Chapter 4 concurrent programming
4.1 ~ 4.2 parallel concept
Parallel: parallel computing is a computing solution that attempts to solve problems more quickly using multiple processors executing parallel algorithms.
Sequential and parallel algorithms, concurrency
Difference between sequential algorithm and parallel algorithm:
The sequential algorithm is executed in one step according to all steps.
The parallel algorithm performs independent tasks according to the specified parallel algorithm.

Under rational circumstances, all tasks in parallel algorithms should run in real time at the same time. However, in real parallel execution, it can only be implemented in multi-core or multiprocessor systems. In single CPU systems, it can only be executed concurrently, that is, logically parallel execution.
thread
Thread is defined under the process. The process is an independent execution unit. In kernel mode, it is executed in a unique address space. Thread is an independent execution unit in a process's unified address space. The main thread can create other threads, and each thread can create more threads.
All threads of a process execute in the same address space of the process, but each thread is an independent execution unit.
Threads seem to be relatively lightweight compared to processes. Threads also have the following advantages:
- Faster thread creation and switching: to create a thread in a process, the operating system does not have to allocate memory and create a page table for the new thread, because the thread shares the same address space with the process. Therefore, creating a thread is faster than creating a process.
- Threads respond faster: a process has only one execution path. When a process is suspended, both processes will stop executing. Conversely, when a thread is suspended, other threads in the same process can continue to execute.
- Threads are more suitable for well row Computing: the goal of parallel computing is to use multiple execution paths to solve inter problems faster. Algorithms based on divide and conquer principles (such as binary tree search and quick sorting) often show a high degree of parallelism, which can improve the computing speed by using parallel or concurrent execution.
However, threads also have problems, need clear synchronization information, and have security problems. On the CPU, processing multithreaded programs requires each thread to switch back and forth, which increases the overhead and reduces the speed.
4.3 ~ 4.5 thread operation and program examples
Thread API provided by Pthread Library under Linux:
pthread_create(thread, attr, function, arg): create thread pthread_exit(status): terminate thread pthread_cancel(thread) : cancel thread pthread_attr_init(attr) : initialize thread attributes pthread_attr_destroy(attr): destroy thread attribute
Creating a thread: using pthread_create() to create a thread.
Terminate thread: after the thread function ends, the thread will terminate automatically. You can also call the function int pthraad_exit {void *status) completes the terminated operation.
Thread connection: a thread can wait for the termination of another thread through: int pthread_join (pthread_t thread, void * * status_ptr). The exit status of the terminated thread is returned by status_ptr.
4.6 thread synchronization
Because threads run in the process's unified address space, all threads in the same process share all global variables and data structures. Competition will occur when multiple threads need to modify the same variable or data structure. To prevent such problems, thread synchronization is required.
The simplest way is to add a lock. A lock is called a mutex. It can be used
- Static method to define the mutex m.
- Dynamic method, use pthread_mutex_init() function to set mutually exclusive attributes.
Or the method of using conditional variables. It is also divided into static and dynamic methods.
Producer consumer issues
A series of producer and consumer processes share a limited number of buffers. Each buffer has a specific item at a time. It is also called limited buffer problem. The main role of the producer is to generate a certain amount of data into the buffer, and then repeat the process. At the same time, consumers also consume this data in the buffer.
Semaphore
In the operating system, we have learned about semaphores. Semaphores represent the availability of a resource and are the general mechanism of process synchronization. There are P primitives and V primitives, both of which are atomic operations or basic operations.
Practice content process and problem solving process
Thread program test
The test is carried out according to the example given in the textbook. The test content is to use threads for quick sorting. The principle is: the main thread runs first, and then the main thread calls qsort (& ARG) to let the qsort() function execute and realize a quick sorting of N integers. In qsort(), the thread will select a benchmark element and then perform the operation of quick sorting.
