We installed dlib19.17 and face_recognition in Windows 10 environment. For details, please refer to:
https://blog.csdn.net/weixin_41943311/article/details/91866987
https://blog.csdn.net/weixin_41943311/article/details/98482615
Then, we use dlib19.17+face_recognition to classify family photos, which can reach a speed of 4-6 seconds per sheet.
We are not satisfied with this speed and intend to improve it (or shorten the running time of the whole task).
We first thought about using multithreading, so we rewrote the program (number_threads to set the number of concurrent threads), the code is as follows:
# -*- coding: UTF-8 -*-
import dlib
import face_recognition
import numpy as np
import threading
from datetime import datetime
import os
import shutil
#Face detection threads convert file names into integers, classify the files to be processed according to the remainder of the integer division, and copy the files to the specified directory if hit.
def face_check_and_copy(num):
# Traverse through all.jpg files in the directory
f = os.walk("f:\images")
for path, d, filelist in f:
for filename in filelist:
if filename.endswith('jpg'):
#Convert the character of file name into ASCII code, and accumulate an integer.
only_name = os.path.splitext(filename)[0]
int_filename = 0
for every_char in only_name:
int_filename += ord(every_char)
#No locks, multithreading
if int_filename % number_threads == num:
image_path = os.path.join(path, filename)
# Loading Pictures
unknown_image = face_recognition.load_image_file(image_path)
count_checked[num] += 1
# Find the location of all faces in the picture
face_locations = face_recognition.face_locations(unknown_image)
# face_locations = face_recognition.face_locations(unknown_image, number_of_times_to_upsample=0, model="cnn")
# Loading a list of face encoding based on location
face_encodings = face_recognition.face_encodings(unknown_image, face_locations)
# Traverse all face codes and compare them with known faces
for (top, right, bottom, left), face_encoding in zip(face_locations, face_encodings):
# Comparisons were obtained.
matches = face_recognition.compare_faces(known_face_encodings, face_encoding, tolerance=0.4)
# Get the name of the successful alignment (without further processing) and copy the file to the specified directory
name = "Unknown"
if True in matches:
first_match_index = matches.index(True)
name = known_face_names[first_match_index]
# If there are more than one known face in the same picture, duplicating the file will cause an error.
try:
shutil.copy(image_path, "f:/images_family")
count_copied[num] += 1
break
except shutil.Error:
break
#Main Procedure Starts
number_threads = 4
count_checked = [0 for i in range(number_threads)]
count_copied = [0 for i in range(number_threads)]
count_check,count_copy = 0,0
# Loading known faces from images and obtaining encoding
steve_image = face_recognition.load_image_file("f:/images/steve.jpg")
steve_face_encoding = face_recognition.face_encodings(steve_image)[0]
lucy_image = face_recognition.load_image_file("f:/images/lucy.jpg")
lucy_face_encoding = face_recognition.face_encodings(lucy_image)[0]
known_face_encodings = [
steve_face_encoding,
lucy_face_encoding,
]
known_face_names = [
"Steve",
"Lucy",
]
# Test start time
t1 = datetime.now()
threadpool = []
for i in range(number_threads):
th = threading.Thread(target=face_check_and_copy, args=(i,))
threadpool.append(th)
for th in threadpool:
th.start()
for th in threadpool:
threading.Thread.join(th)
for i in range(number_threads):
count_check += count_checked[i]
count_copy += count_copied[i]
# End time of test
t2 = datetime.now()
# Show total time overhead
print('%d pictures checked, and %d pictures copied with known faces.' %(count_check, count_copy))
print('time spend: %d seconds, %d microseconds.' %((t2-t1).seconds, (t2-t1).microseconds))
for i in range(number_threads):
print('%d pictures checked in the No.%d thread.' %(count_checked[i], i))The result of the operation is somewhat unexpected:
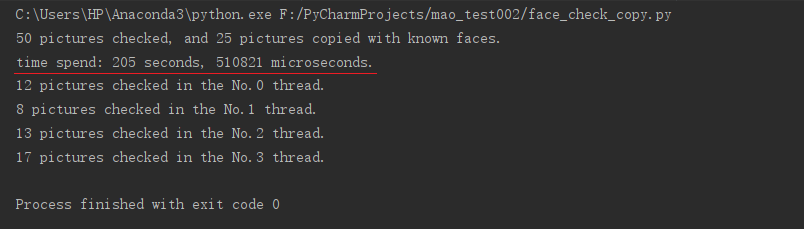
Four threads were used to check 12, 8, 13 and 17 files respectively, and run concurrently. The results did not improve the running efficiency. The total running time was almost the same as that of single thread, even slightly increased. We tried to change the number of threads, but no matter how many we set number_threads, the time it took to run the final program was comparable, neither faster nor slower.
While running the program, we observed that the CPU utilization of Windows 10 was always in the 16-33% range. Obviously, Python multithreading does not significantly improve concurrency performance. Why?
Originally, the problem lies in GIL.
The whole process of GIL is Global Interpreter Lock, which means global interpreter lock. In the mainstream implementation of CPython in Python language, GIL is a genuine global thread lock. When interpreter interprets and executes any Python code, it needs to acquire the lock before it can be released when I/O operation occurs. If it is a purely computational program without I/O operations, the interpreter releases the lock every 100 operations, giving other threads the opportunity to execute (this number can be adjusted by sys. setcheck interval). So although the CPython thread library directly encapsulates the native threads of the operating system, the CPython process as a whole, at the same time only one thread that has obtained the GIL is running, and the other threads are waiting for the release of the GIL.
That is to say, for Python, computing-intensive multithreading has the same performance as single-threading.
So, what else can speed up the processing of image files? Is Intel i7 8750H CPU's 6-core 12-thread configuration?
Of course not!
The way is to run multiple Python programs at the same time. We simply modified the program to run the two programs separately (because we allocate workload by pre-processing file names, so there is no need for communication and synchronization between the two programs). The code is as follows:
Procedure 1:
# -*- coding: UTF-8 -*-
import dlib
import face_recognition
import numpy as np
from datetime import datetime
import os
import shutil
# Loading known faces from images and obtaining encoding
steve_image = face_recognition.load_image_file("f:/images/steve.jpg")
steve_face_encoding = face_recognition.face_encodings(steve_image)[0]
lucy_image = face_recognition.load_image_file("f:/images/lucy.jpg")
lucy_face_encoding = face_recognition.face_encodings(lucy_image)[0]
known_face_encodings = [
steve_face_encoding,
lucy_face_encoding,
]
known_face_names = [
"Steve",
"Lucy",
]
# Test start time
t1 = datetime.now()
count_checked, count_copied = 0, 0
# Traverse through all.jpg files in the directory
f = os.walk("f:\images")
for path,d,filelist in f:
for filename in filelist:
if filename.endswith('jpg'):
image_path = os.path.join(path, filename)
# Convert the character of file name into ASCII code, and accumulate an integer.
only_name = os.path.splitext(filename)[0]
int_filename = 0
for every_char in only_name:
int_filename += ord(every_char)
if int_filename % 2 == 0:
# Loading Pictures
unknown_image = face_recognition.load_image_file(image_path)
count_checked += 1
# Find the location of all faces in the picture
face_locations = face_recognition.face_locations(unknown_image)
#face_locations = face_recognition.face_locations(unknown_image, number_of_times_to_upsample=0, model="cnn")
# Loading a list of face encoding based on location
face_encodings = face_recognition.face_encodings(unknown_image, face_locations)
# Traverse all face codes and compare them with known faces
for (top, right, bottom, left), face_encoding in zip(face_locations, face_encodings):
# Comparisons were obtained.
matches = face_recognition.compare_faces(known_face_encodings, face_encoding, tolerance=0.4)
# Get the name of the successful alignment (without further processing) and copy the file to the specified directory
name = "Unknown"
if True in matches:
first_match_index = matches.index(True)
name = known_face_names[first_match_index]
# If there are more than one known face in the same picture, duplicating the file will cause an error.
try:
shutil.copy(image_path,"f:/images_family")
count_copied += 1
break
except shutil.Error:
break
# End time of test
t2 = datetime.now()
# Show total time overhead
print('No.0 process: %d pictures checked, and %d pictures copied with known faces.' %(count_checked, count_copied))
print('No.0 process: time spend: %d seconds, %d microseconds.' %((t2-t1).seconds, (t2-t1).microseconds))
Procedure 2:
# -*- coding: UTF-8 -*-
import dlib
import face_recognition
import numpy as np
from datetime import datetime
import os
import shutil
# Loading known faces from images and obtaining encoding
steve_image = face_recognition.load_image_file("f:/images/steve.jpg")
steve_face_encoding = face_recognition.face_encodings(steve_image)[0]
lucy_image = face_recognition.load_image_file("f:/images/lucy.jpg")
lucy_face_encoding = face_recognition.face_encodings(lucy_image)[0]
known_face_encodings = [
steve_face_encoding,
lucy_face_encoding,
]
known_face_names = [
"Steve",
"Lucy",
]
# Test start time
t1 = datetime.now()
count_checked, count_copied = 0, 0
# Traverse through all.jpg files in the directory
f = os.walk("f:\images")
for path, d, filelist in f:
for filename in filelist:
if filename.endswith('jpg'):
image_path = os.path.join(path, filename)
