1, Written examination form
It may be because of the recruitment of interns, so the written test is not very formal. An hr Intern directly sent me the questions in the form of PDF after adding me to wechat. He asked to write the answers in word and send them to her in 1 hour to 1.5 hours (without giving me any excel). The PDF did not explain the English code in the picture given by the questions. I was always confused.
To be clear: This is my own answer, which may not be correct. I have verified it in mysql that it can run ~ welcome to discuss it together~
2, Written examination content
First question
Create the corresponding table by yourself (verify whether the code is correct)
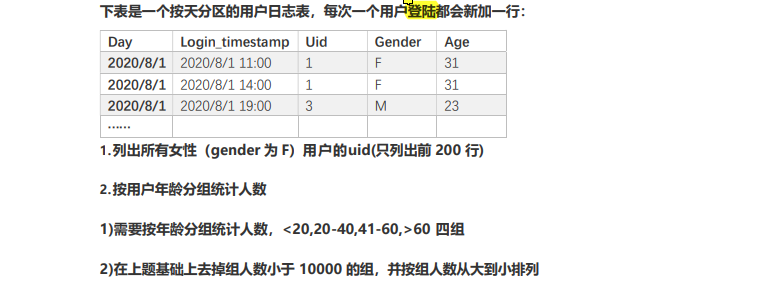
create table u_log (
day date not null,
login_timestamp timestamp not null,
uid int(2) not null,
gender char(1) not null,
age integer not null
);insert data
insert into u_log values ('2020/8/1', '2020/8/1 11:00',1,'F',31),
('2020/8/1', '2020/8/1 14:00',1,'F',31),
('2020/8/1', '2020/8/1 19:00',3,'M',23),
('2020/8/1', '2020/8/1 14:00',1,'F',31),
('2020/8/1', '2020/8/1 20:00',2,'M',19),
('2020/8/1', '2020/8/1 21:00',4,'M',54),
('2020/8/1', '2020/8/1 21:05',5,'M',55);Get tables in the database
1. List female user uid and only display the top 200
select distinct uid from u_log where gender='F' order by uid limit 200 ;
2. Statistics by age group
(1) Divided into < 20, 20-40, 41-60, > 60
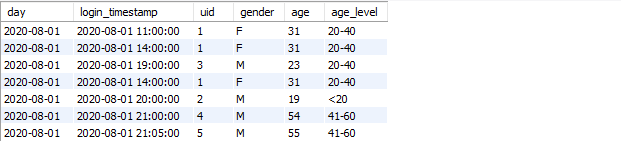
First add a column of age groups
select *, (case when 0<=age and age < 20 then '<20' when 20<=age and age <40 then '20-40' when 40<age and age <= 60 then '41-60' else '>60' end) as age_level from u_log ;
The query result is
The results were obtained by grouping statistics
select age_level,count(*) from ( select *, (case when 0<=age and age < 20 then '<20' when 20<=age and age <40 then '20-40' when 40<age and age <= 60 then '41-60' else '>60' end) as age_level from u_log ) a group by age_level;
Query results

Second question
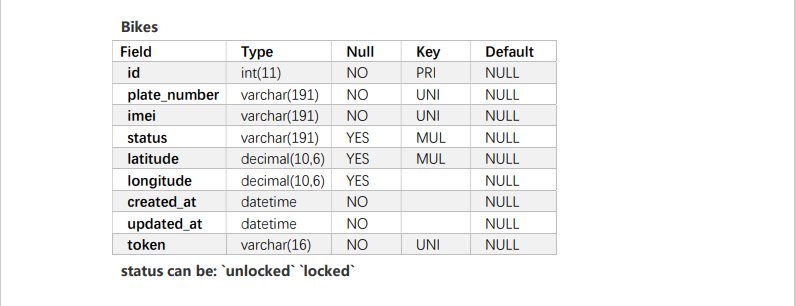
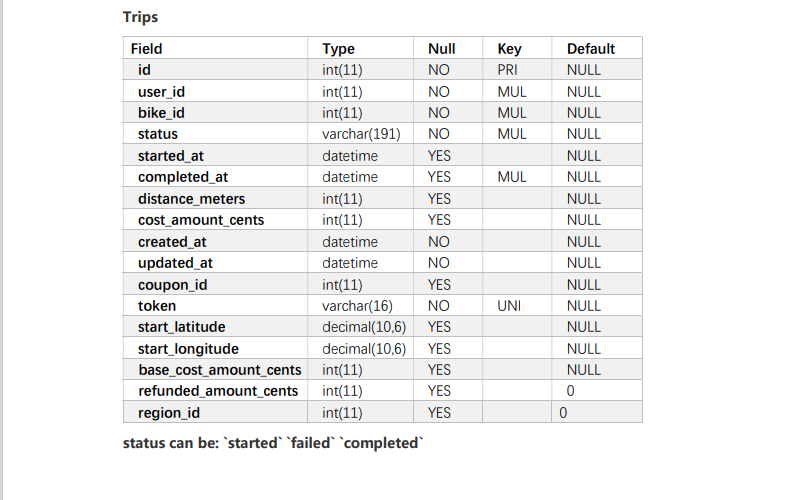
