Preface
The text and pictures of the article are from the Internet, only for learning and communication, and do not have any commercial use. The copyright belongs to the original author. If you have any questions, please contact us in time for handling.
Author: Yura doesn't say data, PYuraL
PS: if you need Python learning materials, you can click the link below to get them by yourself
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
Data crawling
In fact, I wanted to use douban.com's comments at the beginning, but I turned it over and found that only 500 of the "hottest comments" can be seen, only 100 of the "latest comments" can be displayed, and what can be analyzed with 600 pieces of data? 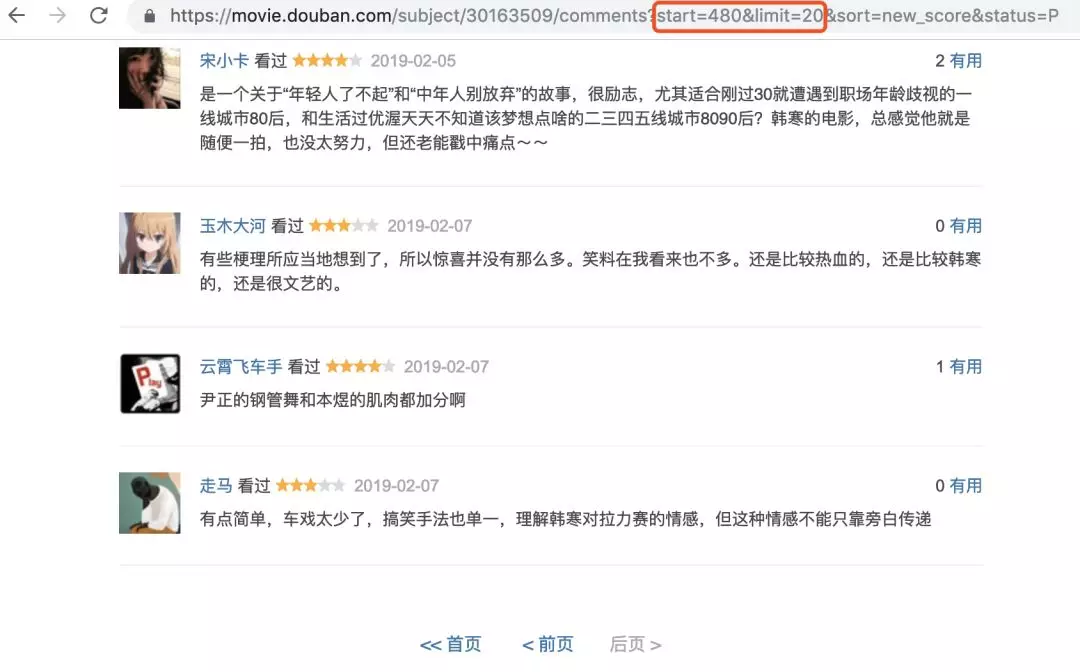
Baidu for a while, see everyone is using cat's eye comment, so Climb the cat's eye! The web version of cat's eye can only display Limited comments. You can only see all comments when you switch to the APP version.
It's not hard to find the web page in the network. You can search it with any comment

The key is to find the law of change between different web pages

Yes
On the surface, the difference between some URLs is offset, but when you change the value to 1005, you will not be able to climb things (maybe because of the internal settings of the web page), which means that we can only get 1000 comments.
Which 1000 comments is that? We can see that there is a keyword "ts=1549640420581" in the website, which is actually the meaning of the current time (timestamp). The transformation is as follows: 
So 1000 comments are the latest 1000 comments from this point in time, 15 from the front.
Through the crawler process of Baidu gods, I found that the ultimate solution is to change the value of ts! If offset 15 means to offset 15 comments from the query time to get 15 comments (limit=15), then we can't change the ts value every time.
The first ts value is the time when the program starts running, and the second value gets the earliest data from the comment data already obtained, so as to keep rolling forward
I crawled all the comments before 24:00 on February 8, and there were at least 80000 + pieces of data displayed by App, but I crawled down only 4w + pieces in total The lack of data is still serious.

