with indexes 1 and 2 (regardless of head and tail)
1
# 1.2 index: same find, but error if not found
>>> msg.index('e',2,4) # Error ValueError
# 1.3 rfind and rindex: omitted
# 1.4 count: Counts the number of times a string occurs in a large string
>>> msg = "hello everyone"
>>> msg.count('e') # Count the number of occurrences of string e
4
>>> msg.count('e',1,6) # Number of occurrences of string e in index range 1-5
1
# 2.center,ljust,rjust,zfill
>>> name='tony'
>>> name.center(30,'-') # Total width is 30, string centered, not enough - fill
-------------tony-------------
>>> name.ljust(30,'*') # Total width 30, string left aligned display, not enough *padding
tony**************************
>>> name.rjust(30,'*') # Total width 30, right aligned string display, not enough *padding
**************************tony
>>> name.zfill(50) # Total width 50, right aligned string display, not enough to fill with 0
0000000000000000000000000000000000000000000000tony
# 3.expandtabs
>>> name = 'tony\thello' # \t denotes a tab key
>>> name
tony hello
>>> name.expandtabs(1) # Modify the number of spaces represented by the \t tab
tony hello
# 4.captalize,swapcase,title
# 4.1 captalize: capital letters
>>> message = 'hello everyone nice to meet you!'
>>> message.capitalize()
Hello everyone nice to meet you!
# 4.2 swapcase: case flip
>>> message1 = 'Hi girl, I want make friends with you!'
>>> message1.swapcase()
hI GIRL, i WANT MAKE FRIENDS WITH YOU!
#4.3 title: capitalize the first letter of each word
>>> msg = 'dear my friend i miss you very much'
>>> msg.title()
Dear My Friend I Miss You Very Much
# 5.is Digital Series
#In python3
num1 = b'4' #bytes
num2 = u'4' #unicode,python3 unicode without adding u
num3 = 'four' #Chinese Numbers
num4 = 'Ⅳ' #Roman Numbers
#isdigt:bytes,unicode
>>> num1.isdigit()
True
>>> num2.isdigit()
True
>>> num3.isdigit()
False
>>> num4.isdigit()
False
#isdecimal:uncicode(bytes type without isdecimal method)
>>> num2.isdecimal()
True
>>> num3.isdecimal()
False
>>> num4.isdecimal()
False
#isnumberic:unicode, Chinese numeral, Roman numeral (bytes type has no isnumberic method)
>>> num2.isnumeric()
True
>>> num3.isnumeric()
True
>>> num4.isnumeric()
True
# Floating point number cannot be determined by the three
>>> num5 = '4.3'
>>> num5.isdigit()
False
>>> num5.isdecimal()
False
>>> num5.isnumeric()
False
'''
//Summary:
//isdigit, the most common type of bytes and unicode, is also the most common scenario for digital applications
//If you want to judge Chinese or Roman numerals, you need to use isnumeric.
'''
# 6.is Other
>>> name = 'tony123'
>>> name.isalnum() #Strings can contain either numbers or letters
True
>>> name.isalpha() #String contains only letters
False
>>> name.isidentifier()
True
>>> name.islower() # Is the string pure lowercase
True
>>> name.isupper() # Is the string pure uppercase
False
>>> name.isspace() # Is the string full of spaces
False
>>> name.istitle() # Whether the first letter of a word in a string is all capitalized
False#Four Lists
##4.1 Definition
# Definition: Within [], values of any data type are separated by commas l1 = [1,'a',[1,2]] # Essential: l1 = list([1,'a',[1,2])
##4.2 Type Conversion
# However, any data type that can be traversed by a for loop can be passed to list() to be converted to a list type, and list() traverses every element contained in the data type as a for loop and places it in the list
>>> list('wdad') # Results: ['w','d','a','d']
>>> list([1,2,3]) # Result: [1, 2, 3]
>>> list({"name":"jason","age":18}) #Result: ['name','age']
>>> list((1,2,3)) # Result: [1, 2, 3]
>>> list({1,2,3,4}) # Result: [1, 2, 3, 4]##4.3 Use
Priority Operations for ###4.3.1
Illustration: Fig. 04
# 1. Access Values by Index (Forward Access + Reverse Access): Save or Retrieve
# 1.1 Forward fetch (left to right)
>>> my_friends=['tony','jason','tom',4,5]
>>> my_friends[0]
tony
# 1.2 Reverse take (minus sign means right to left)
>>> my_friends[-1]
5
# 1.3 For list s, values can be either indexed or modified at specified locations, but errors occur if the index does not exist
>>> my_friends = ['tony','jack','jason',4,5]
>>> my_friends[1] = 'martthow'
>>> my_friends
['tony', 'martthow', 'jason', 4, 5]
# 2. Slices (regardless of end, step size)
# 2.1 Remove elements indexed from 0 to 3
>>> my_friends[0:4]
['tony', 'jason', 'tom', 4]
# 2.2 step: 0:4:2, the third parameter 2 represents the step, which will start from 0 and add up one 2 at a time, so the elements of index 0 and 2 will be taken out
>>> my_friends[0:4:2]
['tony', 'tom']
# 3. Length
>>> len(my_friends)
5
# 4. Membership operations in and not in
>>> 'tony' in my_friends
True
>>> 'xxx' not in my_friends
True
# 5. Add
# Append element at the end of the 5.1 append() list
>>> l1 = ['a','b','c']
>>> l1.append('d')
>>> l1
['a', 'b', 'c', 'd']
# 5.2 extend() adds multiple elements at the end of the list at once
>>> l1.extend(['a','b','c'])
>>> l1
['a', 'b', 'c', 'd', 'a', 'b', 'c']
# 5.3 insert() inserts an element at a specified location
>>> l1.insert(0,"first") # 0 means interpolation by index position
>>> l1
['first', 'a', 'b', 'c', 'alisa', 'a', 'b', 'c']
# 6. Delete
# 6.1 del
>>> l = [11,22,33,44]
>>> del l[2] # Delete element with index 2
>>> l
[11,22,44]
# 6.2 pop() deletes the last element of the list by default and returns the deleted value, in parentheses you can specify the deleted element by adding an indexed value
>>> l = [11,22,33,22,44]
>>> res=l.pop()
>>> res
44
>>> res=l.pop(1)
>>> res
22
# 6.3 remove() parentheses indicate which element to delete, no return value
>>> l = [11,22,33,22,44]
>>> res=l.remove(22) # Look left to right for elements that need to be deleted within the first bracket
>>> print(res)
None
# 7.reverse() reverses the order of elements in the list
>>> l = [11,22,33,44]
>>> l.reverse()
>>> l
[44,33,22,11]
# 8.sort() sorts all elements in the list
# 8.1 List elements must be of the same data type when sorting, not to be mashed up, or an error will be reported
>>> l = [11,22,3,42,7,55]
>>> l.sort()
>>> l
[3, 7, 11, 22, 42, 55] # Default sort from smallest to largest
>>> l = [11,22,3,42,7,55]
>>> l.sort(reverse=True) # Reversee is used to specify whether to fall in the sort, defaulting to False
>>> l
[55, 42, 22, 11, 7, 3]
# 8.2 Understanding knowledge:
# We often use number types to compare sizes directly, but in fact, strings, lists, and so on can compare sizes in the same way: they all compare the sizes of the elements in their corresponding positions in turn. If you separate the sizes, you do not need to compare the next element, such as
>>> l1=[1,2,3]
>>> l2=[2,]
>>> l2 > l1
True
# The size of the characters depends on their order in the ASCII table, and the larger they are
>>> s1='abc'
>>> s2='az'
>>> s2 > s1 # s1 and s2 have no winner or loser for the first character, but the second character'z'>'b', so s2 > s1 holds
True
# So we can also sort this list below
>>> l = ['A','z','adjk','hello','hea']
>>> l.sort()
>>> l
['A', 'adjk', 'hea', 'hello','z']
# 9. Cycle
# Loop through the values in my_friends list
for line in my_friends:
print(line)
'tony'
'jack'
'jason'
4
54.3.2 Understanding Operations
Illustration: Fig. 09
>>> l=[1,2,3,4,5,6] >>> l[0:3:1] [1, 2, 3] # Forward step >>> l[2::-1] [3, 2, 1] # Reverse step # Flip List by Index Value >>> l[::-1] [6, 5, 4, 3, 2, 1]
Five-tuple
5.1 Role
A tuple is similar to a list in that it can store multiple elements of any type, except that the elements of a tuple cannot be modified, that is, a tuple is equivalent to an immutable list, which records multiple fixed values that are not allowed to be modified, and is simply used to fetch

5.2 Definition
# Separate multiple values of any type within () with commas
>>> countries = ("China","U.S.A","Britain") # Essential: countries = tuple("China", "US", "UK")
# Emphasis: If there is only one value in the tuple, a comma must be added, otherwise () will only contain the meaning, not define the tuple
>>> countries = ("China",) # Essential: countries = tuple (China)5.3 Type Conversion
# However, any data type that can be traversed by a for loop can be passed to tuple() to be converted to a tuple type
>>> tuple('wdad') # Results: ('w','d','a','d')
>>> tuple([1,2,3]) # Results: (1, 2, 3)
>>> tuple({"name":"jason","age":18}) # Result: ('name','age')
>>> tuple((1,2,3)) # Results: (1, 2, 3)
>>> tuple({1,2,3,4}) # Results: (1, 2, 3, 4)
# tuple() iterates through each element contained in the data type as a for loop and puts it in a tuple5.4 Use
Illustration: Fig. 08
>>> tuple1 = (1, 'hhaha', 15000.00, 11, 22, 33) # 1. Value by index (forward + reverse): can only take, can not change otherwise error! >>> tuple1[0] 1 >>> tuple1[-2] 22 >>> tuple1[0] = 'hehe' # Error: TypeError: # 2. Slices (regardless of end, step length) >>> tuple1[0:6:2] (1, 15000.0, 22) # 3. Length >>> len(tuple1) 6 # 4. Member operation in and not in >>> 'hhaha' in tuple1 True >>> 'hhaha' not in tuple1 False # 5. Cycle >>> for line in tuple1: ... print(line) 1 hhaha 15000.0 11 22 33
Six Dictionaries
6.1 Definition
# Definition: Separate multiple elements within {} by commas, each of which is in the form of key:value, where value can be of any type and key must be of an immutable type. See subsection 8 for more details, key should usually be of type str, because STR types have descriptive functions on value
info={'name':'tony','age':18,'sex':'male'} #Essential info=dict({....})
# You can also define a dictionary like this
info=dict(name='tony',age=18,sex='male') # info={'age': 18, 'sex': 'male', 'name': 'tony'}6.2 Type Conversion
# Conversion 1:
>>> info=dict([['name','tony'],('age',18)])
>>> info
