Writing high-quality concurrent code is a very difficult task. Since the first version, the Java language has built-in support for multithreading, which was great in those years. However, when we have a deeper understanding and more practice of concurrent programming, we have more schemes and better choices to realize concurrent programming. This article is a summary and Reflection on concurrent programming, and also shares a little experience on how to write concurrent code in Java versions after 5.
Why concurrency
Concurrency is actually a decoupling strategy, It helps us separate what to do (target) from when to do (timing), which can significantly improve the throughput (get more CPU scheduling time) and structure of the application (several parts of the program work together). As anyone who has done java web development knows, the Servlet program in Java Web adopts the single instance multithreading working mode with the support of Servlet container, and the Servlet container handles the concurrency problem for you.
Misunderstanding and positive solution
The most common misconceptions about concurrent programming are the following:
-Concurrency always improves performance (concurrency can significantly improve program performance when the CPU has a lot of idle time, but when there are a large number of threads, frequent scheduling switching between threads will degrade the performance of the system)
-Writing concurrent programs does not need to modify the original design (the decoupling of purpose and timing often has a great impact on the system structure)
-Don't pay attention to concurrency when using the Web or EJB container (you can use the container better only if you understand what the container is doing)
The following statements are the objective understanding of Concurrency:
-Writing concurrent programs adds extra overhead to the code
-Correct concurrency is very complex, even for very simple problems
-Defects in concurrency are not easy to reproduce or be found
-Concurrency often requires fundamental changes to the design strategy
Principles and skills of concurrent programming
Single responsibility principle
Separate concurrency related code from other code (concurrency related code has its own development, modification, and tuning life cycle).
Limit data scope
When two threads modify the same field of a shared object, they may interfere with each other, resulting in unexpected behavior. One of the solutions is to construct critical areas, but the number of critical areas must be limited.
Use data copy
Data copy is a good way to avoid sharing data. The copied objects are only treated as read-only. Java 5 util. A class named CopyOnWriteArrayList is added in the concurrent package. It is a subtype of the List interface, so you can think it is a thread safe version of ArrayList. It uses the method of copy on write to create data copies for operations to avoid problems caused by concurrent access to shared data.
Threads should be as independent as possible
Let threads exist in their own world and do not share data with other threads. Anyone with Java Web development experience knows that servlets work in a single instance multithreaded manner, The data related to each request is through the service method of the Servlet subclass (or doGet or doPost method). As long as the code in the Servlet only uses local variables, the Servlet will not cause synchronization problems. The controller of Spring MVC does the same. The objects obtained from the request are passed in as method parameters rather than as class members. Obviously, Struts 2 does the opposite, so Struts 2 is used as the controller The Action class of is an instance corresponding to each request.
Concurrent programming before Java 5
Java's thread model is based on preemptive thread scheduling, that is:
- All threads can easily share objects in the same process.
- Any thread that can reference these objects can modify them.
- To protect data, objects can be locked.
Java's concurrency based on threads and locks is too low-level, and the use of locks is often very evil, because it is equivalent to making all concurrency turn into queuing.
before Java 5, the synchronized keyword can be used to realize the function of lock. It can be used on code blocks and methods, indicating that the thread must obtain the appropriate lock before executing the whole code block or method. For non static methods (member methods) of a Class, this means that the lock of the object instance should be obtained. For static methods (Class methods) of a Class, the lock of the Class object of the Class should be obtained. For synchronous code blocks, the programmer can specify that the lock of the object should be obtained.
whether it's a synchronous code block or a synchronous method, only one thread can enter at a time, If other threads try to enter (whether the same synchronization block or different synchronization blocks), the JVM will suspend them (put them into the equal lock pool). This structure is called critical section in concurrency theory. Here we can summarize the functions of synchronizing and locking with synchronized in Java:
- Only objects can be locked, not basic data types
- A single object in the locked object array is not locked
- A synchronized method can be thought of as a synchronized(this) {...} code block that contains the entire method
- The static synchronization method locks its Class object
- The synchronization of the inner class is independent of the outer class
- The synchronized modifier is not part of the method signature, so it cannot appear in the method declaration of an interface
- Asynchronous methods don't care about the state of the lock. They can still run when the synchronous method runs
- The locks implemented by synchronized are reentrant locks.
Within the JVM, in order to improve efficiency, each thread running at the same time will have a cache copy of the data it is processing. When we use synchronized for synchronization, What is really synchronized is the memory block representing the locked object in different threads (the replica data will remain synchronized with the main memory. Now you know why to use the word synchronization). In short, after the synchronization block or synchronization method is executed, any changes made to the locked object should be written back to the main memory before releasing the lock; after entering the synchronization block to get the lock, the data of the locked object is read out of the main memory and held The data copy of the locked thread must be synchronized with the data view in main memory.
in the initial version of Java, there was a keyword called volatile, which is a simple synchronous processing mechanism, because variables modified by volatile follow the following rules:
- The value of a variable is always read out from main memory before it is used.
- Changes to variable values are always written back to main memory after completion.
Using volatile keyword can prevent the compiler from incorrect optimization assumptions in a multithreaded environment (the compiler may optimize variables that will not change in a thread into constants), but only variables that do not depend on the current state (value at the time of reading) during modification should be declared as volatile variables.
invariant pattern is also a design that can be considered in concurrent programming. Make the state of the object unchanged. If you want to modify the state of the object, you will create a copy of the object and write the change to the copy without changing the original object. In this way, there will be no inconsistent state. Therefore, the invariant object is thread safe. The String class that we use very frequently in Java adopts this design. If you are not familiar with invariant patterns, you can read chapter 34 of Dr. Yan Hong's Book Java and patterns. At this point, you may also realize the significance of the final keyword.
Concurrent programming in Java 5
No matter what direction Java will develop or get busy in the future, Java 5 is definitely an extremely important version in the history of Java, We will not discuss the various language features provided by this version here (if you are interested, you can read my other article "the 20th year of Java: viewing the development of programming technology from the evolution of java version" )However, we must thank Doug lea for providing his landmark masterpiece Java. Net in Java 5 util. Concurrent package, which gives Java Concurrent Programming more choices and better working methods. Doug Lea's masterpiece mainly includes the following contents:
- Better thread safe container
- Thread pool and related tool classes
- Optional non blocking solution
- Lock and semaphore mechanism for display
Let's interpret these things one by one.
Atomic class
Java. In Java 5 util. Under the concurrent package, there is an atomic sub package with several classes starting with atomic, such as AtomicInteger and AtomicLong. They take advantage of the characteristics of modern processors and can complete atomic operations in a non blocking way. The code is as follows:
/**
ID sequence generator
*/
public class IdGenerator {
private final AtomicLong sequenceNumber = new AtomicLong(0);
public long next() {
return sequenceNumber.getAndIncrement();
}
}
Display lock
The locking mechanism based on the synchronized keyword has the following problems:
- There is only one type of lock, and it works the same for all synchronous operations
- The lock can only be obtained at the beginning of the code block or method and released at the end
- Threads are either locked or blocked. There is no other possibility
Java 5 reconstructs the lock mechanism and provides displayed locks, which can improve the lock mechanism in the following aspects:
- You can add different types of locks, such as read locks and write locks
- You can lock in one method and unlock in another
- You can use tryLock to try to obtain the lock. If you can't get the lock, you can wait, go back or do something else. Of course, you can also give up the operation after timeout
The displayed locks are implemented in Java util. concurrent. The lock interface mainly has two implementation classes:
- ReentrantLock - a slightly more flexible reentrant lock than synchronized
- ReentrantReadWriteLock - a reentrant lock with better performance when there are many read operations and few write operations
CountDownLatch
CountDownLatch is a simple synchronization mode, which allows a thread to wait for one or more threads to complete their work, so as to avoid various problems caused by concurrent access to critical resources. Here's a piece of code from someone else (I've refactored it) to demonstrate how CountDownLatch works.
