1. Module Introduction
Pycurl (http://pycurl.sourceforge.net) is a libcurl Python implementation written in C language. It has very powerful functions. The supporting operation protocols include FTP, HTTP, HTTPS, TELNET, etc. It can be understood as Python encapsulation of curl command function under Linux, which is simple and easy to use. By calling the method provided by pycurl, this regulation can detect the situation of Web service quality, such as HTTP status code of response, request delay, HTTP header information, download speed and so on. Using this information, we can locate the specific link of slow response of service. The following is a detailed description.
2. Description of common methods of modules
The pycurl.Curl () class implements the creation of a Curl handle object for the libcurl package with no parameters. For more information on the libcurl package, see http://curl.haxx.se/libcurl/c/libcurltutorial.html.
Here are some common methods for Curl objects.
· Close () method, corresponding to curl_easy_cleanup method in libcurl package, has no parameters to close and recycle Curl objects.
· perform () method, corresponding to curl_easy_perform ance method in libcurl package, without parameters, implements the submission of Curl object request. ·
The setopt (option, value) method corresponds to the curl_easy_setopt method in the libcurl package. The parameter option is specified by the constant of the libcurl. The value of the parameter value depends on the option, which can be a string, integer, long integer, file object, list or function. Following is a list of commonly used constants:
c = pycurl.Curl() #Create a curl object c.setopt(pycurl.CONNECTTIMEOUT, 5) #Connection wait time, set to 0, no wait c.setopt(pycurl.TIMEOUT, 5) #Request timeout c.setopt(pycurl.NOPROGRESS, 0) #Whether to shield download progress bar, non-zero shield c.setopt(pycurl.MAXREDIRS, 5) #Appoint HTTP Maximum number of redirections c.setopt(pycurl.FORBID_REUSE, 1) #Force disconnection after completing interaction, no reuse c.setopt(pycurl.FRESH_CONNECT,1) #Force the acquisition of a new connection, that is, to replace the connection in the cache c.setopt(pycurl.DNS_CACHE_TIMEOUT,60) #Set up and save DNS Information time, default 120 seconds c.setopt(pycurl.URL,"http: //www.baidu.com") #Designated request URL c.setopt(pycurl.USERAGENT,"Mozilla/5.2 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50324)") #Configuration request HTTP Head User-Agent c.setopt(pycurl.HEADERFUNCTION, getheader) #Will return HTTP HEADER Direction to callback function getheader c.setopt(pycurl.WRITEFUNCTION, getbody) #Directing the returned content to the callback function getbody c.setopt(pycurl.WRITEHEADER, fileobj) #Will return HTTP HEADER Directed to fileobj File object c.setopt(pycurl.WRITEDATA, fileobj) #Will return HTML Content directed to fileobj File object
· The getinfo (option) method corresponds to the curl_easy_getinfo method in the libcurl package, and the parameter option is specified by the constant of libcurl. Following is a list of commonly used constants:
c = pycurl.Curl() #Create a curl object c.getinfo(pycurl.HTTP_CODE) #Returned HTTP Status code c.getinfo(pycurl.TOTAL_TIME) #Total time consumed by end of transmission c.getinfo(pycurl.NAMELOOKUP_TIME) #DNS Analyzing the time consumed c.getinfo(pycurl.CONNECT_TIME) #Time consumed to establish connections c.getinfo(pycurl.PRETRANSFER_TIME) #Time consumed from establishing a connection to preparing for transmission c.getinfo(pycurl.STARTTRANSFER_TIME) #Time consumed from the start of establishing a connection to the transmission c.getinfo(pycurl.REDIRECT_TIME) #Time consumed by redirection c.getinfo(pycurl.SIZE_UPLOAD) #Upload Packet Size c.getinfo(pycurl.SIZE_DOWNLOAD) #Download Packet Size c.getinfo(pycurl.SPEED_DOWNLOAD) #Average download speed c.getinfo(pycurl.SPEED_UPLOAD) #Average upload speed c.getinfo(pycurl.HEADER_SIZE) #HTTP Head size
We use these constants provided by the libcurl package to detect the quality of Web services.
3. Practice: Implementing Detected Web Service Quality
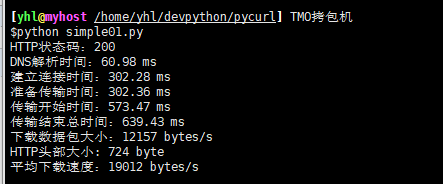
HTTP service is one of the most popular Internet applications. The quality of service is related to the user experience and the level of operation and service of the website. There are two most commonly used standards: one is the availability of services, such as whether they are in the normal service state, rather than whether 404 pages are not found or 500 pages are wrong; the other is the response speed of services, such as static class file download. They are controlled in milliseconds and dynamic CGI is in seconds. This example uses pycurl's setopt and getinfo methods to detect HTTP quality of service, acquire HTTP status codes returned from monitoring URLs, HTTP status codes are obtained by pycurl.HTTP_CODE constants, and the response time of each link from HTTP request to download is achieved by pycurl.NAMELOOKUP_TIME, curl. CONNECT_TIME, pycurl.PRETRANSFER_TIME, pycurl.R and other constants. . In addition, the HTTP response header and page content of the target URL are obtained by pycurl.WRITEHEADER and pycurl.WRITEDATA constants. The source code is as follows:
[/home/test/pycurl/simple1.py]
#_*_coding:utf-8_*_ #****************************************************************# # ScriptName: simple01.py # Author: BenjaminYang # Create Date: 2019-06-02 01:37 # Modify Author: BenjaminYang # Modify Date: 2019-06-02 01:37 # Function: #***************************************************************# #!/usr/bin/python import os,sys import time import pycurl URL="http://www.google.com.hk" #Targets to be detected URL c=pycurl.Curl() #Create a Curl object c.setopt(pycurl.URL,URL) #Defining the request URL constant c.setopt(pycurl.CONNECTTIMEOUT,5) #Define the waiting time for a request connection c.setopt(pycurl.TIMEOUT,5) #Define request timeout c.setopt(pycurl.NOPROGRESS,1) #Shield download progress bar c.setopt(pycurl.FORBID_REUSE,1) #Force disconnection after completing interaction, no reuse c.setopt(pycurl.MAXREDIRS,1) #Appoint HTTP The maximum number of redirections is 1 c.setopt(pycurl.DNS_CACHE_TIMEOUT,30) #Set up and save DNS Information takes 30 seconds #Create a file object to wb"Mode open to store returned http Header and page content indexfile=open(os.path.dirname(os.path.realpath(__file__))+"/content.txt","wb") c.setopt(pycurl.WRITEDATA,indexfile) #Will return HTML Content directed to indexfile File object try: c.perform() #Submit request except Exception,e: print "connection error:"+str(e) indexfile.close() c.close() sys.exit() NAMELOOKUP_TIME=c.getinfo(c.NAMELOOKUP_TIME) #Obtain DNS Analytical time CONNECT_TIME=c.getinfo(c.CONNECT_TIME) #Get the connection setup time PRETRANSFER_TIME=c.getinfo(c.PRETRANSFER_TIME) #Gets the time consumed from establishing a connection to prepare for transmission STARTTRANSFER_TIME = c.getinfo(c.STARTTRANSFER_TIME) #Gets the time consumed from the start of establishing a connection to the transmission TOTAL_TIME=c.getinfo(c.TOTAL_TIME) #Get the total time of transmission HTTP_CODE=c.getinfo(c.HTTP_CODE) #Obtain HTTP Status code SIZE_DOWNLOAD=c.getinfo(c.SIZE_DOWNLOAD) #Get the download packet size HEADER_SIZE=c.getinfo(c.HEADER_SIZE) #Obtain HTTP Head size SPEED_DOWNLOAD=c.getinfo(c.SPEED_DOWNLOAD) #Get Average Download Speed #Print out relevant data print "HTTP Status code:%s" %(HTTP_CODE) print "DNS Resolution time:%.2f ms" %(NAMELOOKUP_TIME*1000) print "Connection time:%.2f ms" %(CONNECT_TIME*1000) print "Prepare transmission time:%.2f ms" %(PRETRANSFER_TIME*1000) print "Transmission start time:%.2f ms" %(STARTTRANSFER_TIME*1000) print "Total transmission end time:%.2f ms" %(TOTAL_TIME*1000) print "Download Packet Size:%d bytes/s" %(SIZE_DOWNLOAD) print "HTTP Head size: %d byte" %(HEADER_SIZE) print "Average download speed:%d bytes/s" %(SPEED_DOWNLOAD) #Close files and Curl object indexfile.close() c.close()