The code is as follows:
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
typedef struct{
int upperbound;
int lowerbound;
}PARM;
#define N 10
int a[N]={5,1,6,4,7,2,9,8,0,3};// unsorted data
int print(){//print current a[] contents
int i;
printf("[");
for(i=0;i<N;i++)
printf("%d ",a[i]);
printf("]\n");
}
void *Qsort(void *aptr){
PARM *ap, aleft, aright;
int pivot, pivotIndex,left, right,temp;
int upperbound,lowerbound;
pthread_t me,leftThread,rightThread;
me = pthread_self();
ap =(PARM *)aptr;
upperbound = ap->upperbound;
lowerbound = ap->lowerbound;
pivot = a[upperbound];//pick low pivot value
left = lowerbound - 1;//scan index from left side
right = upperbound;//scan index from right side
if(lowerbound >= upperbound)
pthread_exit (NULL);
while(left < right){//partition loop
do{left++;} while (a[left] < pivot);
do{right--;}while(a[right]>pivot);
if (left < right ) {
temp = a[left];a[left]=a[right];a[right] = temp;
}
}
print();
pivotIndex = left;//put pivot back
temp = a[pivotIndex] ;
a[pivotIndex] = pivot;
a[upperbound] = temp;
//start the "recursive threads"
aleft.upperbound = pivotIndex - 1;
aleft.lowerbound = lowerbound;
aright.upperbound = upperbound;
aright.lowerbound = pivotIndex + 1;
printf("%lu: create left and right threadsln", me) ;
pthread_create(&leftThread,NULL,Qsort,(void * )&aleft);
pthread_create(&rightThread,NULL,Qsort,(void *)&aright);
//wait for left and right threads to finish
pthread_join(leftThread,NULL);
pthread_join(rightThread, NULL);
printf("%lu: joined with left & right threads\n",me);
}
int main(int argc, char *argv[]){
PARM arg;
int i, *array;
pthread_t me,thread;
me = pthread_self( );
printf("main %lu: unsorted array = ", me);
print( ) ;
arg.upperbound = N-1;
arg. lowerbound = 0 ;
printf("main %lu create a thread to do QS\n" , me);
pthread_create(&thread,NULL,Qsort,(void * ) &arg);//wait for Qs thread to finish
pthread_join(thread,NULL);
printf ("main %lu sorted array = ", me);
print () ;
}
Problems and Solutions
When compiling using conventional methods, it is found that the compilation cannot be performed, and it is prompted that pthread related functions are not defined:
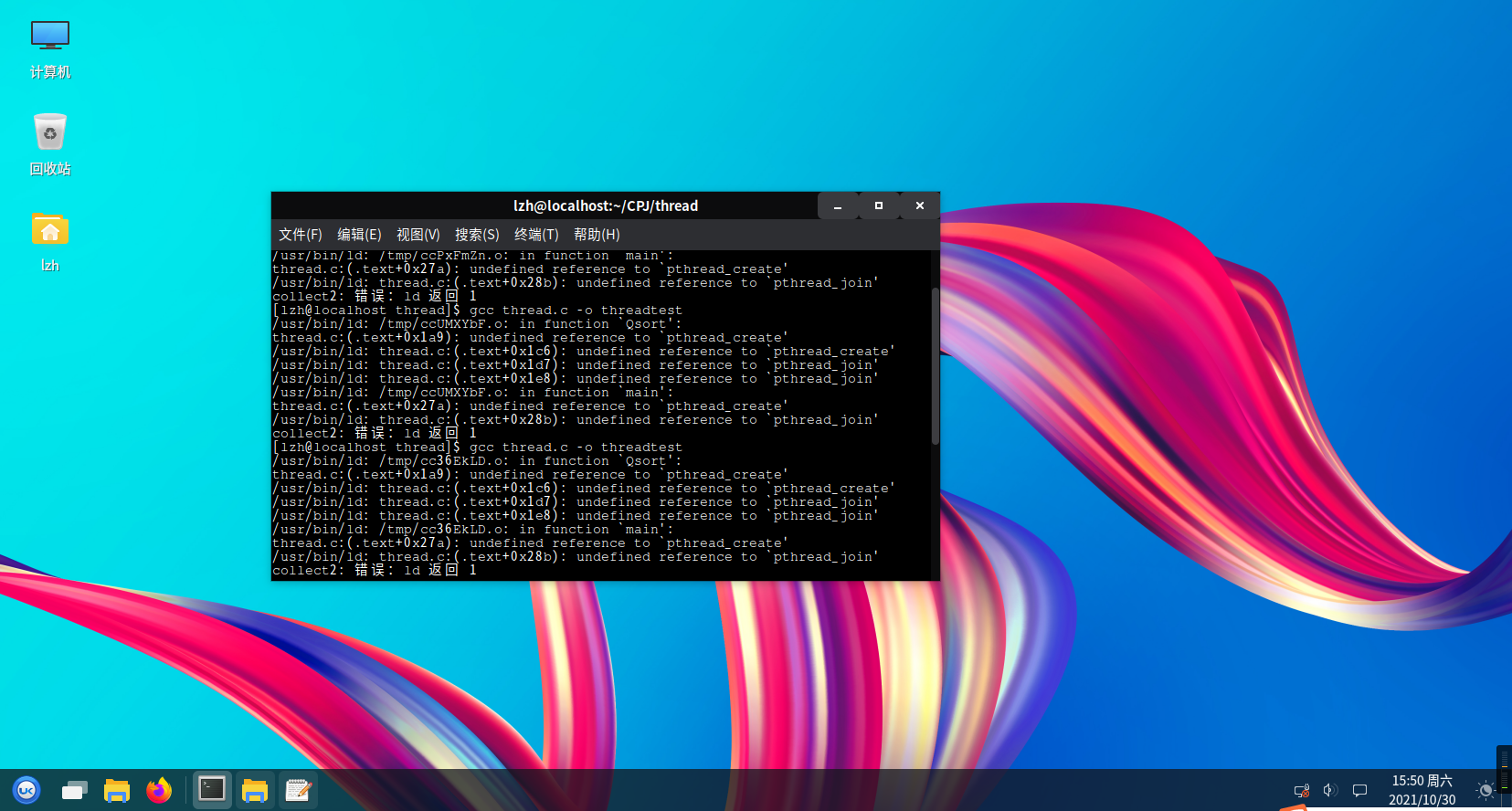
After consulting the data and reading carefully, it is found that the compilation operation can be completed only by adding the - pthread parameter to the gcc command, such as gcc thread.c -pthread.