import java.util.concurrent.CountDownLatch;
/**
* Worker
*
*/
class Worker {
private String name; // name
private long workDuration; // Work duration
/**
* constructor
*/
public Worker(String name, long workDuration) {
this.name = name;
this.workDuration = workDuration;
}
/**
* finish the work
*/
public void doWork() {
System.out.println(name + " begins to work...");
try {
Thread.sleep(workDuration); // Time to simulate job execution with sleep
} catch(InterruptedException ex) {
ex.printStackTrace();
}
System.out.println(name + " has finished the job...");
}
}
/**
* Test thread
*
*/
class WorkerTestThread implements Runnable {
private Worker worker;
private CountDownLatch cdLatch;
public WorkerTestThread(Worker worker, CountDownLatch cdLatch) {
this.worker = worker;
this.cdLatch = cdLatch;
}
@Override
public void run() {
worker.doWork(); // Get the workers to work
cdLatch.countDown(); // The number of countdowns after the work is completed is reduced by 1
}
}
class CountDownLatchTest {
private static final int MAX_WORK_DURATION = 5000; // Maximum working time
private static final int MIN_WORK_DURATION = 1000; // Minimum working time
// Generate random working hours
private static long getRandomWorkDuration(long min, long max) {
return (long) (Math.random() * (max - min) + min);
}
public static void main(String[] args) {
CountDownLatch latch = new CountDownLatch(2); // Create a countdown latch and specify a countdown count of 2
Worker w1 = new Worker("Xiao Hong", getRandomWorkDuration(MIN_WORK_DURATION, MAX_WORK_DURATION));
Worker w2 = new Worker("petty thief", getRandomWorkDuration(MIN_WORK_DURATION, MAX_WORK_DURATION));
new Thread(new WorkerTestThread(w1, latch)).start();
new Thread(new WorkerTestThread(w2, latch)).start();
try {
latch.await(); // Wait for the countdown latch to decrease to 0
System.out.println("All jobs have been finished!");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
ConcurrentHashMap
Concurrent HashMap is the version of HashMap in a concurrent environment. You may want to ask, since it can be accessed through Collections Synchronized map obtains a thread safe mapping container. Why do you need concurrent HashMap? Because the thread safe HashMap obtained through the Collections tool class locks the entire container object when reading and writing data, other threads using the container can no longer obtain the lock of the object, which means that they have to wait until the previous thread that obtained the lock leaves the synchronized code block before they have the opportunity to execute. In fact, HashMap determines the bucket for storing key value pairs through hash function (bucket is introduced to solve hash conflict). When modifying HashMap, you don't need to lock the whole container, just lock the "bucket" to be modified. The data structure of HashMap is shown in the following figure.
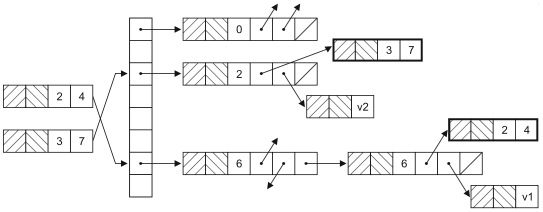
In addition, ConcurrentHashMap also provides atomic operation methods, as shown below:
- putIfAbsent: if there is no corresponding key value pair mapping, add it to the HashMap.
- remove: if the key exists and the value is equal to the current state (the equals comparison result is true), the key value pair mapping is removed atomically
- Replace: replace the atomic operation of the element in the map
CopyOnWriteArrayList
CopyOnWriteArrayList is an alternative to ArrayList in a concurrent environment. CopyOnWriteArrayList avoids the problems caused by concurrent access by adding copy on write semantics, that is, any modification operation will create a copy of the list at the bottom, which means that the existing iterators will not encounter unexpected modifications. This method is very useful for scenarios where there is no strict read-write synchronization, because it provides better performance. Remember to minimize the use of locks, Because that will inevitably lead to performance degradation (isn't it the same for concurrent access to data in the database? If you can, you should give up the pessimistic lock and use the optimistic lock). CopyOnWriteArrayList obviously gains time by sacrificing space (in the computer world, time and space are usually irreconcilable contradictions. We can sacrifice space to improve efficiency and obtain time. Of course, we can also sacrifice time to reduce the use of space).
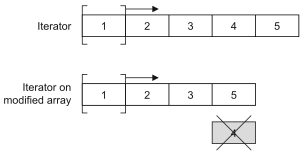
You can verify whether CopyOnWriteArrayList is a thread safe container through the operation of the following two sections of code.
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
class AddThread implements Runnable {
private List<Double> list;
public AddThread(List<Double> list) {
this.list = list;
}
@Override
public void run() {
for(int i = 0; i < 10000; ++i) {
list.add(Math.random());
}
}
}
public class Test05 {
private static final int THREAD_POOL_SIZE = 2;
public static void main(String[] args) {
List<Double> list = new ArrayList<>();
ExecutorService es = Executors.newFixedThreadPool(THREAD_POOL_SIZE);
es.execute(new AddThread(list));
es.execute(new AddThread(list));
es.shutdown();
}
}
The above code will generate ArrayIndexOutOfBoundsException at runtime. Try to replace the ArrayList in line 25 of the above code with CopyOnWriteArrayList and run again.
List<Double> list = new CopyOnWriteArrayList<>();
Queue
Queue is a wonderful concept everywhere. It provides a simple and reliable way to distribute resources to processing units (or allocate units of work to resources to be processed, depending on how you look at the problem). Many concurrent programming models in implementation rely on queue, because it can transfer units of work between threads.
BlockingQueue in Java 5 is a very useful tool in a concurrent environment. When calling the put method to insert elements into the queue, if the queue is full, it will make the thread inserting elements wait for the queue to make room; When the take method is called to fetch elements from the queue, if the queue is empty, the thread that fetches the elements will be blocked.
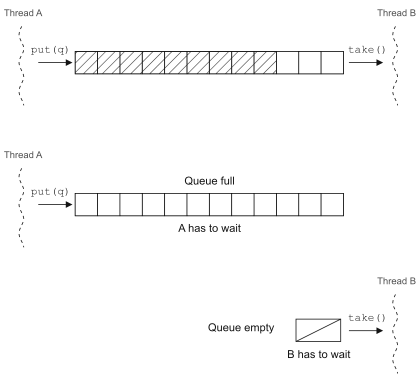
BlockingQueue can be used to implement the producer consumer concurrency model (described in the next section). Of course, before Java 5, thread scheduling can also be realized through wait and notify. Compare the two codes to see what's good about reconstructing concurrent code based on existing concurrency tool classes.
- Implementation based on wait and notify
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* Common constant
*
*/
class Constants {
public static final int MAX_BUFFER_SIZE = 10;
public static final int NUM_OF_PRODUCER = 2;
public static final int NUM_OF_CONSUMER = 3;
}
/**
* Work tasks
*
*/
class Task {
private String id; // Task number
public Task() {
id = UUID.randomUUID().toString();
}
@Override
public String toString() {
return "Task[" + id + "]";
}
}
/**
* consumer
*
*/
class Consumer implements Runnable {
private List<Task> buffer;
public Consumer(List<Task> buffer) {
this.buffer = buffer;
}
@Override
public void run() {
while(true) {
synchronized(buffer) {
while(buffer.isEmpty()) {
try {
buffer.wait();
} catch(InterruptedException e) {
e.printStackTrace();
}
}
Task task = buffer.remove(0);
buffer.notifyAll();
System.out.println("Consumer[" + Thread.currentThread().getName() + "] got " + task);
}
}
}
}
/**
* producer
*
*/
class Producer implements Runnable {
private List<Task> buffer;
public Producer(List<Task> buffer) {
this.buffer = buffer;
}
@Override
public void run() {
while(true) {
synchronized (buffer) {
while(buffer.size() >= Constants.MAX_BUFFER_SIZE) {
try {
buffer.wait();
} catch(InterruptedException e) {
e.printStackTrace();
}
}
Task task = new Task();
buffer.add(task);
buffer.notifyAll();
System.out.println("Producer[" + Thread.currentThread().getName() + "] put " + task);
}
}
}
}
public class Test06 {
public static void main(String[] args) {
List<Task> buffer = new ArrayList<>(Constants.MAX_BUFFER_SIZE);
ExecutorService es = Executors.newFixedThreadPool(Constants.NUM_OF_CONSUMER + Constants.NUM_OF_PRODUCER);
for(int i = 1; i <= Constants.NUM_OF_PRODUCER; ++i) {
es.execute(new Producer(buffer));
}
for(int i = 1; i <= Constants.NUM_OF_CONSUMER; ++i) {
es.execute(new Consumer(buffer));
}
}
}
- Implementation based on BlockingQueue
import java.util.UUID;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
/**
* Common constant
*
*/
class Constants {
public static final int MAX_BUFFER_SIZE = 10;
public static final int NUM_OF_PRODUCER = 2;
public static final int NUM_OF_CONSUMER = 3;
}
/**
* Work tasks
*
*/
class Task {
private String id; // Task number
public Task() {
