61. Explain the http protocol
http is an object-oriented protocol belonging to the application layer. Because of its simple and fast way, it is suitable for distributed hypermedia information system.
The main features of HTTP protocol can be summarized as follows:
- Support client / Server Mode
- Simple and fast: when a client requests a service from the server, it only needs to send the request method and path. The common request method lines are GET, HEAD and POST. Each method specifies the type of contact between the client and the server. Due to the simple HTTP protocol, the program scale of HTTP server is small, so the communication speed is very fast.
- Flexible: HTTP allows any type of data object to be transmitted. The type being transferred is marked by content type
- No link: no link means that only one request can be processed per link. After the server processes the customer's request and receives the customer's response, it will disconnect the link. In this way, the transmission time can be saved.
- Stateless: the HTTP protocol is stateless. Stateless means that the protocol has no memory ability for transaction processing. The lack of status means that if the subsequent processing needs the previous information, it must be retransmitted, which may increase the amount of data transmitted per connection. On the other hand, when the server does not need previous information, its response is faster.
62. Explain the HTTP request header and common response status codes.
- Accpet: refers to the MIME file format acceptable to the browser or other customers. It can be used to judge and return the appropriate file format.
- Accpet charset: indicates the character encoding acceptable to the browser. The default value for English browsers is ISO-8859-1
- Accept language: indicates the language type that the browser can accept, such as en or en US, which refers to English.
- Accept encoding: indicates the encoding method acceptable to the browser. The encoding method is different from the file format. It is to compress the file and speed up the file transfer speed. The browser decodes after receiving the Web response. Then check the file format.
- Cache control: set options related to the storage of requests by the proxy server. Usually not.
- Connection: used to tell the server whether it can maintain a fixed HTTP connection. HTTP/1.1 uses keep alive as the default value, so that when the browser needs multiple files (such as an html file and related graphic files), it does not need to establish a connection every time.
- Content type: used to indicate the content type of the request, which can be obtained by getContentType () method of HttpServiceRequest.
- cookie: the browser uses this property to send cookies to the server. cookie is a small data body accumulated in the browser. It can record the user information related to the server, and can also be used to realize the session function.
The status code consists of three digits. The first digit defines the category of response. And there are five possible values:
- 1xx: instruction information - indicates that the request has been rejected and continues to be processed
- 2xx: successful - indicates that the request has been successfully accepted, understood and accepted
- 3xx: redirection - further erasure is necessary to complete the request
- Request 4xx has syntax error - Request 4xx cannot be implemented
- 5xx: server side error - the server failed to implement the legal request
Common status codes, status descriptions and descriptions:
- 200 ok. / / the client request succeeds
- 400 bad request / / there is a syntax error in the client request, which cannot be understood by the server
- 401 # unauthorized / / the request is not authorized. This status code must be used with the WWW authenticate header field
- 403 forbiden. / / the service received the request but refused to provide the service
- 404 Not found. / / the requested resource does not exist, eg: wrong url entered
- 500 Internal Server Error. / / unexpected error occurred on the server
- 503. Server Unavaliable. / / the server cannot process the client's request at present. It may return to normal after a period of time.
63. Please briefly explain the function of view in data
- The database view hides the complexity of the data
- The database view helps to control users' access to some columns in the table
- Database views make user queries simple.
64. List the network data packets used by the python web crawler you have used
requests, urllib, and so on.
65. List the parsing packets used by Python web crawlers you have used
Beautiful Soup pyquey. Xpath. lxml.
65. What does enumerate mean in python?
For an iteratable / traversable object, enumerate forms it into an index sequence, which can be used to obtain the index and value at the same time. Enumerate is mostly used for the count obtained in the for loop.
66. Use of timed tasks under unix
67. Write out the solution to the anti crawler problem encountered in the process of web crawler crawling data:
- Anti crawler through header: solution strategy, forge headers
- Anti crawler based on user behavior: crawling data dynamically to simulate the behavior of ordinary users
- Anti crawler based on dynamic pages: track ajax requests sent by the server and simulate ajax requests.
68. Read the following code. What is its output?
class Node(object):
def __init__(self, sName):
self._lChildren = []
self.sName = sName
def __repr__(self):
"""
Display properties
:return:
"""
return "<Node '{}'>".format(self.sName)
def append(self, *args, **kwargs):
self._lChildren.append(*args, **kwargs)
def print_all_1(self):
"""
Depth first
:return:
"""
print(self)
for oChild in self._lChildren:
oChild.print_all_1()
def print_all_2(self):
"""
Breadth first
:return:
"""
def gen(o):
lAll = [o, ]
while lAll:
oNext = lAll.pop(0)
lAll.extend(oNext._lChildren)
yield oNext
for oNode in gen(self):
print(oNode)
oRoot = Node("root") # self.sName = root
oChild1 = Node("child1") # self.sName = child1
oChild2 = Node("child2") # self.sName = child2
oChild3 = Node("child3") # self.sName = child3
oChild4 = Node("child4") # self.sName = child4
oChild5 = Node("child5") # self.sName = child5
oChild6 = Node("child6") # self.sName = child6
oChild7 = Node("child7") # self.sName = child7
oChild8 = Node("child8") # self.sName = child8
oChild9 = Node("child9") # self.sName = child9
oChild10 = Node("child10") # self.sName = child10
oRoot.append(oChild1)
oRoot.append(oChild2)
oRoot.append(oChild3)
# oRoot: sname = root_ lChildren = [child1,child2,child3]
oChild1.append(oChild4)
oChild1.append(oChild5)
# sName = child1 ,_lChildren = [child4,child5]
oChild2.append(oChild6)
# sName = child2, _lChildren = [child6]
oChild4.append(oChild7)
# sName = child4, _lChildren = [child7]
oChild3.append(oChild8)
oChild3.append(oChild9)
# sName = child3,_lChildren = [child8,child9]
oChild6.append(oChild10)
# sName = child6 _lChildren = [child10]
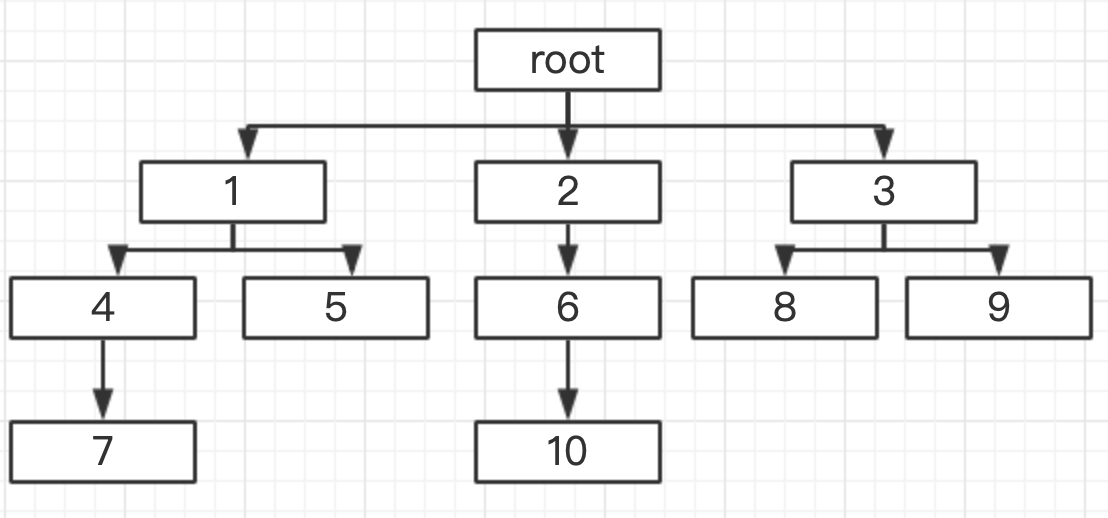
# Explain the output of the following code
# oRoot sName = root
# _lChildren = [[sName=child1,child4&7,child5],[sName=2,child6&child10],[sName = 3,child8,child9]]
# oRoot.print_all_1()
oRoot.print_all_2()You can draw such a diagram to calculate:
data structure
69. Red black tree
Comparison between red black tree and AVL:
AVL is a strictly balanced tree, so when adding or deleting nodes, according to different situations, the number of rotations is more than that of red black tree;
Red and black are used for non strict balance in exchange for reducing the number of rotations when adding and deleting nodes
So simply put, if the number of searches in your application is much greater than the number of inserts and deletions, choose AVL. If the number of inserts and deletions is almost small, you should choose RB.