The data format is as follows (including user id, user nickname, user cat eye level, gender, time, score, comment content, likes and comments):
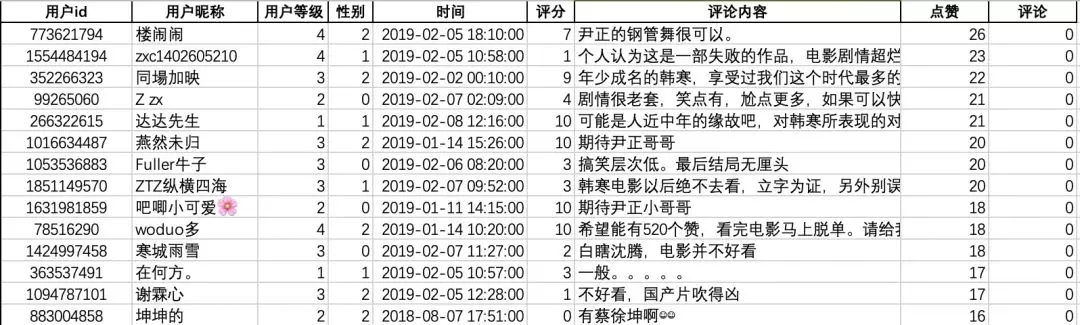
These are all in json, and the format is very clear.

Data cleaning
In addition to making word cloud with Python (code at the end), Excel solves other content in minutes. Thank you for inventing "PivotTable".
Data analysis
1. Audience information

The proportion of men and women is 50% respectively. It's understandable that men are interested in exciting things like racing cars. What is the purpose of this female audience? For Huang Jingyu's little brother's face? Or did you come to Ashin like me? There's too little information here. I only make a few random guesses. 
The user level is similar to the shape of normal distribution. It's smart Only 9.78% of the users (can be identified as new registered users) scored 0 and 1. It can be seen that the number of water army users is very small, and they are basically old cat eyes users.
Take a look at the changes in the number of user reviews in four days:
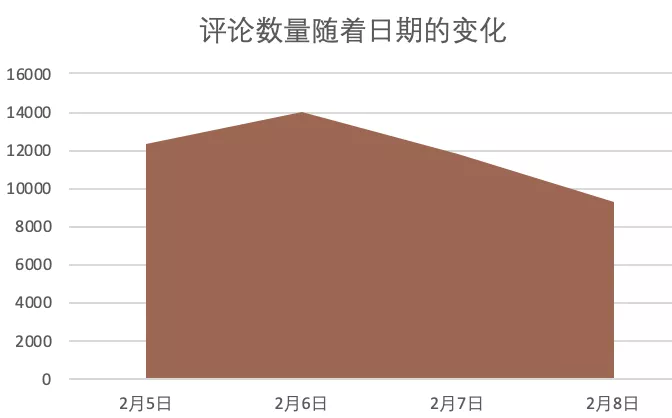
Basically, the popularity of this movie shows a slow downward trend (but due to the incomplete data, it cannot be absolutely explained)
When do users like to comment? Compare the four-day Review hour data:
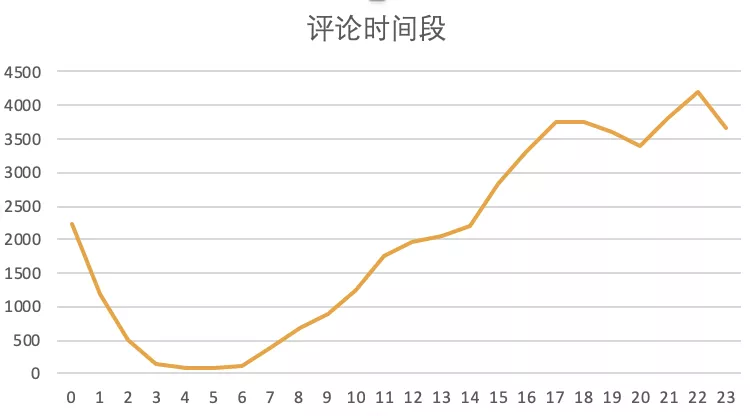
If you are used to evaluating the movie immediately after watching it, judging from the review trend, the number of comments gradually increases after 12 noon, presumably due to the end of the movie around 10 am. After that, the number of comments continued to increase, reaching a small peak at 5, 6 o'clock before dinner and around 23 o'clock before going to bed.
Well, it's very suitable for everyone's "holiday life" of "wake up, watch movies, eat, watch, sleep".
2. Scoring

According to the data I crawled, we saw that more than half (52.37%) of the audience gave the movie a full score of 10, and a very small number of users scored below 6 (only 7.58%). According to the data I crawled, the average score is 8.725, which is not much different from the real-time display score of 8.8.

