(Statement: This article aims at exchanging technology. I hope you will support the original version and the courtyard line)
Demand Background:
Recently, I mistakenly entered a free (daoban) resource sharing group (decent face), which brushes resource links every day. But as we all know, Baidu cloud sharing links are very easy to be river crabs, in addition to sharing links, is a variety of complaints "how failed", "river crabs...". In line with the initial intention of learning technology, I began to study how to automatically crawl the messages of Weixin Group and automatically transfer them to my cloud disk.
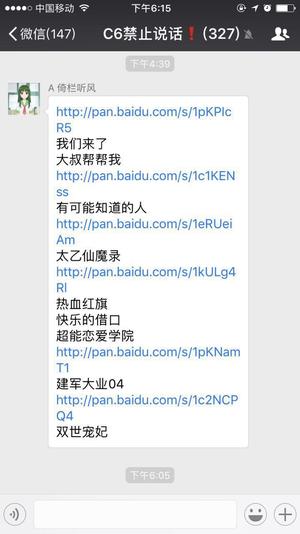
Demand:
1. Climbing Baidu Cloud Sharing Links in Weixin Group
2. Transfer resources to your own websites
Involve:
1. Regular expressions
2. How to analyze cookie s and APIs
3,selenium(webdriver)
Catalogue of this article:
1. Crawl the Web Disk Resources in the Wechat Group Chat Information
2. Searching for and Analyzing Baidu Cloud's Transfer api
3. Crawl shareid, from, filelist and send requests to the disk
4. Complete code
5. Reference
Climbing the Disk Resources of Wechat Group Chat Information
To crawl the group chat information of Wechat, we can use the webpage version of Wechat's api. Here we recommend a highly encapsulated, simple tool: wxpy: Playing Wechat with Python

It's a good tool to implement all the functions of Wechat on the web page. Previously, bloggers used it to realize the chat function of robots, and their personal accounts transformed Microsoft Xiaobing gorgeously. Although Microsoft hasn't released Xiaobing's api yet, we can fully use this tool's forwarding function to achieve, the idea is simple. We adopt Xiaobing on Wechat, forward what others say to Xiaobing, and then forward Xiaobing's words back.

In short, with this tool, we can monitor the information in the group chat of Wechat, and then use regular expressions to grab out the link of the network disk. I will not post the specific code, it is very simple to use. Detailed usage can be referred to in the github project Description document.
Looking for and Analyzing Baidu Cloud's Transfer api
This part is our focus. First, you have to have an account of Baidu Cloud Disk, then log in and open a shared link with a browser (demonstrated here with Firefox). F12 opens the console to grab the package. Manual dump operation: full file - > save to the disk - > select the path - > determine. Before clicking on the "OK" button, it is suggested to clear the record of grabbing bags first, so as to accurately locate the transferred api, which is what we learned in middle school [Control Variable Method] 2333.
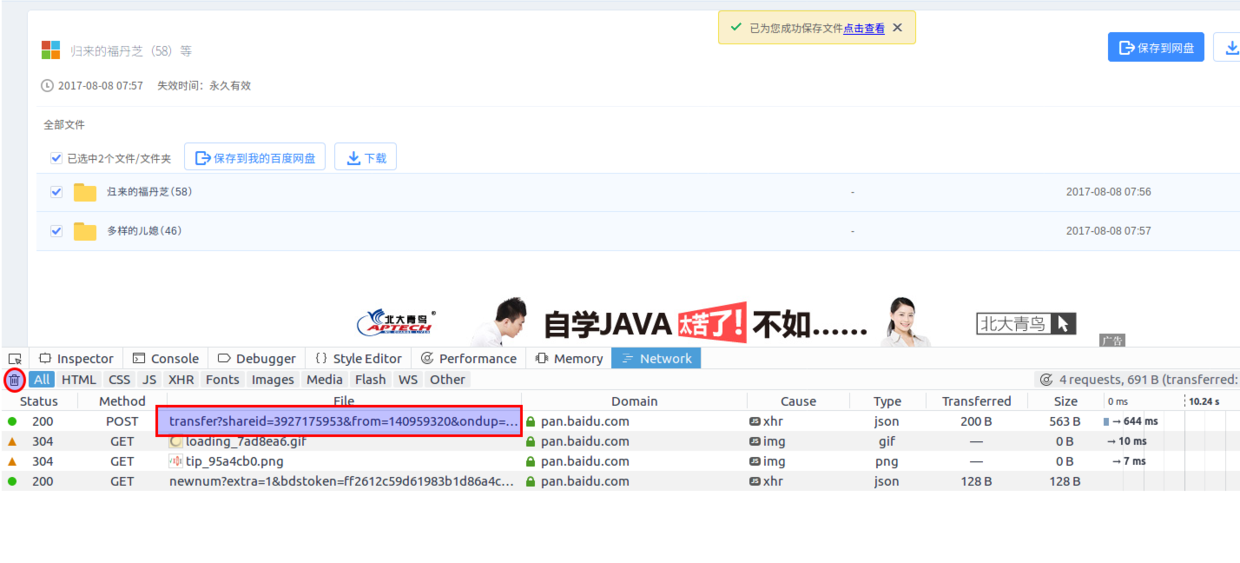
You can see in the figure above that a post request with the word "transfer" is caught, which is the transfer api we are looking for. The next key is to analyze its request header and request parameters for code simulation.
https://pan.baidu.com/share/transfer?shareid=3927175953&from=140959320&ondup=newcopy&async=1&bdstoken=xxx&channel=chunlei&clienttype=0&web=1&app_id=250528&logid=xxx
Click on it and then click on Cookies on the right to see the cookie s in the request header.
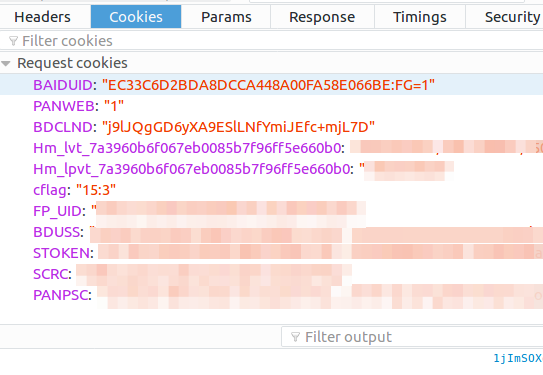
cookie analysis:
Because dump is a post-login operation, it is necessary to simulate the login status and set the cookies related to login in the request header. We continue to use the method of controlling variables. First, we delete all cookies about Baidu in the browser (in the upper right corner settings, click Privacy) to remove cookies. Practice Baidu by yourself.
Then login, enter the browser settings in the upper right corner - > Privacy - > Remove cookies, search for "bai" to observe cookies. This is all the cookies related to Baidu, delete one by one, delete a page that refreshes Baidu once, until the deletion of BDUSS, after the refresh logs out, so it comes to the conclusion that it is a cookie related to the login status.
Similarly, after deleting STOKEN, a dump operation will prompt the re-login. So these are the cookie s that must be brought with the dump operation.
Knowing the cookie situation, you can construct the request header as follows.
def __init__(self,bduss,stoken,bdstoken): self.bdstoken = bdstoken self.headers = { 'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.8', 'Connection': 'keep-alive', 'Content-Length': '161', 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 'Cookie': 'BDUSS=%s;STOKEN=%s;' % (bduss, stoken), 'Host': 'pan.baidu.com', 'Origin': 'https://pan.baidu.com', 'Referer': 'https://pan.baidu.com/s/1dFKSuRn?errno=0&errmsg=Auth%20Login%20Sucess&&bduss=&ssnerror=0', 'User-Agent': self.pro.get_user_agent(),# As a strategy to deal with anti-crawler mechanism, this is a random method of extracting user_agent written by bloggers. You can also go online to collect some and write a random method by yourself. 'X-Requested-With': 'XMLHttpRequest', }
In addition to the two cookies mentioned above, other request header parameters can refer to the request header that grabs packets when manually dumped. The reason why these two cookies are reserved for parameters is that cookies have a life cycle, need to be updated when they are out of date, and different cookies exist for different account logins.
