2021 iFLYTEK - vehicle loan default prediction challenge Top1 - scheme learning
brief introduction
The purpose of auto loan default prediction is to establish a risk identification model to predict the borrowers who may default. The prediction result is whether the borrower may default, which belongs to the second category.
In the competition of partial data mining, the key point is how to abstract and summarize useful features based on the understanding of data.
***
Directly enter the theme and start learning the routine, Wuhu~
Characteristic Engineering
1. Common library and data import
import pandas as pd import numpy as np import lightgbm as lgb import xgboost as xgb from sklearn.metrics import roc_auc_score, auc, roc_curve, accuracy_score, f1_score from sklearn.model_selection import StratifiedKFold from sklearn.preprocessing import StandardScaler, QuantileTransformer, KBinsDiscretizer, LabelEncoder, MinMaxScaler, PowerTransformer from tqdm import tqdm import pickle import logging logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) import os
Some tools are used in the second half:
- tqdm: an elegant progress bar display, which is convenient to observe the number of runs, progress and speed;
- Pickle: store objects on the disk in the form of files. Almost all data types can be serialized by pickle. Generally, dump first and then load, which is similar to writing out and importing; The function is to reuse one result many times to avoid repeated work. hhh, for example, it takes 2h to process column A data. After each modification, you need to run other columns of data again, but you don't need to modify column A data. You can use pickle to solve this problem and quickly retrieve the previous results;
- logging: the console outputs logs to facilitate viewing the running status;
logging.info('data loading...')
train = pd.read_csv('../xfdata/Vehicle loan default forecast data set/train.csv')
test = pd.read_csv('../xfdata/Vehicle loan default forecast data set/test.csv')2. Characteristic Engineering
2.1 structural characteristics
For training set and test set:
- Calculate new features according to business understanding;
- Some proportional features are cut equally, some numerical features are qcut equally, and some numerical features are user-defined to divide the bin range;
def gen_new_feats(train, test):
'''Generate new features: such as annual interest rate/Sub box and other features'''
# Step 1: merge training set and test set
data = pd.concat([train, test])
# Step 2: specific engineering features
# Calculate the annual interest rate of the secondary account
data['sub_Rate'] = (data['sub_account_monthly_payment'] * data['sub_account_tenure'] - data[
'sub_account_sanction_loan']) / data['sub_account_sanction_loan']
# Calculate the annual interest rate of the master account
data['main_Rate'] = (data['main_account_monthly_payment'] * data['main_account_tenure'] - data[
'main_account_sanction_loan']) / data['main_account_sanction_loan']
# Sub box operation for some features
# Equal width box
loan_to_asset_ratio_labels = [i for i in range(10)]
data['loan_to_asset_ratio_bin'] = pd.cut(data["loan_to_asset_ratio"], 10, labels=loan_to_asset_ratio_labels)
# Equal frequency division box
data['asset_cost_bin'] = pd.qcut(data['asset_cost'], 10, labels=loan_to_asset_ratio_labels)
# Custom sub box
amount_cols = [
'total_monthly_payment',
'main_account_sanction_loan',
'main_account_disbursed_loan',
'sub_account_sanction_loan',
'sub_account_disbursed_loan',
'main_account_monthly_payment',
'sub_account_monthly_payment',
'total_sanction_loan'
]
amount_labels = [i for i in range(10)]
for col in amount_cols:
total_monthly_payment_bin = [-1, 5000, 10000, 30000, 50000, 100000, 300000, 500000, 1000000, 3000000, data[col].max()]
data[col + '_bin'] = pd.cut(data[col], total_monthly_payment_bin, labels=amount_labels).astype(int)
# Step 3: return the training set & test set containing new features
return data[data['loan_default'].notnull()], data[data['loan_default'].isnull()]2.2 Target Encoding
Target encoding is a method of feature coding combined with target value.
In the second classification, for feature i, the coding value of target encoding when the feature value is k is the target value expectation E corresponding to category K (y|xi = xik).

There are 10 records in the sample set, of which the value of characteristic Trend in 3 records is Up. We pay attention to these 3 records. When k=Up, the expectation of the target value is 2 / 3 ≈ 0.66, so Up is encoded as 0.66.
After the boss, target encoding is mainly carried out for the id feature.
def gen_target_encoding_feats(train, test, encode_cols, target_col, n_fold=10):
'''generate target encoding features'''
# for training set - cv
tg_feats = np.zeros((train.shape[0], len(encode_cols)))
kfold = StratifiedKFold(n_splits=n_fold, random_state=1024, shuffle=True)
for _, (train_index, val_index) in enumerate(kfold.split(train[encode_cols], train[target_col])):
df_train, df_val = train.iloc[train_index], train.iloc[val_index]
for idx, col in enumerate(encode_cols):
target_mean_dict = df_train.groupby(col)[target_col].mean()
df_val[f'{col}_mean_target'] = df_val[col].map(target_mean_dict)
tg_feats[val_index, idx] = df_val[f'{col}_mean_target'].values
for idx, encode_col in enumerate(encode_cols):
train[f'{encode_col}_mean_target'] = tg_feats[:, idx]
# for testing set
for col in encode_cols:
target_mean_dict = train.groupby(col)[target_col].mean()
test[f'{col}_mean_target'] = test[col].map(target_mean_dict)
return train, testTo tell you the truth, this code has not been fully understood ~ remember it in a small notebook first, and take it out directly when using it, hhh
2.3 characteristics of nearest neighbor fraud
For risk control accounts, there may be a large number of registrations in the same batch for risky accounts, so the IDs may be connected.
Here, the boss has constructed the nearest neighbor fraud feature, that is, the label of the front and rear 10 accounts of each account is taken as the average, which represents the probability, which means the probability of aggregation of possible default accounts, and represents the correlation of possible default of the account to a certain extent.
def gen_neighbor_feats(train, test):
'''Generate nearest neighbor fraud characteristics'''
if not os.path.exists('../user_data/neighbor_default_probs.pkl'):
# This feature takes a long time to run, so it is saved as a pkl file
neighbor_default_probs = []
for i in tqdm(range(train.customer_id.max())):
if i >= 10 and i < 199706:
customer_id_neighbors = list(range(i - 10, i)) + list(range(i + 1, i + 10))
elif i < 199706:
customer_id_neighbors = list(range(0, i)) + list(range(i + 1, i + 10))
else:
customer_id_neighbors = list(range(i - 10, i)) + list(range(i + 1, 199706))
customer_id_neighbors = [customer_id_neighbor for customer_id_neighbor in customer_id_neighbors if
customer_id_neighbor in train.customer_id.values.tolist()]
neighbor_default_prob = train.set_index('customer_id').loc[customer_id_neighbors].loan_default.mean()
neighbor_default_probs.append(neighbor_default_prob)
df_neighbor_default_prob = pd.DataFrame({'customer_id': range(0, train.customer_id.max()),
'neighbor_default_prob': neighbor_default_probs})
save_pkl(df_neighbor_default_prob, '../user_data/neighbor_default_probs.pkl')
else:
df_neighbor_default_prob = load_pkl('../user_data/neighbor_default_probs.pkl')
train = pd.merge(left=train, right=df_neighbor_default_prob, on='customer_id', how='left')
test = pd.merge(left=test, right=df_neighbor_default_prob, on='customer_id', how='left')
return train, test2.4 output of characteristic engineering results
TARGET_ENCODING_FETAS = [
'employment_type',
'branch_id',
'supplier_id',
'manufacturer_id',
'area_id',
'employee_code_id',
'asset_cost_bin'
]
# Characteristic Engineering
logging.info('feature generating...')
train, test = gen_new_feats(train, test)
train, test = gen_target_encoding_feats(train, test, TARGET_ENCODING_FETAS, target_col='loan_default', n_fold=10)
train, test = gen_neighbor_feats(train, test)The subsequent processing of features, such as the data type conversion of some converted features and the simplification of some rate value features, facilitates the subsequent model learning and enhances the robustness of the model.
# Saved final feature name list
SAVE_FEATS = [
'customer_id',
'neighbor_default_prob',
'disbursed_amount',
'asset_cost',
'branch_id',
'supplier_id',
'manufacturer_id',
'area_id',
'employee_code_id',
'credit_score',
'loan_to_asset_ratio',
'year_of_birth',
'age',
'sub_Rate',
'main_Rate',
'loan_to_asset_ratio_bin',
'asset_cost_bin',
'employment_type_mean_target',
'branch_id_mean_target',
'supplier_id_mean_target',
'manufacturer_id_mean_target',
'area_id_mean_target',
'employee_code_id_mean_target',
'asset_cost_bin_mean_target',
'credit_history',
'average_age',
'total_disbursed_loan',
'main_account_disbursed_loan',
'total_sanction_loan',
'main_account_sanction_loan',
'active_to_inactive_act_ratio',
'total_outstanding_loan',
'main_account_outstanding_loan',
'Credit_level',
'outstanding_disburse_ratio',
'total_account_loan_no',
'main_account_tenure',
'main_account_loan_no',
'main_account_monthly_payment',
'total_monthly_payment',
'main_account_active_loan_no',
'main_account_inactive_loan_no',
'sub_account_inactive_loan_no',
'enquirie_no',
'main_account_overdue_no',
'total_overdue_no',
'last_six_month_defaulted_no'
]
# Characteristic engineering post-processing
# Simplified features
for col in ['sub_Rate', 'main_Rate', 'outstanding_disburse_ratio']:
train[col] = train[col].apply(lambda x: 1 if x > 1 else x)
test[col] = test[col].apply(lambda x: 1 if x > 1 else x)
# Data type conversion
train['asset_cost_bin'] = train['asset_cost_bin'].astype(int)
test['asset_cost_bin'] = test['asset_cost_bin'].astype(int)
train['loan_to_asset_ratio_bin'] = train['loan_to_asset_ratio_bin'].astype(int)
test['loan_to_asset_ratio_bin'] = test['loan_to_asset_ratio_bin'].astype(int)
# Stores a dataset containing new features
logging.info('new data saving...')
cols = SAVE_FEATS + ['loan_default', ]
train[cols].to_csv('./train_final.csv', index=False)
test[cols].to_csv('./test_final.csv', index=False)model building
1. Model training - cross validation
Two gradient lifting tree models, lightgbm and xgboost, are adopted. There is not much explanation here. The following code has become the "standard", DDDD~
def train_lgb_kfold(X_train, y_train, X_test, n_fold=5):
'''train lightgbm with k-fold split'''
gbms = []
kfold = StratifiedKFold(n_splits=n_fold, random_state=1024, shuffle=True)
oof_preds = np.zeros((X_train.shape[0],))
test_preds = np.zeros((X_test.shape[0],))
for fold, (train_index, val_index) in enumerate(kfold.split(X_train, y_train)):
logging.info(f'############ fold {fold} ###########')
X_tr, X_val, y_tr, y_val = X_train.iloc[train_index], X_train.iloc[val_index], y_train[train_index], y_train[val_index]
dtrain = lgb.Dataset(X_tr, y_tr)
dvalid = lgb.Dataset(X_val, y_val, reference=dtrain)
params = {
'objective': 'binary',
'metric': 'auc',
'num_leaves': 64,
'learning_rate': 0.02,
'min_data_in_leaf': 150,
'feature_fraction': 0.8,
'bagging_fraction': 0.7,
'n_jobs': -1,
'seed': 1024
}
gbm = lgb.train(params,
dtrain,
num_boost_round=1000,
valid_sets=[dtrain, dvalid],
verbose_eval=50,
early_stopping_rounds=20)
oof_preds[val_index] = gbm.predict(X_val, num_iteration=gbm.best_iteration)
test_preds += gbm.predict(X_test, num_iteration=gbm.best_iteration) / kfold.n_splits
gbms.append(gbm)
return gbms, oof_preds, test_preds
def train_xgb_kfold(X_train, y_train, X_test, n_fold=5):
'''train xgboost with k-fold split'''
gbms = []
kfold = StratifiedKFold(n_splits=10, random_state=1024, shuffle=True)
oof_preds = np.zeros((X_train.shape[0],))
test_preds = np.zeros((X_test.shape[0],))
for fold, (train_index, val_index) in enumerate(kfold.split(X_train, y_train)):
logging.info(f'############ fold {fold} ###########')
X_tr, X_val, y_tr, y_val = X_train.iloc[train_index], X_train.iloc[val_index], y_train[train_index], y_train[val_index]
dtrain = xgb.DMatrix(X_tr, y_tr)
dvalid = xgb.DMatrix(X_val, y_val)
dtest = xgb.DMatrix(X_test)
params={
'booster':'gbtree',
'objective': 'binary:logistic',
'eval_metric': ['logloss', 'auc'],
'max_depth': 8,
'subsample':0.9,
'min_child_weight': 10,
'colsample_bytree':0.85,
'lambda': 10,
'eta': 0.02,
'seed': 1024
}
watchlist = [(dtrain, 'train'), (dvalid, 'test')]
gbm = xgb.train(params,
dtrain,
num_boost_round=1000,
evals=watchlist,
verbose_eval=50,
early_stopping_rounds=20)
oof_preds[val_index] = gbm.predict(dvalid, iteration_range=(0, gbm.best_iteration))
test_preds += gbm.predict(dtest, iteration_range=(0, gbm.best_iteration)) / kfold.n_splits
gbms.append(gbm)
return gbms, oof_preds, test_predsdef train_xgb(train, test, feat_cols, label_col, n_fold=10):
'''train xgboost'''
for col in ['sub_Rate', 'main_Rate', 'outstanding_disburse_ratio']:
train[col] = train[col].apply(lambda x: 1 if x > 1 else x)
test[col] = test[col].apply(lambda x: 1 if x > 1 else x)
X_train = train[feat_cols]
y_train = train[label_col]
X_test = test[feat_cols]
gbms_xgb, oof_preds_xgb, test_preds_xgb = train_xgb_kfold(X_train, y_train, X_test, n_fold=n_fold)
if not os.path.exists('../user_data/gbms_xgb.pkl'):
save_pkl(gbms_xgb, '../user_data/gbms_xgb.pkl')
return gbms_xgb, oof_preds_xgb, test_preds_xgb
def train_lgb(train, test, feat_cols, label_col, n_fold=10):
'''train lightgbm'''
X_train = train[feat_cols]
y_train = train[label_col]
X_test = test[feat_cols]
gbms_lgb, oof_preds_lgb, test_preds_lgb = train_lgb_kfold(X_train, y_train, X_test, n_fold=n_fold)
if not os.path.exists('../user_data/gbms_lgb.pkl'):
save_pkl(gbms_lgb, '../user_data/gbms_lgb.pkl')
return gbms_lgb, oof_preds_lgb, test_preds_lgbOutput model training results:
# Read original dataset
logging.info('data loading...')
train = pd.read_csv('../xfdata/Vehicle loan default forecast data set/train.csv')
test = pd.read_csv('../xfdata/Vehicle loan default forecast data set/test.csv')
# Characteristic Engineering
logging.info('feature generating...')
train, test = gen_new_feats(train, test)
train, test = gen_target_encoding_feats(train, test, TARGET_ENCODING_FETAS, target_col='loan_default', n_fold=10)
train, test = gen_neighbor_feats(train, test)
train['asset_cost_bin'] = train['asset_cost_bin'].astype(int)
test['asset_cost_bin'] = test['asset_cost_bin'].astype(int)
train['loan_to_asset_ratio_bin'] = train['loan_to_asset_ratio_bin'].astype(int)
test['loan_to_asset_ratio_bin'] = test['loan_to_asset_ratio_bin'].astype(int)
train['asset_cost_bin_mean_target'] = train['asset_cost_bin_mean_target'].astype(float)
test['asset_cost_bin_mean_target'] = test['asset_cost_bin_mean_target'].astype(float)
# Model training: the xgboost results of linux and mac are slightly different, and the model file results are the main results
gbms_xgb, oof_preds_xgb, test_preds_xgb = train_xgb(train.copy(), test.copy(),
feat_cols=SAVE_FEATS,
label_col='loan_default')
gbms_lgb, oof_preds_lgb, test_preds_lgb = train_lgb(train, test,
feat_cols=SAVE_FEATS,
label_col='loan_default')2. Partition threshold
Because it is a 0-1 binary classification, the mean value of the final classification can be approximately understood as taking the loan_ The probability of default = 1.
Then, by sorting the prediction results of cv, the probability corresponding to the quantile (1-P(loan_default=1)) is taken as the critical point for the division of positive and negative samples.
In order to make the results more accurate, a small step is taken to traverse the points near the critical point to find the local optimal probability threshold.
def gen_thres_new(df_train, oof_preds):
df_train['oof_preds'] = oof_preds
# It can be regarded as a training set and taken to loan_ Probability of default = 1
quantile_point = df_train['loan_default'].mean()
thres = df_train['oof_preds'].quantile(1 - quantile_point)
# For example, 0,1,1,1 mean = 0.75, 1-mean = 0.25, that is, the 25% quantile value is 0
_thresh = []
# According to the upper and lower 0.2 range and 0.01 step of the theoretical threshold, the best threshold is found. The threshold corresponding to the highest f1 score is the best threshold
for thres_item in np.arange(thres - 0.2, thres + 0.2, 0.01):
_thresh.append(
[thres_item, f1_score(df_train['loan_default'], np.where(oof_preds > thres_item, 1, 0), average='macro')])
_thresh = np.array(_thresh)
best_id = _thresh[:, 1].argmax() # Find the row corresponding to f1
best_thresh = _thresh[best_id][0] # Take out the optimal threshold
print("threshold: {}\n Training set f1: {}".format(best_thresh, _thresh[best_id][1]))
return best_thresh3. Model fusion
The quantiles of cv results of xgb and lgb models are weighted and summed, and then the probability threshold of 0-1 of the fused model is found.
