Deep dive kafka producer - Core Architecture
3. Deep dive KafkaProducer infrastructure
kafka has customized a set of network protocols, which can be implemented in any language to achieve the effect of pushing messages to and from kafka clusters. The clients module in the source code of kafka version 2.8.0 is the official default implementation of Java producer and consumer. We will focus on the implementation of producer in this class.
kafka producer sample demo
According to international practice, let's start with a demo example to show the students the basic use of kafka Producer. The specific code of the example is as follows:
public class ProducerDemo {
public static void main(String[] args) throws Exception {
Properties config = new Properties();
config.put("client.id", "ProducerDemo");
// Specify the address of the kafka broker cluster
config.put("bootstrap.servers", "localhost:9092");
// Before configuring the kafka cluster response, how many replica s need to successfully copy the message. all indicates that the entire ISR set has been copied
config.put("acks", "all");
// Specifies the serializer of message key and value, which is responsible for serializing KV into byte array
config.put("key.serializer", StringSerializer.class);
config.put("value.serializer", StringSerializer.class);
KafkaProducer<String, String> producer = new KafkaProducer<>(config);
for (int i = 0; i < 10; i++) {
// value of message
long startTime = System.currentTimeMillis();
// Construct a ProducerRecord object, in which the target topic, key and value of the message are recorded
ProducerRecord<String, String> record =
new ProducerRecord<>("test_topic", String.valueOf(i), "YangSizheng_" + startTime);
// The second parameter is an anonymous CallBack object. When the producer receives the ACK confirmation message from the kafka cluster,
// Will call its onCompletion() method to complete the callback
Future<RecordMetadata> future = producer.send(record, new Callback() {
public void onCompletion(RecordMetadata metadata, Exception e) {
if (e != null)
System.out.println("Send failed for record:" + record + ", error message:" + e.getMessage());
}
});
// The send() method sends a message asynchronously and returns a Future object. If you need to send synchronously, you can call its get() method,
