Here, let's sort out the relevant knowledge of consumeGroup
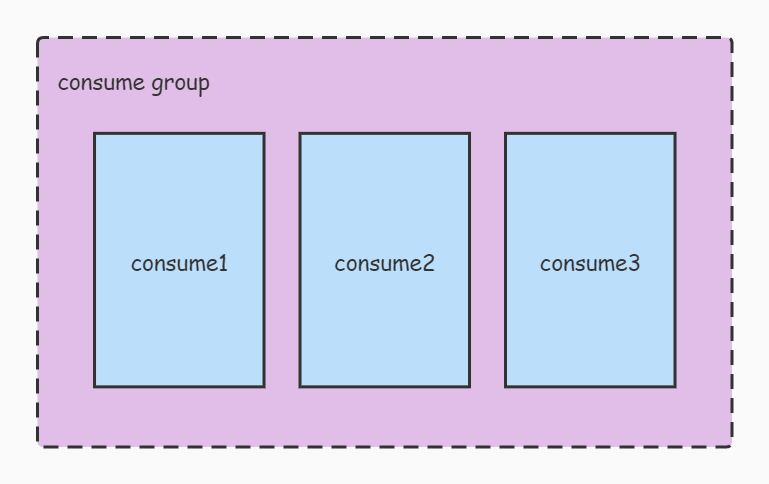
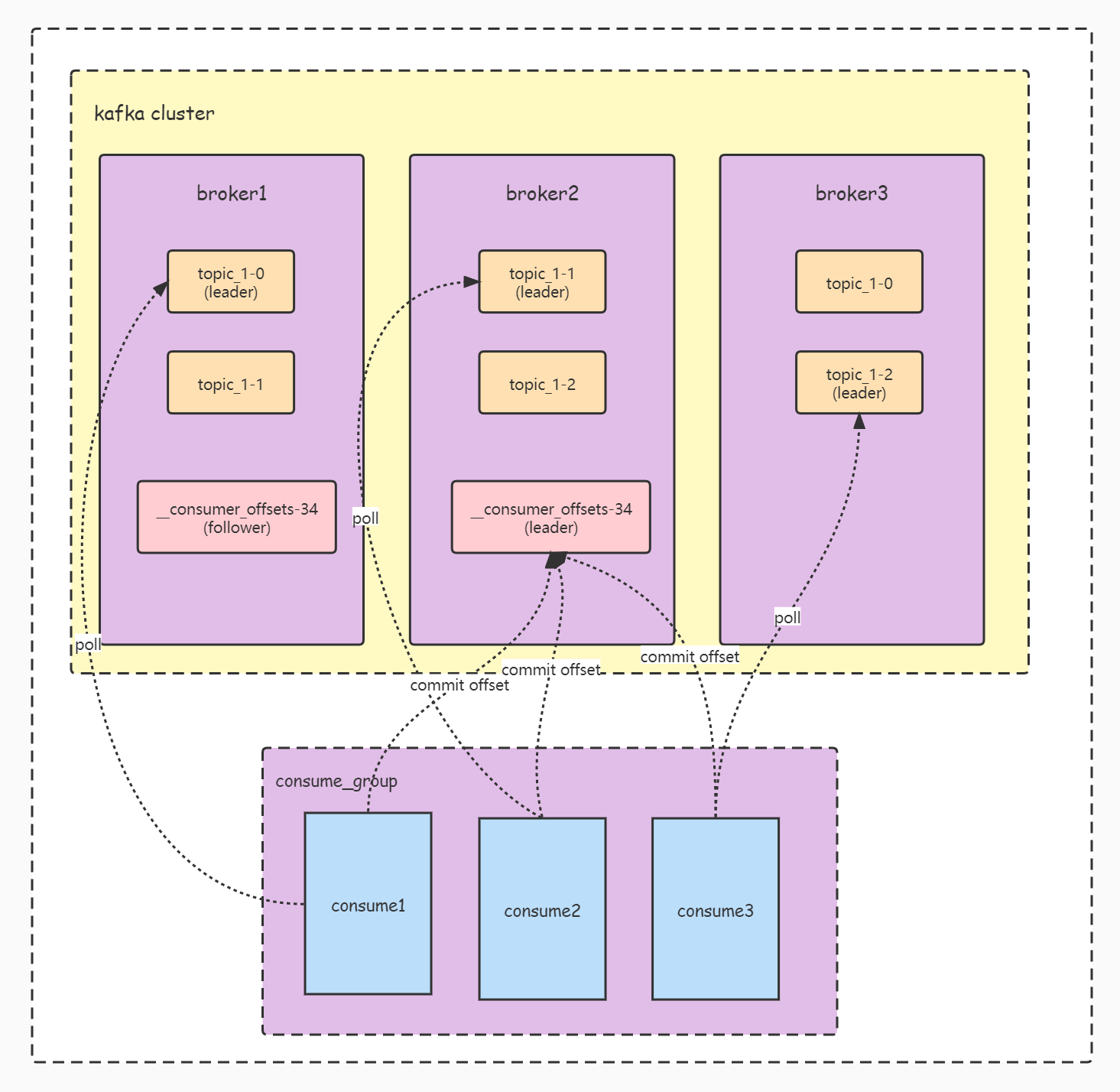
1. First, we will set groupId for each consumer. Consumers with the same groupId and subscribed to the same topic will form a consumeGroup, as shown in Figure 1
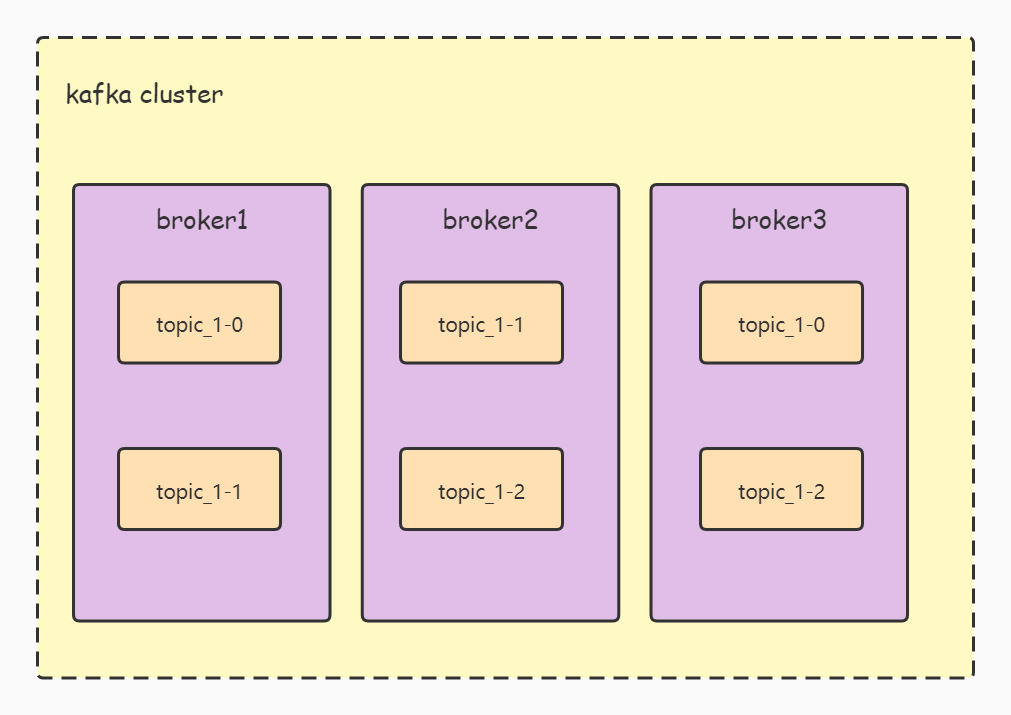
2. For the topic on the Server side, there is the concept of partition, as shown in Figure 2
3. Now we have multiple consumers and multiple partitions. Which consumer will consume which partition? It is determined by the partition allocation policy when consumer starts.
-
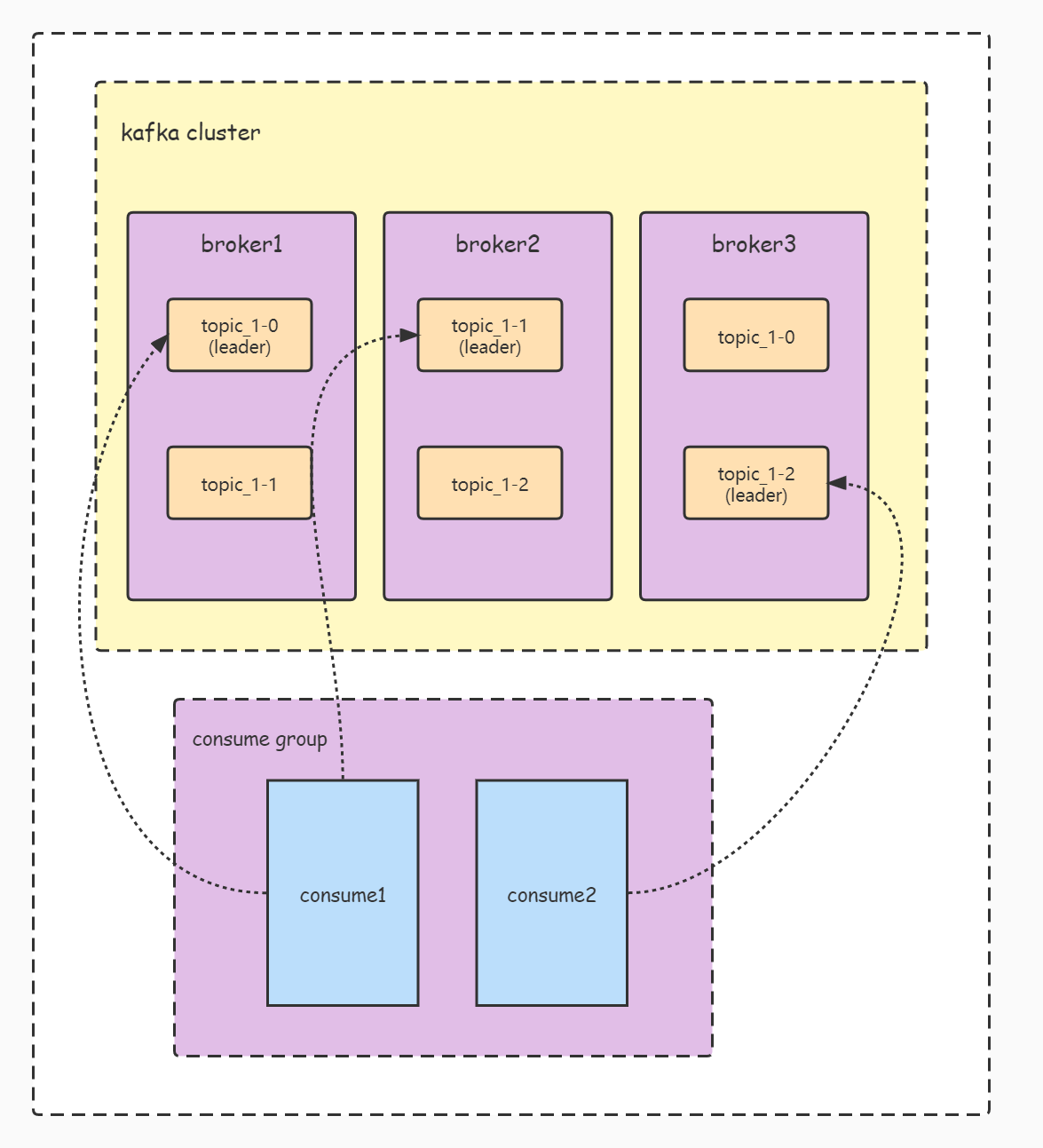
If the number of consumers is less than the number of partitions, one consumer may consume multiple partitions, as shown in Figure 3
-
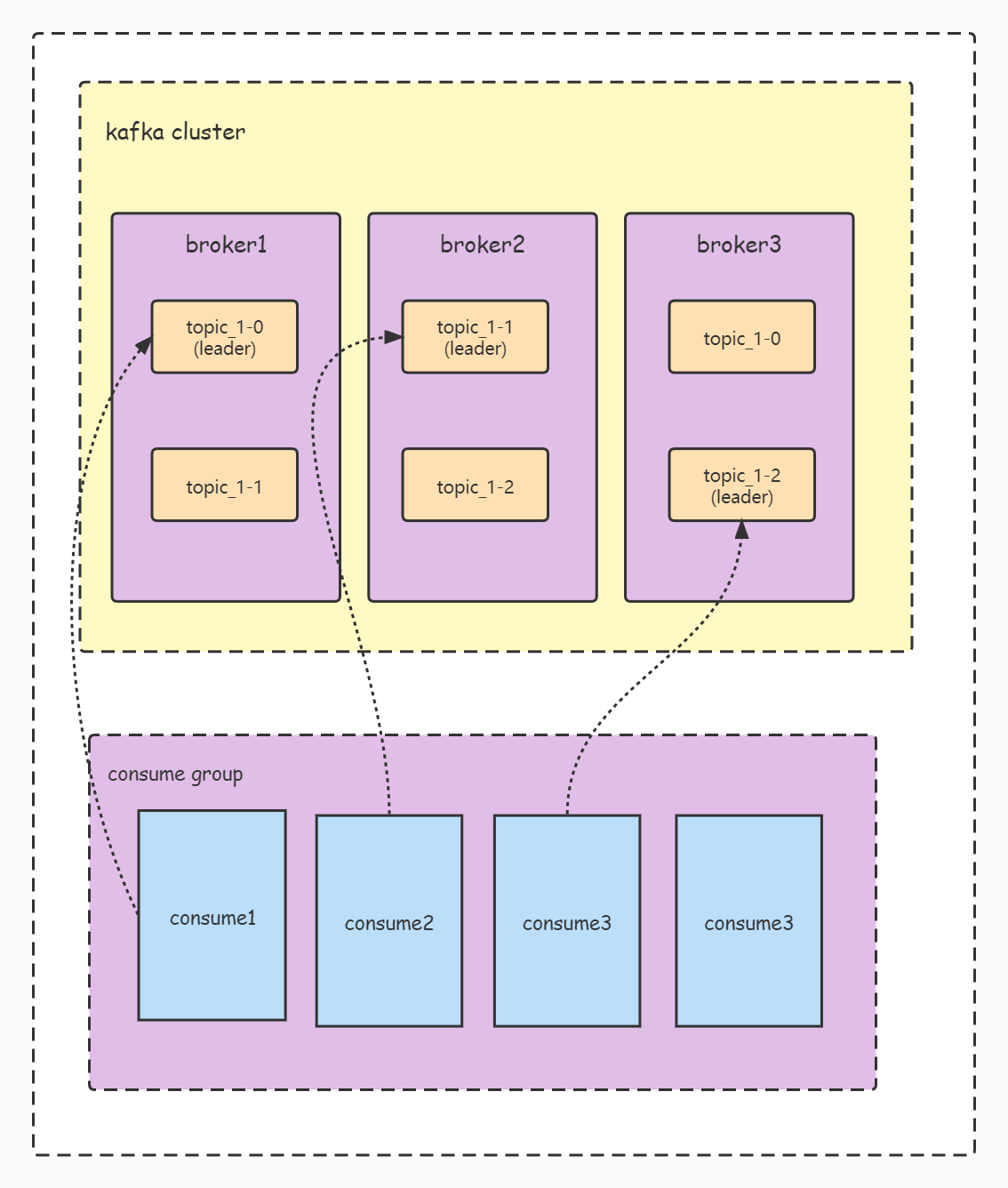
If the number of consume rs is greater than the number of partition s, there will be idle consumption threads, as shown in Figure 4
4. kafka's built-in topic: consumer_offsets specifically records the consumption location information. Since it is a built-in topic, it naturally has the concepts of partition and partition leader. The consumption locations of the same groupId will be recorded in the same partition. In this article, findCoordinator is the leader node that finds the partition corresponding to the groupId, Only when we know this node can we submit the displacement information here for saving. If there are other copies of the partition, the node will also synchronize the displacement information with other copies. Interaction with this node is done by the GroupCoordinator.
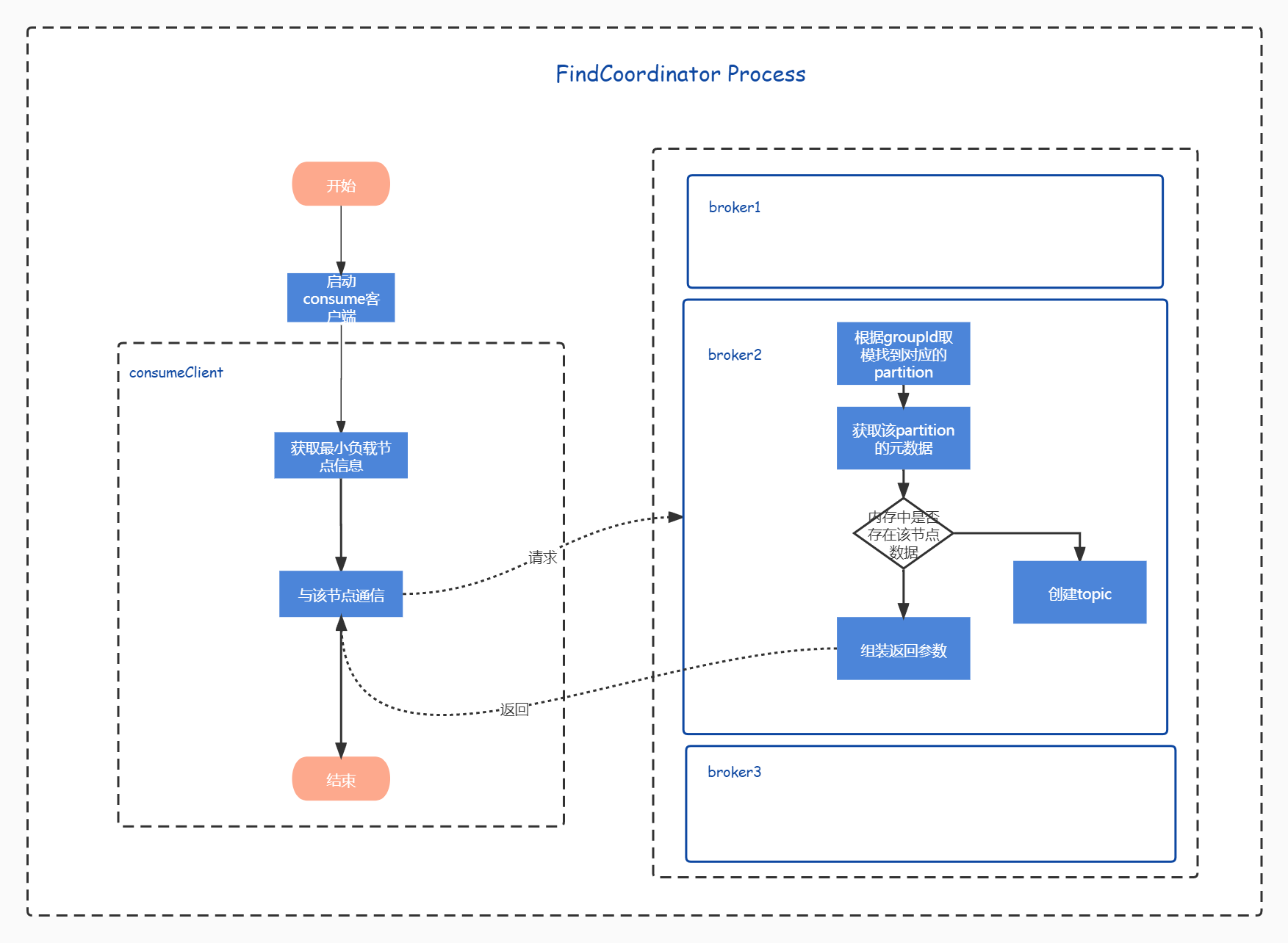
findCoordinator process presentation
Client source code analysis
Let's put the findCoordinator code here. Looking at other consumer codes, we can find that the format of communication between the client and kafkaServer is mostly like this. If the communication finds that the information of the GroupCoordinator has not been obtained at one time, continue to retry until it times out. The timeout here is the timeout time passed in during poll, This time setting runs through the running code of the whole consumer.
protected synchronized boolean ensureCoordinatorReady(final Timer timer) {
//If you have not joined the group, communicate with the group
if (!coordinatorUnknown())
return true;
do {
if (findCoordinatorException != null && !(findCoordinatorException instanceof RetriableException)) {
final RuntimeException fatalException = findCoordinatorException;
findCoordinatorException = null;
throw fatalException;
}
final RequestFuture<Void> future = lookupCoordinator();
client.poll(future, timer);
//If the callback has not been completed, it indicates that it has timed out
if (!future.isDone()) {
// ran out of time
break;
}
if (future.failed()) {
if (future.isRetriable()) {
log.debug("Coordinator discovery failed, refreshing metadata");
client.awaitMetadataUpdate(timer);
} else
throw future.exception();
//After obtaining the group information, the client will establish a connection with the node corresponding to the group. If it is unavailable, it will try again
} else if (coordinator != null && client.isUnavailable(coordinator)) {
// we found the coordinator, but the connection has failed, so mark
// it dead and backoff before retrying discovery
markCoordinatorUnknown();
timer.sleep(rebalanceConfig.retryBackoffMs);
}
//If the communication with group is successful, the loop will jump out
} while (coordinatorUnknown() && timer.notExpired());
return !coordinatorUnknown();
}
Here's another point. You can see from the tracking code that the following code will have the same logic after each check and communication with the Server. You can think carefully. The coordinator is the obtained group node object, client Isunavailable (Coordinator) is to establish a connection with the group. Every time it is judged that the coordinator is not empty and the connection between the client and the group fails, the coordinator is set to empty. Why is this? It is likely that the node is offline or unavailable after requesting the information of the group. At this time, the Server is likely to be in the process of election, so we need to clear the coordinator and communicate again after the election of the Server.
protected synchronized Node checkAndGetCoordinator() {
if (coordinator != null && client.isUnavailable(coordinator)) {
markCoordinatorUnknown(true);
return null;
}
return this.coordinator;
}
org.apache.kafka.clients.consumer.internals.AbstractCoordinator#lookupCoordinator
A highlight of this code is to first find the node with the smallest load, and then communicate with the node to obtain the information of the group node.
protected synchronized RequestFuture<Void> lookupCoordinator() {
if (findCoordinatorFuture == null) {
// find a node to ask about the coordinator
//Communication with node with minimum load
Node node = this.client.leastLoadedNode();
if (node == null) {
log.debug("No broker available to send FindCoordinator request");
return RequestFuture.noBrokersAvailable();
} else {
findCoordinatorFuture = sendFindCoordinatorRequest(node);
// remember the exception even after the future is cleared so that
// it can still be thrown by the ensureCoordinatorReady caller
findCoordinatorFuture.addListener(new RequestFutureListener<Void>() {
@Override
public void onSuccess(Void value) {} // do nothing
@Override
public void onFailure(RuntimeException e) {
findCoordinatorException = e;
}
});
}
}
return findCoordinatorFuture;
}
org.apache.kafka.clients.NetworkClient#leastLoadedNode
Let's take a look at how to find the node with the smallest load. The code here is very particular. First, take the random number to prevent connecting from the first node every time. If it is judged that there is no in transit request, return to the node directly. Otherwise, take the node with the smallest in transit request. If the node does not exist, take the connected node and the node that needs to be retried in turn, If a non null node is found, the node is returned; otherwise, null is returned.
public Node leastLoadedNode(long now) {
List<Node> nodes = this.metadataUpdater.fetchNodes();
if (nodes.isEmpty())
throw new IllegalStateException("There are no nodes in the Kafka cluster");
int inflight = Integer.MAX_VALUE;
Node foundConnecting = null;
Node foundCanConnect = null;
Node foundReady = null;
//Take a node at random
int offset = this.randOffset.nextInt(nodes.size());
for (int i = 0; i < nodes.size(); i++) {
int idx = (offset + i) % nodes.size();
Node node = nodes.get(idx);
//If the node is connectable, the selector is idle, and the send queue is idle, the request can be sent
if (canSendRequest(node.idString(), now)) {
//inFlightRequests records the request that has been sent but has not received the response. It is determined here that if the node does not have such data, it will be returned directly as the minimum load node
int currInflight = this.inFlightRequests.count(node.idString());
if (currInflight == 0) {
// if we find an established connection with no in-flight requests we can stop right away
log.trace("Found least loaded node {} connected with no in-flight requests", node);
return node;
//Otherwise, the node with the minimum count in inFlightRequests is taken as the minimum load node
} else if (currInflight < inflight) {
// otherwise if this is the best we have found so far, record that
inflight = currInflight;
foundReady = node;
}
} else if (connectionStates.isPreparingConnection(node.idString())) {
foundConnecting = node;
} else if (canConnect(node, now)) {
//If the node is not recorded or the retry time is exceeded after disconnection, the node is allowed to be set
foundCanConnect = node;
} else {
log.trace("Removing node {} from least loaded node selection since it is neither ready " +
"for sending or connecting", node);
}
}
// We prefer established connections if possible. Otherwise, we will wait for connections
// which are being established before connecting to new nodes.
//Give priority to nodes in good state
if (foundReady != null) {
log.trace("Found least loaded node {} with {} inflight requests", foundReady, inflight);
return foundReady;
} else if (foundConnecting != null) {
log.trace("Found least loaded connecting node {}", foundConnecting);
return foundConnecting;
} else if (foundCanConnect != null) {
log.trace("Found least loaded node {} with no active connection", foundCanConnect);
return foundCanConnect;
} else {
log.trace("Least loaded node selection failed to find an available node");
return null;
}
}
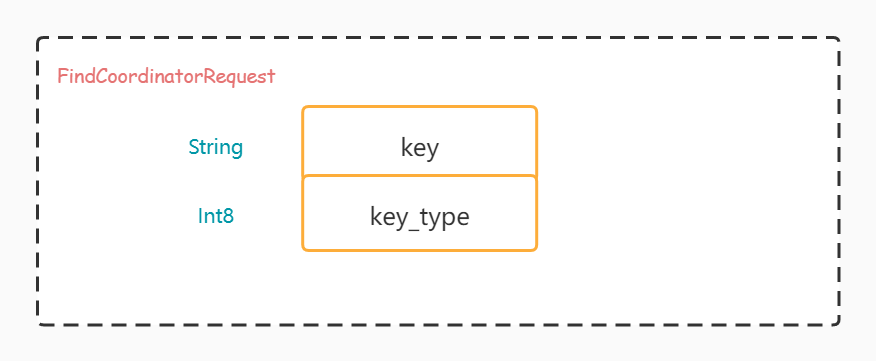
Disassemble FindCoordinatorRequest
Let's see what data is sent through the following figure, key_type has two enumerations, one is GROUP and the other is TRANSACTION. If type is GROUP, the key is groupId
Server source code analysis
kafka.server.KafkaApis#handleFindCoordinatorRequest
The server still processes the request through KafkaApi, and the code is relatively simple.
def handleFindCoordinatorRequest(request: RequestChannel.Request): Unit = {
val findCoordinatorRequest = request.body[FindCoordinatorRequest]
//Check data
//... omit some codes
// get metadata (and create the topic if necessary)
val (partition, topicMetadata) = CoordinatorType.forId(findCoordinatorRequest.data.keyType) match {
case CoordinatorType.GROUP =>
//4.1 find the corresponding distribution partition
val partition = groupCoordinator.partitionFor(findCoordinatorRequest.data.key)
//4.2 get the corresponding metadata
val metadata = getOrCreateInternalTopic(GROUP_METADATA_TOPIC_NAME, request.context.listenerName)
(partition, metadata)
case CoordinatorType.TRANSACTION =>
val partition = txnCoordinator.partitionFor(findCoordinatorRequest.data.key)
val metadata = getOrCreateInternalTopic(TRANSACTION_STATE_TOPIC_NAME, request.context.listenerName)
(partition, metadata)
case _ =>
throw new InvalidRequestException("Unknown coordinator type in FindCoordinator request")
}
//Assembly return parameters
//... omit some codes
}
}
kafka.coordinator.group.GroupMetadataManager#partitionFor
We know that the corresponding locus after consumption is stored in kafka's built-in topic named "_consumer_offsets", During the initialization of built-in topic, the number of partitions is determined by the "offsets.topic.num.partitions" parameter. The default value is 50. The offset of the same consumeGroup will eventually be saved in one of the partitions, and the partition to be saved is determined by the following code. You can see that the logic is very simple, that is, take the hashCode of groupId, and then take the modulus of the total number of partitions. For example, groupId is " consume_group "will eventually save the site in partition 34.
def partitionFor(groupId: String): Int = Utils.abs(groupId.hashCode) % groupMetadataTopicPartitionCount
kafka.server.KafkaApis#getOrCreateInternalTopic
Here, first get the data of the corresponding topic from the metadata cache of the current node. If not, create it. You can also guess from this code that the creation principle of kafka built-in topic is a lazy loading idea. The corresponding topicPartition file will be created only after the first consume r is accessed.
private def getOrCreateInternalTopic(topic: String, listenerName: ListenerName): MetadataResponse.TopicMetadata = {
val topicMetadata = metadataCache.getTopicMetadata(Set(topic), listenerName)
topicMetadata.headOption.getOrElse(createInternalTopic(topic))
}
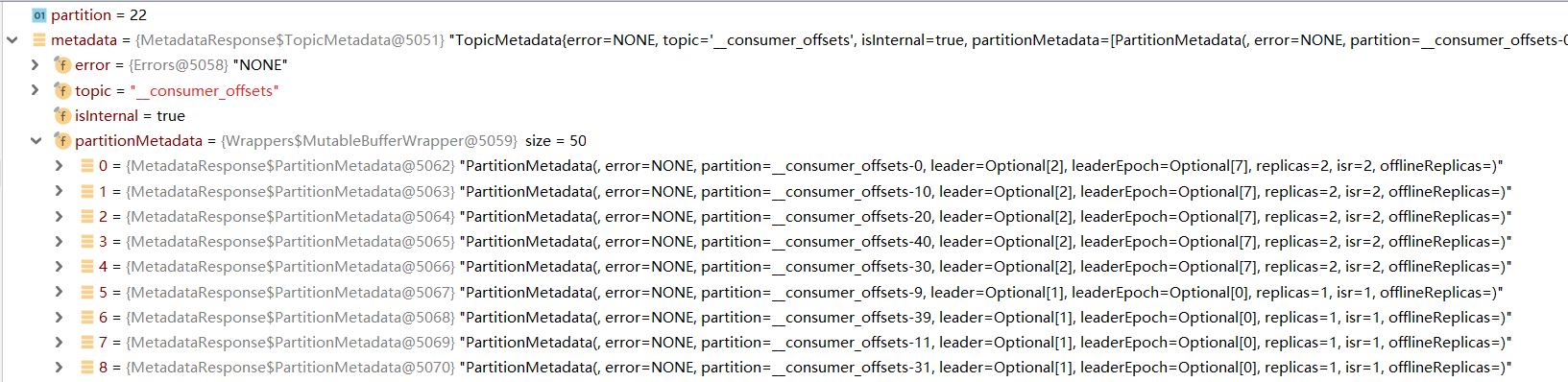
The topicMetadata here is an object that returns a similar list corresponding to the input parameter topic. Because the input parameter has only one topic, the first data is directly taken. The data structure is shown in the figure below, which can more intuitively understand the return parameters.

kafka.server.KafkaApis#createTopic
Here is the code to create the built-in topic, which is to write the following data in zk
1. The / config/topics/{topic} node writes the following dynamic configuration:
{"version":1,"config":{"segment.bytes":"104857600","compression.type":"producer","cleanup.policy":"compact"}.
Where segment Bytes refers to the offsets configured according to the server topic. segment.bytes. The default value is 104857600. This configuration is for the topic compression strategy. This involves the log module, which will be described in detail later.
2. The / brokers/topics/{topic} node writes the replica information of each partition. This involves the creation partition allocation strategy of topic, which will be described in detail later.
This approach is also very interesting. It shows that if we create topic without script, we can create it successfully by directly writing data in zk. Here, you can also guess that the implementation logic triggers the server controller to listen to the zk node and create the corresponding topicPartition according to the written ar data.
There is another point to note here. We know that kafka takes time to create a topic. The implementation method here is to write data to zk to trigger the creation of a topic process. It is an asynchronous method. After writing data to zk, an error and leader will be returned_ NOT_ Available: after the process of creating topic is completed and the metaData of each node is synchronized, the node information findCoordinatorRequest will be successfully returned from the metaData.
private def createTopic(topic: String,
numPartitions: Int,
replicationFactor: Int,
properties: util.Properties = new util.Properties()): MetadataResponse.TopicMetadata = {
try {
adminZkClient.createTopic(topic, numPartitions, replicationFactor, properties, RackAwareMode.Safe)
info("Auto creation of topic %s with %d partitions and replication factor %d is successful"
.format(topic, numPartitions, replicationFactor))
new MetadataResponse.TopicMetadata(Errors.LEADER_NOT_AVAILABLE, topic, isInternal(topic),
util.Collections.emptyList())
} catch {
case _: TopicExistsException => // let it go, possibly another broker created this topic
new MetadataResponse.TopicMetadata(Errors.LEADER_NOT_AVAILABLE, topic, isInternal(topic),
util.Collections.emptyList())
case ex: Throwable => // Catch all to prevent unhandled errors
new MetadataResponse.TopicMetadata(Errors.forException(ex), topic, isInternal(topic),
util.Collections.emptyList())
}
}
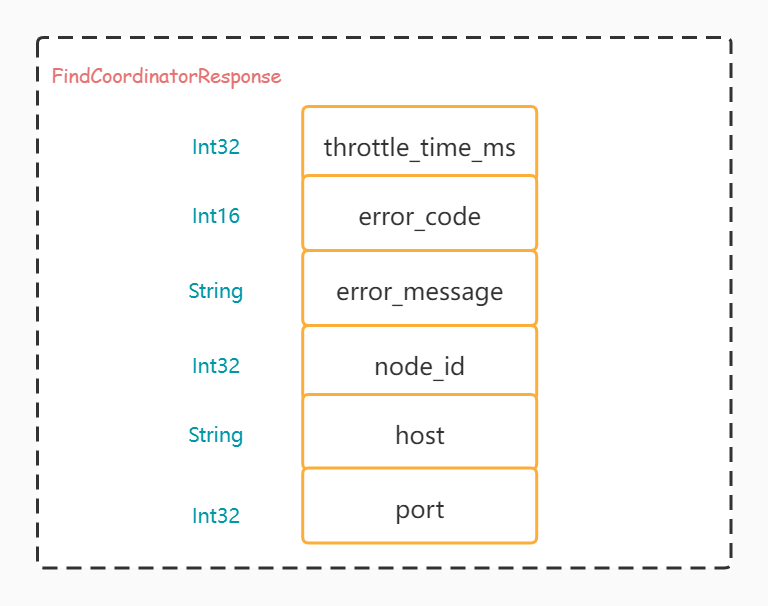
Disassemble FindCoordinatorResponse
Let's take a look at the returned data through the following figure. We can see that a lot of data was taken in the front, and only the node information of the leader was finally spelled into the return parameters
summary
The code itself is not very complex, but there are some details to consider. Careful consideration of these details will be very beneficial to our analysis of consume r exceptions in the future. The process is summarized below
1. Find minimum load node information
2. Send FindCoordinatorRequest to the minimum load node
3. The minimum load node processes the request.
- First, find the partition corresponding to the groupId
- Get the information of the partition through the metaData cached in memory. If it does not exist, create a topic
- Returns the found partition leader information