id = UUID.randomUUID().toString();
}
@Override
public String toString() {
return "Task[" + id + "]";
}
}
/**
* consumer
*
*/
class Consumer implements Runnable {
private BlockingQueue<Task> buffer;
public Consumer(BlockingQueue<Task> buffer) {
this.buffer = buffer;
}
@Override
public void run() {
while(true) {
try {
Task task = buffer.take();
System.out.println("Consumer[" + Thread.currentThread().getName() + "] got " + task);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
/**
* producer
*
*/
class Producer implements Runnable {
private BlockingQueue<Task> buffer;
public Producer(BlockingQueue<Task> buffer) {
this.buffer = buffer;
}
@Override
public void run() {
while(true) {
try {
Task task = new Task();
buffer.put(task);
System.out.println("Producer[" + Thread.currentThread().getName() + "] put " + task);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Test07 {
public static void main(String[] args) {
BlockingQueue<Task> buffer = new LinkedBlockingQueue<>(Constants.MAX_BUFFER_SIZE);
ExecutorService es = Executors.newFixedThreadPool(Constants.NUM_OF_CONSUMER + Constants.NUM_OF_PRODUCER);
for(int i = 1; i <= Constants.NUM_OF_PRODUCER; ++i) {
es.execute(new Producer(buffer));
}
for(int i = 1; i <= Constants.NUM_OF_CONSUMER; ++i) {
es.execute(new Consumer(buffer));
}
}
}
After using BlockingQueue, the code is much more elegant.
Concurrency model
Before continuing the following discussion, let's review some concepts:
| concept | explain |
|---|---|
| Critical resources | There are a fixed number of resources in a concurrent environment |
| mutex | Access to resources is exclusive |
| hunger | One or a group of threads cannot make progress for a long time or forever |
| deadlock | Two or more threads wait for each other to finish |
| Livelock | The thread that wants to execute always finds that other threads are executing so that it can't execute for a long time or forever |
After reviewing these concepts, we can explore the following concurrency models.
Producer consumer
One or more producers create some work and place it in a buffer or queue, and one or more consumers get the work from the queue and complete it. The buffer or queue here is a critical resource. When the buffer or queue is full, production will be blocked; When the buffer or queue is empty, consumers will be blocked. The scheduling of producers and consumers is completed by exchanging signals with each other.
Reader writer
When there is a shared resource that mainly provides information for readers, it will be updated by the writer occasionally, but the throughput of the system needs to be considered, and the problems of hunger and old resources can not be updated should be prevented. In this concurrency model, how to balance readers and writers is the most difficult. Of course, this problem is still a hot topic so far. I'm afraid we must provide appropriate solutions according to specific scenarios without a universal method (unlike what we see in China's scientific research literature).
The Dinning Philosophers
In 1965, Edsger Wybe Dijkstra, winner of the Turing prize for computer scientists in the Netherlands, proposed and solved a synchronization problem he called the dining of philosophers. This problem can be simply described as follows: five philosophers sit around a round table, and each philosopher has a plate of macaroni in front of him. Because the macaroni is slippery, it takes two forks to hold it. There is a fork between two adjacent plates, as shown in the figure below. There are two alternating periods of activity in the life of philosophers: eating and thinking. When a philosopher feels hungry, he tries to take the fork on his left and right twice, one at a time, but in no order. If you succeed in getting two forks, start eating. After eating, put down the fork and continue thinking.
replace the philosophers in the above problems with threads and the forks with competing critical resources. The above problem is the problem of threads competing for resources. Without careful design, the system will have problems such as deadlock, livelock, throughput decline and so on.
