After more than a week of crawling classes, the editor finally couldn't help but decide to write the crawler program manually. Just as LJ encouraged the students to share their results and rewarded their excellent works, he organized the crawl process of crawling high definition Wallpapers of major games with Python programming for submission and sharing with you.
We have crawled the wallpapers of the current popular games, MOBA game "League of Heroes", "Glory of the King", "Master Yin and Yang", FPS game "Jedi Survival". Among them, the wallpapers of "League of Heroes" are the hardest to crawl. Here we show the crawling process of all the hero Wallpapers of "League of Heroes". We have learned this, so it is no problem to crawl other Game wallpapers by ourselves.
First, look at the results of the final crawl. Every hero's wallpaper has been crawled down:

Twelve wallpapers for Annie the Dark Girl:

HD large picture:

Start formal teaching next!
Version: Python 3.5 Tools: Jupyter notebook implements each link and eventually integrates it into a LOL_scrawl.py file
1. Understand the crawl objects and design the crawl process
Before using the crawler, it is necessary to spend some time to understand the crawled objects, which can help us design the crawl process scientifically and reasonably to avoid the difficulties of crawling and save time.
1.1 Basic Hero Information
Open the official website of the Alliance of Heroes and see the message of all the heroes:

To crawl all the heroes, we first need to get the information of these heroes. Right-click - check - Elements on the web page, you can see the information of heroes, such as hero nickname, hero name, English name and so on.Since this information is dynamically loaded using JavaScript and cannot be obtained by ordinary crawling methods, we consider using the virtual browser PhantomJS to obtain this information.

We Click to enter the page of Annie the Dark Girl at "Annie" in the address is the hero's English name. To access other hero interface, just change the English name.
"Annie" in the address is the hero's English name. To access other hero interface, just change the English name.

On the Heroes page, you can switch to different skin maps by clicking on the thumbnails. On the maps,'Right click - open the picture in a new tab', you can open the maps. This is the high definition wallpaper we want:

Look at the address information in the picture above and open several other Annie's skin wallpapers to see that the different wallpapers differ only in the picture number:
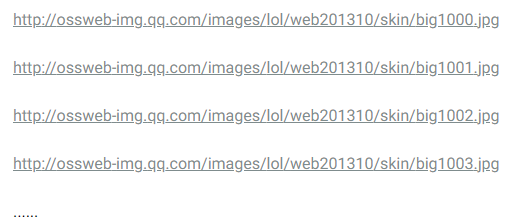
Then look at the wallpaper address of the hero "Blind Monk Li Qing":
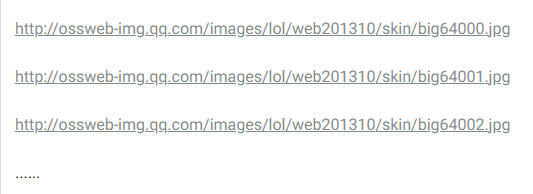
Look at the wallpaper address of the hero "Master Card Trist":
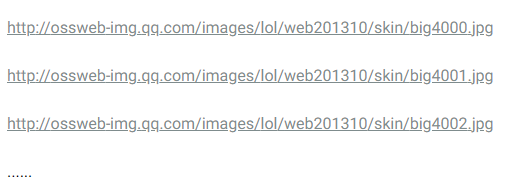
It can be concluded that the wallpaper address consists of three parts, fixed address + Hero id + wallpaper number.
Fixed address: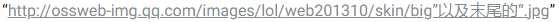 Hero id: Annie's ID is 1, Li Qing's ID is 64, Tristram's is 40. We still need to find the IDs of all the heroes
Wallpaper Number: The wallpaper number starts from 2000, 001, 002, 003..., and varies according to the number of different Heroes'skin. At present, there are no more than 20 Wallpapers per hero, that is, up to 020
Hero id: Annie's ID is 1, Li Qing's ID is 64, Tristram's is 40. We still need to find the IDs of all the heroes
Wallpaper Number: The wallpaper number starts from 2000, 001, 002, 003..., and varies according to the number of different Heroes'skin. At present, there are no more than 20 Wallpapers per hero, that is, up to 020
1.2 Hero ID
In the process above, we have basically understood the information about the objects to be crawled, but we do not know what the IDs of each hero are. We can not find the corresponding information of heroes and IDS after the source code of the web page and loading in JavaScript. Guess this information might be put in a js file, so we can find it.
A champion.js file can be found in all hero information interfaces by "right-clicking - checking - Network" and refreshing the interface:

Open the champion.js file and find the information we need. The hero's English name corresponds to the hero's id one by one:

1.3 Crawler Flowchart
So far we have a certain understanding of the objects we are crawling and some ideas about the specific crawling methods, we can design the following crawl flow chart:

2. Design Code Overall Framework
Based on the crawler flowchart, we can design the following code framework:
class LOL_scrawl: def __init__(self): #Constructor pass def get_info(self): #Enter crawl hero name, nickname, or All pass def create_lolfile(self): #Create folder LOL in current directory pass def get_heroframe(self): #Get all the hero information on the official website pass def get_image(self,heroid,heroframe): #Crawl hero information pass def run(self): self.create_lolfile() #Create LOL Folder inputcontent = self.get_info() #Get keyboard input heroframe = self.get_heroframe() #Get all the hero info print('Obtained hero information stored in heroframe.csv,Start crawling Wallpapers right away...\n') if inputcontent.lower() == 'all': #When all is entered, crawl all hero Wallpapers pass else: #Otherwise crawl individual hero Wallpapers passif __name__ == '__main__': lolscr = LOL_scrawl() #create object lolscr.run() #Running crawls
This code frame is easy to understand, mainly the run() function, which does the following work: create a LOL folder - get the information entered by the keyboard - crawl all the hero Wallpapers if the information is All, otherwise crawl individual hero wallpapers.
When crawling all or single hero wallpapers, crawling fails because of network instability, so we use try-except to handle the code when crawling wallpapers:
if inputcontent.lower() == 'all': #When all is entered, crawl all hero Wallpapers try: allline=len(heroframe) for i in range(1,allline): heroid=heroframe['heroid'][[i]].values[:][0] self.get_image(heroid,heroframe) print('Complete all crawl tasks!\n') except: print('Crawl failed or partially failed, check for errors') else: #Otherwise crawl individual hero Wallpapers try: hero=inputcontent.strip() line = heroframe[(heroframe.heronickname==hero) | (heroframe.heroname==hero)].index.tolist()#Find the row of the hero in the dataframe heroid=heroframe['heroid'][line].values[:][0] #Get the hero id self.get_image(heroid,heroframe) print('Complete all crawl tasks!\n') except: print('Error!Please input correctly as prompted!\n')
Now that the crawler framework is in place, two of the core codes in the crawl process are explained below: get_heroframe() and get_image(heroid,heroframe).
3. Crawl all hero information
3.1 Parsing js files
First, we will parse the champion.js file to get a one-to-one relationship between the hero's English name and ID.Open the file address with urllib.request, read the content and process it as a string, parse the content and turn it into a dictionary {key:value}, key as English name, value as hero id:
import urllib.request as urlrequest#Get hero's English name and id, generate dictionary herodict{Englishname:id}content=urlrequest.urlopen('http://Lol.qqq.com/biz/hero/champion.js').read() str1=r'champion={"keys":'str2=r', "data": {"Aatrox":'champion=str(content).split(str1)[1].split(str2)[0]hero Dict 0=eval(champion) hero dict = Dict dict((k, v), K in hero 0.items()#key dict and value print (hero) are interchanged in the dictionary //Get the dictionary herodict{Englishname: id} as follows: {'Soraka': '16', 'Akali': '84', 'Skarner': '72', 'Tristana': '18', 'Zilean': '26', 'JarvanIV': '59', 'Varus': '110', 'Talon': '91', ... 'Ashe': '22', 'Malphite':'54','Nocturne':'56','Khazix':'121'}
3.2 Selenium+PhantomJS for dynamic loading
For all hero information pages on the official website, because they are loaded in JavaScript, the common method is not good to crawl. We use Selenium+PhantomJS method to load hero information dynamically.Selenium is an automated testing tool that supports browser drivers such as Chrome, Safari, Firefox and requires the selenium module to be installed before use.PhantomJS is a virtual browser with no interface, but it has complete functions such as dom rendering, js running, network access, canvas/svg drawing, etc. It is widely used in page grabbing, page output, automated testing and so on.PhantomJS can be downloaded on the official website.
We use Selenium+PhantomJS to dynamically load hero information and BeautifulSoup to get web page content:
from selenium import webdriver import time from bs4 import BeautifulSoup #The address of all heroes on the official website of the League of Heroes url_Allhero='http://lol.qq.com/web201310/info-heros.shtml#Navi' #Open web address using headless browser PhantomJS to solve JavaScript dynamic loading problem driver=webdriver.PhantomJS(executable_path=r'D:\phantomjs-2.1.1-windows\bin\phantomjs') #executable_path is the installation location of PhantomJS driver.get(url_Allhero)time.sleep(1) #Pause execution for 1 second to ensure that the page loads #Use BeautifulSoup to get web page content pageSource=driver.page_sourcedriver.close()bsObj=BeautifulSoup(pageSource,"lxml")
After getting the page content, use BeautifulSoup to parse the page content, and store the hero nickname, name, id and other information in heroframe:
#Use BeautifulSoup to parse page content and get hero info tables heroframeherolist=bsObj.findAll('ul',{'class':'imgtextlist'}) for hero in herolist: n=len(hero) m=0 heroframe=pd.DataFrame(index=range(0,n), columns=['herolink','heronickname','heroname','Englishname','heroid']) heroinflist=hero.findAll('a') #Extract the hyperlink part of the hero's message for heroinf in heroinflist: #Hyperlink section for hero message herolink=heroinf['href'] eronickname=heroinf['title'].split(' ')[0].strip() heroname=heroinf['title'].split(' ')[1].strip() heroframe['herolink'][m]=herolink heroframe['heronickname'][m]=heronickname heroframe['heroname'][m]=heroname heroframe['Englishname'][m]=heroframe['herolink'][m][21:] heroframe['heroid'][m]=herodict[heroframe['Englishname'][m]] m=m+1 heroframe.to_csv('./LOL/heroframe.csv',encoding='gbk',index=False)
The get_heroframe() function now implements crawling all hero information and storing it in the heroframe.csv file as follows:

4. Crawl hero Wallpapers
Once we get the information about each hero, we can start crawling their Wallpapers happily ~Define the get_image function, which is used to crawl all the wallpapers of a single hero.
First create the hero's subfolder in the LOL folder:
#Create a folder to store the hero's wallpaper line = heroframe[heroframe.heroid == heroid].index.tolist() #Find the row of the hero in the dataframe nickname=heroframe['heronickname'][line].valuesname=heroframe['heroname'][line].valuesnickname_name=str((nickname +' '+ name)[0][:])filehero='.\LOL'+'\\'+nickname_name if not os.path.exists(filehero): os.makedirs(filehero)
Then you can crawl the hero's wallpaper.Since there are no more than 20 Wallpapers per hero, we can crawl all wallpapers in a cycle of less than 20:
#Crawl multiple wallpapers for k in range(21): #Address to generate a wallpaper url='http://ossweb-img.qq.com/images/lol/web201310/skin/big'+str(heroid)+'0'*(3-len(str(k)))+str(k)+'.jpg' #Crawl a wallpaper try: image=urlrequest.urlopen(url).read() imagename=filehero+'\\'+'0'*(3-len(str(k)))+str(k)+'.jpg' with open(imagename, 'wb') as f: f.write(image) except HTTPError as e: continue
Tips for successful output after crawling is complete:
#Finish the hero's crawl print('Hero '+ nickname_name +' Wallpaper crawled successfully\n')
You're done here!As long as you run this applet, all hero's skin wallpapers will be in your pocket. Of course, you can also crawl all the skin of a single hero. Just type in the hero's nickname or name as prompted.
Crawl single hero skin wallpaper:
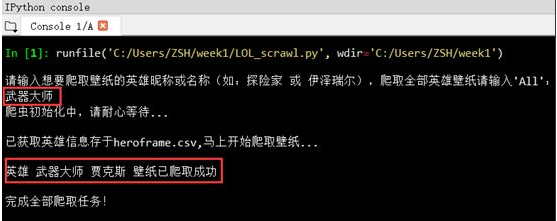
Crawl all heroic skin wallpapers:
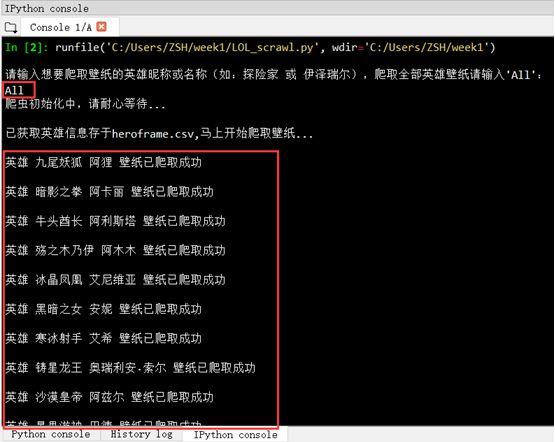
Be careful to keep the network open when running code. Crawling may fail if the network speed is too slow.It takes about 3-4 minutes to crawl all the high definition Wallpapers (about 1,000 pictures) of all 139 heroes on a 3-megabyte cable network.
The Wallpapers of other games such as Glory of the King, Master of Yin and Yang, and Survival of the Jedi can be crawled in the same way. According to my practice, the crawling difficulty of the League of Heroes is the highest, so it is easy to understand the above process and write your own code to crawl other games.
Finally, put a wallpaper of "Never Die Ruiz" to congratulate LPL on winning the championship!

Last
If you still don't know how to write this script, you can focus on Title + Forward this article, and then confide in Title "Skin" to get the completion code, or find me to guide you to grab the hero's skin, the original is not easy!
Click to learn more and get Python Zero Basic Advanced Crawler Learning Materials for free~~