// The returned RecordMetadata contains which partition the message falls on and how many offset s are allocated
RecordMetadata recordMetadata = future.get();
System.out.println("partition:" + recordMetadata.partition()
+ ", offset:" + recordMetadata.offset());
}
}
}
Before executing the producer demo, we execute Kafka - console - consumer Start the command line of consumer:
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test_topic
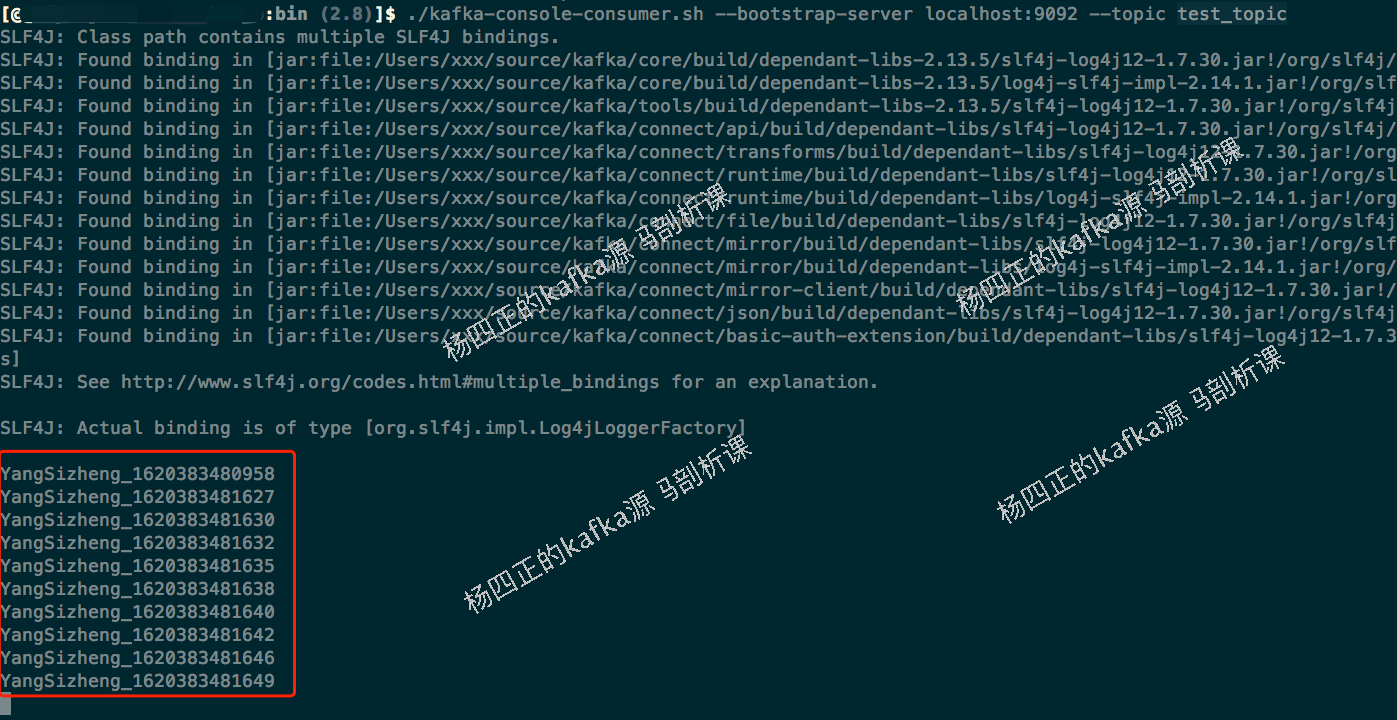
Then execute ProducerDemo, and you can see the following output on the console:
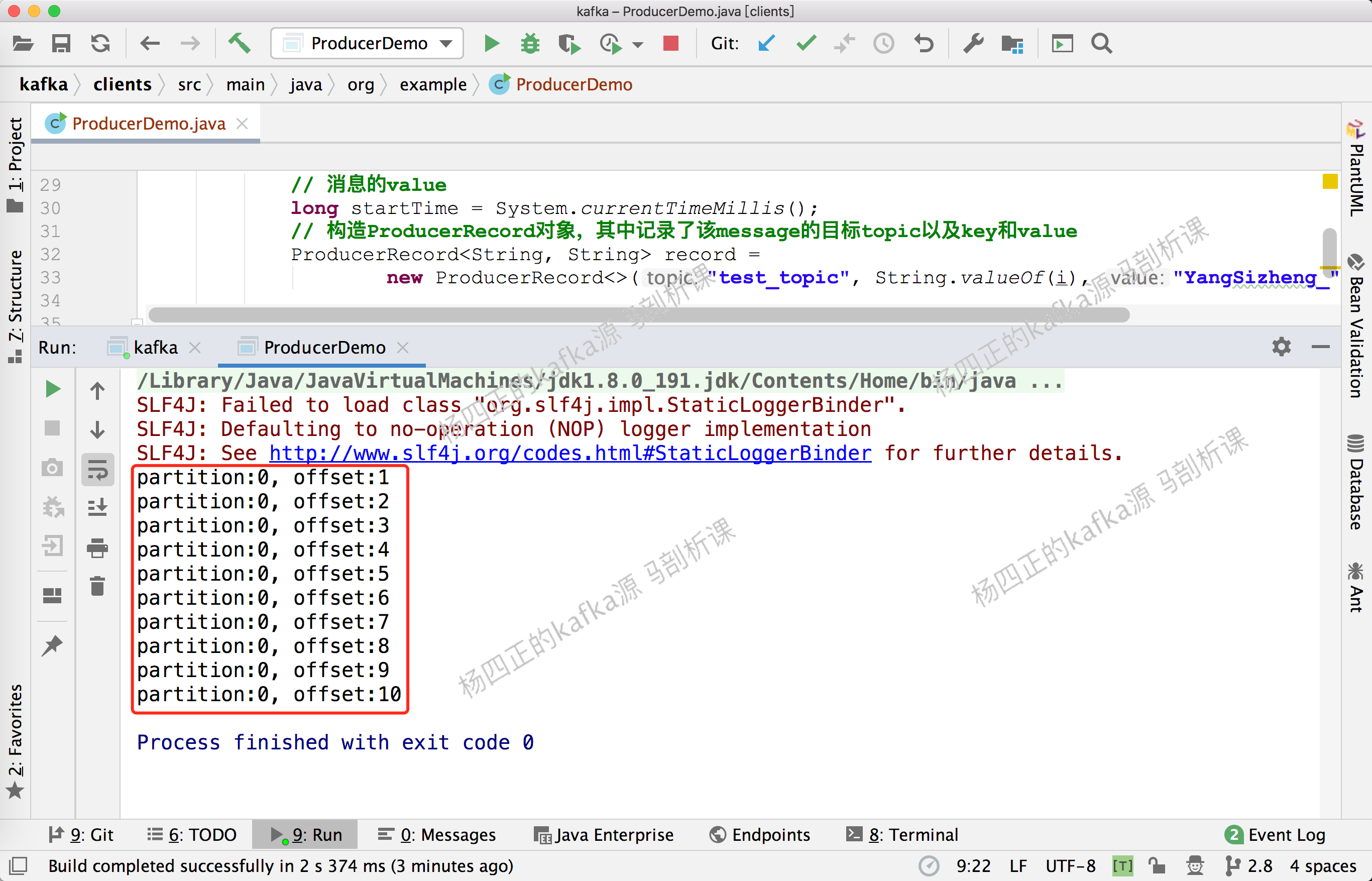
At Kafka console consumer The following output can be seen on the SH command line:
Overview of kafka producer architecture
After understanding the basic use of kafka producer, we began to introduce the architecture of kafka producer in depth. There is no need to rush a picture. The following figure is the core architecture of kafka producer:
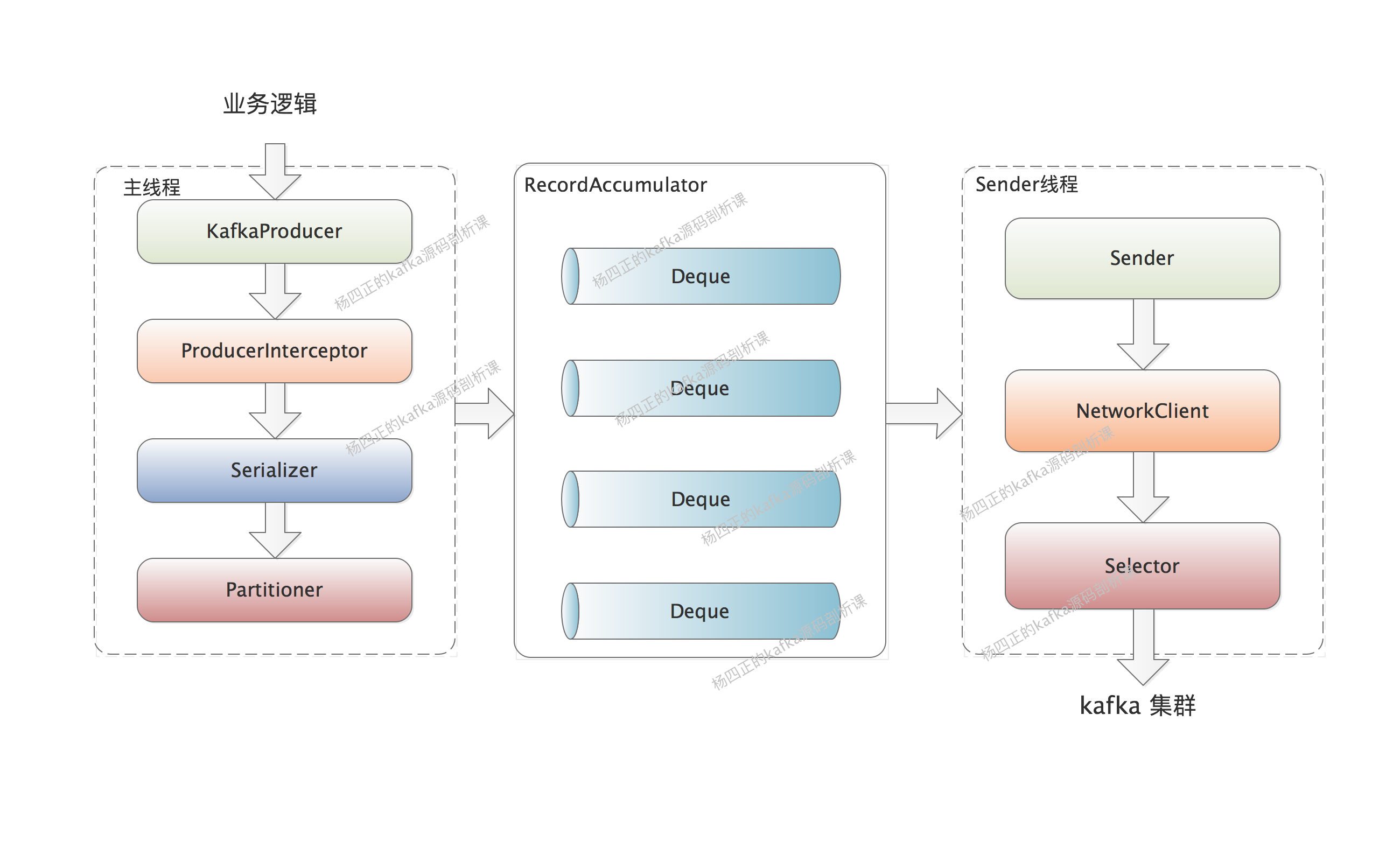
Here is a description of the core components involved in the above figure. Here, two threads are involved, one is our business thread (that is, the main thread in the figure), and the other is the Sender thread. Let's talk about them one by one.
The first is the logic of the main thread:
- First, producer interceptors filter or modify message s.
- Serializer is used to serialize the key and value of message.
- The Partitioner selects the appropriate partition for the message according to a certain policy.
- Encapsulate the message as a producer record and write it to the RecordAccumulator for temporary storage. Multiple queues are maintained in the RecordAccumulator object, which can be regarded as a buffer of messages to realize the batch sending of messages.
Let's look at the logic of the Sender thread:
- The Sender thread obtains message data in batch from the RecordAccumulator and constructs a ClientRequest.
- Send the constructed ClientRequest to the NetworkClient client.
- The NetworkClient client puts the request into the cache of KafkaChannel.
- NetworkClient executes network I/O and completes the sending of requests.
- NetworkClient receives the response, calls the callback function of ClientRequest, and finally triggers the callback function registered on each message.
KafkaProducer.send() core
After introducing the core architecture and process of kafka producer, we begin to analyze kafka producer The send () method, that is, the core logic of the main thread, or the opening diagram. It's easy to say later:
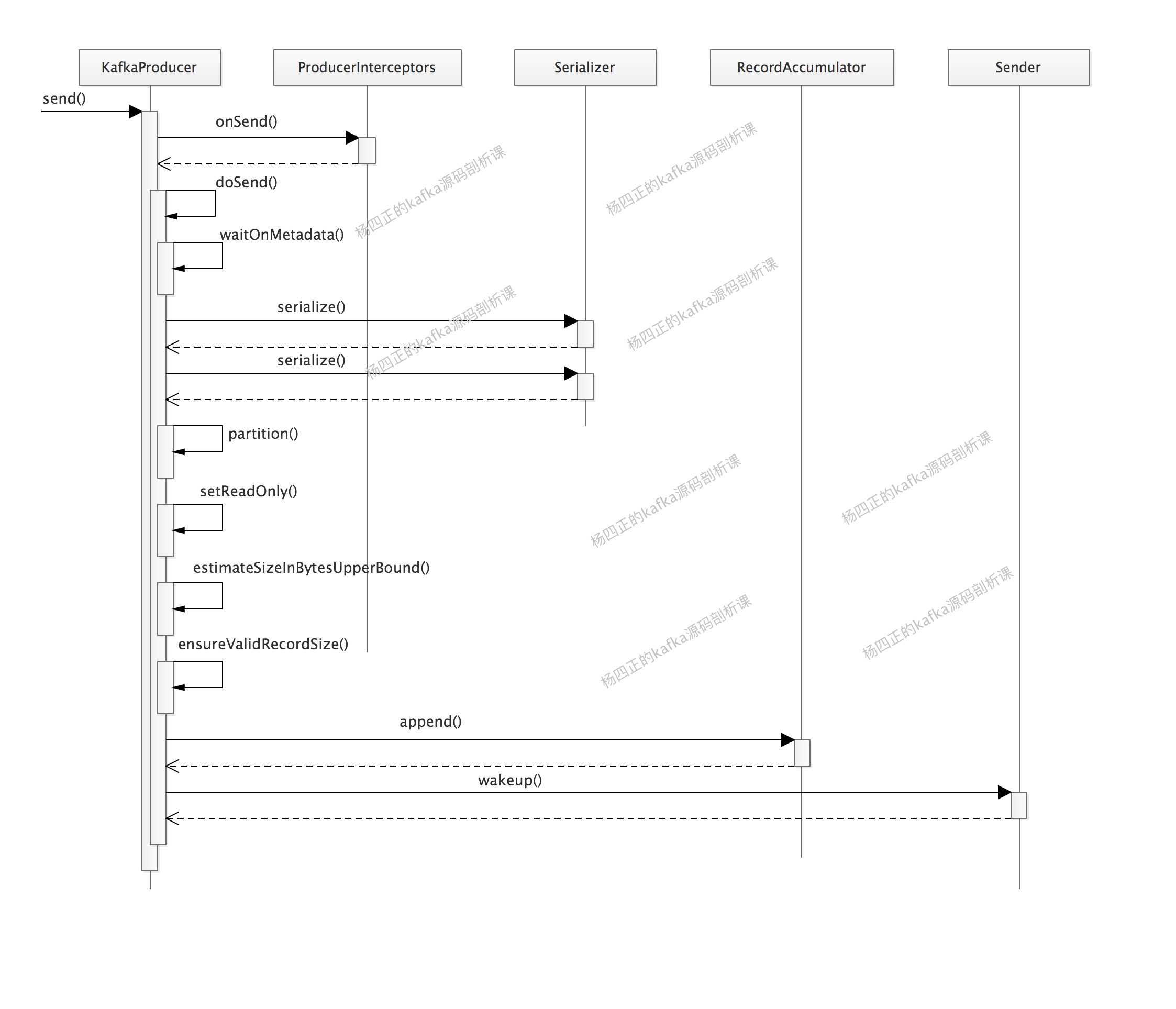
Let's describe Kafka producer The core logic of the send () method, that is, the core steps in the figure above:
- The main thread first calls producer interceptors Modify the send () or on message method. here
- Then, update the Kafka cluster information through the waitOnMetadata() method. The bottom layer is actually to update the Metadata by waking up the Sender thread. The Metadata stores the Kafka cluster Metadata.
