References
"The Treasure Book of Hacker Attack and Defense Technology - System Actual Warfare" 2nd Edition
Original works, typing is not easy, reprint please note
Stack buffer overflow has always been the most popular, we understand one of the most thorough security issues. Although stack buffer overflow is one of the most well-known and open vulnerabilities, there are still stack overflow problems in our software. Here we first introduce the problem of stack buffer overflow.
We hope that through stack overflow series of articles, we can have a deeper understanding of stack and avoid this problem when encoding. In addition, we can use the vulnerability of stack buffer to attack the system, which is the goal of this study.
Buffer
"Buffer": A limited, contiguous area of memory. Array is the most common buffer in C. This section mainly introduces the contents related to array.
In C language, there is no special mechanism to consider checking the internal boundaries of buffers, so stack overflow is easy to occur. Once the input data exceeds the range of buffers, so that other buffers can be rewritten, anything will happen.
Let's start with an example:
1 #include <stdio.h> 2 #include <stdlib.h> 3 4 int main() 5 { 6 int array[5] = {1, 2, 3, 4, 5}; 7 printf("%d \n", array[5]); 8 }
Because as a demonstration, here we intentionally print subscript 5, compiling and running results will get a very strange number:
32766
This example shows that when C does not provide memory protection mechanism, it is very easy to read other data across the buffer. What happens if we input more data than the buffer?
Take a chestnut:
int main() { int array[5]; int i; for (i = 0; i < 255; i++) array[i] = 10; }
Why set 255 so big? In order to achieve the effect, increase the probability of stepping on memory, because not all read and write out of memory will lead to problems, only when the out memory has valid data, the error will occur.
After running, the results are as follows:
Segmentation fault (core dumped)
Now let's understand how to overflow the buffer stored on the stack from the memory management perspective.
II. Stack
Why do we introduce stacks? What does it have to do with the above? Let's take a look at the memory layout of the following C program and then analyze it.
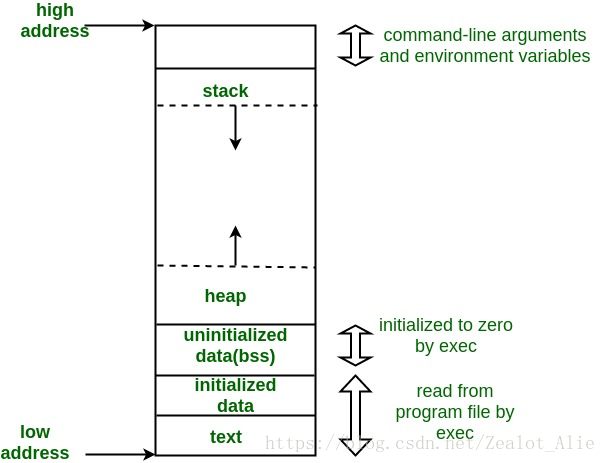
There are five districts:
Text paragraph:
- The text segment contains machine language instructions for the program in which the process runs.
- This section is read-only, so the process does not accidentally change any value through an error pointer.
- Text segments are shared, so a single copy of the program code resides in the virtual address space at one time.
Initialize data segment:
- Global variables and static variables that contain explicit initialization.
- When the program is loaded into memory, the values of these variables are read from the executable file.
Uninitialized data segments:
- Contains global and static variables that are not explicitly initialized.
- The system initializes all memory in this segment to ZERO (0).
- This segment is also called BSS (block starting with a symbol).
- There is no need to allocate space for uninitialized data, which is why they are placed in separate segments.
- This segment is allocated by Loader at runtime, so only its location and size need to be recorded.
Stack segment:
- Stack segments are dynamic growth and contraction segments containing stack frames.
- It contains program stack and LIFO structure. Register the Stack Pointer to track the top of the stack.
- Each function has a stack framework.
- Local variable parameters and return values of a frame storage function.
- They store automatic and local variables.
Reactor section:
- It stores dynamically allocated memory at runtime.
- malloc, realloc, and free are allocated dynamically in the heap area and can be adjusted by using brk and sbrk system calls
- It is shared by all shared libraries in the process and dynamically loaded modules.
So let's see that arrays should be allocated in the stack. Why don't we put them in the stack? Now let's compare the essential difference between stack and stack, and maybe we can see why.
Stack differentiation reference: https://blog.csdn.net/ChenGuiGan/article/details/84102968
Here are some examples:
1) Response of the system after application
Stack: As long as the remaining space of the stack is larger than the requested space, the system will provide memory for the program, otherwise the stack will be reported as an exception overflow.
Heap: First of all, you should know that the operating system has a linked list of free memory addresses. When the system receives an application from the program,
It traverses the list, searches for the first heap node whose space is larger than the requested space, then deletes the node from the list of idle nodes, and allocates the space of the node to the program. In addition, for most systems, it will be in this block.
The size of this allocation is recorded at the first address in the memory space, so that the delete statement in the code can release the memory space correctly. In addition, the size of the heap node found does not necessarily correspond to the size of the application.
Size, the system will automatically put the spare part back into the free list.
2) Limitation of application size
Stack: Under Windows, a stack is a data structure that extends to a low address and is a continuous area of memory. The address at the top of the stack and the maximum capacity of the stack are predetermined by the system.
In WINDOWS, the stack size is 2M (or 1M, in short, a constant determined at compile time). If the application space exceeds the remaining space of the stack, overflow will be prompted. because
Thus, the space available from the stack is small.
Heap: heap is a data structure that extends to a high address and is a discontinuous memory area. This is because the system uses linked lists to store free memory addresses, which are naturally discontinuous, and the traversal direction of linked lists is from low addresses to high addresses. The heap size is limited by the virtual memory available in the computer system. It can be seen that the heap acquires more flexible and larger space.
