In the Oracle database, the optimizer needs to rely on the collection of statistical information of related objects in order to generate the optimal execution plan. The database can automatically collect the execution plan or use the package DBMS_STATS is collected manually. This article does not explain the collection of general statistics. It focuses on the collection of Extended Statistics.
1 Introduction to extended statistics
When executing SQL, the statistics of a single column after the where condition can easily determine the predicate selectivity of the corresponding column. However, if multiple columns of the same table are included as predicates after the where condition, the statistics of a single column cannot show the relationship between columns. At this time, the execution plan obtained by the optimizer based on the statistics of a single column may not be optimal Yes. This problem can be solved by column group. By collecting statistical information of column group, we can reflect the relationship between a group of columns, so that the optimizer can choose the optimal execution plan. The statistical information of column group is called extended statistical information. In Oracle, extended statistics include:
- Column group statistics: when multiple columns of a table appear in a SQL statement at the same time, this type of extended statistics can improve cardinality estimation
- Expression statistics: this type of statistics improves optimizer evaluation when expressions are used on predicates.
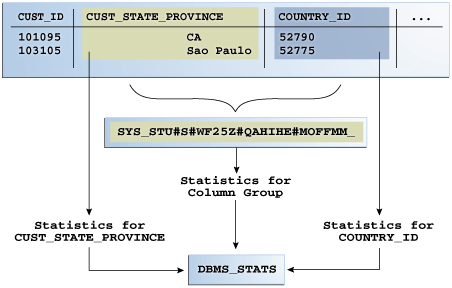
As shown in the figure: sh.customers Two columns cust in the table_ state_ Province and contry_ The statistics of the ID column, as well as the statistics of the column group composed of these two columns, the name of the column group is generated by the system.
2 use general statistics
1) Experimental environment
SQL> select * from v$version; BANNER CON_ID -------------------------------------------------------------------------------- ---------- Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production 0 PL/SQL Release 12.1.0.2.0 - Production 0 CORE 12.1.0.2.0 Production 0 TNS for Linux: Version 12.1.0.2.0 - Production 0 NLSRTL Version 12.1.0.2.0 - Production 0
2) Build test data
SQL> create table sh.customers_new as select * from sh.customers;
Table created.
SQL> exec dbms_stats.gather_table_stats('SH','CUSTOMERS_NEW',method_opt => 'for all columns size 1');
PL/SQL procedure successfully completed.3) Query column statistics
SQL> select column_name,num_distinct,histogram
from dba_tab_col_statistics
where owner='SH' and table_name='CUSTOMERS_NEW' and column_name in('CUST_STATE_PROVINCE','COUNTRY_ID');
COLUMN_NAME NUM_DISTINCT HISTOGRAM
------------------------------ ------------ ---------------
CUST_STATE_PROVINCE 145 NONE
COUNTRY_ID 19 NONE3) Total number of query tables and satisfying cust_ state_ Amount of data for province ='ca '
SQL> select count(1) from sh.customers_new; COUNT(1) ---------- 55500 SQL> select count(1) from sh.customers_new where cust_state_province='CA'; COUNT(1) ---------- 3341
4) View the execution plan corresponding to a single column
SQL> explain plan for
2 select * from sh.customers_new where cust_state_province='CA';
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------------------------------------------------------------
Plan hash value: 3410015392
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 383 | 72387 | 423 (1)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| CUSTOMERS_NEW | 383 | 72387 | 423 (1)| 00:00:01 |
-----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------------------------------------------------------------
1 - filter("CUST_STATE_PROVINCE"='CA')
13 rows selected.Look at the following calculation to match the number of rows estimated by the optimizer:
SQL> select 55500/145 from dual;
55500/145
----------
382.758621
5) View the execution plan corresponding to the combination condition
SQL> explain plan for
2 select * from sh.customers_new where cust_state_province='CA' and country_id='52790';
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------------------------------------------------------------
Plan hash value: 3410015392
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 20 | 3780 | 423 (1)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| CUSTOMERS_NEW | 20 | 3780 | 423 (1)| 00:00:01 |
-----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------------------------------------------------------------
1 - filter("CUST_STATE_PROVINCE"='CA' AND "COUNTRY_ID"=52790)
13 rows selected.The result shows that the optimizer estimates 20 rows, which is the same as the following calculation, but the actual number of rows is 3341. Why?
SQL> select 55500/145/19 from dual;
55500/145/19
------------
20.1451906
First of all, the optimizer does not know the relationship between the two columns and CA in country 52790, which greatly underestimates the returned data row;
3 use rank statistics
Through the above experiments, we can know that if there is a certain relationship between columns and the optimizer cannot accurately evaluate the number of rows returned when there is a combination condition in the where condition, then in this case, we can collect the statistical information of the combination columns.
1) Collect composite column statistics
begin
dbms_stats.gather_table_stats('SH',
'CUSTOMERS_NEW',
method_opt => 'for all columns size 1,for columns (cust_state_province,country_id) size skewonly');
end;
/
PL/SQL procedure successfully completed.2) View the execution plan corresponding to the combination condition
explain plan for
select * from sh.customers_new where cust_state_province='CA' and country_id='52790';
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------------------------------------------------------------
Plan hash value: 3410015392
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3341 | 655K| 423 (1)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| CUSTOMERS_NEW | 3341 | 655K| 423 (1)| 00:00:01 |
-----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------------------------------------------------------------
1 - filter("CUST_STATE_PROVINCE"='CA' AND "COUNTRY_ID"=52790)
13 rows selected.It can be seen that the estimated number of rows is 3341, while the actual number of rows is 3341, which is the same as the real result.
SQL> select count(1) from sh.customers_new where cust_state_province='CA' and country_id='52790';
COUNT(1)
----------
3341
3) Delete extended statistics
begin
dbms_stats.drop_extended_stats('sh',
'CUSTOMERS_NEW',
'(cust_state_province, country_id)');
end;
/
PL/SQL procedure successfully completed.The above is a demonstration of column group statistics in extended statistics.