- Next, execute serializer The Serialize () method completes the serialization of message key and value.
- partition() is then called to select the appropriate partition for message.
- Call the append() method to write the message to the RecordAccumulator for temporary storage.
- Finally, wake up the Sender thread, and then the Sender thread sends message s in batches from the RecordAccumulator to the kafka cluster.
ProducerInterceptor
Let's first look at ProducerInterceptors, which maintains a collection of producerinceptors. Its onSend() method, onAcknowledgement() method and onSendError() method are actually methods that call the collection of ProducerInterceptors in a loop.
We can intercept or modify the message to be sent by implementing the onSend() method of the producerinceptor interface, or preprocess the kafka cluster response by implementing the onAcknowledgement() method and onSendError() method before the user's Callback.
Kafka Metadata
When we send a message through KafkaProducer, we only specify which topic the message is to be written to, but not the partition to be written.
However, the partition of the same topic may be located on different brokers in kafka, so the producer needs to know the meta information of all partitions under the topic (i.e. the IP, port and other information of the broker) clearly, so as to establish a network connection with the broker where the partition is located and send a message.
In KafkaProducer, Node, TopicPartition and PartitionInfo are used to record Kafka cluster metadata:
- Node refers to a node in the kafka cluster, which maintains the basic information of the node, such as host, ip, port, etc.
- TopicPartition is used to abstract a partition in a topic, which maintains the name of the topic and the number information of the partition.
- PartitionInfo is used to abstract the information of a partition, where:
- The leader field records the id of the node where the leader replica is located
- The replica field records the node information of all replicas
- The inSyncReplicas field records the node information of all replicas in the ISR set.
kafka producer will encapsulate the basic information of the above three dimensions into cluster objects for use. The following is the information contained in Cluster:
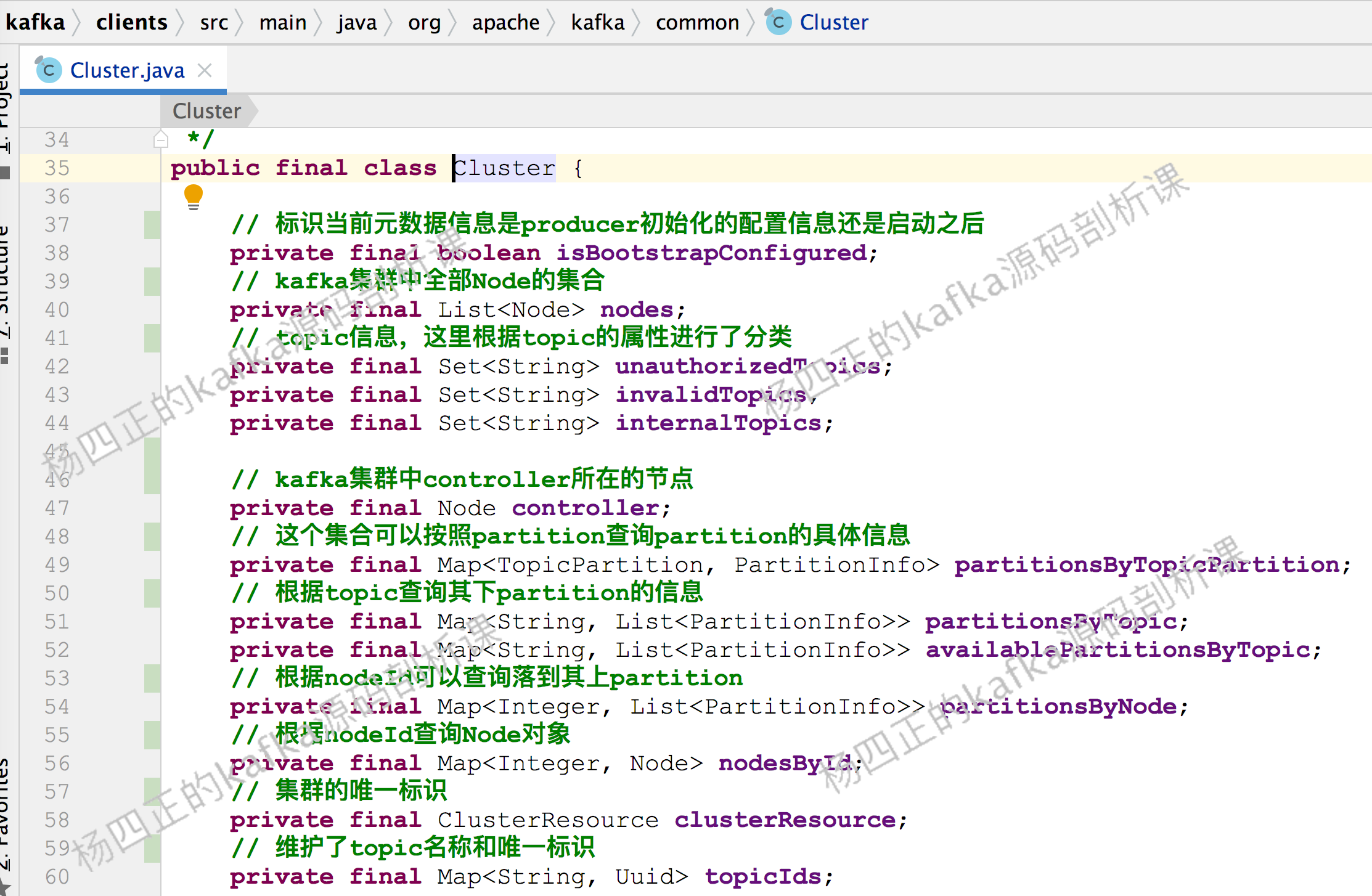
Further up, the Cluster object will be maintained in metadata. Metadata also maintains the version number, expiration time, listener and other information of the Cluster, as shown in the following figure:

After the above analysis, we can get the following diagram:
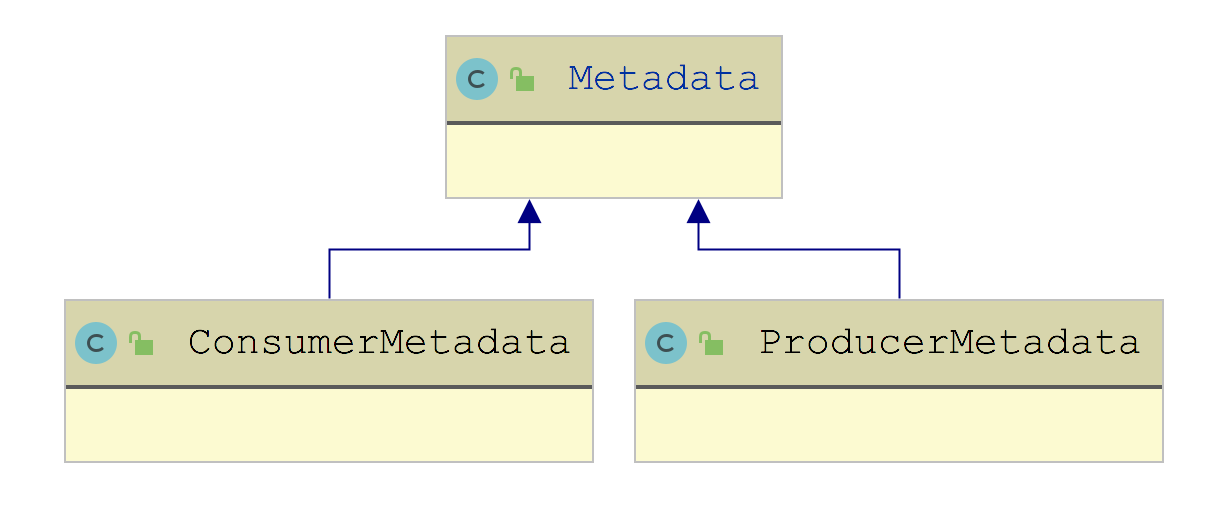
After static data structure analysis, let's look at Kafka producer How the waitonmetadata() method works:
private ClusterAndWaitTime waitOnMetadata(String topic, Integer partition, long nowMs, long maxWaitMs) throws InterruptedException {
// Gets the Cluster object currently cached by MetadataCache
Cluster cluster = metadata.fetch();
if (cluster.invalidTopics().contains(topic))
throw new InvalidTopicException(topic);
// Update the cache of producer metadata
metadata.add(topic, nowMs);
// Get the number of partitions of the target topic from the partitionsByTopic collection
Integer partitionsCount = cluster.partitionCountForTopic(topic);
// If there is no metadata of the target topic, the ClusterAndWaitTime object will be returned directly without the following update operation
if (partitionsCount != null && (partition == null || partition < partitionsCount))
return new ClusterAndWaitTime(cluster, 0);
long remainingWaitMs = maxWaitMs;
long elapsed = 0;
do {
// Update producer metadata cache
metadata.add(topic, nowMs + elapsed);
// Update get the current updateVersion and set the corresponding ID to trigger metadata update as soon as possible
int version = metadata.requestUpdateForTopic(topic);
// Wake up the Sender thread, and the Sender thread completes the metadata update
sender.wakeup();
try {
// Blocking waits for metadata update. The condition to stop blocking is that the updated updateVersion is greater than the current version. If it times out, an exception will be thrown directly
metadata.awaitUpdate(version, remainingWaitMs);
} catch (TimeoutException ex) {
throw new TimeoutException(. . . );
}
cluster = metadata.fetch(); // Get the latest Cluster
elapsed = time.milliseconds() - nowMs;
if (elapsed >= maxWaitMs) {
throw new TimeoutException(partitionsCount == null ?
String.format("Topic %s not present in metadata after %d ms.",
