Big file problem
Function calculation The size of the uploaded zip code package is limited to 50M. This limit can be exceeded in some scenarios, such as Uncut serverless-chrome , similar to libreoffice, in addition to the common machine learning training model file.
At present, there are three ways to solve the problem of large documents
- Adopt higher compression ratio algorithm, such as brotli algorithm introduced in this paper
- Download with OSS runtime
- Adopt NAS file sharing
Simply compare the advantages and disadvantages of these three methods
| Method | Advantage | shortcoming |
|---|---|---|
| High density compression | Easy to release, fastest to start | Upload the code package slowly; write the decompression code; the size is limited to no more than 50 M |
| OSS | No more than 512 M files after downloading and decompressing | It needs to be uploaded to OSS in advance; to write download and decompress code, the download speed is about 50M/s |
| NAS | There is no limit to file size, no need to compress | Need to upload to NAS in advance; VPC environment has cold start delay (~ 5s) |
Under normal circumstances, if the code package can be controlled below 50M, the startup will be faster. Moreover, the project is relatively simple. Data and code are put together, and no additional script is needed to update OSS or NAS synchronously.
compression algorithm
Brotli It is an open source compression algorithm developed by Google engineers, which has been supported by the new version of mainstream browsers as the compression algorithm for HTTP transmission. Here is a comparison benchmark of Brotli and other common compression algorithms found on the Internet.
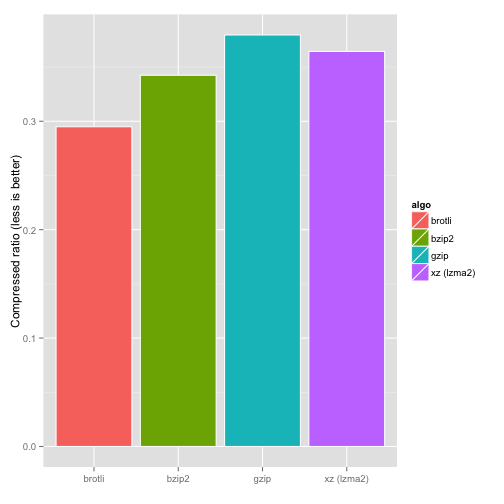
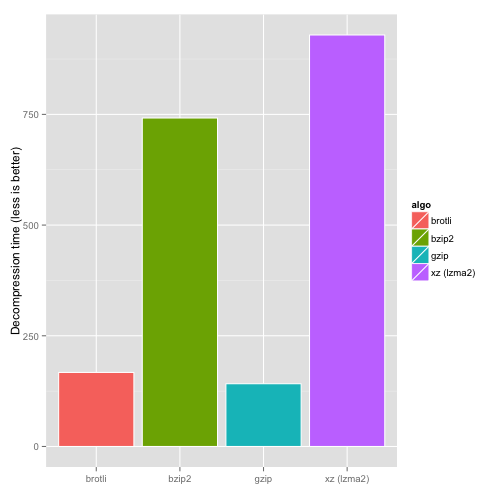
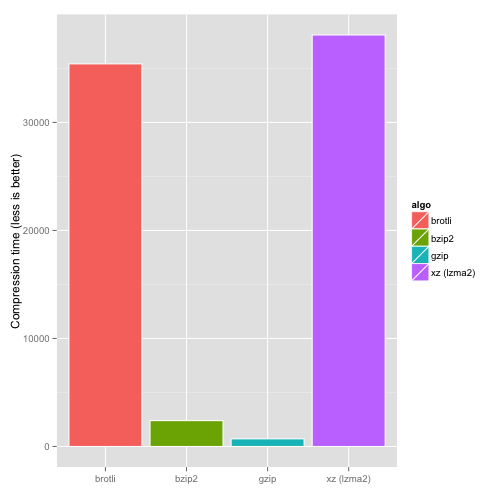

From the above three figures, we can see that brotli has the highest compression ratio, close to the decompression speed of gzip and the slowest compression speed compared with gzip, xz and bz2.
However, in our scenario, we are not sensitive to the disadvantage of slow compression. The compression task only needs to be performed once in the stage of developing and preparing materials.
Making compressed files
Let me first introduce how to make compressed files. The following code and use cases are from the project packed-selenium-java-example .
Install brotli command
Mac users
brew install brotli
Windows users can go to this interface to download, https://github.com/google/brotli/releases
Pack and compress
The first two file sizes are 7.5M and 97M respectively
╭─ ~/D/test1[◷ 18:15:21] ╰─ ll total 213840 -rwxr-xr-x 1 vangie staff 7.5M 3 5 11:13 chromedriver -rwxr-xr-x 1 vangie staff 97M 1 25 2018 headless-chromium
Pack and compress with GZip, size 44 M.
╭─ ~/D/test1[◷ 18:15:33] ╰─ tar -czvf chromedriver.tar chromedriver headless-chromium a chromedriver a headless-chromium ╭─ ~/D/test1[◷ 18:16:41] ╰─ ll total 306216 -rwxr-xr-x 1 vangie staff 7.5M 3 5 11:13 chromedriver -rw-r--r-- 1 vangie staff 44M 3 6 18:16 chromedriver.tar -rwxr-xr-x 1 vangie staff 97M 1 25 2018 headless-chromium
Remove the z option from tar and pack again. The size is 104M
╭─ ~/D/test1[◷ 18:16:42] ╰─ tar -cvf chromedriver.tar chromedriver headless-chromium a chromedriver a headless-chromium ╭─ ~/D/test1[◷ 18:17:06] ╰─ ll total 443232 -rwxr-xr-x 1 vangie staff 7.5M 3 5 11:13 chromedriver -rw-r--r-- 1 vangie staff 104M 3 6 18:17 chromedriver.tar -rwxr-xr-x 1 vangie staff 97M 1 25 2018 headless-chromium
The compressed size is 33M, which is much smaller than the 44M of Gzip. It takes 6 minutes and 18 seconds, and Gzip takes only 5 seconds.
╭─ ~/D/test1[◷ 18:17:08] ╰─ time brotli -q 11 -j -f chromedriver.tar brotli -q 11 -j -f chromedriver.tar 375.39s user 1.66s system 99% cpu 6:18.21 total ╭─ ~/D/test1[◷ 18:24:23] ╰─ ll total 281552 -rwxr-xr-x 1 vangie staff 7.5M 3 5 11:13 chromedriver -rw-r--r-- 1 vangie staff 33M 3 6 18:17 chromedriver.tar.br -rwxr-xr-x 1 vangie staff 97M 1 25 2018 headless-chromium
Runtime decompression
Take java maven project as an example
Add decompression dependency package
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
<version>1.18</version>
</dependency>
<dependency>
<groupId>org.brotli</groupId>
<artifactId>dec</artifactId>
<version>0.1.2</version>
</dependency>Commons compress is a decompression toolkit provided by apache. It provides a consistent abstract interface for various compression algorithms, and only supports decompression for brotli algorithm, which is enough here. org.brotli:dec package is the bottom implementation of brotli decompression algorithm provided by Google.
Implementing the initialize method
public class ChromeDemo implements FunctionInitializer {
public void initialize(Context context) throws IOException {
Instant start = Instant.now();
try (TarArchiveInputStream in =
new TarArchiveInputStream(
new BrotliCompressorInputStream(
new BufferedInputStream(
new FileInputStream("chromedriver.tar.br"))))) {
TarArchiveEntry entry;
while ((entry = in.getNextTarEntry()) != null) {
if (entry.isDirectory()) {
continue;
}
File file = new File("/tmp/bin", entry.getName());
File parent = file.getParentFile();
if (!parent.exists()) {
parent.mkdirs();
}
System.out.println("extract file to " + file.getAbsolutePath());
try (FileOutputStream out = new FileOutputStream(file)) {
IOUtils.copy(in, out);
}
Files.setPosixFilePermissions(file.getCanonicalFile().toPath(),
getPosixFilePermission(entry.getMode()));
}
}
Instant finish = Instant.now();
long timeElapsed = Duration.between(start, finish).toMillis();
System.out.println("Extract binary elapsed: " + timeElapsed + "ms");
}
}Implements the initialize method of the FunctionInitializer interface. At the beginning of the decompression process, there are four layers of nested flows, with the functions as follows:
- FileInputStream read file
- BufferedInputStream provides cache, introduces context switch brought by system call, and prompts the speed of reading
- BrotliCompressorInputStream decodes the byte stream
- TarArchiveInputStream parses the files in the tar package one by one
Then the function of Files.setPosixFilePermissions is to restore the permissions of the files in the tar package. The code is too long. Please refer to packed-selenium-java-example
Instant start = Instant.now();
...
Instant finish = Instant.now();
long timeElapsed = Duration.between(start, finish).toMillis();
System.out.println("Extract binary elapsed: " + timeElapsed + "ms");The above code segment will take about 3.7 s econds to print out and decompress.
Finally, don't forget to configure Initializer and InitializationTimeout in template.yml
Reference reading
- https://www.opencpu.org/posts/brotli-benchmarks/
- https://github.com/vangie/packed-selenium-java-example
Join us
Team Introduction
Alibaba cloud function service is a new computing service that supports event driven programming mode. He helps users focus on their own business logic, build applications in the way of Serverless, and quickly realize low-cost, scalable and highly available systems without considering the management of underlying infrastructure such as servers. Users can quickly create prototypes, and the same architecture can scale smoothly with the business scale. Make computing more efficient, more economical, more flexible and more reliable. Both small start-ups and large enterprises benefit from this. Our team is expanding rapidly and is eager for talents. We want to find teammates like this:
Solid basic skills. It can not only read papers to track the trend of the industry, but also quickly code to solve practical problems.
Rigorous and systematic thinking ability. It can not only consider business opportunities, system architecture, operation and maintenance costs and many other factors, but also control the complete process of design / development / test / release, predict and control risks.
Driven by curiosity and sense of mission. Willing to explore the unknown, he is not only a dreamer, but also a practitioner.
Tough, optimistic and confident. Can see the opportunity in the pressure and the difficulty, lets the work be full of fun!
If you are passionate about cloud computing and want to build an influential computing platform and ecosystem, please join us to realize your dream with us!
Job description
Build a new generation of Serverless computing platform, including:
- Design and implement a complete and extensible front-end system, including authentication / permission management, metadata management, flow control, metering and billing, log monitoring, etc
- Design and implement elastic and reliable back-end system, including resource scheduling, load balancing, fault-tolerant processing, etc
- Rich and easy-to-use SDK/Tools/CLI / console
- Driven by user needs, tracking industry trends, and using technology to drive business growth
Job requirements
- Solid basic knowledge of algorithm / data structure / operating system, excellent logical thinking ability.
- Master at least one programming language. For example, Java / go / C / C × / C + +.
- Experience in large-scale and highly available distributed system development is preferred.
- Web/Mobile Backends/Microservice development experience is preferred.
- Good communication skills and team work spirit, have a certain ability of organization and coordination.
- Bachelor degree or above
- More than 3 years of working experience, students who have passed the "Alibaba code specification" certification are preferred to be admitted, and the certification address is: https://edu.aliyun.com/certification/cldt02
Resume submitted
yixian.dw AT alibaba-inc.com
"Alibaba cloud native technology circle Pay attention to microservices, Serverless, containers, Service Mesh and other technology fields, focus on cloud native popular technology trends, cloud native large-scale landing practice, and become the technology circle that most understands cloud native developers. "