Pain point
In Baidu search engine, the keywords entered are not completely accurate,
The search engine can search the content similar to the keyword. When Jingdong searches for goods, it can also search the content similar to it!
However, in our relational database, this cannot be done; Because the database is an accurate match;
In the actual business, more often, although the content entered by the user is not so accurate, I also hope to be able to search for similar content instead of directly telling me that I can't find it!
terms of settlement
Full text index:
The People's Republic of China
Participle:
Split a long search sentence into various words, match the words and query the data;
It is no longer based on relational database to query, but based on full-text index to search
1. Republic of
2. People
3. Chinese
4. China
lucene. What is it? Www. 18fu
Lucene.net is a high-performance and all-round search engine framework class library for full-text retrieval, which is completely developed by C# development. It is a technology, any application that needs full-text retrieval.
Lucene was originally in java, but later appeared in C #;
Version:3.0.3 --- (it seems that it is not updated now. There are many bug s in the latest beta version)
http://lucenenet.apache.org/download/download.html
If you need to build a full-text retrieval or log system. It is recommended to use ElasticSearch+Logstash+Kibana in conjunction with NEST. There are official operation documents. You can view learning.
ps: ElasticSearch's 9200 products should not be open to the public network.
lucene.net and various query methods
One in and one out;
First step: generate Lucene index from relational database (through word segmentation storage);
One out: query, through the query conditions and word segmentation to match the data in Lucene index (no longer query based on relational database, but query based on Lucene index)
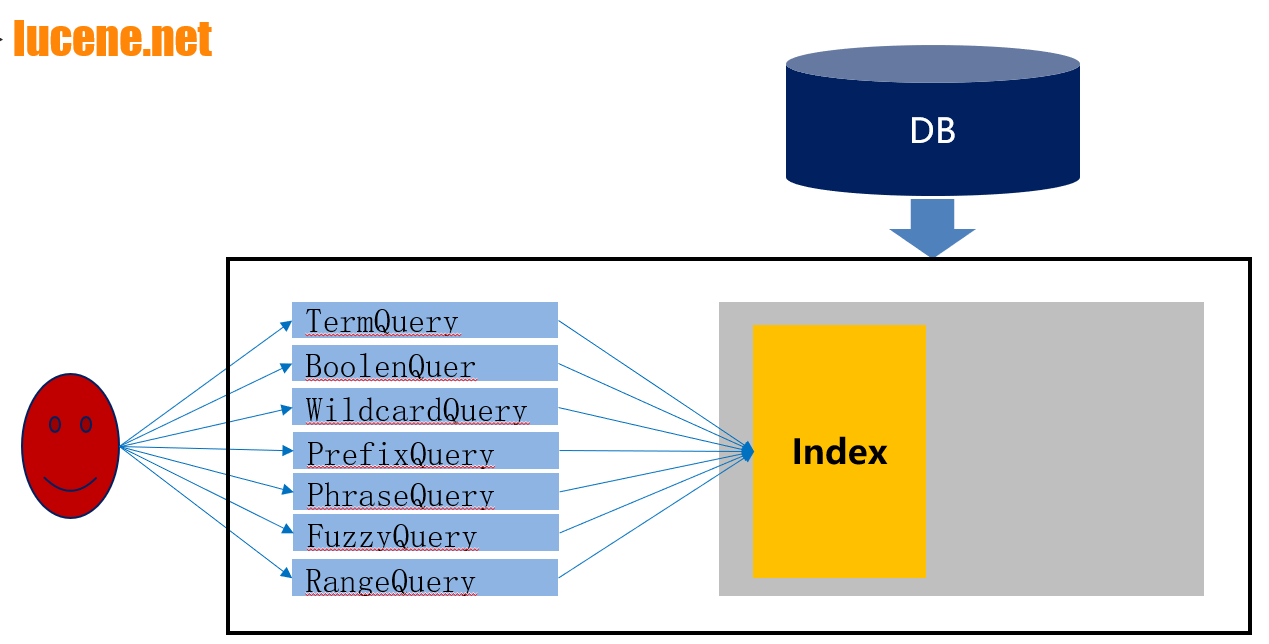
- Lucene.Net.Documents
- Lucene.Net.Analysis
- Lucene.Net.Index
- Lucene.Net.QueryParsers
- Lucene.Net.Search
- Lucene.Net.Store
- Lucene.Net.Util
lucene storage structure
Documents
Provide a simple document class. A document just includes a series of named Fields. Their contents can be text or an IO Instance of reader.
It is used to store a record in the database - a record in the database corresponds to a document; When storing, there must be more than one document;
Analysis
An abstract analyzer API is defined to convert text from a Reader to a TokenStream, that is, an enumeration container including some Tokens. The composition of a TokenStream is generated by applying TokenFilters to the output of a Tokenizer. A small number of implementations of standard analyzer and stopbased analyzer have been provided
Word segmenter: to segment sentences;
Index
It provides two main classes, one is IndexWriter, which is used to create indexes and add document s, and the other is IndexSearcher, which is used to access data in indexes.
Complete the reading and writing of the index;
QueryParsers
Implement a QueryParser.
When querying, you need to set up various query criteria;
Give you a long sentence, through word segmentation, split to generate various query conditions;
Search
Provide data structures to present queries: TermQuery is used for individual words, PhraseQuery is used for phrases, and boolean query is used for queries combined through boolean relationships. The abstract Searcher is used to transform queries into hits. IndexSearcher implements retrieval on a single IndexReader
Extract data from the index according to the conditions you provide;
Store
An abstract class is defined for storing persistent data, i.e. Directory. A collection contains some named files, which are written by an IndexOutput and read by an IndexInput. Two implementations are provided. FSDirectory uses a file system Directory to store files, while the other RAMDirectory implements the memory resident data structures that treat files as resident memory
Used to save index data, including folders and related files;
Search
Search TermQuery
TermQuery: unit query new Term("title", "Zhang San")
title: Zhang San
Search BoolenQuery
BoolenQuery:
new Term("title", "Zhang San") and new Term("title", "Li Si")
title: Zhang San + title: Li Si and==+
new Term("title","Zhang San") or new Term("title","Li Si")
title:Zhang San title:Li Si or== Space
Search WildcardQuery
WildcardQuery: wildcard
new Term("title", "Zhang?") Title: Zhang? Match starts with "Zhang"
Search PrefixQuery
PrefixQuery: prefix query starts with xx
title: Zhang*
Search PhraseQuery
PhraseQuery: the interval distance does not include China, and the distance between them cannot exceed 5
title: "the Republic of China" ~ 5
Republic of China
Search FuzzyQuery
FuzzyQuery: approximate query, iPhone --- iPhone Title: iPhone~
Search RangeQuery
RangeQuery: range query [1100] {1100}
Open interval
Price time
lucene usage process
Nuget import file
- Lucene.Net //nuget implementation dll
- PanGu / / the three files below are used to realize word segmentation
After quoting Pangu participle, there will be another Dict folder under the directory structure, which contains the dictionary used by Pangu participle
Insert data to index
/// <summary>
///Initialize index
/// </summary>
public static void InitIndex()
{
List<Commodity> commodityList = GetList();//Get data source
FSDirectory directory = FSDirectory.Open(StaticConstant.TestIndexPath);//Folder (StaticConstant.TestIndexPath) local storage path
//After word segmentation, write the content to the hard disk
//Pangu analyzer Pangu participle; The people's Republic of China, from the back to the front, matches the same words as the dictionary, and then saves them; I suggest you look at the official website of Pangu participle; Dictionaries can be maintained manually;
//City can play - online popular words - no by default, Pangu participle, we can add these words by ourselves;
using (IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), true, IndexWriter.MaxFieldLength.LIMITED))//Index writer
{
foreach (Commodity commdity in commodityList)
{
int k = 22;
//for (int k = 0; k < 10; k++)
//{
Document doc = new Document();//A piece of data
doc.Add(new Field("id", commdity.Id.ToString(), Field.Store.NO, Field.Index.NOT_ANALYZED));//Whether a field column name value is saved and whether the value is word segmentation
doc.Add(new Field("title", commdity.Title, Field.Store.YES, Field.Index.ANALYZED));
doc.Add(new Field("url", commdity.Url, Field.Store.NO, Field.Index.NOT_ANALYZED));
doc.Add(new Field("imageurl", commdity.ImageUrl, Field.Store.NO, Field.Index.NOT_ANALYZED));
doc.Add(new Field("content", "this is lucene working,powerful tool " + k, Field.Store.YES, Field.Index.ANALYZED));
doc.Add(new NumericField("price", Field.Store.YES, true).SetDoubleValue((double)(commdity.Price + k)));
//doc.Add(new NumericField("time", Field.Store.YES, true).SetLongValue(DateTime.Now.ToFileTimeUtc()));
doc.Add(new NumericField("time", Field.Store.YES, true).SetIntValue(int.Parse(DateTime.Now.ToString("yyyyMMdd")) + k));
writer.AddDocument(doc);//Write it in
//}
}
writer.Optimize();//Optimization is merging
}
}
Query data
public static void Show()
{
FSDirectory dir = FSDirectory.Open(StaticConstant.TestIndexPath);
IndexSearcher searcher = new IndexSearcher(dir);//Finder
{
FuzzyQuery query = new FuzzyQuery(new Term("title", "Coffee products are also high school politics"));
//Termquery = new termquery (new term ("title", "anniversary")// contain
TopDocs docs = searcher.Search(query, null, 10000);//Data found
foreach (ScoreDoc sd in docs.ScoreDocs)
{
Document doc = searcher.Doc(sd.Doc);
Console.WriteLine("***************************************");
Console.WriteLine(string.Format("id={0}", doc.Get("id")));
Console.WriteLine(string.Format("title={0}", doc.Get("title")));
Console.WriteLine(string.Format("time={0}", doc.Get("time")));
Console.WriteLine(string.Format("price={0}", doc.Get("price")));
Console.WriteLine(string.Format("content={0}", doc.Get("content")));
}
Console.WriteLine("1 Hit a total of{0}individual", docs.TotalHits);
}
QueryParser parser = new QueryParser(Version.LUCENE_30, "title", new PanGuAnalyzer());//Parser
{
string keyword = "The new curriculum standard of political education in senior high school electives legal knowledge in life";
//string keyword = "senior high school politicians teach the new curriculum standard elective legal knowledge in life, and coffee products are also senior high school politics";
{
Query query = parser.Parse(keyword);
TopDocs docs = searcher.Search(query, null, 10000);//Data found
int i = 0;
foreach (ScoreDoc sd in docs.ScoreDocs)
{
if (i++ < 1000)
{
Document doc = searcher.Doc(sd.Doc);
Console.WriteLine("***************************************");
Console.WriteLine(string.Format("id={0}", doc.Get("id")));
Console.WriteLine(string.Format("title={0}", doc.Get("title")));
Console.WriteLine(string.Format("time={0}", doc.Get("time")));
Console.WriteLine(string.Format("price={0}", doc.Get("price")));
}
}
Console.WriteLine($"Total hits{docs.TotalHits}");
}
{
Query query = parser.Parse(keyword);
NumericRangeFilter<int> timeFilter = NumericRangeFilter.NewIntRange("time", 20090101, 20201231, true, true);//filter
SortField sortPrice = new SortField("price", SortField.DOUBLE, false);//false:: descending order
SortField sortTime = new SortField("time", SortField.INT, true);//true: ascending order
Sort sort = new Sort(sortTime, sortPrice);//Which comes first and which comes second
TopDocs docs = searcher.Search(query, timeFilter, 10000, sort);//Data found
//What can I do? You can query by page!
int i = 0;
foreach (ScoreDoc sd in docs.ScoreDocs)
{
if (i++ < 1000)
{
Document doc = searcher.Doc(sd.Doc);
Console.WriteLine("***************************************");
Console.WriteLine(string.Format("id={0}", doc.Get("id")));
Console.WriteLine(string.Format("title={0}", doc.Get("title")));
Console.WriteLine(string.Format("time={0}", doc.Get("time")));
Console.WriteLine(string.Format("price={0}", doc.Get("price")));
}
}
Console.WriteLine("3 Hit a total of{0}individual", docs.TotalHits);
}
}
}
- In the process of using it, I found a problem. In a word, I just added a space between the words of the Title, and obtained little data.
- To solve problem 1, manually add spaces to solve it. The results can be seen at last
- However, ElasticSearch is still recommended. Lucene feels that there are few documents, few application scenarios in the future, and it takes too much effort to encapsulate itself.