MapReduce actual case, MapTask operation mechanism, ReduceTask operation mechanism, MapReduce execution process, hadoop data compression, implementation of Join algorithm
MapReduce actual case
Reverse order of upstream traffic
- Step 1: define FlowBean to implement WritableComparable to implement comparative sorting
java compareTo method description
The compareTo method is used to compare the current object with the parameters of the method.
Returns 0 if the specified number is equal to the parameter.
Returns - 1 if the specified number is less than the parameter.
Returns 1 if the specified number is greater than the parameter.
For example: o1.compareTo(o2);
If a positive number is returned, the current object (object o1 calling the compareTo method) should be placed after the comparison object (compareTo parameter object o2). If a negative number is returned, it should be placed first.
public class FlowBean implements WritableComparable<FlowBean> { private Integer upFlow; private Integer downFlow; private Integer upCountFlow; private Integer downCountFlow; public FlowBean() { } public FlowBean(Integer upFlow, Integer downFlow, Integer upCountFlow, Integer downCountFlow) { this.upFlow = upFlow; this.downFlow = downFlow; this.upCountFlow = upCountFlow; this.downCountFlow = downCountFlow; } @Override public void write(DataOutput out) throws IOException { out.writeInt(upFlow); out.writeInt(downFlow); out.writeInt(upCountFlow); out.writeInt(downCountFlow); } @Override public void readFields(DataInput in) throws IOException { upFlow = in.readInt(); downFlow = in.readInt(); upCountFlow = in.readInt(); downCountFlow = in.readInt(); } public Integer getUpFlow() { return upFlow; } public void setUpFlow(Integer upFlow) { this.upFlow = upFlow; } public Integer getDownFlow() { return downFlow; } public void setDownFlow(Integer downFlow) { this.downFlow = downFlow; } public Integer getUpCountFlow() { return upCountFlow; } public void setUpCountFlow(Integer upCountFlow) { this.upCountFlow = upCountFlow; } public Integer getDownCountFlow() { return downCountFlow; } public void setDownCountFlow(Integer downCountFlow) { this.downCountFlow = downCountFlow; } @Override public String toString() { return upFlow+"\t"+downFlow+"\t"+upCountFlow+"\t"+downCountFlow; } @Override public int compareTo(FlowBean o) { return this.upCountFlow > o.upCountFlow ?-1:1; } }
- Step 2: define FlowMapper
public class FlowMapper extends Mapper<LongWritable,Text,FlowBean,Text> { Text outKey = new Text(); FlowBean flowBean = new FlowBean(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] split = value.toString().split("\t"); flowBean.setUpFlow(Integer.parseInt(split[1])); flowBean.setDownFlow(Integer.parseInt(split[2])); flowBean.setUpCountFlow(Integer.parseInt(split[3])); flowBean.setDownCountFlow(Integer.parseInt(split[4])); outKey.set(split[0]); context.write(flowBean,outKey); } }
- Step 3: define FlowReducer
public class FlowReducer extends Reducer<FlowBean,Text,Text,FlowBean> { FlowBean flowBean = new FlowBean(); @Override protected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException { context.write(values.iterator().next(),key); } }
- Step 4: program main function entry
public class FlowMain extends Configured implements Tool { @Override public int run(String[] args) throws Exception { Configuration conf = super.getConf(); conf.set("mapreduce.framework.name","local"); Job job = Job.getInstance(conf, FlowMain.class.getSimpleName()); job.setJarByClass(FlowMain.class); job.setInputFormatClass(TextInputFormat.class); TextInputFormat.addInputPath(job,new Path("file:///50: \ \ lesson plan and materials and documents for offline big data - by L ao Wang \ \ 4. The fourth day of offline big data \ \ traffic statistics \ \ output“)); job.setMapperClass(FlowMapper.class); job.setMapOutputKeyClass(FlowBean.class); job.setMapOutputValueClass(Text.class); job.setReducerClass(FlowReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); TextOutputFormat.setOutputPath(job,new Path("file:///50: \ \ lesson plan and material documents for offline stage of big data - by L ao Wang \ \ 4. The fourth day of offline big data \ \ traffic statistics \ \ output port“)); job.setOutputFormatClass(TextOutputFormat.class); boolean b = job.waitForCompletion(true); return b?0:1; } public static void main(String[] args) throws Exception { Configuration configuration = new Configuration(); int run = ToolRunner.run(configuration, new FlowMain(), args); System.exit(run); } }
Cell phone number division
Requirement: separate the mobile phone numbers starting with the following numbers
-
137 data to a partition file
-
138 starting data to a partition file
-
139 starting data to a partition file
-
135 data to a partition file
-
136 starting data to a partition file
-
Other partitions
-
Custom partition:
public class FlowPartition extends Partitioner<Text,FlowBean> { @Override public int getPartition(Text text, FlowBean flowBean, int i) { String line = text.toString(); if (line.startsWith("135")){ return 0; }else if(line.startsWith("136")){ return 1; }else if(line.startsWith("137")){ return 2; }else if(line.startsWith("138")){ return 3; }else if(line.startsWith("139")){ return 4; }else{ return 5; } } }
- Job run add partition settings:
job.setPartitionerClass(FlowPartition.class);
- Change the input and output paths and package them to run on the cluster
TextInputFormat.addInputPath(job,new Path("hdfs://node01:8020/partition_flow/")); TextOutputFormat.setOutputPath(job,new Path("hdfs://node01:8020/partition_out"));
MapTask operation mechanism
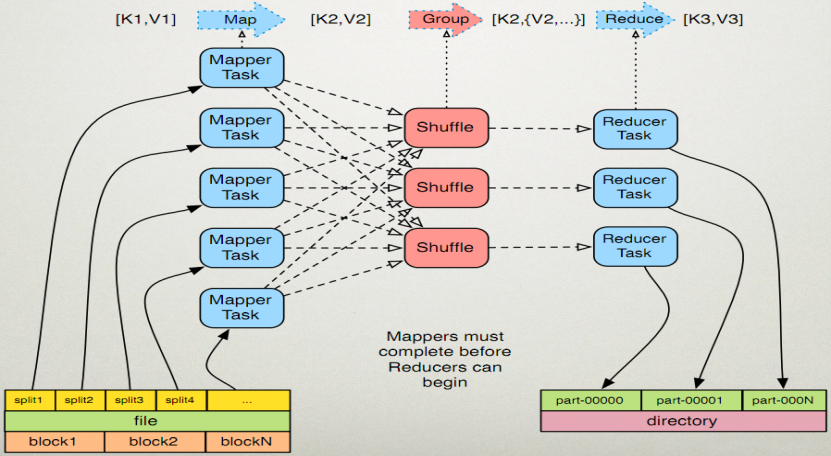
Operation process
1. First of all, InputFormat (default TextInputFormat), the read data component, will logically slice the files in the input directory through the getSplits method to get splits. The number of splits corresponds to the number of maptasks started. The default correspondence between split and block is one-to-one.
2. After the input file is divided into splits, it is read by the RecordReader object (default LineRecordReader). With the separator of \ n, a row of data is read and < key, value > is returned. Key represents the offset value of the first character of each line, and value represents the text content of this line.
3. Read the split and return < key, value >, enter the Mapper class inherited by the user, and execute the map function rewritten by the user. The RecordReader reads a line and calls it here once.
4. After map logic is completed, each result of map is passed through context.write Collect data. In collect, it will be partitioned first, using the HashPartitioner by default.
MapReduce provides the Partitioner interface. Its function is to determine which reduce task the current output data should be handed over to according to the number of keys or value s and reduce. By default, after the key hash is set, the module is based on the number of reduce tasks. The default mode of module fetching is just to average the processing power of reduce. If the user has a demand for the Partitioner, it can be customized and set to the job.
5. Next, the data will be written to memory. This area of memory is called ring buffer. The function of buffer is to collect map results in batch and reduce the impact of disk IO. The results of our key/value pair and Partition will be written to the buffer. Of course, before writing, the key and value values will be sequenced into byte arrays.
The ring buffer is actually an array, in which the serialized data of key and value and metadata information of key and value are stored, including partition, start position of key, start position of value and length of value. Ring structure is an abstract concept.