test result
Test in openEuler:
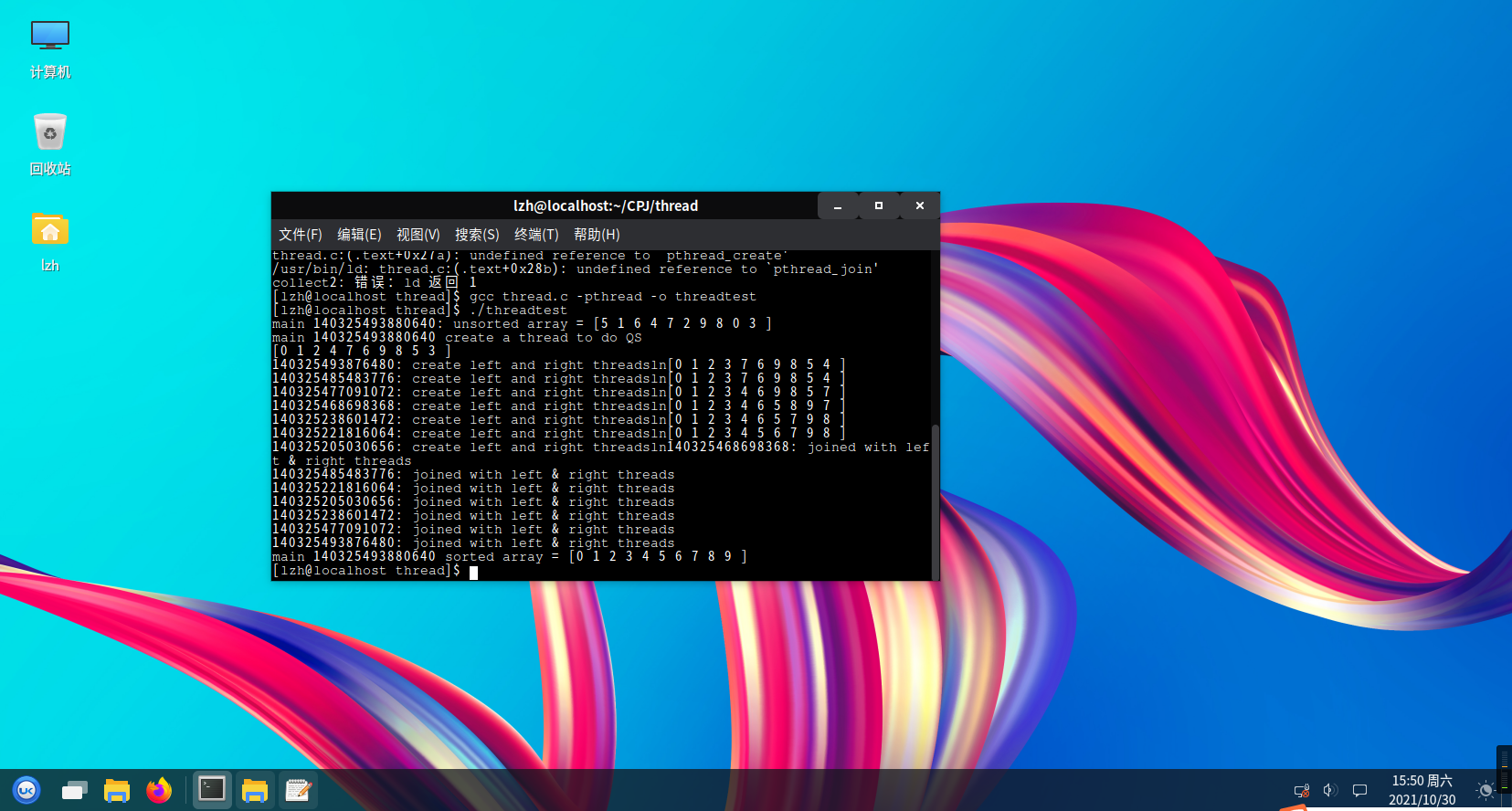
Finally, the program test is successful.
Code link
The code includes some previous codes in the code cloud. Link: https://gitee.com/Ressurection20191320/code/tree/master/IS