Parametric analysis:
Next, analyze the parameters and click on Params on the right of Cookies to see the parameters. As follows:
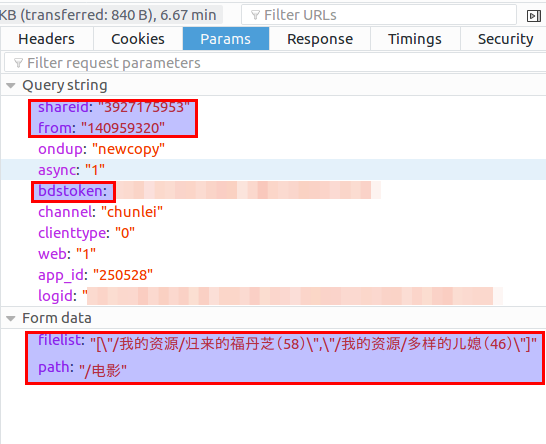
The query string above (that is? In the following parameters), except for the box shareid, from and bdstoken, which need us to fill in, all of them can be unchanged and copied directly when simulating the request.
The first two are related to shared resources, and the bdstoken is related to the logged-in account. The following two parameters in form data are the directory where the resource is on the shared user's disk and the directory we just clicked to save the specified directory.
Therefore, we need to fill in additional parameters: shareid, from, bdstoken, filelist and path. bdstoken can be found by manually transferring the grab package. path can be defined according to your needs, provided that there is this path in your webdisk. The other three need to be crawled from the shared link, which will be explained later in the section "Crawling shareid, from, filelist, sending requests to the disk".
Having figured out the parameters, we can construct the url of the dump request as follows.
def transfer(self,share_id,uk,filelist_str,path_t_save):# The parameters to be filled in correspond to the shareid, from, filelist and path of the figure above, respectively. # General parameters ondup = "newcopy" async = "1" channel = "chunlei" clienttype = "0" web = "1" app_id = "250528" logid = "Your logid" url_trans = "https://pan.baidu.com/share/transfer?shareid=%s" \ "&from=%s" \ "&ondup=%s" \ "&async=%s" \ "&bdstoken=%s" \ "&channel=%s" \ "&clienttype=%s" \ "&web=%s" \ "&app_id=%s" \ "&logid=%s" % (share_id, uk, ondup, async, self.bdstoken, channel, clienttype, web, app_id, logid) form_data = { 'filelist': filelist_str, 'path': path_t_save, } proxies = {'http': self.pro.get_ip(0, 30, u'domestic')}# In response to the anti-crawler mechanism, proxy is used here, which will be explained later. response = requests.post(url_trans, data=form_data, proxies = proxies,headers=self.headers) print response.content jsob = json.loads(response.content) if "errno" in jsob: return jsob["errno"] else: return None
Crawl shareid, from, filelist and send requests to the disk
https://pan.baidu.com/s/1jImSOXg
Take this resource link as an example (it may be crab at any time, but it doesn't matter, the structure of other links is the same). Let's first use the browser to access it manually. F12 opens the console and first analyses the source code to see where we want the resource information. The console has a search function to search "shareid" directly.
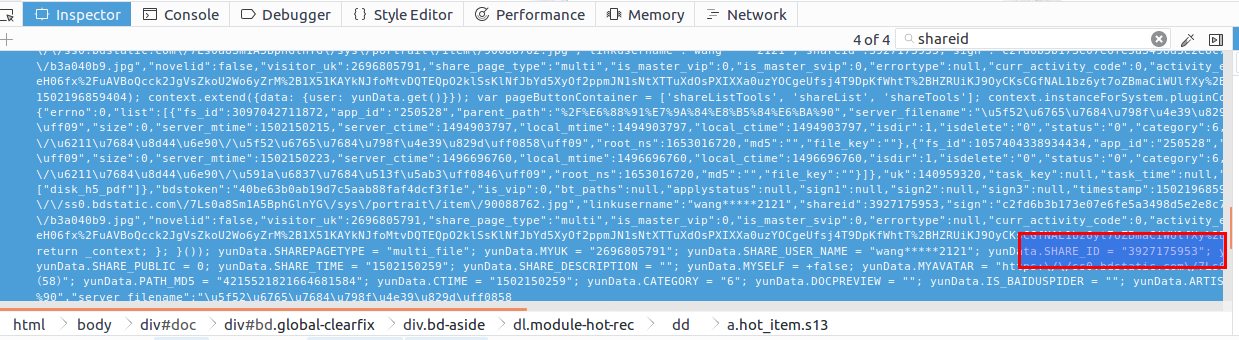
Locate to four shareid s, the first three unrelated to the resource are other shared resources, and the last one is located in the last < script ></script > tag block of the html file. After double-clicking, you can see the formatted js code, and you can see that all the information we want is in it. The following excerpts:
yunData.SHAREPAGETYPE = "multi_file"; yunData.MYUK = ""; yunData.SHARE_USER_NAME = "wang*****2121"; yunData.SHARE_ID = "3927175953"; yunData.SIGN = "7f166e9b5cf54486074ccce2fc0548e8aa50bdfb"; yunData.sign = "7f166e9b5cf54486074ccce2fc0548e8aa50bdfb"; yunData.TIMESTAMP = "1502175170"; yunData.SHARE_UK = "140959320"; yunData.SHARE_PUBLIC = 0; yunData.SHARE_TIME = "1502150259"; yunData.SHARE_DESCRIPTION = ""; yunData.MYSELF = +false; yunData.MYAVATAR = ""; yunData.NOVELID = ""; yunData.FS_ID = "3097042711872"; yunData.FILENAME = "Return of Fudanzhi (58)"; yunData.PATH = "\/My resources\/Return of Fudanzhi (58)"; yunData.PATH_MD5 = "4215521821664681584"; yunData.CTIME = "1502150259"; yunData.CATEGORY = "6"; yunData.DOCPREVIEW = ""; yunData.IS_BAIDUSPIDER = ""; yunData.ARTISTNAME = ""; yunData.ALBUMTITLE = ""; yunData.TRACKTITLE = ""; yunData.FILEINFO = [{"fs_id":3097042711872,"app_id":"250528","parent_path":"%2F%E6%88%91%E7%9A%84%E8%B5%84%E6%BA%90","server_filename":"Return of Fudanzhi (58)","size":0,"server_mtime":1502150215,"server_ctime":1494903797,"local_mtime":1494903797,"local_ctime":1494903797,"isdir":1,"isdelete":"0","status":"0","category":6,"share":"0","path_md5":"4215521821664681584","delete_fs_id":"0","extent_int3":"0","extent_tinyint1":"0","extent_tinyint2":"0","extent_tinyint3":"0","extent_tinyint4":"0","path":"\/My resources\/Return of Fudanzhi (58)","root_ns":1653016720,"md5":"","file_key":""},{"fs_id":1057404338934434,"app_id":"250528","parent_path":"%2F%E6%88%91%E7%9A%84%E8%B5%84%E6%BA%90","server_filename":"Diversified Daughters-in-law (46)","size":0,"server_mtime":1502150223,"server_ctime":1496696760,"local_mtime":1496696760,"local_ctime":1496696760,"isdir":1,"isdelete":"0","status":"0","category":6,"share":"0","path_md5":"5972282562760833248","delete_fs_id":"0","extent_int3":"0","extent_tinyint1":"0","extent_tinyint2":"0","extent_tinyint3":"0","extent_tinyint4":"0","path":"\/My resources\/Diversified Daughters-in-law (46)","root_ns":1653016720,"md5":"","file_key":""}];
You can see these two lines.
yunData.SHARE_ID = "3927175953"; yunData.SHARE_UK = "140959320"; // By contrast, that's what we want from.
yunData.PATH only points to one path information. A complete filelist can be extracted from yunData.FILEINFO. It is a json. The information in the list is Unicode coded, so you can't see Chinese in the console. You can access it with Python code and get the output.
Direct request requests will yield 404 errors, which may require the construction of request header parameters, not direct requests. In order to save time, bloggers here directly use selenium's webdriver to get twice, and receive the return information. The first get doesn't have any cookie s, but baidu will return you a BAIDUID, which will be accessed normally in the second get.
The structure of yunData.FILEINFO is as follows. You can copy and paste it to json.cn Here, you can see more clearly.
[{"fs_id":3097042711872,"app_id":"250528","parent_path":"%2F%E6%88%91%E7%9A%84%E8%B5%84%E6%BA%90","server_filename":"Return of Fudanzhi (58)","size":0,"server_mtime":1502150215,"server_ctime":1494903797,"local_mtime":1494903797,"local_ctime":1494903797,"isdir":1,"isdelete":"0","status":"0","category":6,"share":"0","path_md5":"4215521821664681584","delete_fs_id":"0","extent_int3":"0","extent_tinyint1":"0","extent_tinyint2":"0","extent_tinyint3":"0","extent_tinyint4":"0","path":"\/My resources\/Return of Fudanzhi (58)","root_ns":1653016720,"md5":"","file_key":""},{"fs_id":1057404338934434,"app_id":"250528","parent_path":"%2F%E6%88%91%E7%9A%84%E8%B5%84%E6%BA%90","server_filename":"Diversified Daughters-in-law (46)","size":0,"server_mtime":1502150223,"server_ctime":1496696760,"local_mtime":1496696760,"local_ctime":1496696760,"isdir":1,"isdelete":"0","status":"0","category":6,"share":"0","path_md5":"5972282562760833248","delete_fs_id":"0","extent_int3":"0","extent_tinyint1":"0","extent_tinyint2":"0","extent_tinyint3":"0","extent_tinyint4":"0","path":"\/My resources\/Diversified Daughters-in-law (46)","root_ns":1653016720,"md5":"","file_key":""}]
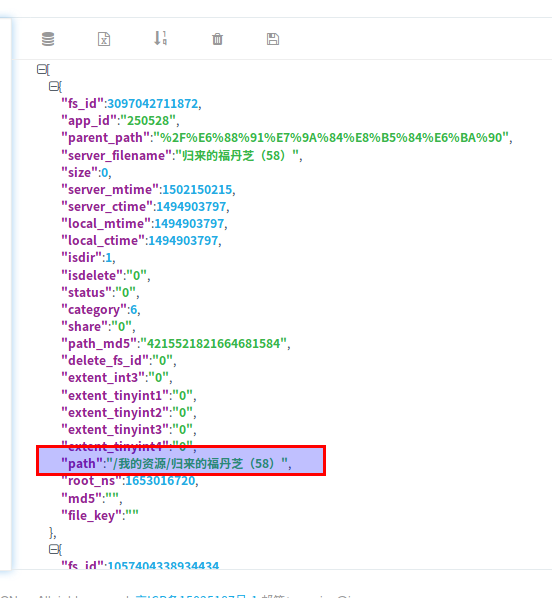
With the location of these three parameters clear, we can use regular expressions to extract them. The code is as follows:
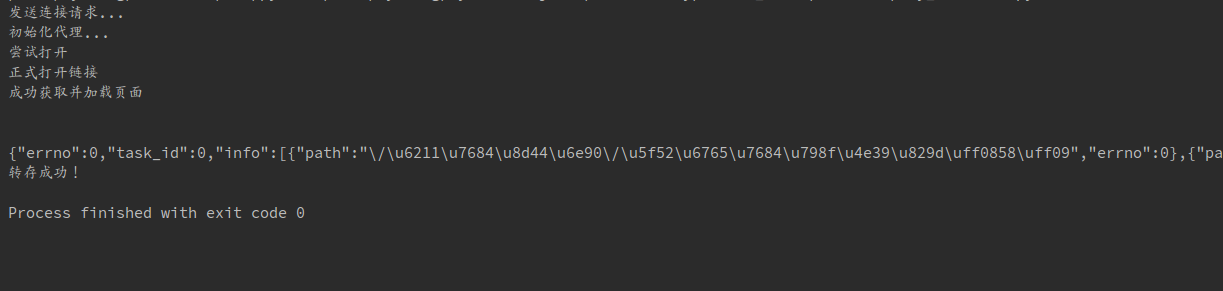
from wechat_robot.business import proxy_mine # This is my own proxy class. I can use native ip first when testing. pro = proxy_mine.Proxy() url = "https://pan.baidu.com/s/1jImSOXg" driver = webdriver.Chrome() print u"Initialization agent..." driver = pro.give_proxy_driver(driver) def get_file_info(url): driver.get(url) time.sleep(1) driver.get(url) script_list = driver.find_elements_by_xpath("//body/script") innerHTML = script_list[-1].get_attribute("innerHTML")# Get innerHTML for the last script pattern = 'yunData.SHARE_ID = "(.*?)"[\s\S]*yunData.SHARE_UK = "(.*?)"[\s\S]*yunData.FILEINFO = (.*?);[\s\S]*' # [ s S]* can match all characters including newlines, s for spaces, S for non-space characters srch_ob = re.search(pattern, innerHTML) share_id = srch_ob.group(1) share_uk = srch_ob.group(2) file_info_jsls = json.loads(srch_ob.group(3))# Parsing json path_list = [] for file_info in file_info_jsls: path_list.append(file_info['path']) return share_id,share_uk,path_list try: print u"Send connection request..." share_id,share_uk,path_list = get_file_info(url) except: print u"The link failed and was not retrieved fileinfo..." else: print share_id print share_uk print path_list
With these three parameters crawled, you can call the previous transfer method for dump.
Complete code
# -*- coding:utf-8 -*- import requests import json import time import re from selenium import webdriver from wechat_robot.business import proxy_mine class BaiduYunTransfer: headers = None bdstoken = None pro = proxy_mine.Proxy() def __init__(self,bduss,stoken,bdstoken): self.bdstoken = bdstoken self.headers = { 'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.8', 'Connection': 'keep-alive', 'Content-Length': '161', 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 'Cookie': 'BDUSS=%s;STOKEN=%s;' % (bduss, stoken), 'Host': 'pan.baidu.com', 'Origin': 'https://pan.baidu.com', 'Referer': 'https://pan.baidu.com/s/1dFKSuRn?errno=0&errmsg=Auth%20Login%20Sucess&&bduss=&ssnerror=0', 'User-Agent': self.pro.get_user_agent(), 'X-Requested-With': 'XMLHttpRequest', } def transfer(self,share_id,uk,filelist_str,path_t_save): # General parameters ondup = "newcopy" async = "1" channel = "chunlei" clienttype = "0" web = "1" app_id = "250528" logid = "Your logid" url_trans = "https://pan.baidu.com/share/transfer?shareid=%s" \ "&from=%s" \ "&ondup=%s" \ "&async=%s" \ "&bdstoken=%s" \ "&channel=%s" \ "&clienttype=%s" \ "&web=%s" \ "&app_id=%s" \ "&logid=%s" % (share_id, uk, ondup, async, self.bdstoken, channel, clienttype, web, app_id, logid) form_data = { 'filelist': filelist_str, 'path': path_t_save, } proxies = {'http': self.pro.get_ip(0, 30, u'domestic')} response = requests.post(url_trans, data=form_data, proxies = proxies,headers=self.headers) print response.content jsob = json.loads(response.content) if "errno" in jsob: return jsob["errno"] else: return None def get_file_info(self,url): driver = webdriver.Chrome() print u"Initialization agent..." driver = self.pro.give_proxy_driver(driver) print u"Trying to open" driver.get(url) time.sleep(1) print u"Open the link formally" driver.get(url) print u"Successfully retrieve and load the page" script_list = driver.find_elements_by_xpath("//body/script") innerHTML = script_list[-1].get_attribute("innerHTML") pattern = 'yunData.SHARE_ID = "(.*?)"[\s\S]*yunData.SHARE_UK = "(.*?)"[\s\S]*yunData.FILEINFO = (.*?);[\s\S]*' # [ s S]* can match all characters including newlines, s for spaces, S for non-space characters srch_ob = re.search(pattern, innerHTML) share_id = srch_ob.group(1) share_uk = srch_ob.group(2) file_info_jsls = json.loads(srch_ob.group(3)) path_list_str = u'[' for file_info in file_info_jsls: path_list_str += u'"' + file_info['path'] + u'",' path_list_str = path_list_str[:-1] path_list_str += u']' return share_id, share_uk, path_list_str def transfer_url(self,url_bdy,path_t_save): try: print u"Send connection request..." share_id, share_uk, path_list = self.get_file_info(url_bdy) except: print u"The link failed and was not retrieved fileinfo..." else: error_code = self.transfer(share_id, share_uk, path_list, path_t_save) if error_code == 0: print u"Successful transfer!" else: print u"Transfer failed, error code:" + str(error_code) bduss = 'Your BDUSS' stoken = 'Your STOKEN' bdstoken = "Your bdstoken" bdy_trans = BaiduYunTransfer(bduss,stoken,bdstoken) url_src = "https://pan.baidu.com/s/1jImSOXg" path = u"/Film" bdy_trans.transfer_url(url_src,path)
The above code, if you do not need multiple requests, please ignore all involved in the use of proxy. If you need a proxy, recommend a github project: IPProxyPool
Reference resources
wxpy: Playing Wechat with Python
Python regular expressions
Use of Selenium, Python Crawler Tool 5
python implements batch Baidu cloud storage tool
IPProxyPool proxy pool