There is a size limit for the buffer, which is 100MB by default. When there are many output results of map task, the memory may burst, so it is necessary to temporarily write the data in the buffer to disk under certain conditions, and then reuse the buffer. This process of writing data from memory to disk is called Spill, which can be translated into Chinese as overflow. This overflow is done by a separate thread, which does not affect the thread that writes the map result to the buffer. The overflow thread should not block the result output of map when it starts, so there is an overflow ratio in the whole buffer spill.percent . This ratio is 0.8 by default, that is, when the data in the buffer has reached the threshold value (buffer size * spill percent = 100MB * 0.8 = 80MB), the overflow thread starts, locks the 80MB memory, and executes the overflow process. The output results of map task can also be written to the remaining 20MB of memory, without mutual influence.
6. When the overflow thread starts, you need to sort the key s in the 80MB space. Sorting is the default behavior of MapReduce model. Sorting here is also the sorting of serialized bytes.
If the job has set combiner, it's time to use combiner. Add up the values of key/value pairs with the same key to reduce the amount of data overflowing to disk. Combiner optimizes the intermediate results of MapReduce, so it is used multiple times throughout the model.
Which scenarios can I use combiner? From the analysis here, the output of combiner is the input of Reducer, and combiner can never change the final calculation result. Combiner should only be used in scenarios where the input key/value of reduce is exactly the same as the output key/value, and does not affect the final result. Such as accumulation, maximum value, etc. The use of combiner must be careful. If it is used well, it will help the job execution efficiency, otherwise it will affect the final result of reduce.
7. merge overflow file: each overflow will generate a temporary file on the disk (judge whether there is a combiner before writing). If the output result of map is really large, there will be multiple such overflows, and there will be multiple temporary files on the disk. When the whole data processing is finished, the temporary files in the disk are merged. Because there is only one final file, it is written to the disk, and an index file is provided for this file to record the offset of data corresponding to each reduce.
This completes the whole stage of map.
Basic configuration
Some basic settings configuration of mapTask (mapred-site.xml Among them):
Setting 1: set the memory value size of the ring buffer (the default setting is as follows)
mapreduce.task.io.sort.mb 100
Setting 2: set the overflow percentage (the default setting is as follows)
mapreduce.map.sort.spill.percent 0.80
Setting 3: set the overflow data directory (default setting)
mapreduce.cluster.local.dir ${hadoop.tmp.dir}/mapred/local
Setting 4: set the maximum number of overflow files to be merged at one time (the default setting is as follows)
mapreduce.task.io.sort.factor 10
ReduceTask working mechanism
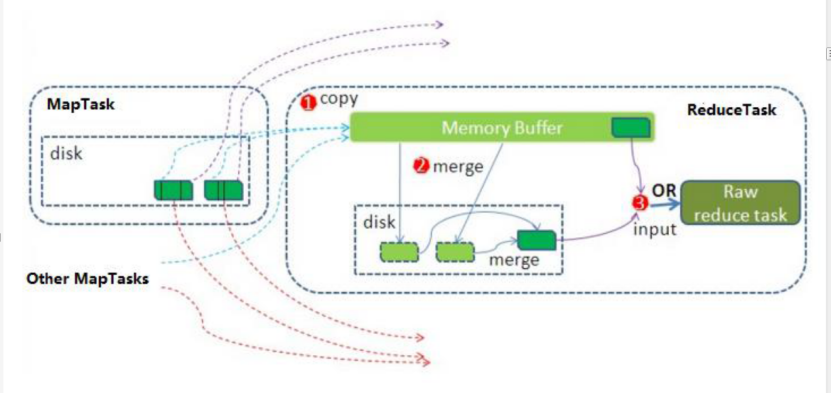
Operation process
Reduce can be roughly divided into three stages: copy, sort and reduce, with the focus on the first two stages. The copy phase contains an eventFetcher to get the completed map list. The Fetcher thread will copy the data. In this process, two merge threads will be started, namely inMemoryMerger and onDiskMerger. The data in memory will be merged into the disk and the data in the disk will be merged. After the data copy is completed, the copy phase is completed and the sort phase is started. The sort phase is mainly to perform the finalMerge operation, which is a pure sort phase. After the completion, the reduce phase is to call the user-defined reduce function for processing.
Detailed steps:
1. In the copy phase, simply pull data. The Reduce process starts some data copy threads (fetchers) and requests the maptask to obtain its own files through HTTP.
2. Merge phase. Here, the merge is like the merge action on the map side, except that the array stores the values copied from different map sides. The copied data will be put into the memory buffer first. The buffer size here is more flexible than that on the map side. There are three forms of merge: memory to memory, memory to disk, and disk to disk. The first form is not enabled by default. When the amount of data in memory reaches a certain threshold, the memory to disk merge is started. Similar to map side, this is also the process of overflow. If you set Combiner in this process, it will also be enabled, and then many overflow files are generated in the disk. The second method of merge runs until there is no map data, and then starts the third method of disk to disk merge to generate the final file.
3. Merge sort. After merging the scattered data into a large data, the combined data will be sorted again.
4. Call the reduce method for the sorted key value pairs, and call the reduce method once for the key value pairs with equal keys. Each call will generate zero or more key value pairs. Finally, write these output key value pairs to the HDFS file.
MapReduce execution process
How to transfer the data processed in the map phase to the reduce phase is the most critical process in the MapReduce framework. This process is called shuffle.
Shuffle: shuffle, licensing - (core mechanism: data partition, sorting, grouping, specification, merging and other processes).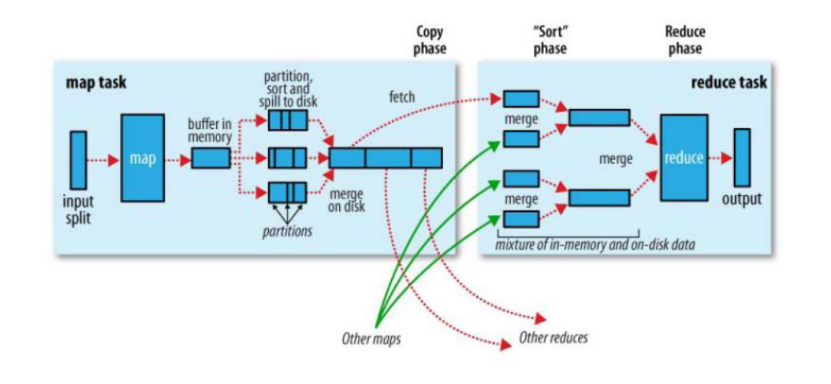
Shuffle is the core of map reduce, which is distributed in the map phase and reduce phase of Mapreduce. Generally speaking, the process from map output to reduce data as input is called shuffle.
1).Collect stage: output the result of MapTask to a ring buffer with the default size of 100M, which stores key/value, Partition partition information, etc.
2).Spill stage: when the amount of data in the memory reaches a certain threshold, the data will be written to the local disk. Before writing the data to the disk, the data needs to be sorted. If the combiner is configured, the data with the same partition number and key will be sorted.
3).Merge stage: merge all overflow temporary files once to ensure that only one intermediate data file is generated by a MapTask.
4).Copy stage: ReduceTask starts the Fetcher thread to copy a copy of its own data on the completed MapTask node. The data will be saved in the memory buffer by default. When the memory buffer reaches a certain threshold, the data will be written to the disk.
5).Merge stage: when ReduceTask remotely copies data, two threads will be opened in the background to merge data files from memory to local.
6).Sort stage: when merging data, sorting operation will be carried out. Because the MapTask stage has sorted the data locally, ReduceTask only needs to ensure the final overall validity of the copied data.
