SogouQ log analysis
Data research and business analysis
Sogou lab is used to provide [user query log (SogouQ)] data, and Spark framework is used to encapsulate the data into RDD for business data processing and analysis.
- 1) . data introduction:
The search engine query log database is designed as a collection of Web query log data including some web query requirements and user clicks of Sogou search engine for about one month (June 2008).
- 2) . data format
Access time \ tuser ID\t [query term] \ t the ranking of the URL in the returned results \ t the sequence number clicked by the user \ t the URL clicked by the user

3) Data download: it is divided into three data sets with different sizes
Mini version (sample data, 376KB):
http://download.labs.sogou.com/dl/sogoulabdown/SogouQ/SogouQ.mini.zip
Compact version (1-day data, 63MB):
http://download.labs.sogou.com/dl/sogoulabdown/SogouQ/SogouQ.reduced.zip
Full Version (1.9GB):
http://www.sogou.com/labs/resource/ftp.php?dir=/Data/SogouQ/SogouQ.zip
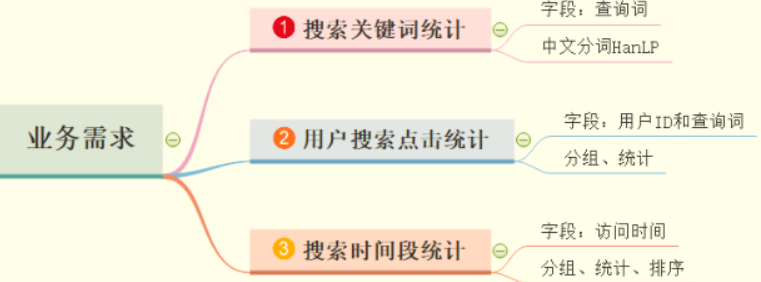
For SougouQ query log data, analyze business requirements:
use SparkContext Read log data and encapsulate it into RDD Data collection, call Transformation Function sum Action Function place
Rational analysis, flexible grasp of Scala language programming.
HanLP Chinese word segmentation
HanLP is a natural language processing toolkit for production environment. HanLP is a Java toolkit composed of a series of models and algorithms. The goal is to popularize the application of natural language processing in production environment.
Official website: http://www.hanlp.com/ , add Maven dependency
<!-- https://mvnrepository.com/artifact/com.hankcs/hanlp -->
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.7.7</version>
</dependency>
Demonstration example
object HanLpTest {
def main(args: Array[String]): Unit = {
// Getting started Demo
val terms: util.List[Term] = HanLP.segment("Jack Altman complete video")
println(terms)
import scala.collection.JavaConverters._
println(terms.asScala.map(term => term.word.trim))
// Standard participle
val terms1: util.List[Term] = StandardTokenizer.segment("to be on holiday++Dragon Boat Festival++Chongyang")
println(terms1.asScala.map(_.word.replaceAll("\\s+", "")))
}
}
Data encapsulation SogouRecord
Encapsulate each line of log data into the CaseClass sample class SogouRecord to facilitate subsequent processing
/**
* User search click web Record
*
* @param queryTime Access time, format: HH:mm:ss
* @param userId User ID
* @param queryWords Query words
* @param resultRank The ranking of the URL in the returned results
* @param clickRank Sequence number clicked by the user
* @param clickUrl URL clicked by the user
*/
case class SogouRecord(
queryTime: String, //
userId: String, //
queryWords: String, //
resultRank: Int, //
clickRank: Int, //
clickUrl: String //
)
Build the SparkContext instance object and read the sogouq Sample data, encapsulated in SougoRecord.
// In the Spark application, the entry is: SparkContext. You must create an instance object, load data and scheduler execution
val sc: SparkContext = {
// Create a SparkConf object
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// Building a SparkContext instance object
SparkContext.getOrCreate(sparkConf)
}
// TODO: 1. Read search log data from local file system
val rawLogsRDD: RDD[String] = sc.textFile("datas/sogou/SogouQ.sample", minPartitions = 2)
//println(s"First:\n ${rawLogsRDD.first()}")
//println(s"Count: ${rawLogsRDD.count()}")
// TODO: 2. Analyze the data (filter the unqualified data first) and encapsulate the sample class SogouRecord object
val sogouLogsRDD: RDD[SogouRecord] = rawLogsRDD
// Filter data
.filter(log => null != log && log.trim.split("\\s+").length == 6)
// Parse logs and encapsulate instance objects
.mapPartitions(iter => {
iter.map(log => {
// Install separator partition data
val split: Array[String] = log.trim.split("\\s+")
// Building instance objects
SogouRecord(
split(0),
split(1), //
split(2).replaceAll("\\[", "").replace("]", ""),
split(3).toInt,
split(4).toInt,
split(5)
)
})
})
//println(s"Count = ${sogouLogsRDD.count()}")
//println(s"First: ${sogouLogsRDD.first()}")
Supplementary knowledge points!!!
In regular expressions\s Matches any white space characters, including spaces, tabs, page breaks, and so on, Equivalent to[ \f\n\r\t\v] \f -> Match a page feed \n -> Match a newline character \r -> Match a carriage return \t -> Match a tab \v -> Match a vertical tab And“\s+"It means matching any number of above characters. And because the backslash is Java Is an escape character, so in Java Inside, we're going to use it like this“\\s+". So here's the problem“\\s+"What are the usage scenarios? notes: [\s]Indicates that as long as there is blank space, it will match [\S]Indicates that if it is not blank, it matches
Search keyword statistics
Get the user's [query words], use HanLP to segment words, and count the occurrence times according to word grouping and aggregation, similar to the WordCount program. The specific code is as follows:
Step 1: get the data of the [query words] field in each log data
Step 2: use HanLP to segment the query words
Step 3: make word frequency statistics according to the words in word segmentation, similar to WordCount
// TODO: 3. Analyze the data according to the requirements
/*
Demand 1. Search keyword statistics and use HanLP Chinese word segmentation
- Step 1: get the data of the [query words] field in each log data
- Step 2: use HanLP to segment the query words
- Step 3: make word frequency statistics according to the words in word segmentation, similar to WordCount
*/
val queryKeyWordsCountRDD: RDD[(String, Int)] = sogouLogsRDD
// Extract the value of the query term field
.flatMap { record =>
val query: String = record.queryWords
// Use HanLP word segmentation
val terms: util.List[Term] = HanLP.segment(query.trim)
// Convert to the set list in Scala and process each word segmentation
terms.asScala.map(term => term.word.trim)
}
// Convert each participle into a binary, indicating that the grouping occurs once
.map(word => (word, 1))
// Group according to words and count the times
.reduceByKey((tmp, item) => tmp + item)
//queryKeyWordsCountRDD.take(10).foreach(println)
// TODO: get query word Top10
queryKeyWordsCountRDD
.map(tuple => tuple.swap)
.sortByKey(ascending = false) // Descending sort
.take(10)
.foreach(println)
User search click statistics
Count the number of times each user clicks on the web page for each search term, which can be used as the evaluation index of search engine search effect. First group according to the user ID, then group according to the query term, and finally count the times to calculate the maximum, minimum and average times.
/*
Demand II. Statistics of user search times
TODO: Count the number of clicks of each user on each search term, and two-dimensional grouping: group users first, and then search terms
SQL:
SELECT user_id, query_words, COUNT(1) AS total FROM records GROUP BY user_id, query_words
*/
val clickCountRDD: RDD[((String, String), Int)] = sogouLogsRDD
// Extract field values
.map(record => (record.userId, record.queryWords) -> 1)
// Group according to Key (userId first, then queryWords) for aggregation statistics
.reduceByKey(_ + _)
//clickCountRDD.take(50).foreach(println)
//TODO: extract the search times of each user separately for statistics
val countRDD: RDD[Int] = clickCountRDD.map(tuple => tuple._2)
println(s"Max Click Count: ${countRDD.max()}")
println(s"Min Click Count: ${countRDD.min()}")
println(s"stats Click Count: ${countRDD.stats()}") // mathematical statistics
Search time period statistics
Click search engines to find the number of search engines users like to use, and then click search engines to get the number of search hours.
/*
Demand 3. Statistics of search time period, counting the number of user searches per hour
00:00:00 -> 00 Extract hours
*/
val hourCountRDD: RDD[(Int, Int)] = sogouLogsRDD
// Extract time field value
.map { record =>
val queryTime = record.queryTime
// Get hours
val hour = queryTime.substring(0, 2)
// Returns a binary
(hour.toInt, 1)
}
// Aggregate statistics by hour
.foldByKey(0)(_ + _)
//hourCountRDD.foreach(println)
// TODO: sort by times in descending order
hourCountRDD
.top(24)(Ordering.by(tuple => tuple._2))
.foreach(println)