3) Comparisons of application efficiency:
The stack is allocated automatically by the system, which is faster. But programmers can't control it.
The heap is allocated by new memory, which is generally slow and prone to memory fragmentation, but most convenient to use.
In addition, under WINDOWS, the best way to allocate memory is to use Virtual Alloc. It is not in the heap, nor is it in the stack to keep a fast memory directly in the address space of the process, although it is the most inconvenient to use. But it's fast and flexible.
4) Storage content in stack and stack
Stack:
When a function is called, the first step is the address of the next instruction in the main function (the next executable statement in the function call statement), and then the parameters of the function. In most C compilers, the parameters are stacked from right to left, followed by local variables in the function. Note that static variables are not stacked.
When the function call is finished, the local variables go out of the stack first, and then the parameters. Finally, the top pointer of the stack points to the address at the beginning, which is the next instruction in the main function. The program continues to run from that point.
Heap: The size of the heap is usually stored in one byte at the head of the heap. The specific contents of the heap are programmer arrangements
Okay, back to the point, go on with the stack:
Why do functions use stacks at the bottom? The main purpose is to use functions more effectively. Functions can change the process of program execution. Therefore, an instruction can be executed independently, and more importantly,
After the function is executed, the control will be handed over to the caller. By using the stack, the whole calling process of the function will be more efficient.
Here's a chestnut:
1 #include <stdio.h> 2 #include <stdlib.h> 3 void function(int a, int b) 4 { 5 int array[5]; 6 } 7 void main() 8 { 9 function(1, 2); 10 printf("This is where the return address points"); 11 }
In this example, the system will first execute the instructions in main, interrupt the normal process of function call when it encounters function call, and then execute the instructions in function. The whole process is as follows:
The parameters a and B of function are stacked ==> the system call function, and the return address of the function (RET, which saves the address of the instruction pointer EIP where the calling function is) is pushed into the stack ==> the call function.
Next let's look at this example from a compilation point of view:
gcc -mpreferred-stack-boundary=2 -ggdb func.c -o func
But it was found that the report was wrong:
func.c:1:0: error: -mpreferred-stack-boundary=2 is not between 4 and 12 #include <stdio.h>
Why does intelligence value between 4 and 12? Now let's see what - mpreferred-stack-boundary does.
I found a foreign language material and posted it here for fear of inaccurate translation.
I'm trying to visualize and understand how to utilize mpreferred-stack-boundary(more like build code to exploit it for school). From reading the gcc manual, it states that it aligns the stack according to mpreferred-stack-boundary=number, where number is the exponent to base 2. By default, number=4 so the alignment of the stack is 2^4= 16 bytes. I don't know if it's the caffeine messing with my brain, but all the shell code injections I've seen in class demand that we use mpreferred-stack-boundary=2 when compiling, which would align the stack by 4 bytes. So does that mean I have that the variables placed on the stack try to fill the stack 16 bytes at a time by default? Also, why does shellcode that I place in the buffer work when the boundary when it is set to 2 yet does not work when run it in default mode?
The following is the solution:
The size of the whole stack frame will be rounded up to 16 bytes, not each individual local variable. Shellcode would work either way, but code is written for one particular layout so you need to use different shellcode for different layout. – Jester
Here we modify the alignment:
gcc -mpreferred-stack-boundary=4 -ggdb func.c -o func
It can be compiled and passed
Let's talk about why we compile this way: because we need to disassemble and debug gdb, we need to add the - ggdb option, and we should also use the optimization stack boundary option, because it will increase (or decrease) the stack in double byte units.
Otherwise, gcc will optimize the stack, which makes the analysis more complicated.
G480:huibian$ gdb func GNU gdb (Ubuntu 7.7.1-0ubuntu5~14.04.2) 7.7.1 Copyright (C) 2014 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "x86_64-linux-gnu". Type "show configuration" for configuration details. For bug reporting instructions, please see: <http://www.gnu.org/software/gdb/bugs/>. Find the GDB manual and other documentation resources online at: <http://www.gnu.org/software/gdb/documentation/>. For help, type "help". Type "apropos word" to search for commands related to "word"... Reading symbols from func...done. (gdb)
First look at how the program calls function, disassemble main:
(gdb) disassemble main
Dump of assembler code for function main:
0x0000000000400539 <+0>: push %rbp
0x000000000040053a <+1>: mov %rsp,%rbp
0x000000000040053d <+4>: mov $0x2,%esi
0x0000000000400542 <+9>: mov $0x1,%edi
0x0000000000400547 <+14>: callq 0x40052d <function>
0x000000000040054c <+19>: mov $0x4005e8,%edi
0x0000000000400551 <+24>: mov $0x0,%eax
0x0000000000400556 <+29>: callq 0x400410 <printf@plt>
0x000000000040055b <+34>: pop %rbp
0x000000000040055c <+35>: retq
End of assembler dump.
In the < main + 4 > and < main + 9 > parameters 0x10x2 are pushed into the stack one after another
Press RET (EIP) into the stack in the <main+14> callq call instruction
Later, control will be handed over to 0x40052d
Now let's look at what happens after the handover of control?
(gdb) disassemble Dump of assembler code for function function: 0x000000000040052d <+0>: push %rbp 0x000000000040052e <+1>: mov %rsp,%rbp 0x0000000000400531 <+4>: mov %edi,-0x24(%rbp) 0x0000000000400534 <+7>: mov %esi,-0x28(%rbp) => 0x0000000000400537 <+10>: pop %rbp 0x0000000000400538 <+11>: retq End of assembler dump.
As you can see, it just initializes the array and does nothing else.
About the overflow of the buffer on the stack, the next section of re-analysis and learning, unconsciously very late, get up and move bricks.