xgb_thres = gen_thres_new(train, oof_preds_xgb)
lgb_thres = gen_thres_new(train, oof_preds_lgb)
# Result aggregation
df_oof_res = pd.DataFrame({'customer_id': train['customer_id'],
'loan_default':train['loan_default'],
'oof_preds_xgb': oof_preds_xgb,
'oof_preds_lgb': oof_preds_lgb})
# Model fusion
df_oof_res['xgb_rank'] = df_oof_res['oof_preds_xgb'].rank(pct=True) # percentile rank, which returns the quantile after sorting
df_oof_res['lgb_rank'] = df_oof_res['oof_preds_lgb'].rank(pct=True)
df_oof_res['preds'] = 0.31 * df_oof_res['xgb_rank'] + 0.69 * df_oof_res['lgb_rank']
# Fused model, probability threshold
thres = gen_thres_new(df_oof_res, df_oof_res['preds'])forecast
According to the probability threshold of the training set after melting, the prediction results of the test set are divided into 0-1, and the final prediction submission results are output.
def gen_submit_file(df_test, test_preds, thres, save_path):
# It is divided according to the threshold after the final model fusion
df_test['test_preds_binary'] = np.where(test_preds > thres, 1, 0)
df_test_submit = df_test[['customer_id', 'test_preds_binary']]
df_test_submit.columns = ['customer_id', 'loan_default']
print(f'saving result to: {save_path}')
df_test_submit.to_csv(save_path, index=False)
print('done!')
return df_test_submit
df_test_res = pd.DataFrame({'customer_id': test['customer_id'],
'test_preds_xgb': test_preds_xgb,
'test_preds_lgb': test_preds_lgb})
df_test_res['xgb_rank'] = df_test_res['test_preds_xgb'].rank(pct=True)
df_test_res['lgb_rank'] = df_test_res['test_preds_lgb'].rank(pct=True)
df_test_res['preds'] = 0.31 * df_test_res['xgb_rank'] + 0.69 * df_test_res['lgb_rank']
# Result output
df_submit = gen_submit_file(df_test_res, df_test_res['preds'], thres,
save_path='../prediction_result/result.csv')summary
The big guy's code style is clear and concise. He looks at the code very smoothly and has a very clear idea. He can learn these engineering codes well. It has strong expansibility and is convenient for debug ging.
From the perspective of competition questions, after thinking about the business, we made a "nearest neighbor fraud feature" from the id concentration; In the mold melting operation, it is weighted according to the quantile of the ranking value of the predicted value. These tips can be directly reused ~ (also the upper point mentioned by the boss)
It is estimated that many students, like me, will have some doubts about the following two questions. I will take a direct screenshot from b:
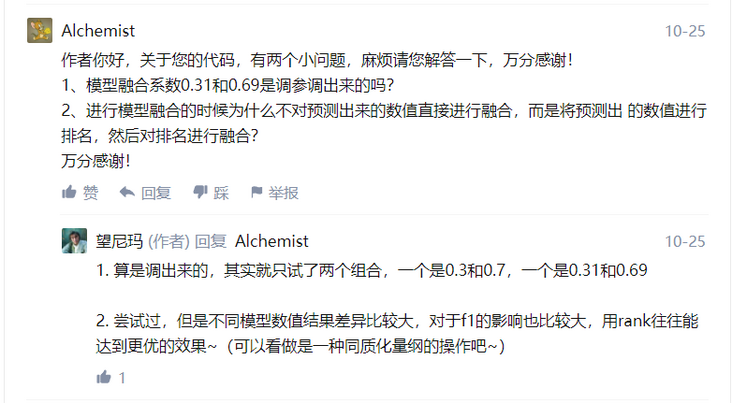
Source code: https://github.com/WangliLin/...
In addition, I also arranged a ipynb to facilitate learning, and the official account of the students needed to reply to "1208".
reference resources:
- logging module
- pickle module
- tqdm module
- Target Encoding formula
- Target Encoding
- https://zhuanlan.zhihu.com/p/...
Welcome to the official account of individuals: Distinct number