topic, maxWaitMs) :
String.format("Partition %d of topic %s with partition count %d is not present in metadata after %d ms.",
partition, topic, partitionsCount, maxWaitMs));
}
metadata.maybeThrowExceptionForTopic(topic);
remainingWaitMs = maxWaitMs - elapsed; // Calculation metadata update time
partitionsCount = cluster.partitionCountForTopic(topic); // Get partition number
} while (partitionsCount == null || (partition != null && partition >= partitionsCount));
return new ClusterAndWaitTime(cluster, elapsed);
}
Here, we will analyze in detail how to update metadata when introducing the workflow of Sender thread.
Serializer
The communication between nodes in distributed system inevitably involves the conversion between memory object and byte stream, that is, serialization and deserialization.
The Serializer interface in kafka is Serializer, which is responsible for converting objects into byte arrays; Deserializer is the deserializer interface, which is responsible for converting byte arrays into objects in memory.
The following shows the implementation classes of Serializer and Deserializer interfaces:


From the above figure, we can see that kafka comes with the Serializer and Deserializer implementations of common Java types. Of course, we can also customize the Serializer and Deserializer implementations to deal with complex types.
Let's take the implementation of StringSerializer as an example to illustrate the core implementation of Serializer:
- The configure() method is the configuration before the serialization operation, for example, in stringserializer The appropriate encoding type will be selected in the configure() method. The default is UTF-8
- The serializer() method is the real place for serialization, serializing the incoming Java object into byte [].
partition selection
After the waitOnMetadata() method obtains the latest cluster metadata, we will start to determine which partition the message to be sent to.
If we explicitly specify the target partition, the one specified by the user shall prevail. However, generally, the business does not specify which partition the message needs to be written to. At this time, a target partition will be calculated through the Partitioner combined with the cluster metadata.