The buffer size in Shuffle will affect the execution efficiency of mapreduce program. In principle, the larger the buffer, the less disk io, and the faster the execution speed
The size of the buffer can be adjusted by parameters: mapreduce.task.io.sort.mb Default 100M
hadoop data compression
There are two advantages of file compression: saving disk space and accelerating data transmission on the network and disk
Using the snappy compression of hadoop to compress our data
Step 1: add configuration to the code
Here we can compress the data by modifying the code
map stage output compression configuration
Configuration configuration = new Configuration(); configuration.set("mapreduce.map.output.compress","true"); configuration.set("mapreduce.map.output.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");
reduce stage output compression configuration
configuration.set("mapreduce.output.fileoutputformat.compress","true"); configuration.set("mapreduce.output.fileoutputformat.compress.type","RECORD"); configuration.set("mapreduce.output.fileoutputformat.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");
Implementation of Join algorithm
Implementation of reduce end join algorithm
Step 1: define our OrderBean
public class OrderJoinBean implements Writable { private String id; private String date; private String pid; private String amount; private String name; private String categoryId; private String price; @Override public String toString() { return id+"\t"+date+"\t"+pid+"\t"+amount+"\t"+name+"\t"+categoryId+"\t"+price; } public OrderJoinBean() { } public OrderJoinBean(String id, String date, String pid, String amount, String name, String categoryId, String price) { this.id = id; this.date = date; this.pid = pid; this.amount = amount; this.name = name; this.categoryId = categoryId; this.price = price; } public String getId() { return id; } public void setId(String id) { this.id = id; } public String getDate() { return date; } public void setDate(String date) { this.date = date; } public String getPid() { return pid; } public void setPid(String pid) { this.pid = pid; } public String getAmount() { return amount; } public void setAmount(String amount) { this.amount = amount; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getCategoryId() { return categoryId; } public void setCategoryId(String categoryId) { this.categoryId = categoryId; } public String getPrice() { return price; } public void setPrice(String price) { this.price = price; } @Override public void write(DataOutput out) throws IOException { out.writeUTF(id+""); out.writeUTF(date+""); out.writeUTF(pid+""); out.writeUTF(amount+""); out.writeUTF(name+""); out.writeUTF(categoryId+""); out.writeUTF(price+""); } @Override public void readFields(DataInput in) throws IOException { this.id = in.readUTF(); this.date = in.readUTF(); this.pid = in.readUTF(); this.amount = in.readUTF(); this.name = in.readUTF(); this.categoryId = in.readUTF(); this.price = in.readUTF(); } }
Step 2: define our map class
public class OrderJoinMap extends Mapper<LongWritable,Text,Text,OrderJoinBean> { private OrderJoinBean orderJoinBean = new OrderJoinBean(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //Distinguish two different files by getting the file name String[] split = value.toString().split(","); FileSplit inputSplit = (FileSplit) context.getInputSplit(); String name = inputSplit.getPath().getName(); System.out.println("Get file name as"+name); if(name.contains("orders")){ //Order data orderJoinBean.setId(split[0]); orderJoinBean.setDate(split[1]); orderJoinBean.setPid(split[2]); orderJoinBean.setAmount(split[3]); context.write(new Text(split[2]),orderJoinBean); }else{ //Commodity data orderJoinBean.setName(split[1]); orderJoinBean.setCategoryId(split[2]); orderJoinBean.setPrice(split[3]); context.write(new Text(split[0]),orderJoinBean); } } }
Step 3: customize the reduce class
public class OrderJoinReduce extends Reducer<Text,OrderJoinBean,OrderJoinBean,NullWritable> { private OrderJoinBean orderJoinBean; @Override protected void reduce(Text key, Iterable<OrderJoinBean> values, Context context) throws IOException, InterruptedException { orderJoinBean = new OrderJoinBean(); for (OrderJoinBean value : values) { System.out.println(value.getId()); //All the objects of the same key are sent here, where the data is spliced completely if(null !=value.getId() && !value.getId().equals("null") ){ orderJoinBean.setId(value.getId()); orderJoinBean.setDate(value.getDate()); orderJoinBean.setPid(value.getPid()); orderJoinBean.setAmount(value.getAmount()); }else{ orderJoinBean.setName(value.getName()); orderJoinBean.setCategoryId(value.getCategoryId()); orderJoinBean.setPrice(value.getPrice()); } } context.write(orderJoinBean,NullWritable.get()); } }
Step 4: develop the main method portal
