Compression parameter configuration
- To enable compression in Hadoop, you can use mapred site Configure the following parameters in XML
| Default value | stage | parameter | proposal |
|---|---|---|---|
| org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.Lz4Codec | Input compression | io.compression.codecs (configured in core-site.xml) | Hadoop uses file extensions to determine whether a codec is supported |
| false | mapper output | mapreduce.map.output.compress | Set this parameter to true to enable compression |
| org.apache.hadoop.io.compress.DefaultCodec | mapper output | mapreduce.map.output.compress.codec | Use LZO, LZ4, or snappy codecs to compress data at this stage |
| false | reducer output | mapreduce.output.fileoutputformat.compress | Set this parameter to true to enable compression |
| org.apache.hadoop.io.compress. DefaultCodec | reducer output | mapreduce.output.fileoutputformat.compress.codec | Use standard tools or codecs, such as gzip and bzip2 |
| RECORD | reducer output | mapreduce.output.fileoutputformat.compress.type | The compression type used for SequenceFile output: NONE and BLOCK |
Map output stage compression
- Turning on map output compression can reduce the amount of data transfer between map and Reduce Task in the job
Case practice
# Enable hive intermediate transmission data compression function set hive.exec.compress.intermediate=true; # Enable the map output compression function in mapreduce set mapreduce.map.output.compress=true; # Set the compression method of map output data in mapreduce set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec; # Execute query statement select count(ename) name from emp;
Reduce output stage compression
# Enable hive final output data compression function set hive.exec.compress.output=true; # Enable mapreduce final output data compression set mapreduce.output.fileoutputformat.compress=true; # Set the compression mode of mapreduce final data output set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec; # Set mapreduce final data output compression to block compression set mapreduce.output.fileoutputformat.compress.type=BLOCK; # Test whether the output is a compressed file insert overwrite local directory '/opt/module/hive/datas/distribute-result' select * from emp distribute by deptno sort by empno desc;
File storage format
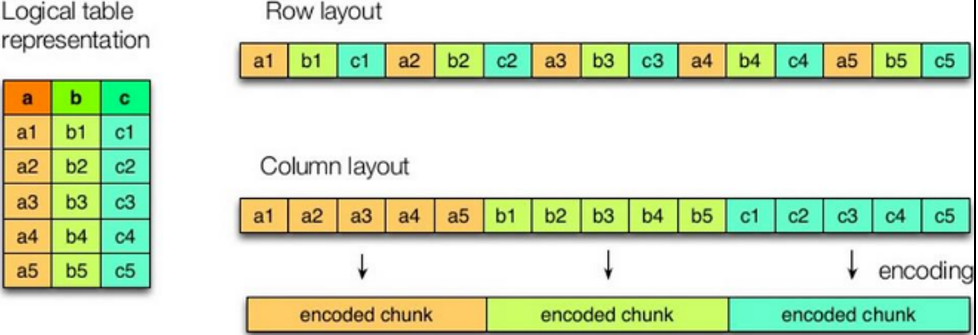
Column storage and row storage
characteristic
- Row storage: faster queries
- Column storage: better compression algorithms can be designed
- textfile and sequencefile are based on row storage
- orc and parquet are based on columnar storage
Orc format
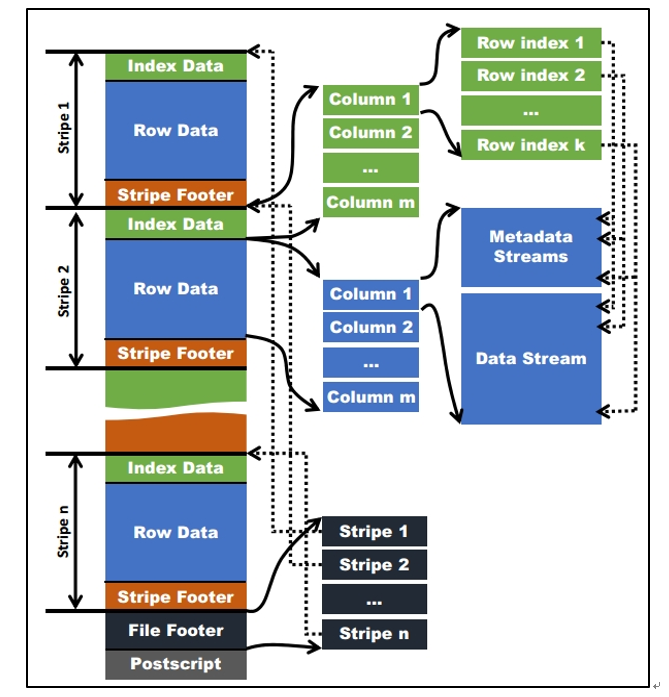
Parquet format
- It is stored in binary mode and cannot be read directly
- The file includes the data and metadata of the file, so the Parquet format file is self parsing
Combination of storage and compression
- In the actual project development, the data storage format of Hive table generally selects orc or parquet
- Generally, the compression mode is snappy, lzo
Explain
explain select * from emp;
Fetch grab
- The query of some cases in Hive can be calculated without MapReduce
- For example, select * from employees
- In this case, Hive can simply read the files in the storage directory corresponding to the employee, and then output the query results to the console
Case practice
# Put hive fetch. task. Set conversion to none, and the following queries will go through mapreduce # Set it to more and you won't go mapreduce set hive.fetch.task.conversion=more; select * from emp; select ename from emp; select ename from emp limit 3;
Local mode
# Turn on local mr set hive.exec.mode.local.auto=true; # Set the maximum input data amount of local mr. when the input data amount is less than this value, the mode of local mr is adopted. The default is 134217728, i.e. 128M set hive.exec.mode.local.auto.inputbytes.max=50000000; # Set the maximum number of input files of local mr. when the number of input files is less than this value, the mode of local mr is adopted, and the default is 4 set hive.exec.mode.local.auto.input.files.max=10;
Small table large table Join(MapJoin)
# Set automatic selection of Mapjoin set hive.auto.convert.join = true; Default to true # Threshold setting of large table and small table (it is considered as small table below 25M by default) set hive.mapjoin.smalltable.filesize = 25000000;
MapJoin working mechanism
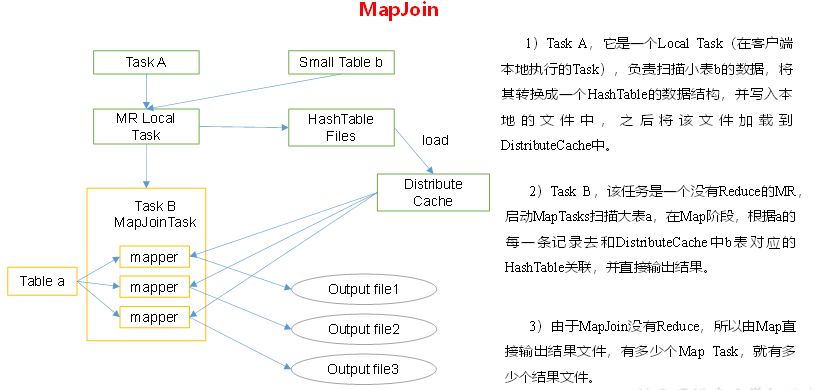
Big table Join big table
Empty key filtering
- Sometimes the join timeout is due to too much data corresponding to some key s
- The same key will be sent to the same reducer, resulting in insufficient memory
- In many cases, the data corresponding to these key s is abnormal data
- We need to filter in SQL statements. For example, the field corresponding to key is empty
Empty key conversion
- Sometimes, although a key is empty, there are many corresponding data, but the corresponding data is not abnormal data
- At this time, we can assign a random value to the field with empty key to make the data randomly and evenly distributed to different reducer s
Group by
- By default, the same key data in the Map phase is distributed to a reduce. When a key data is too large, it will be tilted
- Partial aggregation can be carried out on the Map side, and finally the final result can be obtained on the Reduce side
# Whether to aggregate on the Map side. The default value is True set hive.map.aggr = true # Number of entries for aggregation at the Map side set hive.groupby.mapaggr.checkinterval = 100000 # Load balancing when there is data skew (false by default) set hive.groupby.skewindata = true
Count(Distinct) de duplication statistics
- In case of large amount of data, the count distinct operation needs to be completed with a reduce task
- The amount of data that needs to be processed by this reduce is too large, which will make the whole job difficult to complete
- Generally, count distinct is replaced by group by count
Reasonably set the number of maps and Reduce
Is it true that the more map s, the better?
- The answer is No
- If a task has many small files, each small file will also be treated as a block and completed with a map task
- The start-up and initialization time of a map task is much longer than the logical processing time, which will cause a great waste of resources
- Moreover, the number of map s that can be executed at the same time is limited
Is it safe to ensure that each map can process files close to 128M quickly?
- The answer is not necessarily
- For example, a 127M file is normally completed with a map
- But this file has only one or two small fields, but there are tens of millions of records
- If the logic of map processing is complex, it will be time-consuming to do it with a map task
- At this point, the number of map s should be increased
Merge small files
# Merge small files before map execution to reduce the number of maps set hive.input.format= org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; # Merge small files at the end of the map only task. The default is true SET hive.merge.mapfiles = true; # Merge small files at the end of the map reduce task. The default is false SET hive.merge.mapredfiles = true; # The size of the merged file is 256M by default SET hive.merge.size.per.task = 268435456; # When the average size of the output file is less than this value, start an independent map reduce task to merge the file SET hive.merge.smallfiles.avgsize = 16777216;
Reasonably set the number of Reduce
# Mode 1 # The amount of data processed by each Reduce is 256MB by default hive.exec.reducers.bytes.per.reducer=256000000 # The maximum number of reduce per task is 1009 by default hive.exec.reducers.max=1009 # Formula for calculating reducer number N=min(Total data input 2/Parameter 1) # Mode 2 # mapred-default.xm set mapreduce.job.reduces = 15;
The number of reduce is not the more the better
- Too much startup and initialization of reduce will consume time and resources
- There will be as many small files as there are reduce files. If these small files are used as the input of the next task, there will be too many small files
Parallel execution
# Open task parallel execution set hive.exec.parallel=true; # The maximum parallelism allowed for the same sql is 8 by default set hive.exec.parallel.thread.number=16;
Strict mode
- Hive can prevent some dangerous operations by setting
Partitioned tables do not use partition filtering
# For partitioned tables, unless the where statement contains partition field filter conditions to limit the scope, it is not allowed to execute hive.strict.checks.no.partition.filter=true;
order by has no limit filter
# For queries that use the order by statement, it is required to use the limit statement hive.strict.checks.orderby.no.limit=true;
Cartesian product
# Queries that restrict Cartesian product hive.strict.checks.cartesian.product=true