This is a simple story of data production import, the original story should be as follows: data collation - > test verification - > production release - > production verification, and then back to home, so this should be a plain story, but in fact it has become the following plot: data collation - > test verification - > production release - > production verification - > verification failure (expected data). Problem Checking - > Problem Checking - > Problem Solving - > Production Publishing - > Production Verification - > Checking Problem (Most of the data are correct, a few of the data are incorrect) > Problem Checking - > Problem Checking (the reason was not found at that time, but it can be judged that the abnormality is related to the original abnormal data of production) > Abnormal Data Delete SQL compilation - > Test Checking - > Production Verification - > Re-import Delete part of the data (excluding abnormal data directly this time, not included in the import scope) - > Lead to amend part of the abnormal data - > revise Sql preparation - > test verification - > production release - > revise data corresponding data import - > production verification!
Do you think it's over here? NO NO NO, how could the story end like this? Because this batch of data is imported into other business and needs to be carried out. After final confirmation, they can go back to each house. It turns out that the data of pit dad's database is corrected, but because the program uses Redis, the abnormal data is still in Redis, so they have to be deleted from Redis. It's good to divide the abnormal data into two parts. It's a tragic story that the program's function is not abnormal after deleting the abnormal data directly. It's only the end of this release, but it's already 0:00 a.m.
First of all, we need to introduce the imported pig foot, a pre-written stored procedure that has been released to production. In addition, the pig foot scene is MySql, and its general code is simplified as follows.
1 DROP PROCEDURE IF EXISTS `usp_SadEvent`; 2 DELIMITER $$ 3 CREATE PROCEDURE `usp_SadEvent` 4 ( 5 IN identityNo VARCHAR(20), 6 IN uName VARCHAR(15), 7 IN cAmount LONG 8 ) 9 label_at_start: 10 BEGIN 11 12 SELECT @uid := id FROM `user` 13 WHERE identity_no=identityNo AND NAME=uName; 14 15 IF @uid IS NULL THEN 16 select identityNo,uName,0 ret; 17 LEAVE label_at_start; 18 END IF; 19 update account set balance=balance+cAmount where uid=@uid; 20 select identityNo,uName,1 ret; 21 END label_at_start$$ 22 DELIMITER ;
The first is what the fuck fails to execute, and the result of calling the stored procedure is that it fails to return ret=0!!
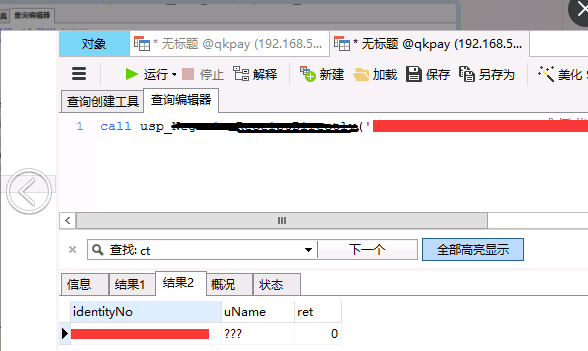
Fortunately, when writing stored procedures, considering the result query, it is easier to find why the uName returned is scrambled. When you encounter this problem, intuition is that there is a problem with database coding, as you can see.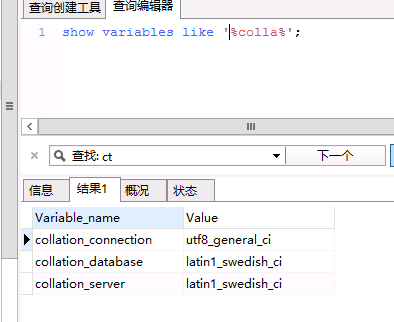
Question found out, how to fix it, the normal scenario of course is to change the default database code to utf8, but after the reorganization of Mysql must be restarted, production environment you want to restart can restart it? Well, it's good that MySQL stored procedures support specified encoding, modify stored procedures, and specify the encoding set as utf8 in uName (supplementing that although the default character set of database is latin1, the tables inside actually specify utf8 by default at the time of creation, so no default encoding set problem has been found in the production environment).
IN uName VARCHAR(15) character set utf8,
The sql that executes batch calls to stored procedures after modification is roughly as follows
call usp_SadEvent('123131231313123132','Zhang San',3000);#The database has call usp_SadEvent('123454566778899999','Li Si',5000);#The database has no Li Si, or the database is called Li Si.
Here it is specially indicated that the first database has corresponding data, the second one can not find user data in the database, and the execution results unexpectedly find that the second "Li Si" amount was added to "Zhang San". What the hell is this?
In fact, the problem lies in the default declaration parameters of mysql, just add one more sentence below the call statement above.
call usp_SadEvent('123131231313123132','Zhang San',3000);#The database has call usp_SadEvent('123454566778899999','Li Si',5000);#No database select @uid;
It's obvious that the execution results tell you that @uid is valuable, and the value is Zhang San's uid. Well, I didn't expect it to be in Mysql.
SELECT @uid := id
This implicit way of declaring parameters will be valid throughout the conversation, so it's still possible to test correctly by honestly changing to the following explicit declaration
declare u_id long; select `id` into u_id FROM `user`
The final fully modified stored procedure should be as follows
DROP PROCEDURE IF EXISTS `usp_SadEvent`; DELIMITER $$ CREATE PROCEDURE `usp_SadEvent` ( IN identityNo VARCHAR(20), IN uName VARCHAR(15) character set utf8, IN cAmount LONG ) label_at_start: BEGIN declare u_id long; select `id` into u_id FROM `user` WHERE identity_no=identityNo AND NAME=uName; IF u_id IS NULL THEN select identityNo,uName,0 ret; LEAVE label_at_start; END IF; update account set balance=balance+cAmount where uid=u_id; select identityNo,uName,1 ret; END label_at_start$$ DELIMITER ;
Well, it seems very simple to describe the problem afterwards. It's still pitfalls to actually investigate these problems. Hey...