public class OrderJoinMain extends Configured implements Tool { @Override public int run(String[] args) throws Exception { Job job = Job.getInstance(super.getConf(), OrderJoinMain.class.getSimpleName()); job.setInputFormatClass(TextInputFormat.class); TextInputFormat.addInputPath(job,new Path("file:///F: \ \ podcast course materials in the offline stage of big data \ \ 4. The fourth day of big data offline \ \ map end join\input“)); job.setMapperClass(OrderJoinMap.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(OrderJoinBean.class); job.setReducerClass(OrderJoinReduce.class); job.setOutputKeyClass(OrderJoinBean.class); job.setOutputValueClass(NullWritable.class); job.setOutputFormatClass(TextOutputFormat.class); TextOutputFormat.setOutputPath(job,new Path("file:///F: \ \ podcast course materials in offline stage of big data \ \ 4. The fourth day of big data offline \ \ map end join\out“)); boolean b = job.waitForCompletion(true); return b?0:1; } public static void main(String[] args) throws Exception { ToolRunner.run(new Configuration(),new OrderJoinMain(),args); } }
Implementation of join algorithm at map end
When the reduce end implements the join algorithm, the join operation is completed in the reduce stage. The processing pressure of the reduce end is too large, the operation load of the map node is very low, the resource utilization rate is not high, and the data skew is easily generated in the reduce stage. Therefore, the join algorithm can be solved by implementing the formula of the map end
Principle description
It is applicable to the case that there are small tables in the associated table;
Small tables can be distributed to all map nodes. In this way, map nodes can join the large table data they read locally and output the final results, which can greatly improve the concurrency of join operations and speed up the processing speed
Implementation example
First, define the small table in the mapper class and join
– introduce the solution in the actual scenario: load the database once or use
Step 1: define mapJoin
public class JoinMap extends Mapper<LongWritable,Text,Text,Text> { HashMap<String,String> b_tab = new HashMap<String, String>(); String line = null; /* map The initialization method of the end gets our cache file and loads it into the map at one time */ @Override public void setup(Context context) throws IOException, InterruptedException { //This way, all cache files are obtained // URI[] cacheFiles1 = DistributedCache.getCacheFiles(context.getConfiguration()); Path[] localCacheFiles = DistributedCache.getLocalCacheFiles(context.getConfiguration()); URI[] cacheFiles = DistributedCache.getCacheFiles(context.getConfiguration()); FileSystem fileSystem = FileSystem.get(cacheFiles[0], context.getConfiguration()); FSDataInputStream open = fileSystem.open(new Path(cacheFiles[0])); BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(open)); while ((line = bufferedReader.readLine())!=null){ String[] split = line.split(","); b_tab.put(split[0],split[1]+"\t"+split[2]+"\t"+split[3]); } fileSystem.close(); IOUtils.closeStream(bufferedReader); } @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //Here is the slice data of the map task (on hdfs) String[] fields = value.toString().split(","); String orderId = fields[0]; String date = fields[1]; String pdId = fields[2]; String amount = fields[3]; //Get the product details in the map String productInfo = b_tab.get(pdId); context.write(new Text(orderId), new Text(date + "\t" + productInfo+"\t"+amount)); } }
Step 2: define the main method of program running
public class MapSideJoin extends Configured implements Tool { @Override public int run(String[] args) throws Exception { Configuration conf = super.getConf(); //Note that the cache files here can only be added to the hdfs file system, but not loaded locally DistributedCache.addCacheFile(new URI("hdfs://192.168.52.100:8020/cachefile/pdts.txt"),conf); Job job = Job.getInstance(conf, MapSideJoin.class.getSimpleName()); job.setJarByClass(MapSideJoin.class); job.setInputFormatClass(TextInputFormat.class); TextInputFormat.addInputPath(job,new Path("file:///F: \ \ podcast course materials in the offline stage of big data \ \ 4. The fourth day of big data offline \ \ map end join\map_join_iput")); job.setMapperClass(JoinMap.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputFormatClass(TextOutputFormat.class); TextOutputFormat.setOutputPath(job,new Path("file:///F: \ \ podcast course materials in the offline stage of big data \ \ 4. The fourth day of big data offline \ \ map end join\map_join_output")) ; boolean b = job.waitForCompletion(true); return b?0:1; } public static void main(String[] args) throws Exception { Configuration configuration = new Configuration(); ToolRunner.run(configuration,new MapSideJoin(),args); } }