Loving LOL, I finally got in touch with python~
This is my GitHub: Download source code

The reptile is divided into three steps:
1. Analyzing picture links
F12, click on a few heroic skins to have a look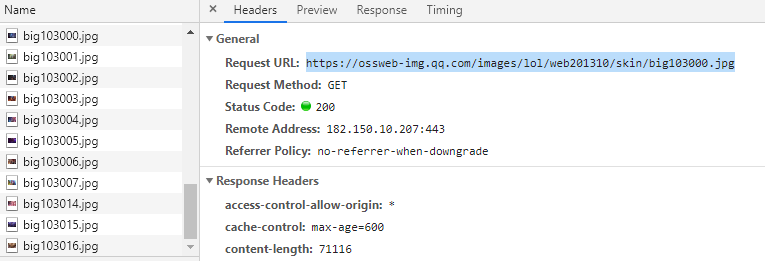
After looking at the skin information of several heroes, it's easy to find that each hero's skin links are all a model, such as https://ossweb-img.qq.com/images/lol/web201310/skin/big103000.jpg, https://ossweb-img.q.com/images/lol/web201310/skin/big266002.jpg, etc. The previous links are the same, No. Also behind Big, 103000,266002? What on earth is this?
After repeated observation, it can be concluded that the first three numbers should be the id number of each hero, and the last three numbers should be the serial number of each hero's skin picture, the first 001, the second 002 (see more heroes, you can also find that not all come in order, such as the picture above, after 007, the next becomes 014). Now we just need to get the id number of each hero to download the picture to the local place.
2. Find the hero's id information
On the Heroes List page https://lol.qq.com/data/info-heros.shtml, find the file champion.js. In its response, you can find the names and IDs of each hero stored.
Then in the program, address is analyzed, response is obtained, and regular expression is used to get such content as "266", "Aatrox", "103", "Ahri", "84", "Akali", "12", "Alistar", "32", "Amumu".
Then get a list of id and name respectively for later use.
url = 'https://lol.qq.com/biz/hero/champion.js' ret = requests.get(url).text # Regular matching of hero name and id content regex = re.compile(r'LOLherojs.champion={"keys":(.*?),"data":', re.S) hero_info = regex.search(ret).group(1) # Converting to dictionary form, it is convenient to extract corresponding attributes. hero_info = json.loads(hero_info) id_list, name_list = [], [] # Store id, list of names for id, name in hero_info.items(): id_list.append(id) name_list.append(name)
3. Write code, download pictures to local
All code:
import requests import re import json import os import threading import time class Skin(): def __init__(self): self.headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Apple" "WebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"} def get_name_id(self): '''Get the hero's name and id''' url = 'https://lol.qq.com/biz/hero/champion.js' ret = requests.get(url, headers=self.headers).text # Regular matching of hero name and id content regex = re.compile(r'LOLherojs.champion={"keys":(.*?),"data":', re.S) hero_info = regex.search(ret).group(1) # Converting to dictionary form, it is convenient to extract corresponding attributes. hero_info = json.loads(hero_info) id_list, name_list = [], [] # Store id, list of names for id, name in hero_info.items(): id_list.append(id) name_list.append(name) return id_list, name_list def get_skin_image(self, path, id, img_num): # img_num is the serial number on the url of the skin image, indicating which picture it is. '''Get Skin Pictures''' # Skin url template easy_url = 'http://ossweb-img.qq.com/images/lol/web201310/skin/big' # Download Skin Address skin_url = easy_url + id + '%03d' % img_num + '.jpg' # Forms like id002.jpg, id015.jpg image = requests.get(skin_url, headers=self.headers) if image.status_code == 200: # The included serial number indicates that the address exists before downloading. with open(path, 'wb') as f: f.write(image.content) time.sleep(1) # Take a break to avoid being blocked def download_image(self, name, id): '''Download pictures to folders''' name_dir = 'lol_hero_skins/%s' % name # Folders in the name of Heroes # This lol_hero_skins is a folder I created beforehand. You can change your code or create your own folder. if not os.path.exists(name_dir): os.mkdir(name_dir) # create folder for img_num in range(30): # Should there be no hero's skin with more than 30 numbers (not in order 001, 002, so row, some are not continuous) path = name_dir + '/%d' % img_num + '.jpg' self.get_skin_image(path, id, img_num) def run(self): '''Multithread Download Main Program''' threads = [] id_list = self.get_name_id()[0] name_list = self.get_name_id()[1] # Download queue generator name_queue = [name for name in name_list] id_queue = [id for id in id_list] while len(name_queue) > 0: for thread in threads: if not thread.is_alive(): threads.remove(thread) while len(threads) < 5 and len(name_queue) > 0: # Up to 5 threads running name = name_queue.pop(0) id = id_queue.pop(0) thread = threading.Thread(target=self.download_image, args=(name, id)) thread.setDaemon(True) # Set to daemon thread, the main thread will reclaim the sub-threads after execution. thread.start() print("Downloading %s" % name) threads.append(thread) print("All done!") if __name__ == '__main__': skin = Skin() skin.run()