The following figure shows all the implementations of the Partitioner interface:
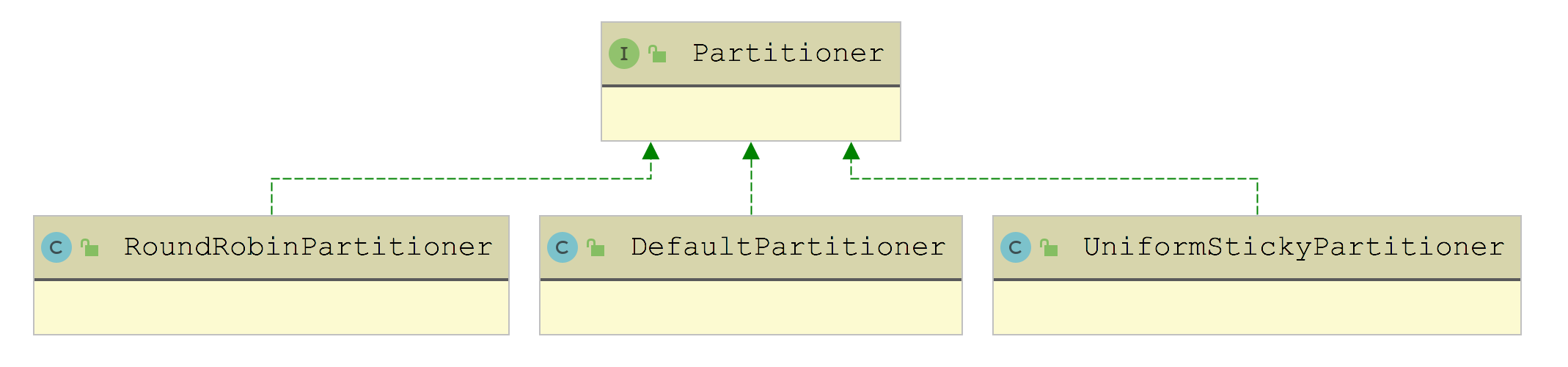
It can also be seen from the name that DefaultPartitioner is the default implementation. In the partition() method:
- If there is a key in the message, take the Hash value of the key (using murmur2, a Hash algorithm with high efficiency and low collision), and then take the module with the total number of partitions to obtain the target partition number, which can ensure that the message of the same key enters the same partition.
- If the message does not have a key, use stickypartitioncache The partition () method calculates the target partition.
Here we explain the function of stickypartition cache. When we introduced the whole KafkaProducer process earlier, we said that the RecordAccumulator is a buffer. The messages sent by the main thread will enter the RecordAccumulator first, and then the Sender thread will send them in batches when it has saved enough messages.
There are two main conditions that trigger the Sender thread to send bulk message s:
- The delay time of message is up, that is to say, our business scenario requires a delay in message sending, and message cannot be cached on the producer side all the time. We can use linker MS configuration reduces the sending delay of message.
- Messages accumulate enough to reach a certain threshold before they are suitable for batch sending, so the payload is high. Batch sent in batch The default value of size is 16KB.
StickyPartitionCache mainly implements "sticky selection", which is to send messages to a partition as soon as possible, so that the buffer sent to the partition can be filled quickly. In this way, the message sending delay can be reduced. We don't have to worry about the imbalance of partition data, because as long as the business runs long enough, messages will be sent to each partition evenly.
Let's look at the implementation of StickyPartitionCache, in which a ConcurrentMap(indexCache field) is maintained. key is topic and value is which partition is currently stuck.
In the partition() method, StickyPartitionCache will first get the stuck partition from the indexCache field. If not, it will call the nextPartition() method to write one to the indexCache. In the nextPartition() method, it will first obtain the available partitions in the target topic and randomly select one to write to the indexCache.
Finally, students may ask, when to update the stuck partition? Let's take a look at Kafka producer In the dosend() method, there is a fragment:
// Try appending a message to the RecordAccumulator
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);
// Because the current batch of the target partition has no space, you need to replace a partition and try again
if (result.abortForNewBatch) {
int prevPartition = partition;
// Replacing the target partition will also replace the partition stuck by the StickyPartitionCache
partitioner.onNewBatch(record.topic(), cluster, prevPartition);
// Calculate new target partition
partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
// Call the append() method again to write a message to the RecordAccumulator. If there is no space for batch in the partition buffer,
// Then a new batch will be created and will not be tried again
result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, false, nowMs);
}
RecordAccumulator. The append () method will be analyzed later.
The underlying layer of UniformStickyPartitioner also relies on StickyPartitionCache to realize sticky sending, which will not be introduced.
Let's look at the implementation of RoundRobinPartitioner. It can also be seen from the name that it calculates the target partition according to the rotation training strategy. It also maintains a ConcurrentMap set (topicCounterMap field), in which the key is the name of topic and the value is an increasing AtomicInteger.
At roundrobin partitioner In the partition () method, you will first find the total number of partitions of the target topic, then increase the above AtomicInteger value and take a module with the total number of partitions to get the number of the target partition.
summary
In this class, we first introduced the basic use of KafkaProducer, then introduced the core architecture of KafkaProducer, and finally introduced KafkaProducer The core operation of the main thread in the send () method.
In the next lesson, we will begin to introduce the contents related to the RecordAccumulator in Kafka producer.
The article and video explanation in this class will also be placed in:
-
The official account of WeChat:

-
Station B search: Yang Sizheng