In addition to the macro perspective of rating, let's look at the secret of commentator's gender, comment time and final rating?
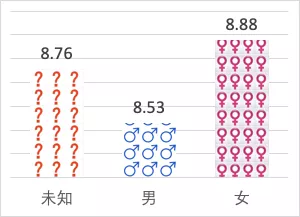
The difference of gender didn't make a big difference in the scores. The average score of male audience and female audience was only 0.35, and the score of "Unknown Gender" group was between them, which was basically equal to the average value of male score 8.53 and female score 8.88 (8.71). Well, I have good reason to suspect that the proportion of men and women in the "unknown group" is also half!

From the perspective of the relationship between scoring time and scoring, low scores generally appear between 0:00 and 7:00. I guess it's in such a quiet time of night that everyone's mood tends to rise and fall. The excitement of watching the movie in the daytime has gone away, leaving only deep thinking, maybe a little critical, right.
3. Comments
First look at the top 5 comments.

We found that the first five comments were all scored 10 points: the first one, emmm, had nothing to do with the movie, so we skipped it for now The others praise Han Han, Shen Teng and Huang Jingyu.
Let's take a look at the comments through the word cloud:

Immature code
1 from bs4 import BeautifulSoup 2 import requests 3 import warnings 4 import re 5 from datetime import datetime 6 import json 7 import random 8 import time 9 import datetime 10 11 headers = { 12 'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1', 13 'Connection':'keep-alive'} 14 cookies={'cookie':'_lxsdk_cuid=168c325f322c8-0156d0257eb33d-10326653-13c680-168c325f323c8; uuid_n_v=v1; iuuid=30E9F9E02A1911E9947B6716B6E91453A6754AA9248F40F39FBA1FD0A2AD9B42; webp=true; ci=191%2C%E5%8F%B0%E5%B7%9E; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; __mta=49658649.1549462270794.1549465778684.1549548206227.3; _lxsdk=30E9F9E02A1911E9947B6716B6E91453A6754AA9248F40F39FBA1FD0A2AD9B42; _lxsdk_s=168c898414e-035-f0e-e6%7C%7C463'} 15 16 #url Set up offset Offset 0 17 url = 'http://m.maoyan.com/review/v2/comments.json?movieId=1218091&userId=-1&offset=0&limit=15&ts={}&type=3' 18 19 comment=[] 20 nick=[] 21 score=[] 22 comment_time=[] 23 gender=[] 24 userlevel=[] 25 userid=[] 26 upcount=[] 27 replycount=[] 28 ji=1 29 30 31 url_time=url_time=int(time.time())*1000#Get the current time in milliseconds, so✖️1000) 32 33 for i in range(2000): 34 value=15*i 35 url_range=url.format(url_time) 36 res=requests.get(url_range,headers=headers,cookies=cookies,timeout=10) 37 res.encoding='utf-8' 38 print('Climbing to the top'+str(ji)+'page') 39 content=json.loads(res.text,encoding='utf-8') 40 list_=content['data']['comments'] 41 count=0 42 for item in list_: 43 comment.append(item['content']) 44 nick.append(item['nick']) 45 score.append(item['score']) 46 comment_time.append(datetime.datetime.fromtimestamp(int(item['time']/1000))) 47 gender.append(item['gender']) 48 userlevel.append(item['userLevel']) 49 userid.append(item['userId']) 50 upcount.append(item['upCount']) 51 replycount.append(item['replyCount']) 52 count=count+1 53 if count==15: 54 url_time=item['time'] 55 ji+=1 56 time.sleep(random.random()) 57 print('Crawl finish') 58 print(url_time) 59 result={'user id':userid,'User nickname':nick,'User level':userlevel,'Gender':gender,'time':comment_time,'score':score,'Comment content':comment,'Give the thumbs-up':upcount,'comment':replycount} 60 results=pd.DataFrame(result) 61 results.info() 62 results.to_excel('Cat eye_Flying life.xlsx')