70. Step problem / Fibonacci
A frog can jump up one step or two steps at a time. How many ways does the frog jump up a n-level step.
fib = lambda n:n if n<=2 else fib(n-1)+fib(n-2)
The second method:
def memo(func):
cache = {}
def wrap(*args):
if args not in cache:
cache[args] = func(*args)
return cache[args]
return wrap
@memo
def fib(i):
if i < 2:
return 1
return fib(i - 1) + fib(i - 2)
print(fib(2))
The third method:
def fib(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a + b
return b
print(fib(4))71. Abnormal steps
A frog can jump up one step or two steps at a time... It can also jump up n steps. How many jumping methods does the frog jump up an n-step
fib = lambda n: n if n < 2 else 2 * fib(n - 1)
72. Rectangular coverage
We can use 2 * 1 small rectangles to cover the largest rectangle horizontally or vertically. How many methods are there to cover a 2*n giant star with N 2 * 1 small rectangles without overlap?
The covering method of the 2nd * nth rectangle is equal to the method of the 2nd * (n-1) plus the 2nd * (n-2).
f = lambda n: 1 if n < 2 else f(n - 1) + f(n - 2)
73. Young's matrix search
In a two-dimensional array of m rows and n columns, each row is sorted in ascending order from left to right, and each column is sorted in ascending order from top to bottom. Please complete a function, input such a two-dimensional array and an integer, and judge whether the array contains the integer.
74. Remove duplicate elements from the list
Use set
list(set(L))
Use a dictionary
The fromkeys() function of Python dictionary is used to create a new dictionary. The elements in the sequence ¢ seq ¢ are used as the keys of the dictionary, and value ¢ is the initial value corresponding to all keys of the dictionary.
l1 = ['b', 'c', 'd', 'b', 'c', 'a', 'a']
l2 = {}.fromkeys(l1).keys()
print(l2, {}.fromkeys(l1))
# Output results
# dict_keys(['b', 'c', 'd', 'a']) {'b': None, 'c': None, 'd': None, 'a': None}
Use the dictionary and keep the order
l1 = ['b','c','d','b','c','a','a'] l2 = list(set(l1)) l2.sort(key=l1.index) print (l2)
Sort then delete
l1 = ['b','c','d','b','c','a','a'] l2 = [] [l2.append(i) for i in l1 if i not in l2] print(l2)
75. Method of creating dictionary
# Create directly
dict1 = {'name': 'earth', 'port': '80'}
# Factory method
items = [('name', 'earth'), ('port', '80')]
dict2 = dict(items)
dict3 = dict((['name', 'earth'], ['port', '80']))
print(dict3)
# fromkeys
dict5={}.fromkeys(('x','y'),-1)
dict ={'x':-1,'y':-1}
dict4={}.fromkeys(('x','y'))
# dict4={'x':None, 'y':None}
print(dict5,dict4)
# Output results
{'name': 'earth', 'port': '80'}
{'x': -1, 'y': -1} {'x': None, 'y': None}Django
76. Briefly talk about the development of Django's ORM?
<1> all(): Query all results
<2> filter(**kwargs): It contains objects that match the given filter criteria. Cannot get return None
<3> get(**kwargs): There is only one object that matches the filter criteria and returns only one result.
If there are more than one or no objects that meet the filter criteria, an error will be thrown.
<4> exclude(**kwargs): It contains objects that do not match the given filter criteria
<5> order_by(*field): Sort query results
<6> reverse(): Reverse sort query results
<8> count(): Returns the matching query in the database(QuerySet)Number of objects.
<9> first(): Return to the first record
<10> last(): Returns the last record
<11> exists(): If QuerySet If it contains data, it returns True,Otherwise return False
<12> values(*field): Return a ValueQuerySet-A special QuerySet,Obtained after operation
Not a series model Instead of an instantiated object, it is an iterative dictionary sequence
<13> values_list(*field): It and values()Very similar. It returns a tuple sequence, values Returns a dictionary sequence
<14> distinct(): Eliminate duplicate records from the returned results77. Briefly talk about Restful framework
78. Briefly describe how your Django is deployed on the server
79. How do you separate the front and rear ends? What is coupled development? What is uncoupled development?
80. How does django implement cross domain access requests?
When did you use the Web Models method?
82. What are the advantages and disadvantages of django?
advantage:
- Perfect functions and complete elements: it comes with a large number of common tools and frameworks for enterprise Web development (such as paging, auth and permission management), which is suitable for the rapid development of enterprise level websites.
- Perfect documents: after more than ten years of development and improvement, Django has a wide range of practical cases and perfect online documents. When developers encounter problems, they can search online documents for solutions.
- Powerful database access component: the ORM component of the database in Django's Model layer enables developers to operate the database without learning SQL language.
- DJango's advanced APP design concept: APP is pluggable, which is a rare meaning. No, you can delete it directly, which has little impact on the whole system.
- Built in station management system admin: a complete background data management and control platform can be realized only through a few lines of configuration and code.
Disadvantages:
- Take care of everything: Django also includes functional modules that are not needed for some lightweight applications. It is not as light as Flask.
- Over encapsulation: many classes and methods encapsulate classes, which is relatively simple to use directly, but it is difficult to change.
- Performance disadvantage: compared with c and c + +, Django's performance is low. Of course, this is Pyrhon's pot. Other Python frameworks will have the same problem when the traffic comes up.
- Template function: django's template implements the complete separation of class code and style. Python code is not allowed in the template. Flexibility may not be enough for some programmers.
83. Let's talk about Django's request life cycle
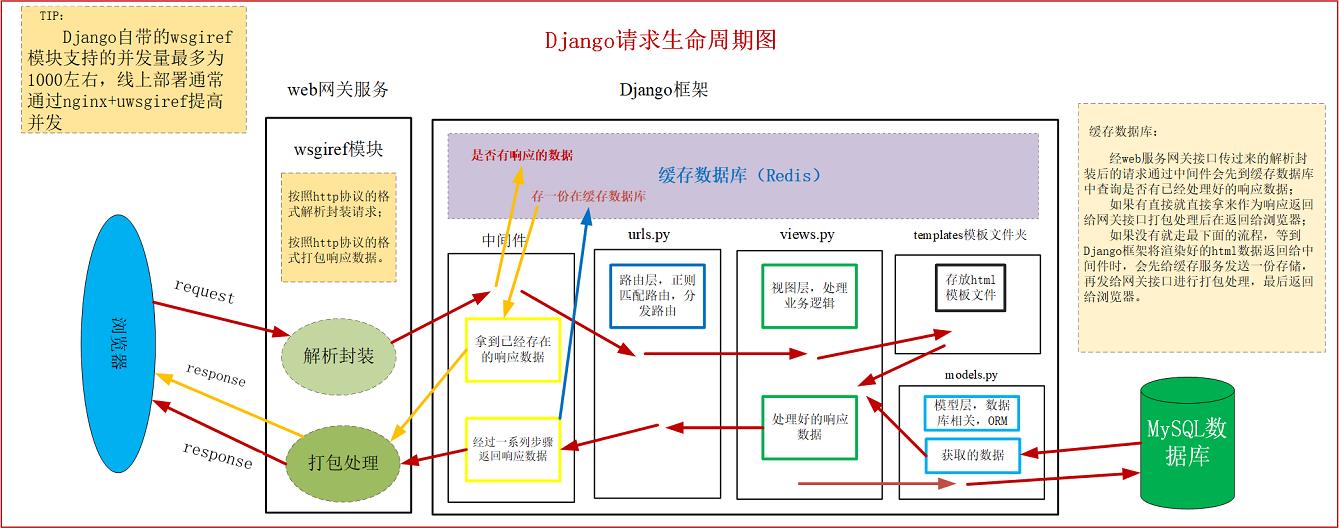
be careful ⚠️: The most important thing is that answering the user's request does not achieve the corresponding view all at once through URL matching, and the returned data is not returned to the user all at once. There are layers of Middleware in the middle. For details, please see your own blog Learning of django Middleware
List five methods of django middleware? And the application scenario of django middleware
- .process_request: authority authentication when the request comes in
- .process_view: after route matching, the view function can be obtained
- .process_exception: execute in case of exception
- .process_template_responseprocess: executed when the template is rendered
- .process_response: execute when the request has corresponding
84. Please list several methods commonly used in django orm to obtain data query sets
Common methods include filter and exculde methods. String fuzzy matching can use icontains,in and other methods.
85. What are the features of django's Queryset
Django's QuerySet has two main features:
- Inert.
- Built in cache.
For example: in the following example, article_ The list view queries a list of all articles with django in the title from the database:
article_list = Article.objects.filter(title__contains="django")
When we define article_list, Django's data interface queryset does not query the database. No matter how many filter conditions you add, Django will not query the database. Only when you need to be on the article_ Django will really execute the query on the database only when the list performs further operations (such as printing the query result, judging whether it exists, and counting the length of the query result). This process is called the execution of queryset.
Django is designed to minimize invalid operations on the database, such as querying results instead of a great waste of computing resources.
# example 1
for article in article_list:
print(article.titleIn example 1, when you traverse the querset(article_list), all matching records will be obtained from the database. These results are loaded into memory and saved in the built-in cache of queryset. In this way, if you are convenient or read this article again_ List, Django does not need to query repeatedly, which can also reduce the query to the database.
# Example 2: Good
article_list = Article.objects.filter(title__contains="django")
for article in article_list:
print(article.title)
# Example 3: Bad
for article in Article.objects.filter(title__contains="django"):
print(article.title)
# Example 4: Good -- if will lead to article_list execution
article_list = Article.objects.filter(title__contains="django")
if article_list:
for article in article_list:
print(article.title)
else:
print("No records")If you do not need to execute the article_list, you can use the exists() method. It will only check whether the query result exists and return True or False, instead of caching article_list.
# Example 5: Good
article_list = Article.objects.filter(title__contains="django")
if article_list.exists():
print("Records found.")
else:
print("No records")count method is preferred for counting the number of query results.
Both len() and count() can count the number of query results. Generally speaking, count will be faster, because it directly obtains the number of query results from the database level, rather than returning the whole data set. Len will lead to the execution of queryset, and its length can be counted only after the whole queryset is loaded into memory.
# Example 6: Good
count = Article.objects.filter(title__contains="django").count()
# Example 7:Bad
count = Article.objects.filter(title__contains="django").len()
# Example 8: Good
article_list = Article.objects.filter(title__contains="django")
if article_list:
print("{} records found.".format(article_list.len()))When the queryset is very large, the data is fetched on demand
When the queried queryset is very large, it will occupy a lot of memory. We can use values and value_ The list method extracts data on demand.
# Example 9: Good
article_list = Article.objects.filter(title__contains="django").values('title')
if article_list:
print(article.title)
article_list = Article.objects.filter(title__contains="django").values_list('id', 'title')
if article_list:
print(article.title)Please use the update method to update some fields in the database (the number of update entries will also be returned)
If you need to update some existing data or some word short in the database, you'd better use update instead of save.
In example 10, the data of the whole Article object needs to be extracted first, cached in memory, and written to the database after changing the information.
In example 11, the title is updated directly without loading the data of the whole article object into memory, which is obviously more efficient.
# Example 10: Bad article = Article.objects.get(id=10) Article.title = "Django" article.save() # Example 11: Good Article.objects.filter(id=10).update(title='Django')
Use the explain method professionally
It can count the execution time consumed by a query, which can help programmers better optimize the query results.
print(Blog.objects.filter(title='My Blog').explain(verbose=True)) # output Seq Scan on public.blog (cost=0.00..35.50 rows=10 width=12) (actual time=0.004..0.004 rows=10 loops=1) Output: id, title Filter: (blog.title = 'My Blog'::bpchar) Planning time: 0.064 ms Execution time: 0.058 ms
86. What are function based view (FBV) and class based view (CBV) and their disadvantages
FBV uses functions to process requests in the view. CBV is to use classes to process requests in the view. CBV has two main advantages:
- It improves the reusability of code, and can use object-oriented technology, such as Mixin
- Different functions can be used to deal with different HTTO methods, rather than judging by many if methods, so as to improve the readability of the code.
87. How to use decorator for class based view CBV
Need Django Method of utils module_ It also supports the list of decorators, as shown below:
from django.utils.decorators import method_decorator
decorators = [login_required, check_user_permission]
@method_decorator(decorators, name='dispatch')
class ArticleCreateView(CreateView):
model = Article
form_class = ArticleForm
template_name = 'blog/article_manage_form.html'
# 1. Add:
@method_decorator(check_login)
def post(self, request):
# 2. Add to the dispatch:
@method_decorator(check_login)
def dispatch(self, request, *args, **kwargs):88. Can you list some ways to reduce the number of database queries?
- Make use of the inertia of django queryset and the characteristics of its own cache
- Using select_related and prefetch_ The related method performs the join operation in the database
- Use cache
89. What are the methods of model inheritance in Django? What are the differences between them and when to use them?
- Abstract model inheritance
- Multi table model inheritance
- surrogate model
The differences are as follows:
- django does not generate its own data tables in the database for abstract models. abstract = True in the parent class Meta will not be passed to the child class. If you find that multiple models have many common fields, you need to use abstract model inheritance.
- The biggest difference between multi table model inheritance and abstract model inheritance is that Django will also establish its own data table for the parent model, and implicitly resume a one-to-one relationship between the parent and child classes
- If we just want to change the behavior of a model. Instead of adding additional short words or creating additional data tables, we can use the proxy model. To set a proxy model, you need to set proxy = true in the Meta option of the subclass model. Django will not generate a new data table for the proxy model.
90. How to customize template labels and filters?
First, you need to create a new templatetags file in your App directory. See (can't take another name), which must contain__ init__.py. In this directory, you can also create a new python file to store your customized template label functions, for example:
blog/
__init__.py
models.py
templatetags/
__init__.py
blog_extras.py
views.pyWhen using a custom template label in the template, you need to first load the custom filter with {% load blog_extras%} and then use it through {% tag_name%}.
give an example
We will define three simple template tags, one will return a string, one will pass variables to the template context, and one will display the rendered template. We're on the blog_extra.py add the following code.
#blog_extra.py
from django import template
import datetime
from blog.models import Article
register = template.Library()
# use simple tag to show string
@register.simple_tag
def total_articles():
return Article.objects.filter(status='p').count()
# use simple tag to set context variable
@register.simple_tag
def get_first_article():
return Article.objects.filter(status='p').order_by('-pub_date')[0]
# show rendered template
@register.inclusion_tag('blog/latest_article_list.html')
def show_latest_articles(count=5):
latest_articles = Article.objects.filter(status='p').order_by('-pub_date')[:count]
return {'latest_articles': latest_articles, }91. List the built-in components of django?
- . admin is a component provided for adding, deleting, modifying and querying the corresponding data table in the model
- . model component. Responsible for operating the database
- . form component: 1. Generate HTML code. 2. Data validity verification. 3. Verification information is returned and displayed
- . ModelForm component: used not only for database operation, but also for user requested authentication.
92. When was the request object of django created?
class WSGIHandler(base.BaseHandler):
request = self.request_class(environ)When the request goes to the WSGIHandler class, execute the cell method and encapsulate the environ into a request.
93,select_related and prefetch_ The difference between related?
Premise: when foreign keys exist, it can reduce the number of data requests and improve performance.
- select_related through multi table join Association query, all data can be obtained at one time and SQL query can be executed only once
- prefetch_related queries each table separately, then processes it according to the relationship between them, and executes the query twice.
94. List three methods in django ORM that can write SQL statements
1.use execute Execute custom SQL
Direct execution SQL Statement (similar to pymysql (usage of)
# Execute native SQL statements in a more flexible way
from django.db import connection
cursor = connection.cursor()
cursor.execute("SELECT DATE_FORMAT(create_time, '%Y-%m') FROM blog_article;")
ret = cursor.fetchall()
print(ret)
2.use extra method: queryset.extra(select={"key": "Native SQL sentence"})
3.use raw method
1.Execute original sql And return to the model
2.rely on model Mostly used for query95. Difference between cookie and session
- Cookie: a cookie is a key value pair stored in the browser and can be used for user authentication
- Session: save the user's session information on the server. The key value is the randomly generated string, and the value value is the content of the session. Depending on the cookie, save each user's random string to the user's browser
- Django session is saved in the database by default: django_session table
- Flash, session writes the encrypted data in the user's cookie by default.
96. How to use django orm to create data in batch?
objs = [models.Book(title="library{}".format(i+15)) for I in range(100)]\
models.Book.objects.bulk_create(objs)97. In django's Form component, if the field contains the choices parameter, please use two ways to update the data source in real time:
- 1. Rewrite constructor
def__init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.fields["city"].widget.choices = models.City.objects.all().values_list("id", "name")
- 2. Using the ModelChoiceField field, the parameter is queryset object
authors = form_model.ModelMultipleChoiceField(queryset=models.NNewType.objects.all()) / / multiple choices
98. On in the ForeginKey field in django's Model_ What is the function of the delete parameter
- When deleting the data in the associated table, the operation of the current table and its associated field
- After django 2.0, when associating tables, you must write on_delete parameter, otherwise an exception will be reported.
99. Self defined filter and simple in Django's self template_ Tag difference
- Custom filter: {{parameter 1 | filter function name: parameter 2}}
- Can be used with the if tag
- Two formal parameters need to be written during customization
Example: Custom filter
1. stay app01 The next one is called templatetags of Python package
2. stay templatetags Create under folder py file myfilters
3. stay py Write code in the file
from django import template
register = template.Library()
@register.filter
def add_sb(value,arg='aaa'):
return "{}_sb_{}".formart(value,arg)
@register.filter(name='sb')
def add_sb(value,arg='aaa'):
return "{}_sb_{}".formart(value,arg)
4. Use custom filter
{% load myfilters %}
{{ name|add_sb:'xxx'}}
{{ name|sb:'xxx'}}
- simple_ Tag: {% simple_tag function name parameter 1 Parameter 2%}
- Multiple parameters can be passed without limitation
- Cannot be used with if tag
Example: Custom simpletag
establish
1 ,stay app01 Create a name in templatetags My bag,
2,Create one in the package py file
3,stay py Import from file
from django import template
register = template.Library()
4,Write function
@register.simple_tag(name="plus")
def plus(a,b,c):
return '{}+{}+{}'.format(a,b,c)
5,Add decorator@register.simple_tag(name="plus")
use
1,Import
{% load mytag %}
2,use
{% plus 1 2 3 %}100. Implementation mechanism of csrf in django
- Step 1: the first time django responds to a request from a client, the back end randomly generates a token value and saves the token in the SESSION state; At the same time, the back-end puts the token into the cookie and gives it to the front-end page.
- Step 2: the next time the front end needs to initiate a request (such as posting), add the token value to the request data or header information and send it to the back end together; Cookies:{csrftoken:XXX}
- Step 3: the back-end verifies whether the token brought by the front-end request is consistent with the token in the session.
101. What method can be used to carry CSRF when sending post requests using ajax based on django_ token?
- The back-end sends the csrftoken to the front-end, and carries this value when sending the post request
data: { csrfmiddlewaretoken: '{{ csrf_token }}' }, - Get the csrftoken value of the hidden tag in the form, add it to the request data and send it to the back end
data: { csrfmiddlewaretoken:$('[name="csrfmiddlewaretoken"]').val() }, - There is a csrftoken in the cookie. Put the csrftoken value into the request header.
headers:{ "X-CSRFtoken":$.cookie("csrftoken")}102. django itself carries runserver. Why can't it be deployed? (the difference between runserver and uWSGI)
- The runserver method is often used when debugging Django. It uses the WSGI Server provided by Django to run. It is mainly used in testing and development, and the runserver is opened in a single process.
- Uwsgi is a web server, which implements WSGI protocol, uwsgi, http and other protocols. Note that uwsgi is a communication protocol, and uwsgi is a web server that implements uwsgi protocol and WSGI protocol. Uwsgi has the advantages of ultra fast performance, memory occupation and multi app management. In addition, it is a production environment combined with Nginx. It can isolate user access requests from application apps and realize real deployment. In contrast, it supports a higher amount of concurrency, which is convenient to manage multiple processes, give full play to the advantages of multi-core and improve performance.
103. Describe the performance optimization of Web projects from the front end, back end and database respectively
Front end optimization:
- Reduce http requests, such as making sprites
- HTML and CSS are placed at the top of the page and JavaScript is placed at the bottom of the page. Because js loading is slower than HTML and CSS loading, HTML and CSS should be loaded first to prevent incomplete page display, poor performance and affecting the user experience.
Back end optimization:
- The cache stores data with high write times and few changes, such as the information on the home page of the website, the information of commodities, etc. When an application reads data, it usually reads it from the cache first. If it cannot be read or the data has expired, it accesses the disk database and writes the data to the cache again.
- Asynchronous mode. If there are time-consuming operations, asynchronous mode can be adopted, such as celery
- Code optimization to avoid too many cycles and judgments. If multiple if else judgments are made, the most likely situation will be judged first.
Database optimization
- If possible, the data is stored in redis, and the reading speed is fast
- Resume index, foreign key, etc.
Thank you for the following websites 🙏🙏🙏
Link: https://www.jianshu.com/p/724233387ba3