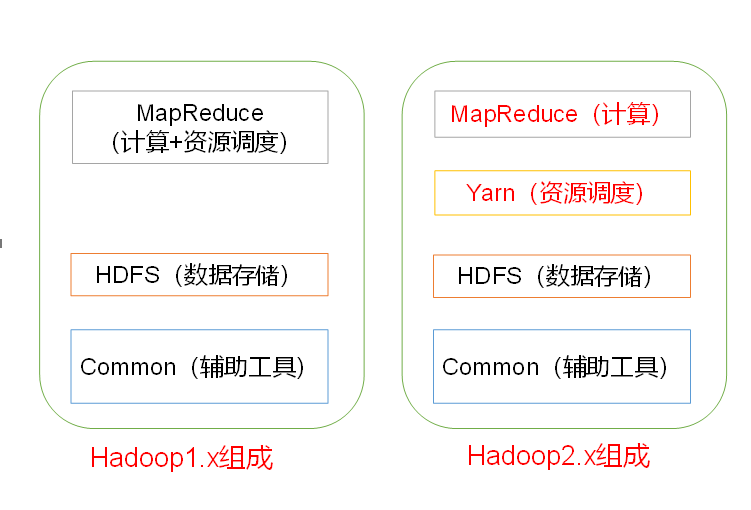
Hadoop composition
HDFS Architecture Overview
- NameNode(nn): stores the metadata of the file, such as file name, file directory structure, file attributes, block list of each file, DataNode where the block is located, etc
- DataNode(dn): stores file block data and the checksum of block data in the local file system
- Secondary NameNode(2nn): backup the metadata of NameNode at regular intervals
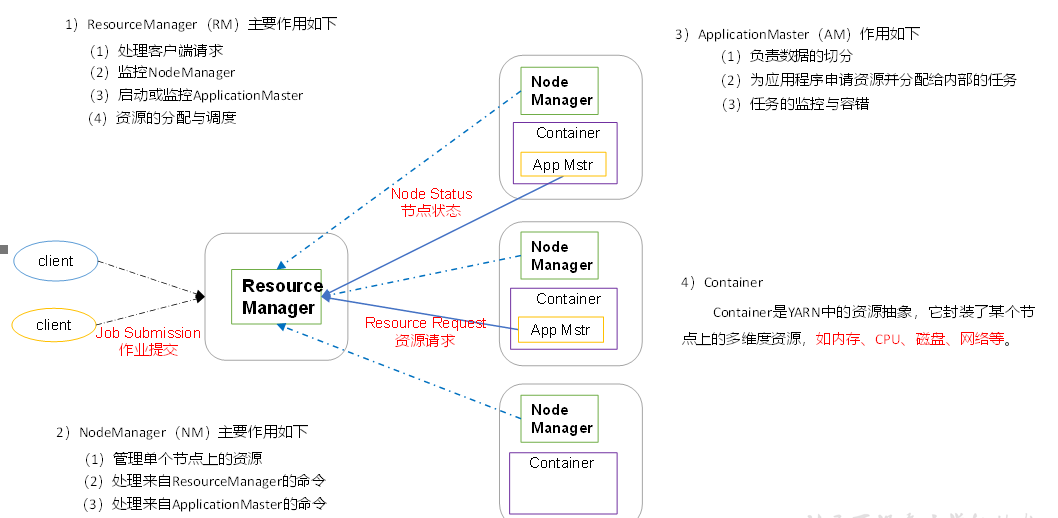
Overview of Yarn architecture
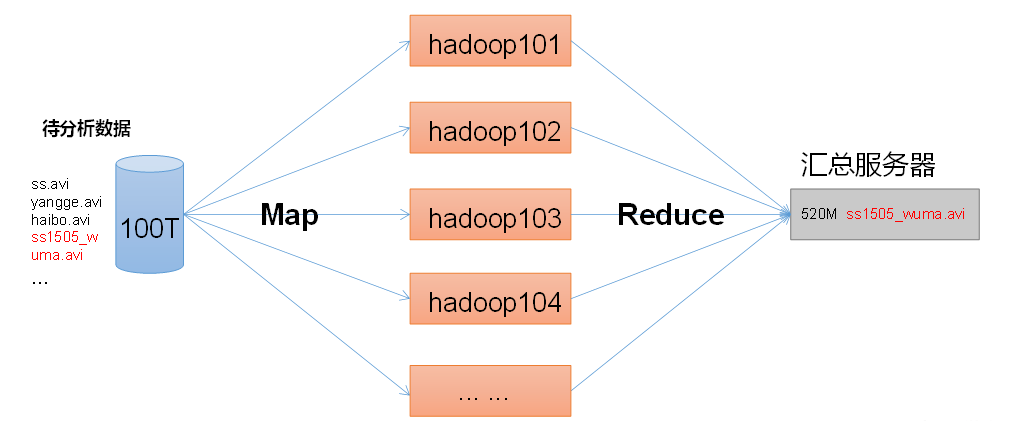
MapReduce Architecture Overview
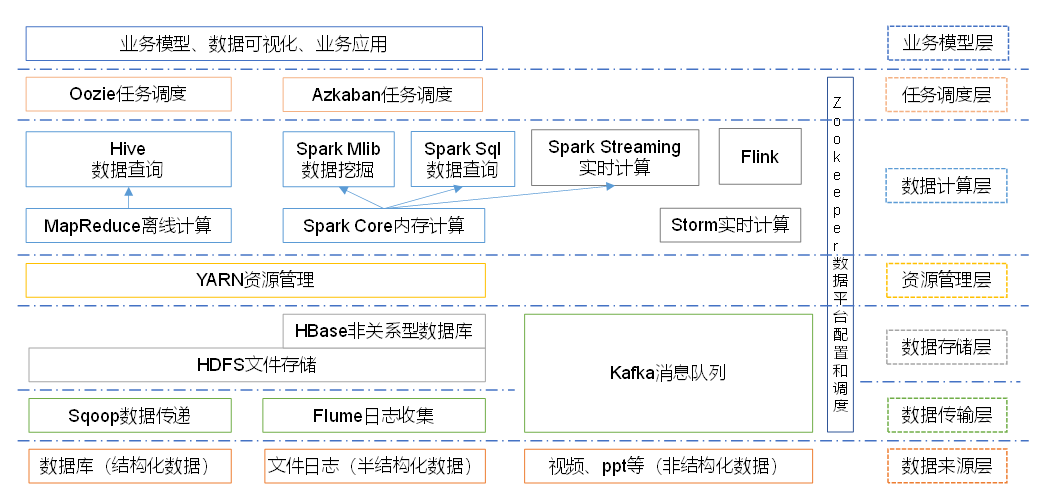
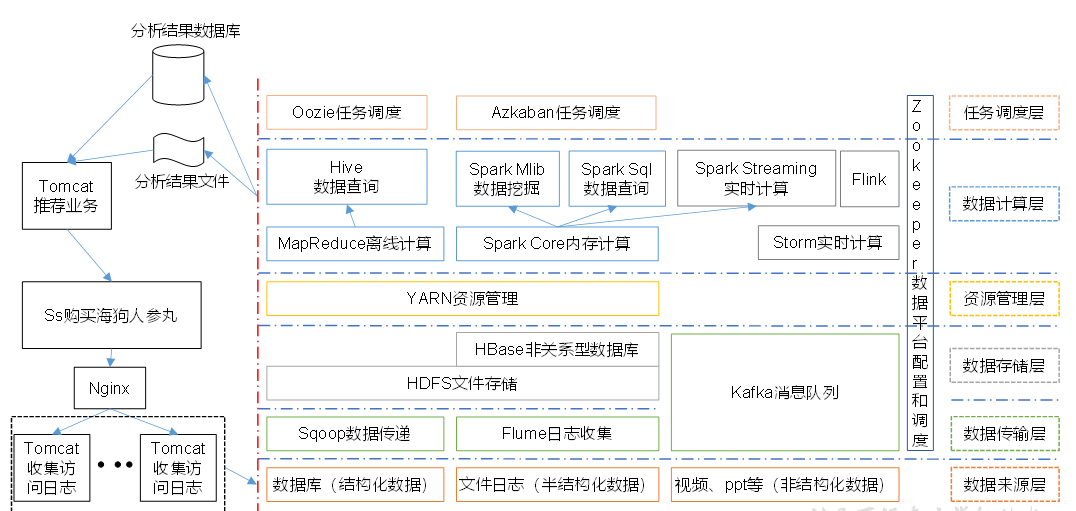
Big data ecosystem
Recommended system framework
Prepare template virtual machine (Centos7, 4G memory, 50G hard disk)
Installation environment
yum install -y epel-release yum install -y psmisc nc net-tools rsync vim lrzsz ntp libzstd openssl-static tree iotop git
Turn off the firewall. Turn off the firewall and start it automatically
systemctl stop firewalld systemctl disable firewalld
Create an ordinary user and change the password
useradd lixuan passwd lixuan
Configure that the lixuan user has root privileges
vim /etc/sudoers
## Allow root to run any commands anywhere root ALL=(ALL) ALL lixuan ALL=(ALL) NOPASSWD:ALL
Create a file in the / opt directory and modify the owner and owner
mkdir /opt/module mkdir /opt/software
chown lixuan:lixuan /opt/module chown lixuan:lixuan /opt/software
Uninstall the openJDK that comes with the virtual machine
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
Restart the virtual machine
reboot
Clone virtual machine node01
Modify the static IP of the clone machine (all three must be changed)
vim /etc/sysconfig/network-scripts/ifcfg-ens33
DEVICE=ens33 TYPE=Ethernet ONBOOT=yes BOOTPROTO=static NAME="ens33" IPADDR=192.168.50.100 PREFIX=24 GATEWAY=192.168.50.2 DNS1=192.168.50.2
View virtual network editor
Modify clone hostname
vim /etc/hostname
Configure host file
vim /etc/hosts
192.168.50.100 node01 192.168.50.110 node02 192.168.50.120 node03 192.168.50.130 node04
restart
Modify the hosts file of windows host
Install JDK
ls /opt/software/ hadoop-3.1.3.tar.gz jdk-8u212-linux-x64.tar.gz
Unzip JDK
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
Configure JDK environment variables
sudo vim /etc/profile.d/my_env.sh
#JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
Install hadoop
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
Add Hadoop to environment variable
sudo vim /etc/profile.d/my_env.sh
#HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
source /etc/profile
Write cluster distribution script xsync
scp
scp -r $pdir/$fname $user@$host:$pdir/$fname Command recursion File path to copy/name Target user@host:Destination path/name
scp -r /opt/module/jdk1.8.0_212 lixuan@node02:/opt/module
scp -r lixuan@node01:/opt/module/* lixuan@node03:/opt/module
rsync
-
It is mainly used for backup and mirroring. It has the advantages of high speed, avoiding copying the same content and supporting symbolic links
rsync -av $pdir/$fname $user@$host:$pdir/$fname The command option parameter is the path of the file to be copied/name Target user@host:Destination path/name
rsync -av /opt/software/* lixuan@node02:/opt/software
Write xsync
cd /home/lixuan mkdir bin cd bin vim xsync
#!/bin/bash
#1. Number of judgment parameters
if [ $# -lt 1 ]
then
echo Input Path You Need Give Others
exit;
fi
#2. Traverse all machines in the cluster
for host in node01 node02 node03 node04
do
echo ==================== $host ====================
#3. Traverse all directories and send them one by one
for file in $@
do
#4. Judge whether the document exists
if [ -e $file ]
then
#5. Get parent directory
pdir=$(cd -P $(dirname $file); pwd)
#6. Get the name of the current file
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
chmod +x xsync
SSH password free login configuration
ssh-keygen -t rsa #Then hit three returns
ssh-copy-id node02 ssh-copy-id node03
- The other two machines have to perform the same operation
Cluster deployment planning
| node01 | node02 | node03 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
Configure cluster
core-site.xml
cd $HADOOP_HOME/etc/hadoop vim core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- appoint NameNode Address of -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9820</value>
</property>
<!-- appoint hadoop Storage directory of data -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- to configure HDFS The static user used for web page login is lixuan -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>lixuan</value>
</property>
<!-- Configure this lixuan(superUser)Host nodes that are allowed to be accessed through proxy -->
<property>
<name>hadoop.proxyuser.lixuan.hosts</name>
<value>*</value>
</property>
<!-- Configure this lixuan(superUser)Allow groups to which users belong through proxy -->
<property>
<name>hadoop.proxyuser.lixuan.groups</name>
<value>*</value>
</property>
<!-- Configure this lixuan(superUser)Allow users through proxy-->
<property>
<name>hadoop.proxyuser.lixuan.groups</name>
<value>*</value>
</property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web End access address-->
<property>
<name>dfs.namenode.http-address</name>
<value>node01:9870</value>
</property>
<!-- 2nn web End access address-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node03:9868</value>
</property>
</configuration>
yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- appoint MR go shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- appoint ResourceManager Address of-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node02</value>
</property>
<!-- Inheritance of environment variables -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn Maximum and minimum memory allowed to be allocated by the container -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn The amount of physical memory the container allows to manage -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- close yarn Limit check on physical memory and virtual memory -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
Configure log aggregation
-
At yarn site Add the following configuration to XML
<!-- Enable log aggregation --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- Set log aggregation server address --> <property> <name>yarn.log.server.url</name> <value>http://node01:19888/jobhistory/logs</value> </property> <!-- Set the log retention time to 7 days --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>
mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- appoint MapReduce The program runs on Yarn upper -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Configure history server
-
At mapred site Add the following configuration to XML
<!-- Historical server address --> <property> <name>mapreduce.jobhistory.address</name> <value>node01:10020</value> </property> <!-- History server web End address --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node01:19888</value> </property>
Distribution profile
xsync /opt/module/hadoop-3.1.3/etc/hadoop/
Configure workers
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
#Add the following contents. There shall be no spaces at the end and no blank lines in the file node01 node02 node03
#Synchronize all node profiles xsync /opt/module/hadoop-3.1.3/etc
Group together
First start
-
If it is the first time to start, you need to format the NameNode in node01 node
hdfs namenode -format
-
If you want to format after running, delete the data and logs directories of all machines before formatting
Start of node01 history server
mapred --daemon start historyserver
jps
Write jpsall script
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps $@ | grep -v Jps
done
chmod +x jpsall
Write the cluster startup and shutdown script myhadoop sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "In Put start/stop"
exit ;
fi
case $1 in
"start")
echo " =================== start-up hadoop colony ==================="
echo " --------------- start-up hdfs ---------------"
ssh node01 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- start-up yarn ---------------"
ssh node02 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- start-up historyserver ---------------"
ssh node01 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== close hadoop colony ==================="
echo " --------------- close historyserver ---------------"
ssh node01 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- close yarn ---------------"
ssh node02 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- close hdfs ---------------"
ssh node01 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac