1 Introduction to Flink programming
1.1 initialize Flink project template
1.1.1 preparations
Maven 3.0.4 and above and JDK 8 are required
1.1.2 using maven command to create java project template
- Execute the maven command. If the maven local warehouse does not have dependent jar s, it needs to have a network
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-java -DarchetypeVersion=1.12.0 -DgroupId=cn._51doit.flink -DartifactId=flink-java -Dversion=1.0 -Dpackage=cn._51doit.flink -DinteractiveMode=false

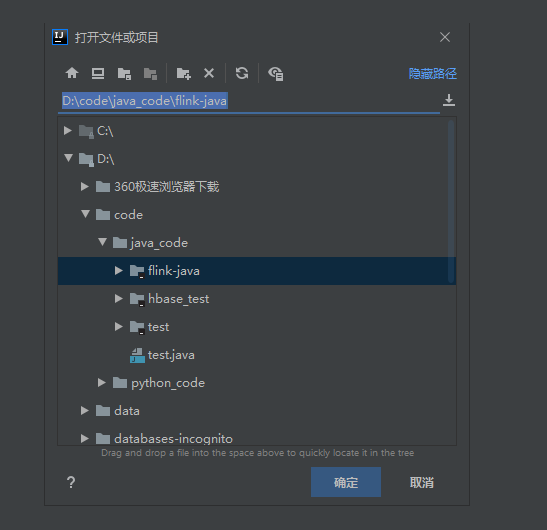
After the command is executed, the project appears in D:\code\java_code
- Or execute the following commands on the command line. You need a network
curl https://flink.apache.org/q/quickstart.sh | bash -s 1.12.0
1.1.3 create scala project template with maven command
- Execute the maven command. If the maven local warehouse does not have dependent jar s, it needs to have a network
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-scala -DarchetypeVersion=1.12.0 -DgroupId=cn._51doit.flink -DartifactId=flink-scala -Dversion=1.0 -Dpackage=cn._51doit.flink -DinteractiveMode=false

- Or execute the following command on the command line
curl https://flink.apache.org/q/quickstart-scala.sh | bash -s 1.12.0
1.1.4 import maven project into IDEA or Eclipse

1.2 DataFlow programming model
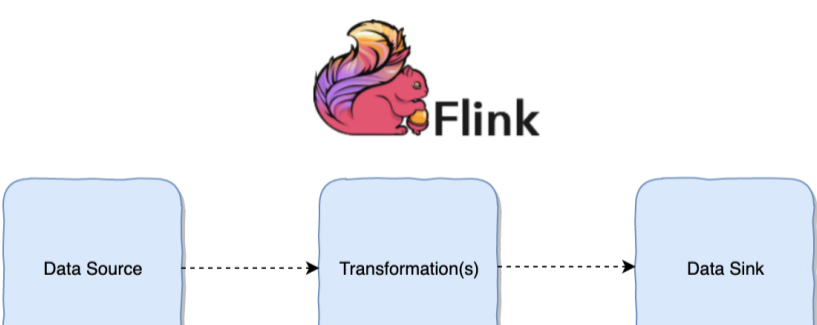
Flink provides different levels of programming abstraction. By calling the abstract data set and calling the operator to build DataFlow, we can realize the streaming calculation and offline calculation of distributed data,
DataSet is an abstract data set of batch processing, and DataStream is an abstract data set of streaming computing. Their methods are Source, Transformation and Sink respectively;
- Source is mainly responsible for reading data
- Transformation is mainly responsible for data conversion
- Sink is responsible for the final calculated result data output.
1.3 Flink's first entry program
1.3.1 real time WordCount
Read data from a socket port in real time, and then count the number of occurrences of the same word in real time. The program will run all the time. Before starting the program, use nc -lk 8888 to start a socket to send data
package cn._51doit.flink;package cn._51doit.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* Read data from the specified socket and calculate the word
*
*/
public class StreamingWordCount {
public static void main(String[] args) throws Exception {
//Create an execution environment for Flink streaming computing
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//Create DataStream
//Source
DataStream<String> lines = env.socketTextStream("cs-28-86",8888);
//Call Transformation to start
//Call Transformation
SingleOutputStreamOperator<String> wordsDataStream = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> collector) throws Exception {
String[] words = line.split(" ");
for (String word : words) {
collector.collect(word);
}
}
});
//Combine words with 1
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = wordsDataStream.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
return Tuple2.of(word, 1);
}
});
//grouping
KeyedStream<Tuple2<String, Integer>, String> keyed = wordAndOne.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> tp) throws Exception {
return tp.f0;
}
});
//polymerization
SingleOutputStreamOperator<Tuple2<String, Integer>> summed = keyed.sum(1);
//End of Transformation
//Call Sinnk
summed.print();
//Start execution
env.execute("StreamingWordCount");
}
}
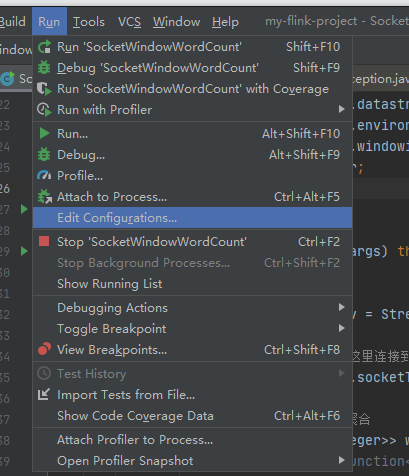
Execute the Flink program written by yourself in IntelliJ IDEA and report an error caused by: Java lang.ClassNotFoundException: org. apache. flink. api. common. functions. FlatMapFunction
terms of settlement:

Local operation results:

The previous 4 2 1 is equivalent to Slots, which is represented as the logical core of the CPU in the local computer

1.3.2 LambdaWordCount
package cn._51doit.flink; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.LocalStreamEnvironment; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; import java.util.Arrays; /** * Lambda Write WordCount */ public class LambdaStreamingWordCount { public static void main(String[] args) throws Exception { //Localstreaminenvironment can only run in local mode and is usually used for local testing LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(8); DataStreamSource<String> lines = env.socketTextStream("cs-28-86", 8888); //Lambda expressions using java8 SingleOutputStreamOperator<String> words = lines.flatMap((String line, Collector<String> out) -> Arrays.stream(line.split(" ")).forEach(out::collect)).returns(Types.STRING); //When using Lambda expressions, return information must be returned SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = words.map(w -> Tuple2.of(w, 1)).returns(Types.TUPLE(Types.STRING, Types.INT)); SingleOutputStreamOperator<Tuple2<String, Integer>> summed = wordAndOne.keyBy(0).sum(1); //Printout summed.print(); //Throw exception env.execute(); } }
1.3.2 scala WordCount
Add scala plug-in to IDEA:
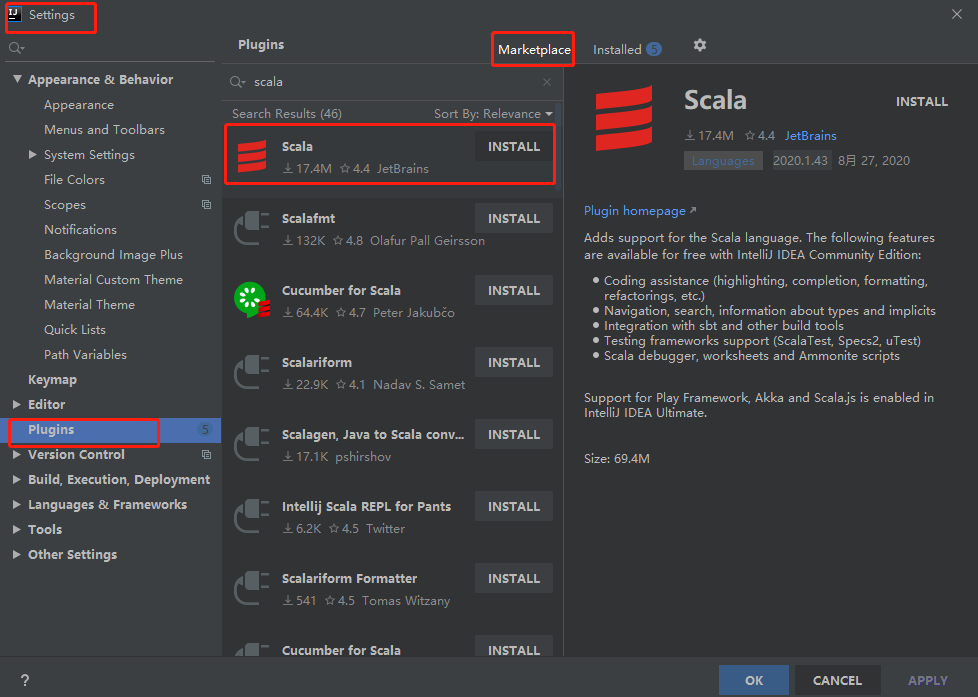
Then restart IDEA;
Add the corresponding SDK and click OK:

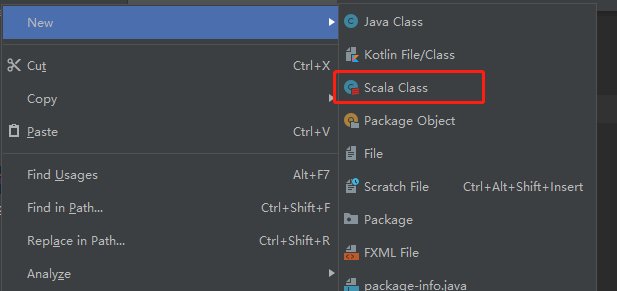
----------------
package cn._51doit.flink import org.apache.flink.streaming.api.scala._ object StreamingWordCount { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment val lines: DataStream[String] = env.socketTextStream("cs-28-86", port = 8888) val wordAndOne: DataStream[(String, Int)] = lines.flatMap(_.split(" ")).map((_, 1)) val result = wordAndOne.keyBy(_._1).sum(position = 1) result.print() env.execute() } }
1.3.3 submit to run in the cluster
Change the host name and port to receive parameters:
package cn._51doit.flink; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.LocalStreamEnvironment; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; import java.util.Arrays; /** * Lambda Write WordCount */ public class LambdaStreamingWordCount { public static void main(String[] args) throws Exception { //LocalStreamEnvironment Only in local Mode operation, usually used for local testing //LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(8); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> lines = env.socketTextStream(args[0], Integer.parseInt(args[1])); //use java8 of Lambda expression SingleOutputStreamOperator<String> words = lines.flatMap((String line, Collector<String> out) -> Arrays.stream(line.split(" ")).forEach(out::collect)).returns(Types.STRING); //use Lambda Expression, with return Return information SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = words.map(w -> Tuple2.of(w, 1)).returns(Types.TUPLE(Types.STRING, Types.INT)); SingleOutputStreamOperator<Tuple2<String, Integer>> summed = wordAndOne.keyBy(0).sum(1); //Printout summed.print(); //Throw exception env.execute(); } }
Packaging procedure;
- Upload jar to web
Start an nc first:

Submit:
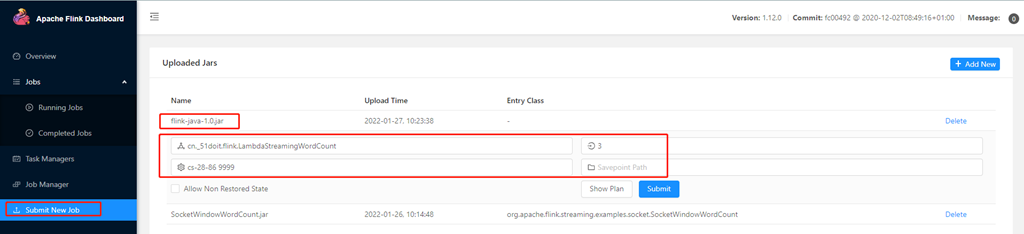
Execution result:

