It has been several days since "later we" was released. I haven't been to see it. There was a ticket refund incident a few days ago. The theme song of the movie was sung by Eason Chan. I specially looked for the MV of the theme song "we" and watched it. It's still that feeling. That day, I saw an official account of the Python Chinese community public. New discovery of 100000 comments on Eason Chan's new song "we" in Python . Recently, I have been learning Python, trying to find an interesting project to do an exercise, so I started to practice by imitating the author's code. In the original, the author said in the title "new discovery of 100000 comments". Through the operation of the program, I found that the author didn't crawl all comments, just crawled the popular comments of "we" in Netease cloud music, and according to the number According to the chart.
Code:
1 #!/usr/bin/env python3 2 # -*- coding: utf-8 -*- 3 # @Time : 2018/4/29 18:09 4 # @Author : yang 5 # @File : Code.py 6 # @Software: PyCharm 7 import requests 8 import json 9 10 #Crawling through the popular comments of Eason Chan's "we" 11 #Parameters: url,headers,user_data(params,encSecKey) 12 url = 'http://music.163.com/weapi/v1/resource/comments/R_SO_4_551816010?csrf_token=' #Link to comment 13 headers = { 14 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36', 15 'Referer':'http://music.163.com/song?id=551816010', 16 'Origin':'http://music.163.com', 17 'Host':'music.163.com' 18 } 19 #Encrypt the data and use it directly 20 user_data = { 21 'params':'60e75d03+rb9U8IQhy6/9+H1si5pp7qLysZoQsYG9qFkXtXL9dRKMfchCKpJ8OpN9m7vSRVkYWN+wscyUqelunqxGDozt2bJWQ2QRj4pJrSa0xoJPAk5Jw8t70rYW8hwdyoYswl+kRQTQ6oz3eHHZ5BLzZZB4t/4asFSQQDnCteg2GqrEJBomMgpFMIa4Ybt', 22 'encSecKey':'52db8824c86503bc2cfc050ac78969c9155ff08f274f88b767ad6535febcbad021d0cdabcc172e01f91c42a2aca0786e407935f8feaa44a03efb96ec9d71de181e92ae8471738e4a43b252f22b46739cb3b86544a9f9403b0402bd9638a3bc2b87bf3a0b9cff6ef7b6b1589f00a5bfeecb9d45c493456082d80fbece6ac5a3fa' 23 } 24 25 response = requests.post(url,headers=headers,data=user_data) 26 data = json.loads(response.text) 27 hotcomments = [] 28 for hotcomment in data['hotComments']: 29 item = { 30 'nickname':hotcomment['user']['nickname'], 31 'content':hotcomment['content'], 32 'likedCount':hotcomment['likedCount'] 33 } 34 hotcomments.append(item) 35 #Get comment user name, content, and the corresponding number of likes 36 content_list = [content['content'] for content in hotcomments] 37 nickname = [content['nickname'] for content in hotcomments] 38 liked_count = [content['likedCount'] for content in hotcomments] 39 40 #Praise points 41 from pyecharts import Bar #pyecharts: Charting package 42 bar = Bar('Example of popular likes') 43 bar.add('Praise points',nickname,liked_count,is_stack=True,mark_line=['min','max'],mark_point=['average']) 44 bar.render() 45 46 #Word cloud diagram 47 from wordcloud import WordCloud #WordCloud: Word cloud package 48 import matplotlib.pyplot as plt #matplotlib: Drawing function package 49 content_text = ' '.join(content_list) 50 wordcloud = WordCloud(font_path=r'C:\simhei.ttf',max_words=200).generate(content_text) 51 plt.figure() 52 plt.imshow(wordcloud,interpolation='bilinear') 53 plt.axis('off') 54 plt.show()
Crawling results:
Top comments like:
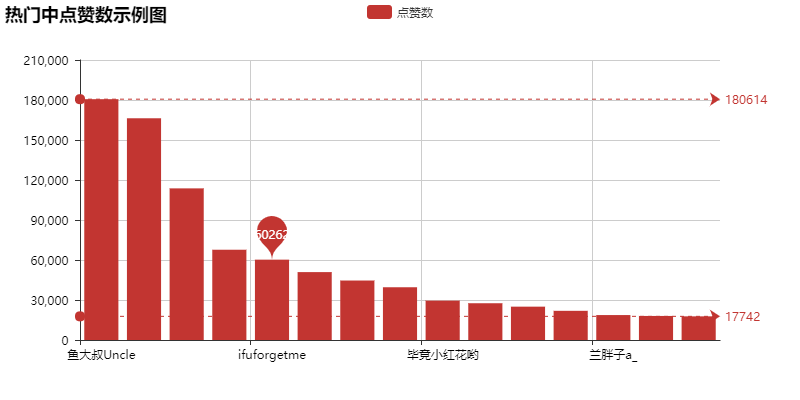
Cloud of popular comments:
