I. crawling for Douban reading information
Only the title and score of Douban's reading information are crawled here
Crawling method is to search according to the selector corresponding to the required information in the web page.
For example: Https://book.doublan.com/tag/fiction On the page, climb to the name of the book,
Then hang the cursor over the title of the book "alive", then right-click to select "check", and you will see the following parts: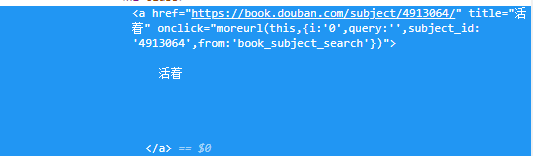
Then, hover the cursor over this part, right-click to select "copy" - "copy selector", and the book name selector will be copied:
#subject_list > ul > li:nth-child(1) > div.info > h2 > a
Among them, Nth child (1) means that this is the first book on this page. If you remove: nth child (1), you can access all the titles on this page at one time.
#coding=utf-8
import urllib.request
import lxml.etree
from cssselect import GenericTranslator, SelectorError
def loadDoubanScore(url, tag, start):
'''
//Score of reading by crawling Douban:
url: Website
tag: Reading labels, eg: 'Novel'
start: Start number, because each page has only limited book information, you need to turn the page start=0,Second pages start=20(It depends on how many books are on the first page),And so on
'''
tag = urllib.request.quote(tag)
url = url + tag + '?start=' + str(start)+'&type=T'
request = urllib.request.Request(url=url)
request.add_header(key="user-agent", val="Mozilla/5.0") #Simulating Mozilla browser for crawler
response = urllib.request.urlopen(url=request)
html = response.read().decode('utf-8')
dataList = []
try:
expressionName = GenericTranslator().css_to_xpath('#subject_list > ul > li > div.info > h2 > a') #In brackets is the selector of the title of the book
expressionScore = GenericTranslator().css_to_xpath('#subject_list > ul > li > div.info > div.star.clearfix > span.rating_nums') #Fill in the selector copied from the web source code here
except SelectorError:
print('Invalid selector.')
document = lxml.etree.HTML(text=html)
for name, score in zip(document.xpath(expressionName), document.xpath(expressionScore)):
dataList.append((name.get('title'), score.text))
# print(score.text) #Get content between tags
# print(name.get('title')) #Get information based on attributes
return dataList
url = "https://book.douban.com/tag/"
dataList = loadDoubanScore(url, tag="Novel", start=0)
for dl in dataList:
print(dl[0], " ", dl[1])
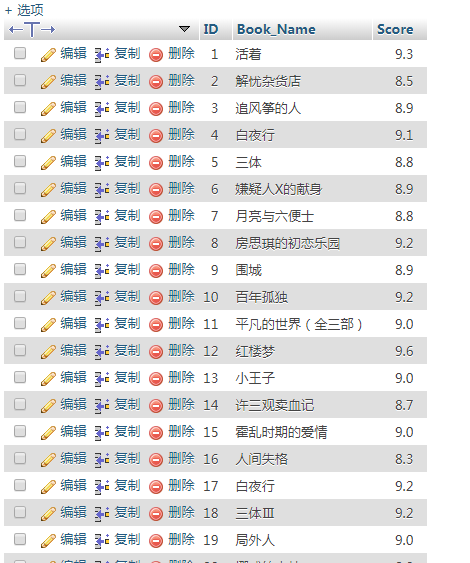
The results of the first page crawled are:
II. Store the data crawled above into Excel table
My code is written in the same python file, so the following code does not write the previous library and the statement url=“ https://book.douban.com/tag/"
'''Put crawling data into Excel Form'''
import xlwt
savePath = r"E:\douban.xls"
wb = xlwt.Workbook(encoding='ascii', style_compression=0)
sheet = wb.add_sheet(sheetname='sheet1', cell_overwrite_ok=True)
#——————————The following part is format setting, optional————————————————
font = xlwt.Font()
font.name = "Arial" #font name
font.bold = True #Thickening
alignment = xlwt.Alignment()
alignment.horz = xlwt.Alignment.HORZ_CENTER #Centered
style = xlwt.XFStyle()
style.font = font
style.alignment = alignment
#------------------------
sheet.col(1).width = 6000 #2962 initially, widen the first column
for i, bt in enumerate(['ID', 'bookName', 'score']):
sheet.write(r=0, c=i, label=bt, style=style) #If style is set, add the style parameter. If not, remove style -- sheet.write(r=0, c=i, label=bt)
id = 1
for page in range(2):
dataList = loadDoubanScore(url, tag="Novel", start=page*20) #Call the method of crawling data above
for i in range(len(dataList)):
sheet.write(r=id, c=0, label=id, style=style)
sheet.write(r=id, c=1, label=dataList[i][0], style=style)
sheet.write(r=id, c=2, label=float(dataList[i][1]), style=style)
id += 1
wb.save(savePath)
The results are as follows: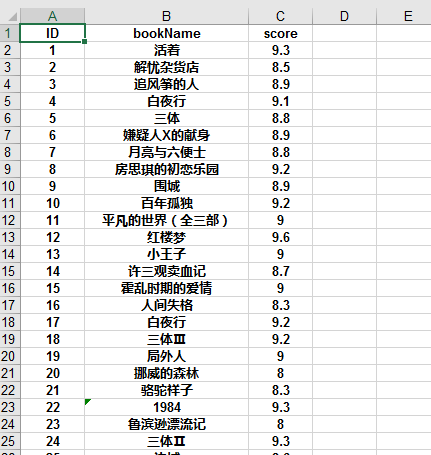
3. Store the crawling data in mysql database
My code is written in the same python file, so the following code does not write the previous library and the statement url=“ https://book.douban.com/tag/"
Of course, if you have mysql installed
'''Store the crawled data in the database'''
import pymysql
host = "localhost"
user = "root" #Your user name in mysql
pwd = "xxx" #Password for your root
dbName = "doubanRecord" #Database name where data will be stored
try:
connection = pymysql.connect(host=host, user=user, password=pwd, db=dbName, charset='utf8mb4', cursorclass=pymysql.cursors.DictCursor)
except pymysql.err.InternalError as err:
if(err.args[0] == 1049):
print(err.args[1], " ", "need create db")
connection = pymysql.connect(host=host, user=user, password=pwd, charset='utf8mb4', cursorclass=pymysql.cursors.DictCursor)
with connection.cursor() as cursor:
cursor.execute("CREATE DATABASE " + dbName) #Create database
connection.commit() #If you want to modify the contents of the database, you need to add this sentence
finally:
with connection.cursor() as cursor:
try:
# Use the preprocessing statement to create a table, [table name: DOUBAN, first column name: ID, second column name: Book [name], third column name: score]
sql = """CREATE TABLE DOUBAN (
ID INT NOT NULL AUTO_INCREMENT,
Book_Name VARCHAR(100) NOT NULL,
Score FLOAT(2,1),
PRIMARY KEY (ID))
ENGINE=InnoDB DEFAULT CHARSET=utf8;"""
cursor.execute(sql) #Create data table
except pymysql.err.InternalError as err:
print(err)
finally:
for page in range(0, 3): #Prepare to climb the first three pages, each page has 20 records
dataList = loadDoubanScore(url, tag="Novel", start=page*20) #Call the previous method of crawling data
for item in dataList:
#SQL = "insert into ` double '(` book ` name', ` score ') values (" alive ", 9.3)"
sql = "INSERT INTO `DOUBAN` (`Book_Name`, `Score`) VALUES "+ str(item)
cursor.execute(sql)
connection.commit()
connection.close()
The results are as follows: