Python basic syntax learning path
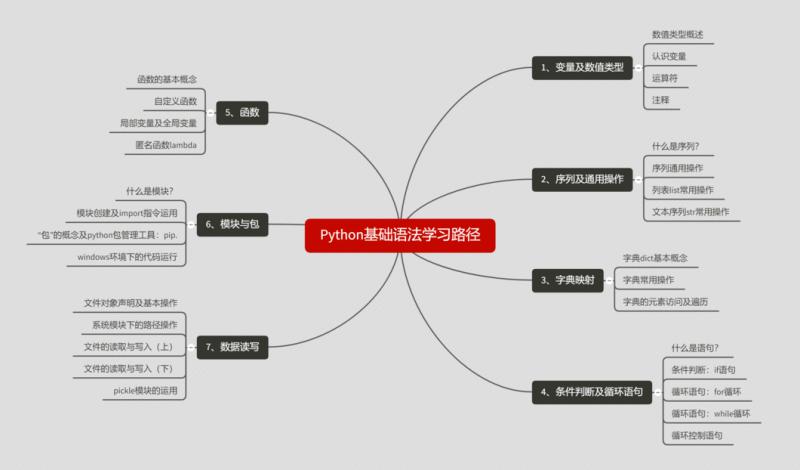
python concept level
Expression → create and process objects
Statement → include expression
Logical unit → function or class, composed of statements
Module →. py code file composition module
Package → define a group of related files or modules (package is a folder, module is a file in it, and the folder includes an init.py file)
Program → several packages + several files
What are the ten mistakes?
1. Variable naming problem

2. Difference between numerical value and string calculation

3. The difference between list and dictionary

4. Sequence index problem

5. Dictionary index problem

6,range()

7. Two kinds of operators: assignment operation and comparison operation

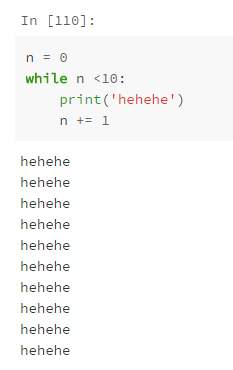
8. Dead cycle problem
*9. The difference between f(x) and f(x)

10. The difference between return and print in function

Implementing the first data crawler in Python
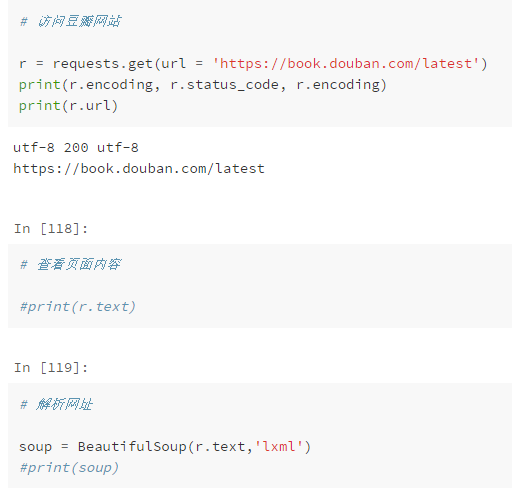
Let's make a crawler of Douban Book score.
Import module:
import requests from bs4 import BeautifulSoup print('Module imported successfully')
The code annotation is very clear, so it will not be explained here.
The code is as follows:
# Extract label #print(soup.head) # Header information print(soup.title) # Title print(soup.a) # First a tag extracted <title>New book Express</title> <a class="nav-login" href="https://Accounts. Double. COM / Passport / login? Source = book "rel =" nofollow "> sign in / register</a>
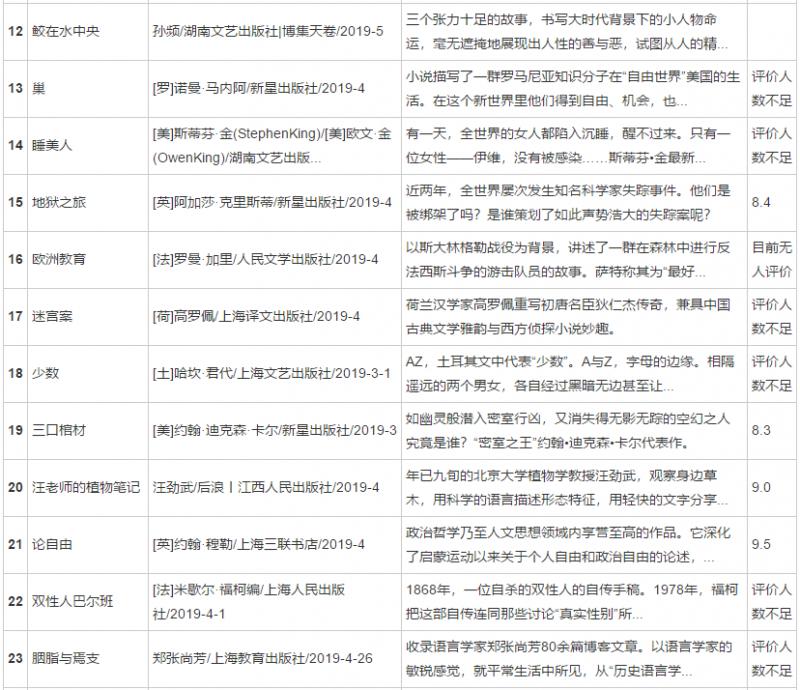
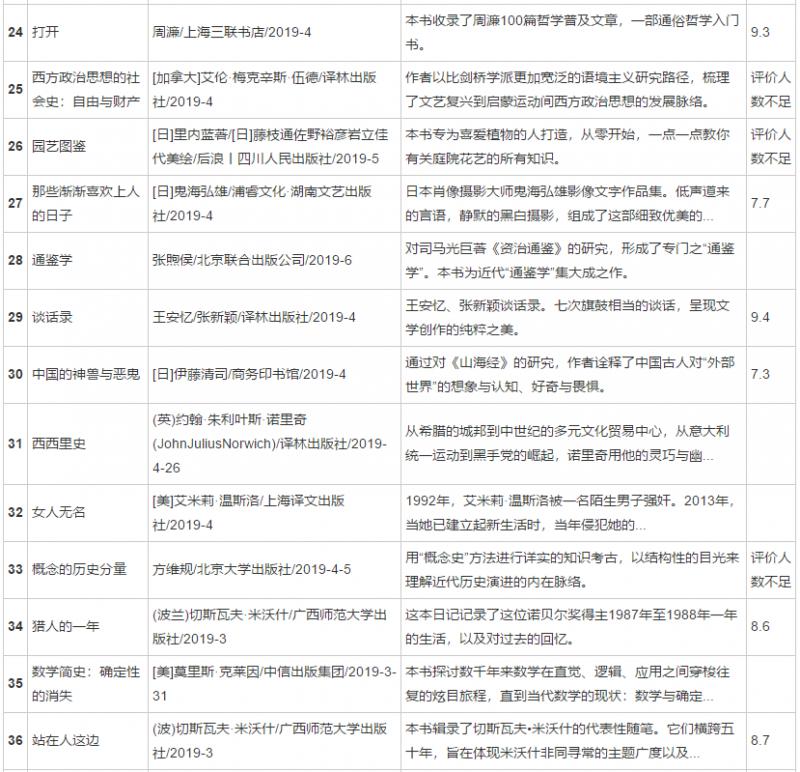
# Label, attribute, element print(soup.a.name,type(soup.a.name)) print(soup.a.attrs,type(soup.a.attrs)) print(soup.a.text,type(soup.a.text)) soup.a.attrs['href'] a <class 'str'> {'href': 'https://accounts.douban.com/passport/login?source=book', 'class': ['nav-login'], 'rel': ['nofollow']} <class 'dict'> //Log in / register < class' STR '> # Find all() → find all tags urls = soup.find('div',class_="grid-12-12 clearfix").find_all('a') url_lst = [] for url in urls[::2]: url_lst.append(url['href']) # Save all URLs print(len(url_lst)) print(url_lst[:5]) 40 ['https://book.douban.com/subject/30475767/', 'https://book.douban.com/subject/30488936/', 'https://book. # Create function and collect page information def get_data(ui): ri = requests.get(url = ui) soupi = BeautifulSoup(ri.text,'lxml') # Visit page + page resolution infors = soupi.find_all('div',class_="detail-frame") lst = [] for i in infors: dic = {} dic['Title'] = i.find('h2').text.replace('\n','') dic['score'] = i.find_all('p')[0].text.replace('\n','').replace(' ','') dic['Other information'] = i.find_all('p')[1].text.replace('\n','').replace(' ','') dic['brief introduction'] = i.find_all('p')[2].text.replace('\n','').replace(' ','') lst.append(dic) return lst # Function build complete url = 'https://book.douban.com/latest' result = get_data(url) # Call function to collect data result[:3]
Output:
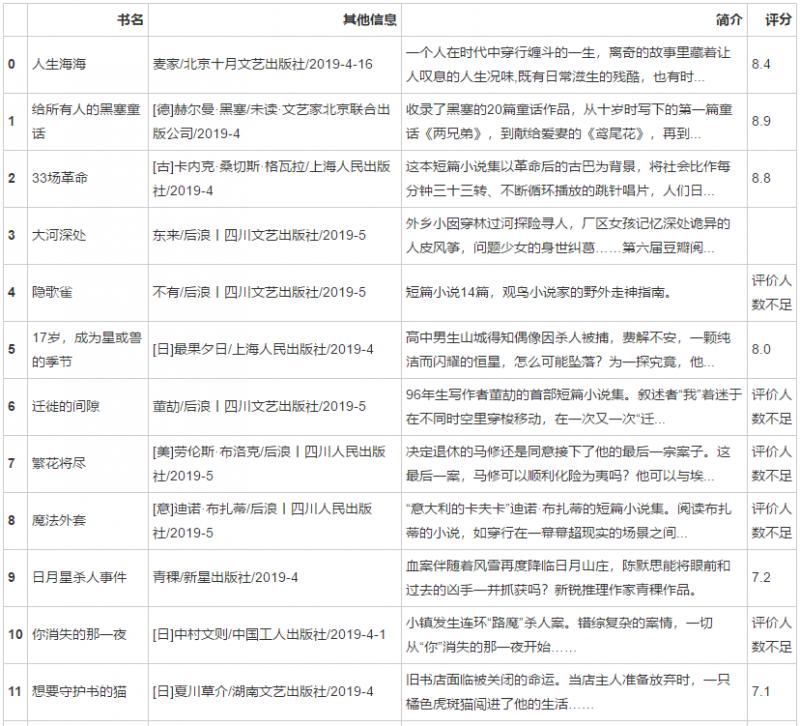
[{'Title': 'Life sea', 'score': '8.4', 'Other information': 'Mai Jia/Beijing October literature and Art Press/2019-4-16', 'brief introduction': 'A person goes through the life of struggle in the era, and there is a sigh of life in the strange story,There is cruelty in daily life, and kindness in time. A new work by the Mai family.'}, {'Title': 'Hesse's fairy tale for everyone', 'score': '8.9', 'Other information': '[Virtue]Herman·Hesse/Unread·Artists Beijing United Publishing Company/2019-4', 'brief introduction': 'It contains 20 fairytale works of Hesse, from the first fairy tale "two brothers" written when he was ten years old, to "iris" dedicated to his wife, and then to "king you of Zhou" from the war drama princes.'}, {'Title': '33 A revolution', 'score': '8.8', 'Other information': '[ancient]Carnegie·Sanchez·Guevara/Shanghai People's Publishing House/2019-4', 'brief introduction': 'This collection of short stories is based on Cuba after the revolution. It compares the society to a thirty-three turn per minute skipping pin record, which is played repeatedly. People are facing material and spiritual difficulties day by day. The author is the grandson of Guevara, the leader of the Cuban revolution.'}]
Data conversion:
# Data transformation - dataframe import pandas as pd df = pd.DataFrame(result) df
result:
Source network, for learning purposes only, invasion and deletion.
Don't panic. I have a set of learning materials, including 40 + E-books, 800 + teaching videos, involving Python foundation, reptile, framework, data analysis, machine learning, etc. I'm not afraid you won't learn! https://shimo.im/docs/JWCghr8prjCVCxxK/ Python learning materials
Pay attention to the official account [Python circle].