{'age': 18, 'name': 'tony'}
# Conversion 2:fromkeys takes each value from the tuple as a key, then composes key:value with None and puts it in the dictionary
>>> {}.fromkeys(('name','age','sex'),None)
{'age': None, 'sex': None, 'name': None}##6.3 Use
Priority Operations for ###6.3.1
Illustration: Fig. 07

# 1. Access values by key: accessible
# 1.1 fetch
>>> dic = {
... 'name': 'xxx',
... 'age': 18,
... 'hobbies': ['play game', 'basketball']
... }
>>> dic['name']
'xxx'
>>> dic['hobbies'][1]
'basketball'
# 1.2 For assignment operations, if the key did not originally exist in the dictionary, a new key:value will be added
>>> dic['gender'] = 'male'
>>> dic
{'name': 'tony', 'age': 18, 'hobbies': ['play game', 'basketball'],'gender':'male'}
# 1.3 For assignment operations, if the key originally existed in the dictionary, the value of the corresponding value would be modified
>>> dic['name'] = 'tony'
>>> dic
{'name': 'tony', 'age': 18, 'hobbies': ['play game', 'basketball']}
# 2. Length len
>>> len(dic)
3
# 3. Member operation in and not in
>>> 'name' in dic # Determine if a value is a dictionary key
True
# 4. Delete
>>> dic.pop('name') # Delete key-value pairs from a dictionary by specifying its key
>>> dic
{'age': 18, 'hobbies': ['play game', 'basketball']}
# 5. keys(), values(), and key-value pairs items()
>>> dic = {'age': 18, 'hobbies': ['play game', 'basketball'], 'name': 'xxx'}
# Get all key s of the dictionary
>>> dic.keys()
dict_keys(['name', 'age', 'hobbies'])
# Get all the value s of the dictionary
>>> dic.values()
dict_values(['xxx', 18, ['play game', 'basketball']])
# Get all key-value pairs of a dictionary
>>> dic.items()
dict_items([('name', 'xxx'), ('age', 18), ('hobbies', ['play game', 'basketball'])])
# 6. Cycle
# 6.1 The default traversal is a dictionary key
>>> for key in dic:
... print(key)
...
age
hobbies
name
# 6.2 traverse key only
>>> for key in dic.keys():
... print(key)
...
age
hobbies
name
# 6.3 Traverse value only
>>> for key in dic.values():
... print(key)
...
18
['play game', 'basketball']
xxx
# 6.4 Traversing key and value
>>> for key in dic.items():
... print(key)
...
('age', 18)
('hobbies', ['play game', 'basketball'])
('name', 'xxx')6.3.2 Operations Required
Illustration: Joke Fig. 10
1.get()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> dic.get('k1')
'jason' # If key exists, get the value of the key
>>> res=dic.get('xxx') # key does not exist and returns None by default instead of error
>>> print(res)
None
>>> res=dic.get('xxx',666) # When key does not exist, you can set the value returned by default
>>> print(res)
666
# ps:Dictionary Value Suggestion Using get Method2.pop()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> v = dic.pop('k2') # Deletes the key-value pair corresponding to the specified key and returns the value
>>> dic
{'k1': 'jason', 'kk2': 'JY'}
>>> v
'Tony'3.popitem()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> item = dic.popitem() # Randomly delete a set of key-value pairs and return the deleted key values in a tuple
>>> dic
{'k3': 'JY', 'k2': 'Tony'}
>>> item
('k1', 'jason')4.update()
# Update the old dictionary with the new one, modify it if you want, and add it if you don't
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> dic.update({'k1':'JN','k4':'xxx'})
>>> dic
{'k1': 'JN', 'k3': 'JY', 'k2': 'Tony', 'k4': 'xxx'}5.fromkeys()
>>> dic = dict.fromkeys(['k1','k2','k3'],[])
>>> dic
{'k1': [], 'k2': [], 'k3': []}6.setdefault()
# If the key does not exist, a new key-value pair is added and the new value is returned
>>> dic={'k1':111,'k2':222}
>>> res=dic.setdefault('k3',333)
>>> res
333
>>> dic # A new key-value pair has been added to the dictionary
{'k1': 111, 'k3': 333, 'k2': 222}
# The key exists without any modification and returns the value corresponding to the existing key
>>> dic={'k1':111,'k2':222}
>>> res=dic.setdefault('k1',666)
>>> res
111
>>> dic # Dictionary unchanged
{'k1': 111, 'k2': 222}Seven Sets
7.1 Role
Sets, list s, tuple s, dict s can store multiple values, but sets are mainly used for: de-weighting, relational operations
Illustration: Hoax Fig. 11
7.2 Definition
"""
Definition: Multiple elements are separated by commas within {}, and a collection has three characteristics:
1: Each element must be of an immutable type
2: There are no duplicate elements in the collection
3: The elements in the set are out of order
"""
s = {1,2,3,4} #Essential s = set({1,2,3,4})
#Note 1: List types are index corresponding values, dictionaries are key corresponding values, and each can get a single specified value. Collection types have neither indexes nor keys corresponding to values, so they cannot get a single value, and for collections, they are mainly used to de-reappear relationship elements without the need to fetch a single specified value at all.
#Note 2:{} can be used to define dicts as well as collections, but the elements in the dictionary must be in key:value format. Now we want to define an empty dictionary and an empty collection. How can we define both exactly?
d = {} #The default is an empty dictionary
s = set() #This is the definition of an empty set7.3 Type Conversion
# However, any data type that can be traversed by a for loop (emphasizing that every value traversed must be of an immutable type) can be passed to set() to be converted to a set type
>>> s = set([1,2,3,4])
>>> s1 = set((1,2,3,4))
>>> s2 = set({'name':'jason',})
>>> s3 = set('egon')
>>> s,s1,s2,s3
{1, 2, 3, 4} {1, 2, 3, 4} {'name'} {'e', 'o', 'g', 'n'}7.4 Use
7.4.1 Relational Operations
We define two sets, friends and friends2, to store the names of friends of two people, and then use these two sets as examples to illustrate the relational operation of sets.
>>> friends1 = {"zero","kevin","jason","egon"} # User 1 Friends
>>> friends2 = {"Jy","ricky","jason","egon"} # User 2 FriendsThe relationship between the two sets is illustrated below
Illustration: Demonstration set illustration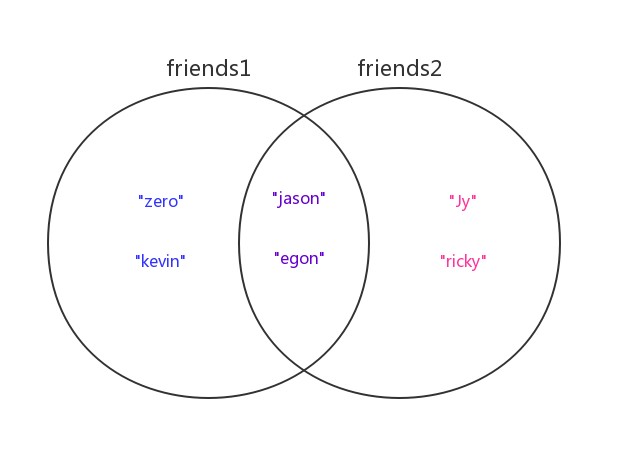
# 1. Aggregate (|): Ask all friends of two users (repeat only one)
>>> friends1 | friends2
{'kevin', 'ricky', 'zero', 'jason', 'Jy', 'egon'}
# 2. Intersection (&): Seek common friends of two users
>>> friends1 & friends2
{'jason', 'egon'}
# 3. Difference sets (-):
>>> friends1 - friends2 # Ask User 1 for a unique friend
{'kevin', 'zero'}
>>> friends2 - friends1 # Ask User 2 for unique friends
{'ricky', 'Jy'}
# 4.Symmetric difference set(^) # Ask for friends that are unique to two users (that is, remove friends in common)
>>> friends1 ^ friends2
{'kevin', 'zero', 'ricky', 'Jy'}
# 5. Is the value equal (==)
>>> friends1 == friends2
False
# 6. Parent Set: Does one set contain another set
# 6.1 Include returns True
>>> {1,2,3} > {1,2}
True
>>> {1,2,3} >= {1,2}
True
# 6.2 Returns True if there is no inclusion relationship
>>> {1,2,3} > {1,3,4,5}
False
>>> {1,2,3} >= {1,3,4,5}
False
# 7. Subsets
>>> {1,2} < {1,2,3}
True
>>> {1,2} <= {1,2,3}
True####7.4.2 weight removal
Illustration: Fig. 12
Limitations of set de-duplication
# 1. Only for immutable types # 2. The set itself is out of order and cannot be preserved after de-duplication
Examples are as follows
>>> l=['a','b',1,'a','a']
>>> s=set(l)
>>> s # Convert List to Collection
{'b', 'a', 1}
>>> l_new=list(s) # Return the collection to the list
>>> l_new
['b', 'a', 1] # Duplicates removed, but the order was disrupted
# For immutable types, and ensuring order requires that we write our own code implementation, for example
l=[
{'name':'lili','age':18,'sex':'male'},
{'name':'jack','age':73,'sex':'male'},
{'name':'tom','age':20,'sex':'female'},
{'name':'lili','age':18,'sex':'male'},
{'name':'lili','age':18,'sex':'male'},
]
new_l=[]
for dic in l:
if dic not in new_l:
new_l.append(dic)
print(new_l)
# Result: Duplication is removed, sequence is guaranteed, and weight is removed for the immutable type
[
{'age': 18, 'sex': 'male', 'name': 'lili'},
{'age': 73, 'sex': 'male', 'name': 'jack'},
{'age': 20, 'sex': 'female', 'name': 'tom'}
]
7.4.3 Other Operations
Illustration: Hoax Fig. 13
# 1. Length
>>> s={'a','b','c'}
>>> len(s)
3
# 2. Member Operations
>>> 'c' in s
True
# 3. Cycle
>>> for item in s:
... print(item)
...
c
a
b7.5 Exercises

"""
1. Relational operations
There are two collections, pythons is the student name collection for the python course and linuxs is the student name collection for the linux course
pythons={'jason','egon','kevin','ricky','gangdan','biubiu'}
linuxs={'kermit','tony','gangdan'}
1. Find a set of names of trainees who sign up for both python and linux courses
2. Find a collection of names of all the students who have registered
3. Find out the names of only the trainees who sign up for the python course
4. Find a set of student names without both courses
"""
#Get a collection of names of trainees who sign up for both python and linux courses
>>> pythons & linuxs
#Find a collection of names for all students who sign up
>>> pythons | linuxs
#Find out the names of only the trainees who sign up for the python course
>>> pythons - linuxs
#Find a set of student names without both courses
>>> pythons ^ linuxsEight Variable Types and Invariant Types
Variable data type: when the value changes, the memory address does not change, that is, the id does not change, indicating that the original value is changing
Invariant type: When the value changes, the memory address also changes, that is, the id also changes, proving that the original value is not changed, and that a new value is generated
Number type:
>>> x = 10 >>> id(x) 1830448896 >>> x = 20 >>> id(x) 1830448928 # Memory address changed, indicating that integer is an immutable data type, as is floating point

Character string
>>> x = "Jy" >>> id(x) 938809263920 >>> x = "Ricky" >>> id(x) 938809264088 # Memory address changed, indicating that the string is an immutable data type
list
>>> list1 = ['tom','jack','egon']
>>> id(list1)
486316639176
>>> list1[2] = 'kevin'
>>> id(list1)
486316639176
>>> list1.append('lili')
>>> id(list1)
486316639176
# When manipulating a list's values, the values change but the memory address does not change, so the list is a variable data type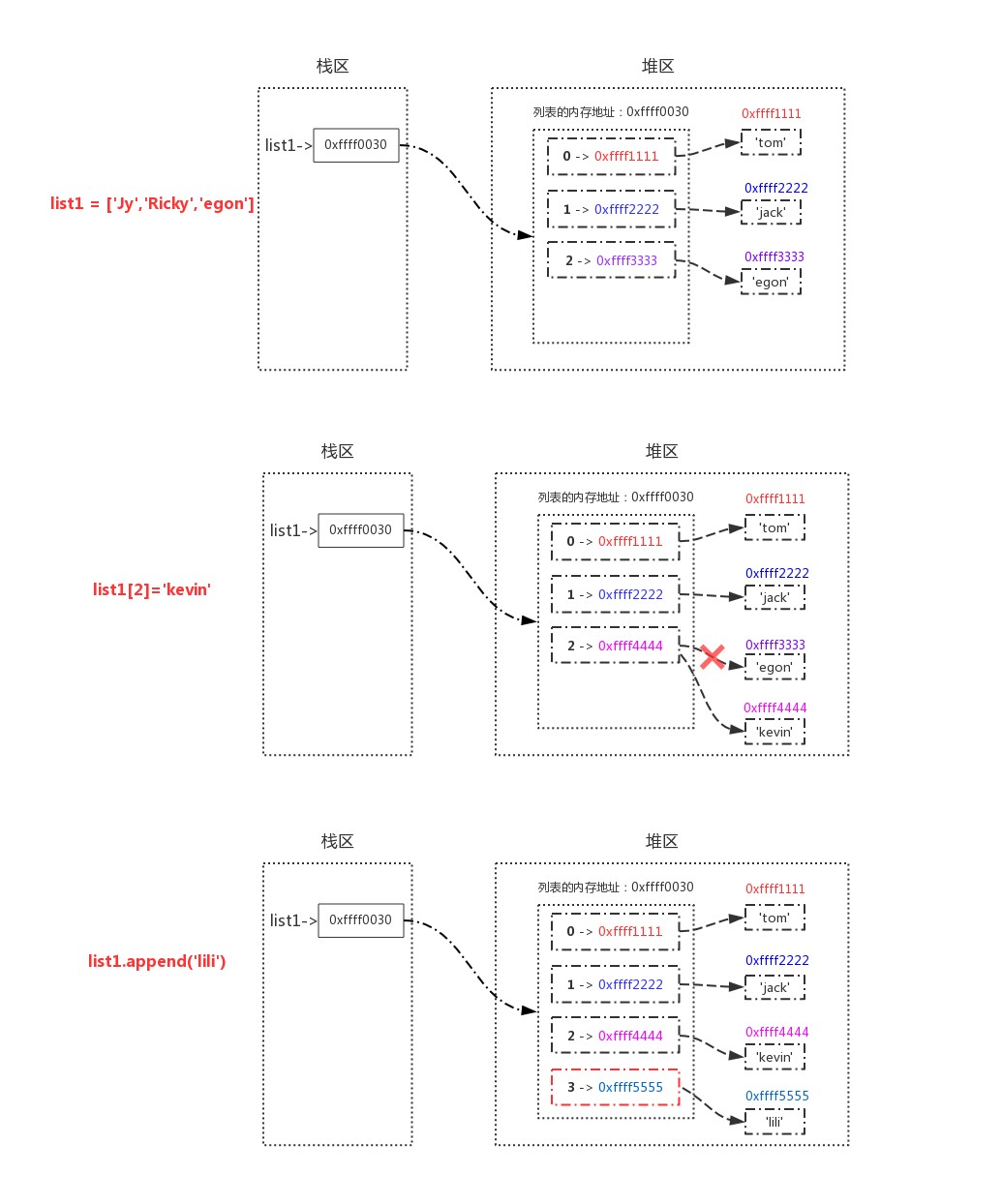
tuple
>>> t1 = ("tom","jack",[1,2])
>>> t1[0]='TOM' # Error: TypeError
>>> t1.append('lili') # Error: TypeError
# Elements within a tuple cannot be modified, meaning that the memory address pointed to by the index within the tuple cannot be modified
>>> t1 = ("tom","jack",[1,2])
>>> id(t1[0]),id(t1[1]),id(t1[2])
(4327403152, 4327403072, 4327422472)
>>> t1[2][0]=111 # If there is a mutable type in the tuple, it can be modified, but the modified memory address does not change
>>> t1
('tom', 'jack', [111, 2])
>>> id(t1[0]),id(t1[1]),id(t1[2]) # View id remains unchanged
(4327403152, 4327403072, 4327422472)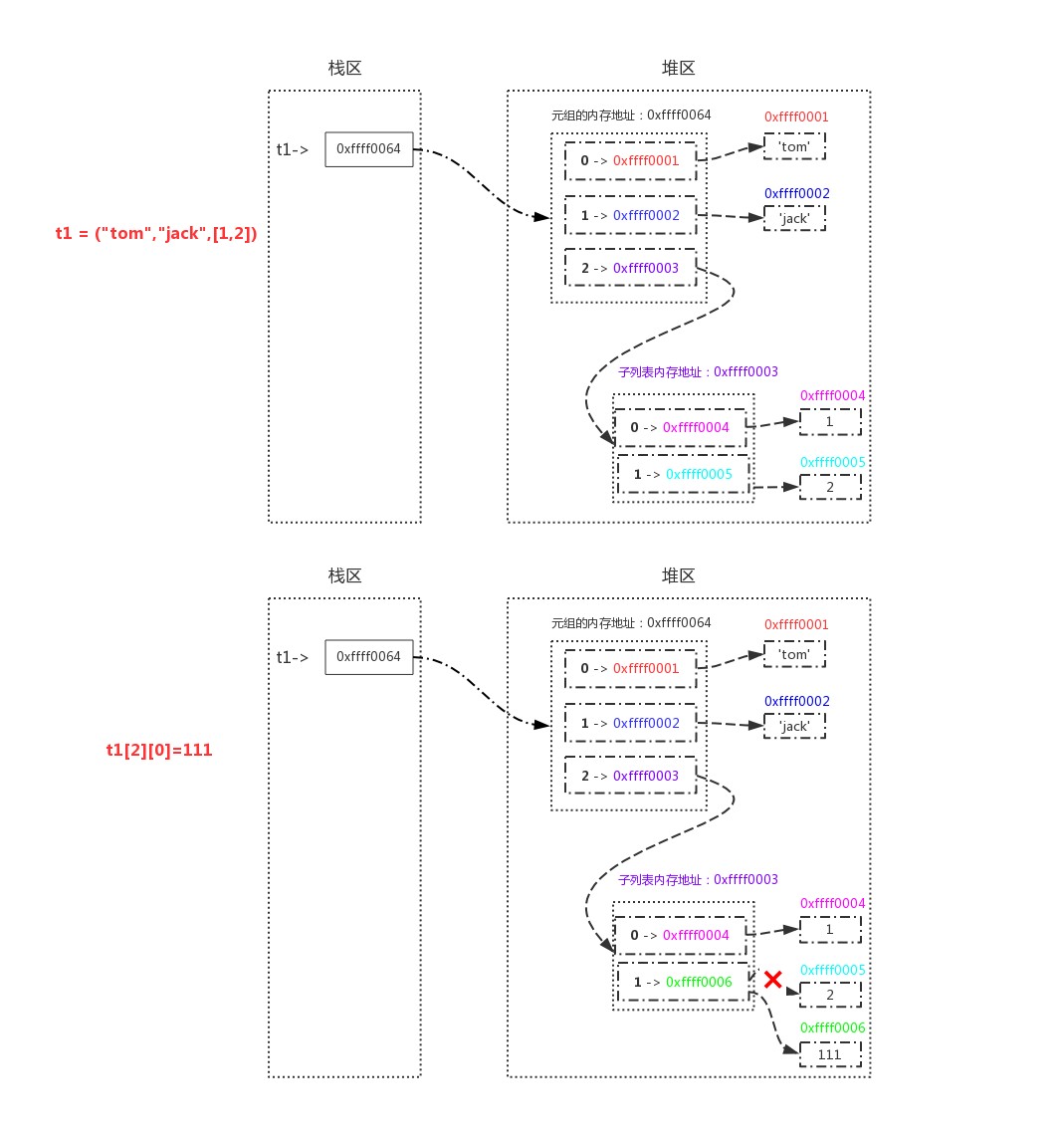
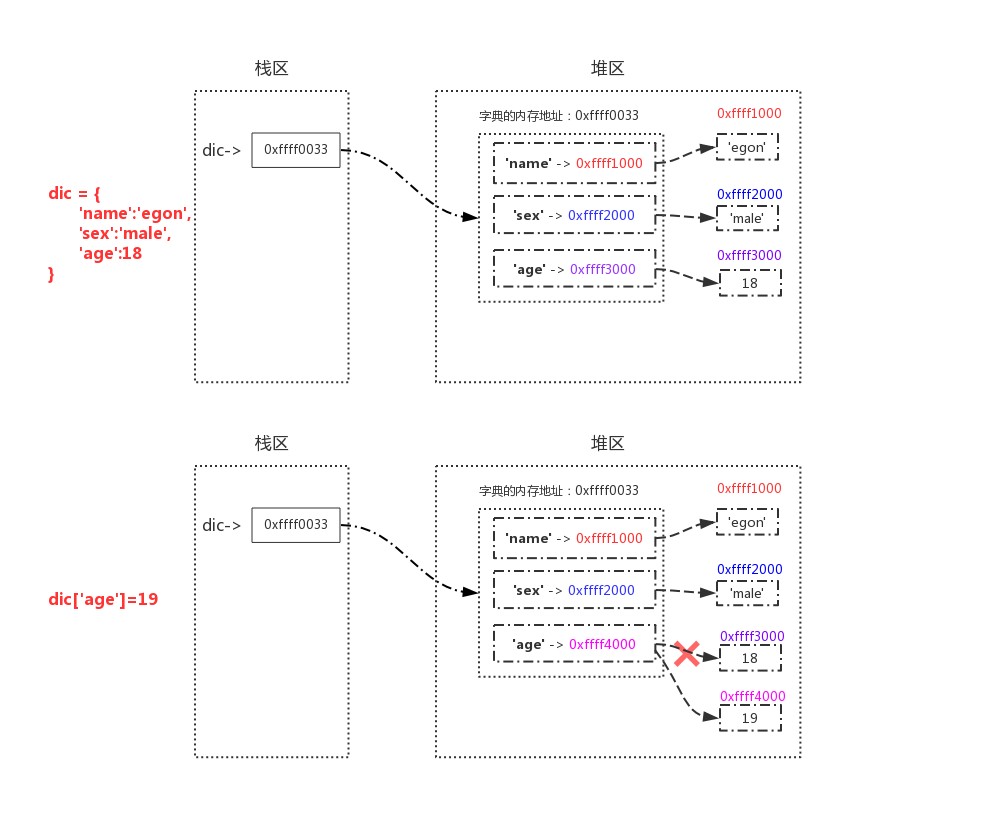
Dictionaries
>>> dic = {'name':'egon','sex':'male','age':18}
>>>
>>> id(dic)
4327423112
>>> dic['age']=19
>>> dic
{'age': 19, 'sex': 'male', 'name': 'egon'}
>>> id(dic)
4327423112
# When a dictionary is operated on, the id of the dictionary remains unchanged if the value changes, that is, the dictionary is also a variable data type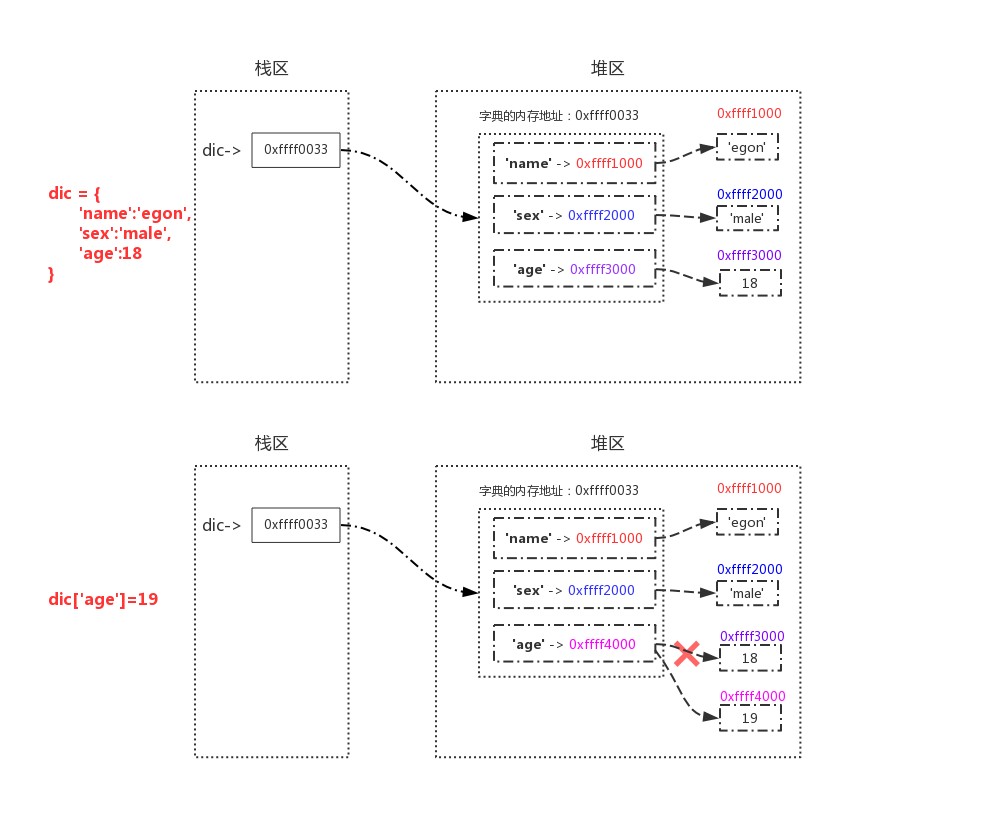
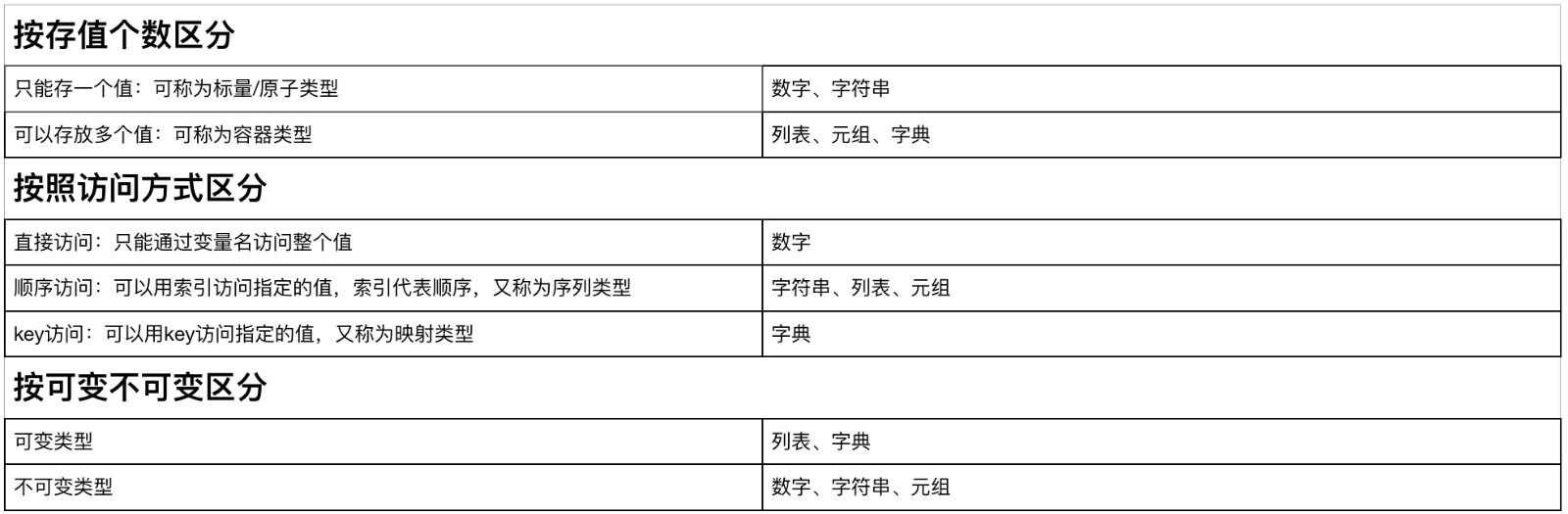
9 Summary of Data Types

Illustration: Summary of data types