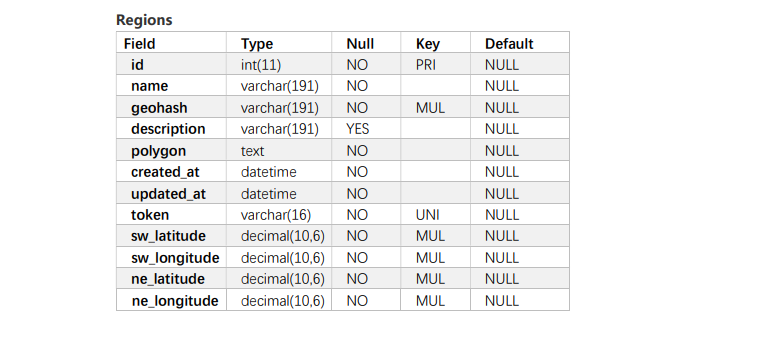
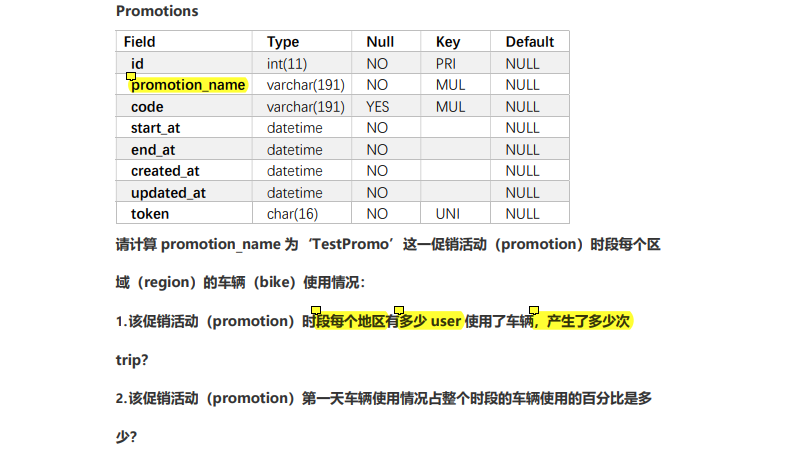
I don't think the bikes table and users are used in this problem, so I only built three tables: trips, region and promotion
Create table statement
create table trips (
id int(11) not null primary key default 0,
user_id int(11) not null default 0,
bike_id int(11) not null default 0,
status varchar(191) not null default '0',
started_at datetime default '0000-00-00',
completed_at datetime default '0000-00-00',
region_id int(11) default 0
);
create table regions (
id int(11) not null primary key default 0,
name varchar(191)
);
create table promotions (
id int(11) not null primary key default 0,
p_name varchar(191),
start_at datetime,
end_at datetime);
insert data
insert into trips values(1,001,545,'completed','2020-08-01 09:00','2020-08-01 09:05',2),(2,010,589,'completed','2020-08-01 10:00','2020-08-01 09:02',1), (3,024,245,'failed','2020-08-02 08:00','2020-08-02 08:05',1),(4,001,556,'completed','2020-08-02 09:00','2020-08-01 09:05',2), (5,054,123,'completed','2020-08-03 20:00','2020-08-03 21:05',1),(6,078,545,'completed','2020-08-10 19:00','2020-08-10 19:05',1), (7,011,111,'completed','2020-08-11 02:00','2020-08-11 02:05',2),(8,001,545,'started','2020-09-11 09:00','2020-09-11 09:05',2); insert into regions values(1,'Pudong New Area'),(2,'Chengbei high tech Zone'); insert into promotions values(1,'8 Lunar promotion','2020-08-01','2020-08-31');
1. How many users and orders are there during the promotion (write the activity name as August promotion when inserting data)
select r.name,count(distinct user_id),count(r.id)
from trips t
join regions r
on t.region_id = r.id
where started_at between
(select start_at from promotions where p_name = '8 Lunar promotion')
and
(select end_at from promotions where p_name = '8 Lunar promotion')
group by r.name;
2. Proportion of first day use
select concat(
round(sum(case when day(started_at) =
(select day(start_at) from promotions
where p_name = '8 Lunar promotion') then 1 else 0 end)
/
sum(case when started_at between
(select start_at from promotions
where p_name = '8 Lunar promotion') and (select end_at from promotions where p_name = '8 Lunar promotion')
then 1 else 0 end)*100
,2)
,'%') as a
from trips;Question 3
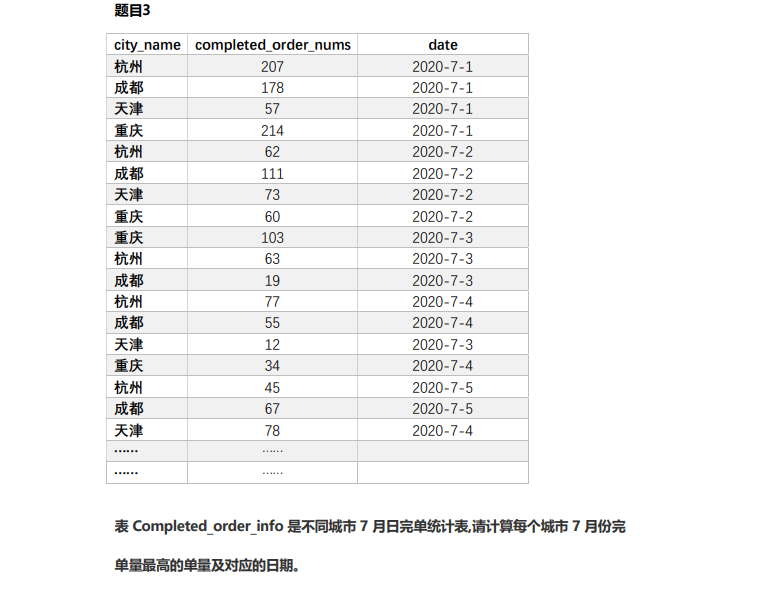
Create table statement
create table completes_order_info (
city_name varchar(191),
completed_order_nums int(3),
date date
);insert data
insert into completes_order_info values ('Hangzhou',207,'2020-7-1'),('Chengdu',178,'2020-7-1'),
('Tianjin',57,'2020-7-01'),('Chongqing',214,'2020-7-01'),
('Hangzhou',62,'2020-7-02'),('Chengdu',111,'2020-7-02'),
('Tianjin',73,'2020-7-02'),('Chongqing',60,'2020-7-02'),
('Chongqing',103,'2020-7-03'),('Hangzhou',63,'2020-7-03');1. The order quantity and date with the highest order quantity in each city
select a.city_name,a.completed_order_nums,a.date from( select *, row_number()over(partition by city_name order by completed_order_nums desc) as rn from completes_order_info) a where rn = 1;
Question 4

Find the details of each order with completion status of 1 from 2021-01-04 to 2021-01-10 and the completion time of the user's last and next order
Question 5
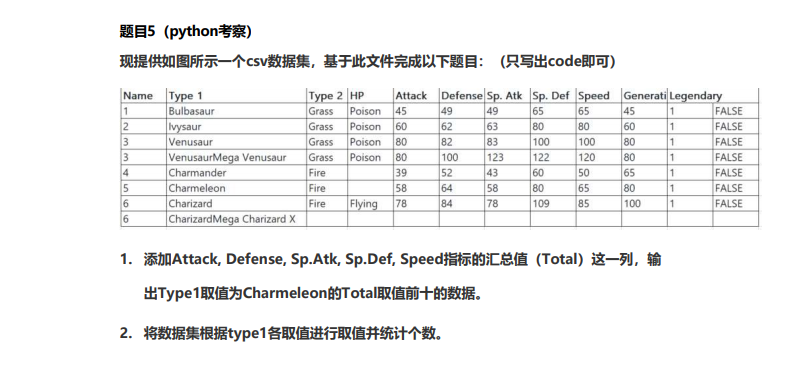 I built a table named python. csv myself
I built a table named python. csv myself
1. Add the Total column of Attack, Defense, Sp.Atk, Sp.Def, Speed and Generation indicators, and output the data with the value of type 1 in the top ten of the Total value of Charmeleon.
import pandas as pd
#read in data
data = pd.read_csv(open('C:/Users/dell/Desktop/folder/Didi written test 9.9/python investigate.csv',encoding = 'UTF-8'))
#Add summary column
data['total'] = data[['Attack','Dedense','Sp.Atk','Sp.Def','Speed','Generation']].apply( lambda x: x.sum(),axis=1)
#Take out the first 10 lines
data[data['type1']=='chameleon'][:10]data is
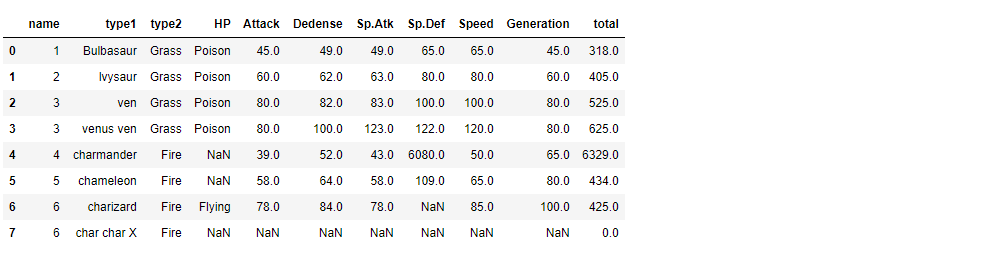 Get results
Get results

2. Take values and count the number of data sets according to the values of type1.
data.type1.value_counts()

If there are mistakes, you are welcome to point them out, discuss them and make progress together~
I wish everyone can achieve the desired results~