In parallel programming, we often encounter the problem of operating shared sets among multiple threads. In many cases, it is difficult for us to avoid this problem and achieve a lockless programming state. You also know that once the shared sets are locked, the concurrency and scalability will often have a great impact. This article will talk about how to reduce the number of lock times or not as much as possible.
1: Cause
1. Business background
When I review ed the code yesterday, I saw a piece of code that I had written before, which was simplified as follows:
private static List<long> ExecuteFilterList(int shopID, List<MemoryCacheTrade> trades, List<FilterConditon> filterItemList, MatrixSearchContext searchContext) { var customerIDList = new List<long>(); var index = 0; Parallel.ForEach(filterItemList, new ParallelOptions() { MaxDegreeOfParallelism = 4 }, (filterItem) => { var context = new FilterItemContext() { StartTime = searchContext.StartTime, EndTime = searchContext.EndTime, ShopID = shopID, Field = filterItem.Field, FilterType = filterItem.FilterType, ItemList = filterItem.FilterValue, SearchList = trades.ToList() }; var smallCustomerIDList = context.Execute(); lock (filterItemList) { if (index == 0) { customerIDList.AddRange(smallCustomerIDList); index++; } else { customerIDList = customerIDList.Intersect(smallCustomerIDList).ToList(); } } }); return customerIDList; }
The function of this code is as follows: the filteritem list carries all the atomized filter conditions, and then executes the items in the form of multithreading in parallel. Finally, the number of customers obtained by each item is set at the high level for overall intersection, as shown in the figure below.
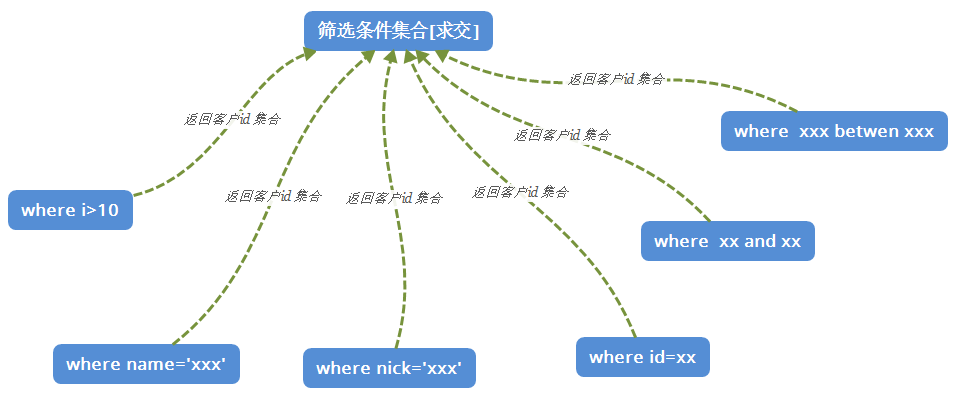
2. Problem analysis
In fact, there is a big problem in this code. If I use lock directly in Parallel, I will lock as many times as there are filteritemlists, which has a certain impact on concurrency and scalability. Now let's think about how to optimize it!
3. Test cases
To facilitate the demonstration, I simulated a small case for you to see the real-time results. The modified code is as follows:
public static void Main(string[] args) { var filterItemList = new List<string>() { "conditon1", "conditon2", "conditon3", "conditon4", "conditon5", "conditon6" }; ParallelTest1(filterItemList); } public static void ParallelTest1(List<string> filterItemList) { var totalCustomerIDList = new List<int>(); bool isfirst = true; Parallel.ForEach(filterItemList, new ParallelOptions() { MaxDegreeOfParallelism = 2 }, (query) => { var smallCustomerIDList = GetCustomerIDList(query); lock (filterItemList) { if (isfirst) { totalCustomerIDList.AddRange(smallCustomerIDList); isfirst = false; } else { totalCustomerIDList = totalCustomerIDList.Intersect(smallCustomerIDList).ToList(); } Console.WriteLine($"{DateTime.Now} Locked"); } }); Console.WriteLine($"Last intersection customer ID:{string.Join(",", totalCustomerIDList)}"); } public static List<int> GetCustomerIDList(string query) { var dict = new Dictionary<string, List<int>>() { ["conditon1"] = new List<int>() { 1, 2, 4, 7 }, ["conditon2"] = new List<int>() { 1, 4, 6, 7 }, ["conditon3"] = new List<int>() { 1, 4, 5, 7 }, ["conditon4"] = new List<int>() { 1, 2, 3, 7 }, ["conditon5"] = new List<int>() { 1, 2, 4, 5, 7 }, ["conditon6"] = new List<int>() { 1, 3, 4, 7, 9 }, }; return dict[query]; } ------ output ------ 2020/04/21 15:53:34 Locked 2020/04/21 15:53:34 Locked 2020/04/21 15:53:34 Locked 2020/04/21 15:53:34 Locked 2020/04/21 15:53:34 Locked 2020/04/21 15:53:34 Locked //Last intersection customer ID:1,7
2: First optimization
From the results, we can see that there are 6 filteritemlists and 6 locks, so how to reduce them? In fact, the FCL God that implements Parallel code also takes this problem into consideration, and gives a good overload from the bottom, as shown below:
public static ParallelLoopResult ForEach<TSource, TLocal>(OrderablePartitioner<TSource> source, ParallelOptions parallelOptions, Func<TLocal> localInit, Func<TSource, ParallelLoopState, long, TLocal, TLocal> body, Action<TLocal> localFinally);
This overload is very special. There are two more parameters, localInit and localFinally. What do you mean in the future? Let's see the modified code first
public static void ParallelTest2(List<string> filterItemList) { var totalCustomerIDList = new List<int>(); var isfirst = true; Parallel.ForEach<string, List<int>>(filterItemList, new ParallelOptions() { MaxDegreeOfParallelism = 2 }, () => { return null; }, (query, loop, index, smalllist) => { var smallCustomerIDList = GetCustomerIDList(query); if (smalllist == null) return smallCustomerIDList; return smalllist.Intersect(smallCustomerIDList).ToList(); }, (finalllist) => { lock (filterItemList) { if (isfirst) { totalCustomerIDList.AddRange(finalllist); isfirst = false; } else { totalCustomerIDList = totalCustomerIDList.Intersect(finalllist).ToList(); } Console.WriteLine($"{DateTime.Now} Locked"); } }); Console.WriteLine($"Last intersection customer ID:{string.Join(",", totalCustomerIDList)}"); } ------- output ------ 2020/04/21 16:11:46 Locked 2020/04/21 16:11:46 Locked //Last intersection customer ID:1,7 Press any key to continue . . .
Well, this optimization reduced the number of lock s from 6 to 2. Here, I used new paralleloptions() {maxdegreeofparallelism = 2} The concurrency is set to two CPU cores at most. After the program runs, two threads will be opened. A large set will be divided into two small sets, which is equivalent to one set and three conditions. The first thread will execute your localInit function at the beginning of the three conditions, and then execute your localFinally after the three conditions are iterated. The second thread will execute three of its own in the same way Conditions, said a little obscure, draw a picture to explain it.

3: Second optimization
If you know the Task < T > with return value, it's easy to do. You can open as many tasks as you want in the filter item list. Anyway, the bottom layer of the Task is hosted by the thread pool, so don't be afraid. This is the perfect way to implement lockless programming.
public static void ParallelTest3(List<string> filterItemList) { var totalCustomerIDList = new List<int>(); var tasks = new Task<List<int>>[filterItemList.Count]; for (int i = 0; i < filterItemList.Count; i++) { tasks[i] = Task.Factory.StartNew((query) => { return GetCustomerIDList(query.ToString()); }, filterItemList[i]); } Task.WaitAll(tasks); for (int i = 0; i < tasks.Length; i++) { var smallCustomerIDList = tasks[i].Result; if (i == 0) { totalCustomerIDList.AddRange(smallCustomerIDList); } else { totalCustomerIDList = totalCustomerIDList.Intersect(smallCustomerIDList).ToList(); } } Console.WriteLine($"Last intersection customer ID:{string.Join(",", totalCustomerIDList)}"); } ------ output ------- //Last intersection customer ID:1,7 Press any key to continue . . .
4: Summary
We optimized the original six locks to lockless programming, but it doesn't mean that the efficiency of lockless programming is higher than that of lockless programming. We should use and mix reasonably according to our own use scenarios.
Well, that's all. I hope it can help you.