# Convert the character of file name into ASCII code, and accumulate an integer.
only_name = os.path.splitext(filename)[0]
int_filename = 0
for every_char in only_name:
int_filename += ord(every_char)
if int_filename % 2 == 1:
# Loading Pictures
unknown_image = face_recognition.load_image_file(image_path)
count_checked += 1
# Find the location of all faces in the picture
face_locations = face_recognition.face_locations(unknown_image)
# face_locations = face_recognition.face_locations(unknown_image, number_of_times_to_upsample=0, model="cnn")
# Loading a list of face encoding based on location
face_encodings = face_recognition.face_encodings(unknown_image, face_locations)
# Traverse all face codes and compare them with known faces
for (top, right, bottom, left), face_encoding in zip(face_locations, face_encodings):
# Comparisons were obtained.
matches = face_recognition.compare_faces(known_face_encodings, face_encoding, tolerance=0.4)
# Get the name of the successful alignment (without further processing) and copy the file to the specified directory
name = "Unknown"
if True in matches:
first_match_index = matches.index(True)
name = known_face_names[first_match_index]
# If there are more than one known face in the same picture, duplicating the file will cause an error.
try:
shutil.copy(image_path, "f:/images_family")
count_copied += 1
break
except shutil.Error:
break
# End time of test
t2 = datetime.now()
# Show total time overhead
print('No.1 process: %d pictures checked, and %d pictures copied with known faces.' % (count_checked, count_copied))
print('No.1 process: time spend: %d seconds, %d microseconds.' % ((t2 - t1).seconds, (t2 - t1).microseconds))
We let the two programs run at the same time. Sure enough, the total running time is halved!

At the same time, we observed that CPU utilization increased from 16-33% to 32-68%, and even reached a peak of 80% instantaneously.
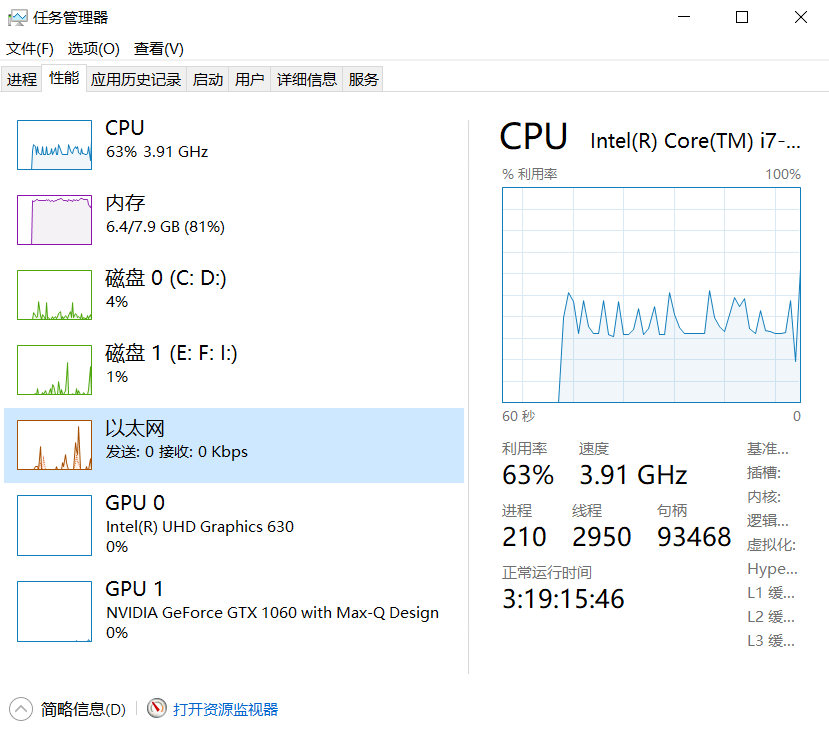
According to the standard of 6 cores and 12 threads, we can theoretically run six Python programs at the same time to occupy the CPU as much as possible.
In this case, in order to solve the problem that Python multi-threading can not improve performance, Python introduced the multiprocessing multi-process standard library, and we can try it again.
In addition, you can also use C/C++, write the key parts of the computing intensive into Python extensions with C/C++, create native threads with C in the extensions, and do not lock GIL, so you can make full use of CPU computing resources.
Reference resources:
http://blog.sina.com.cn/s/blog_64ecfc2f0102uzzf.html
(End)