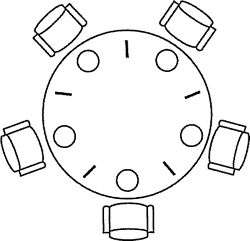
the following is the code to solve the dining problem of philosophers with Semaphore primitives, using the Semaphore class in the Java 5 concurrency Toolkit (the code is not beautiful enough, but it is enough to illustrate the problem).
//import java.util.concurrent.ExecutorService;
//import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
/**
* Up and down questions for storing thread shared semaphores
*
*/
class AppContext {
public static final int NUM_OF_FORKS = 5; // Number of forks (resources)
public static final int NUM_OF_PHILO = 5; // Number of threads
public static Semaphore[] forks; // Semaphore of fork
public static Semaphore counter; // Philosopher's semaphore
static {
forks = new Semaphore[NUM_OF_FORKS];
for (int i = 0, len = forks.length; i < len; ++i) {
forks[i] = new Semaphore(1); // The semaphore of each fork is 1
}
counter = new Semaphore(NUM_OF_PHILO - 1); // If there are N philosophers, only N-1 people are allowed to take the fork at the same time
}
/**
* Get a fork
* @param index The first few philosophers
* @param leftFirst Do you want to get the fork on the left first
* @throws InterruptedException
*/
public static void putOnFork(int index, boolean leftFirst) throws InterruptedException {
if(leftFirst) {
forks[index].acquire();
forks[(index + 1) % NUM_OF_PHILO].acquire();
}
else {
forks[(index + 1) % NUM_OF_PHILO].acquire();
forks[index].acquire();
}
}
/**
* Put the fork back
* @param index The first few philosophers
* @param leftFirst Would you like to put back the fork on the left first
* @throws InterruptedException
*/
public static void putDownFork(int index, boolean leftFirst) throws InterruptedException {
if(leftFirst) {
forks[index].release();
forks[(index + 1) % NUM_OF_PHILO].release();
}
else {
forks[(index + 1) % NUM_OF_PHILO].release();
forks[index].release();
}
}
}
/**
* philosopher
*
*/
class Philosopher implements Runnable {
private int index; // number
private String name; // name
public Philosopher(int index, String name) {
this.index = index;
this.name = name;
}
@Override
public void run() {
while(true) {
try {
AppContext.counter.acquire();
boolean leftFirst = index % 2 == 0;
AppContext.putOnFork(index, leftFirst);
System.out.println(name + "Eating Spaghetti (macaroni)..."); // Take two forks and you can eat
AppContext.putDownFork(index, leftFirst);
AppContext.counter.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Test04 {
public static void main(String[] args) {
String[] names = { "Xiao Hong", "Xiao Ming", "bachelor", "petty thief", "Xiao Wang" }; // Names of five philosophers
// ExecutorService es = Executors.newFixedThreadPool(AppContext.NUM_OF_PHILO); // Create a fixed size thread pool
// for(int i = 0, len = names.length; i < len; ++i) {
// es.execute(new Philosopher(i, names[i])); // Start thread
// }
// es.shutdown();
for(int i = 0, len = names.length; i < len; ++i) {
new Thread(new Philosopher(i, names[i])).start();
}
}
}
Concurrency problems in reality are basically these three models or variants of these three models.
Test concurrent code
The testing of concurrent code is also very difficult. It is so difficult that we don't need to explain it. So here we just discuss how to solve this difficult problem. We suggest that you write some tests that can find problems and run these tests under different configurations and loads frequently. Don't ignore any failed tests. Defects in threaded code may occur only once in tens of thousands of tests. Specifically, there are several precautions:
- Don't attribute the failure of the system to accidental events, just like when you can't pull shit, you can't blame the earth for its lack of gravity.
- Let non concurrent code work first. Don't try to find defects in concurrent and non concurrent code at the same time.
- Write thread code that can run in different configuration environments.
- Write thread code that is easy to adjust, so you can adjust threads to optimize performance.
- Make the number of threads more than the number of CPUs or CPU cores, so that potential problems in the process of CPU scheduling switching will be exposed.
- Let concurrent code run on different platforms.
- Add some auxiliary test code to the concurrent code by means of automation or hard coding.
Concurrent programming in Java 7
TransferQueue is introduced in Java 7. It has a method called transfer more than BlockingQueue. If the receiving thread is waiting, the operation can hand over the task to it immediately. Otherwise, it will be blocked until the thread taking the task appears. You can use TransferQueue instead of BlockingQueue because it can achieve better performance.
I forgot one thing just now. Java 5 also introduces Callable interface, Future interface and FutureTask interface. They can also build concurrent applications. The code is as follows.
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class Test07 {
private static final int POOL_SIZE = 10;
static class CalcThread implements Callable<Double> {
private List<Double> dataList = new ArrayList<>();
public CalcThread() {
for(int i = 0; i < 10000; ++i) {
dataList.add(Math.random());
}
}
@Override
public Double call() throws Exception {
double total = 0;
for(Double d : dataList) {
total += d;
}
return total / dataList.size();
}
}
public static void main(String[] args) {
List<Future<Double>> fList = new ArrayList<>();
ExecutorService es = Executors.newFixedThreadPool(POOL_SIZE);
for(int i = 0; i < POOL_SIZE; ++i) {
fList.add(es.submit(new CalcThread()));
}
for(Future<Double> f : fList) {
try {
System.out.println(f.get());
} catch (Exception e) {
e.printStackTrace();
}
}
es.shutdown();
}
}
The Callable interface is also a single method interface. Obviously, it is a callback method, which is similar to the callback function in functional programming. Before Java 8, Lambda expressions could not be used in Java to simplify this functional programming. Unlike the Runnable interface, the callback method call method of the Callable interface returns an object that can obtain information at the end of thread execution in the Future tense. The call method in the above code is to return the calculated average value of 10000 random decimals between 0 and 1. We get this return value through an object of the Future interface. In the latest java version, the Callable interface and Runnable interface are annotated with @ functional interface, that is, it can create interface objects in a functional programming way (Lambda expression).
the following are the main methods of Future interface:
- get(): get the result. If the result is not ready, the get method will block until the result is obtained; Of course, you can also set the blocking timeout through parameters.
- cancel(): cancel before the end of the operation.
- isDone(): it can be used to judge whether the operation ends.
Branching / merging is also available in Java 7 (fork/join) framework, which can realize the automatic scheduling of tasks in the thread pool, and this scheduling is transparent to the user. In order to achieve this effect, the task must be decomposed in the way specified by the user, and then the execution results of the decomposed small tasks must be combined into the execution results of the original task. Obviously, the divide and conquer method is used The following code uses the branch / merge framework to calculate the sum of 1 to 10000. Of course, for such a simple task, the branch / merge framework is not needed at all, because the branch and merge itself will bring some overhead, but here we just explore how to use the branch / merge framework in the code to make full use of our code With the powerful computing power of modern multi-core CPU.
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
class Calculator extends RecursiveTask<Integer> {
private static final long serialVersionUID = 7333472779649130114L;
private static final int THRESHOLD = 10;
private int start;
private int end;
public Calculator(int start, int end) {
this.start = start;
this.end = end;
}
@Override
public Integer compute() {
int sum = 0;
if ((end - start) < THRESHOLD) { // When the problem is decomposed to a solvable level, the calculation results are directly obtained
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
int middle = (start + end) >>> 1;
// Split the task in two
Calculator left = new Calculator(start, middle);
Calculator right = new Calculator(middle + 1, end);
left.fork();
right.fork();
// Note: because this is a recursive task decomposition, it means that the next two will be divided into four and four into eight
sum = left.join() + right.join(); // Merge the results of the two subtasks
}
return sum;
}
}
public class Test08 {
public static void main(String[] args) throws Exception {
ForkJoinPool forkJoinPool = new ForkJoinPool();
Future<Integer> result = forkJoinPool.submit(new Calculator(1, 10000));
System.out.println(result.get());
}
}
With the advent of Java 7, the default array sorting algorithm in Java is no longer the classic quick sort (double pivot quick sort). The new sorting algorithm is called TimSort. It is a mixture of merge sort and insert sort. TimSort can make full use of the multi-core characteristics of modern processors through the branch merge framework, so as to obtain better performance (shorter sorting time).