Create autocrawler files with commands
Creating crawler files is based on the master scrapy to create crawler files
Scrapy genspider-l View scrapy's available master for creating crawler files
Available templates: Master description
Create basic crawler files
crawl Create Autocrawler Files
Create crawler files for crawling csv data
Create crawling xml data crawler files
Create a base master crawler, the same goes for the rest
Scrapy genspider-t master name crawler file name to crawl the domain name to create a base master crawler, the same as other
For example: scrapy genspider-t crawl Lagou www.lagou.com
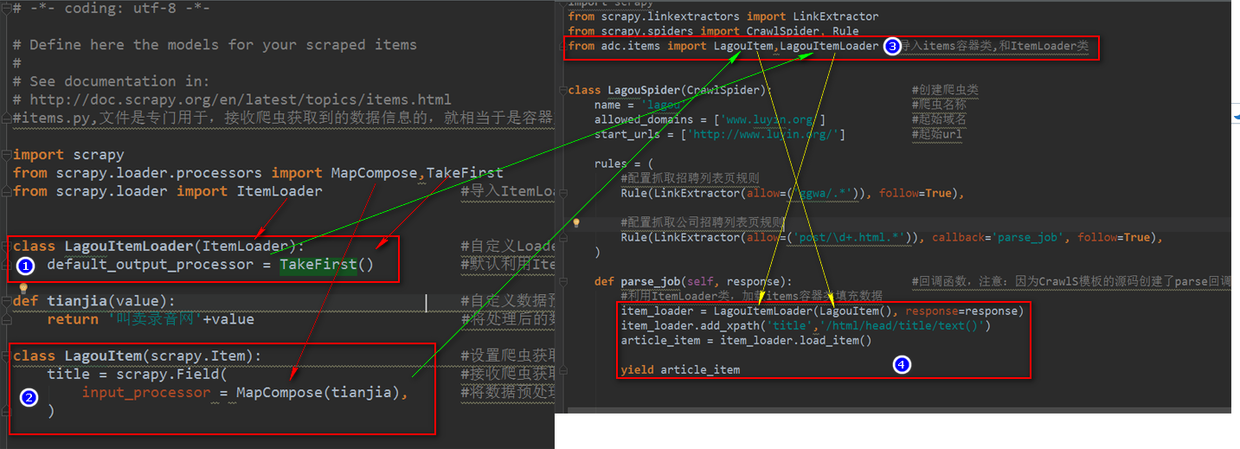
First, configure items.py to receive data fields
default_output_processor = TakeFirst() defaults to use the ItemLoader class to load the items container class to fill in the data, which is a list type and can be retrieved from the list through the TakeFirst() method.
Input_processor = MapCompose (preprocessing function) sets the preprocessing function for the data field, which can be multiple functions
What I don't know in the process of learning can be added to me?
python Learning Exchange Button qun,784758214
//There are good learning video tutorials, development tools and e-books in the group.
//Share with you the current talent needs of python enterprises and how to learn python from zero foundation, and what to learn
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
#Item. py, the file is specially used to receive data information from the crawler, which is equivalent to container file.
import scrapy
from scrapy.loader.processors import MapCompose,TakeFirst
from scrapy.loader import ItemLoader #Importing the ItemLoader class also loads the items container class to fill in the data.
class LagouItemLoader(ItemLoader): #Custom Loader inherits the ItemLoader class and calls it on the crawler page to populate the data into the Item class
default_output_processor = TakeFirst() #By default, the ItemLoader class is used to load the items container class to fill in the data, which is a list type. The contents of the list can be obtained through the TakeFirst() method.
def tianjia(value): #Custom Data Preprocessing Function
return 'Hawking Recording Network'+value #Return the processed data to Item
class LagouItem(scrapy.Item): #Setting the information container class that the crawler gets
title = scrapy.Field( #Receiving title information from Crawlers
input_processor = MapCompose(tianjia), #When the name of the data preprocessing function is passed into the MapCompose method for processing, the formal parameter value of the data preprocessing function automatically receives the field title.
)The second step is to write the automatic crawler and use the ItemLoader class to load the items container class to fill the data.
Autocrawler
Rule() Sets crawler rules
Parameters:
LinkExtractor() Sets url rules
callback='callback function name'
follow=True means to go deeper in crawling pages
LinkExtractor() makes rule judgment on the url acquired by the crawler
Parameters:
Allo= r'jobs/'is a regular expression, which means that only if it conforms to this url format can it be extracted.
deny= r'jobs/'is a regular expression that indicates that it conforms to this url format, does not extract and discard, as opposed to allow.
Allo_domains= www.lagou.com/ indicates that the connection under this domain name is extracted
deny_domains= www.lagou.com/ denotes that connections under this domain name are not withdrawn and discarded
The restrict_xpaths= xpath expression indicates that the crawler can use the xpath expression to restrict it to extract only the URL s of the specified area of a page
Rest_css= CSS selector, which means that the crawler can use CSS selector to restrict the URL to extract only one page's specified area
Tags='a'means that the crawler searches for url through a tag, which is set by default and can be done by default.
Attrs='href'denotes the href attribute of the tag a, which has been set by default and can be done by default.
Inheriting ItemLoader class with custom Loader class, loading items container class to fill data
ItemLoader() instantiates an ItemLoader object to load the ItemLoader container class and fill in the data, the same usage as ItemLoader inherited by custom Loader
Parameters:
First parameter: Note parentheses for the items container class to fill in the data.
The second parameter is response:
Method under ItemLoader object:
The add_xpath('field name','xpath expression') method fills the specified field with the data obtained from the XPath expression
The add_css('field name','css selector') method fills in the specified field with the data obtained by the CSS selector
The add_value('field name', string content) method fills the specified string data into the specified field
The load_item() method has no parameters and generates all the data. After the load_item() method is yield ed, the data is filled in the fields of the specified class of the items container.
Crawler files
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from adc.items import LagouItem,LagouItemLoader #Import items container classes, and ItemLoader classes
class LagouSpider(CrawlSpider): #Create reptiles
name = 'lagou' #Reptilian name
allowed_domains = ['www.luyin.org'] #Initial domain name
start_urls = ['http://www.luyin.org/'] start url
rules = (
#Configuration crawl list page rule
Rule(LinkExtractor(allow=('ggwa/.*')), follow=True),
#Configuration crawl content page rule
Rule(LinkExtractor(allow=('post/\d+.html.*')), callback='parse_job', follow=True),
)
def parse_job(self, response): #Callback function, note: Because the source code of the CrawlS template creates the parse callback function, remember that we can't create the function with the parse name.
#Using ItemLoader class to load items container class to fill data
item_loader = LagouItemLoader(LagouItem(), response=response)
item_loader.add_xpath('title','/html/head/title/text()')
article_item = item_loader.load_item()
yield article_itemIf you are still confused in the world of programming, you can join our Python Learning button qun: 784758214 to see how our predecessors learned. Exchange of experience. From basic Python script to web development, crawler, django, data mining, zero-base to actual project data are sorted out. To every Python buddy! Share some learning methods and small details that need attention. Click to join us. python learner gathering place
Schematic diagram of items.py file and crawler file