catalogue
why do you need interpreter mode
how to implement interpreter mode
Classic case of open source framework
Analysis of RoleMapperExpression expression of Elasticsearch
Meal: ASTNode version evolution in ShardingSphere
Comparison of advantages and disadvantages
what is interpreter mode
Gof definition: given a language, define a representation of its grammar, and define an interpreter that uses the representation to interpret sentences in the language.
HeadFirst definition: when you need to implement a simple language, use the Interpreter pattern to define the syntax class, and use an interpreter to interpret the sentence. Each syntax rule is represented by a class.
Almost all related to SQL and DSL are inseparable from the Expression mode, but there are differences in rules and grammatical meanings, such as Elasticsearch Analysis of DSL, ShardingSphere and mybatis – MyBatis 3 Parsing of SQL.
why do you need interpreter mode
To tell you the truth, this should be the least design mode I use. It can only be used when I formulate grammar rules. I remember that there are only two times in my work. One is the ant report submission mode, which involves complex retrieval and sorting rules. Therefore, I have customized a set of grammar and used the standard interpreter mode for interpretation. In addition, a DSL compatible with Explorer, Elasticsearch and Odps syntax is customized, which also uses the interpreter mode.
The explanation of GOF design pattern is applied here:
If the frequency of a particular type of problem is high enough, it may be worth expressing each instance of the problem as a sentence in a simple language. In this way, you can build an interpreter that solves the problem by interpreting these sentences. For example, searching for strings that match a pattern is a common problem. Regular expression is a standard language for describing string patterns. Instead of constructing a specific algorithm for each pattern, it is better to use a general search algorithm to interpret and execute a regular expression that defines the set of strings to be matched. The Interpreter pattern describes how to define a grammar for a simple language, how to represent a sentence in the language, and how to interpret these sentences. The interpreter design pattern describes how to define a grammar for a regular expression, how to represent a specific regular expression, and how to interpret the regular expression.

The Interpreter pattern uses classes to represent each grammar rule. The symbol to the right of the rule is the instance variable of these classes. The above grammar is represented by five classes: an abstract class RegularExpression and its four subclasses LiteralExpression, AlternationExpression, SequenceExpression and RepetitionExpression. The variables defined by the last three classes represent subexpressions.
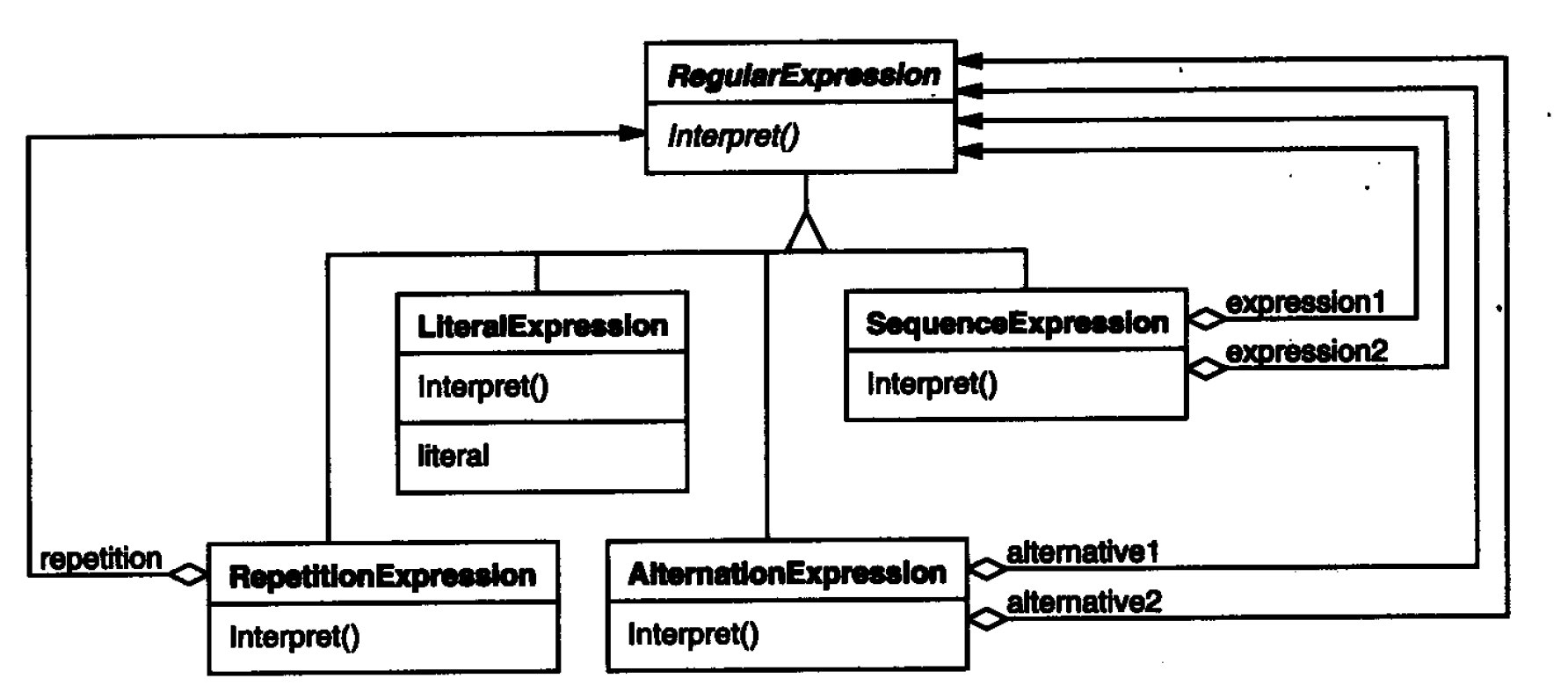
Each regular expression defined with this grammar is represented as an abstract syntax tree composed of instances of these classes. For example, Abstract syntax tree: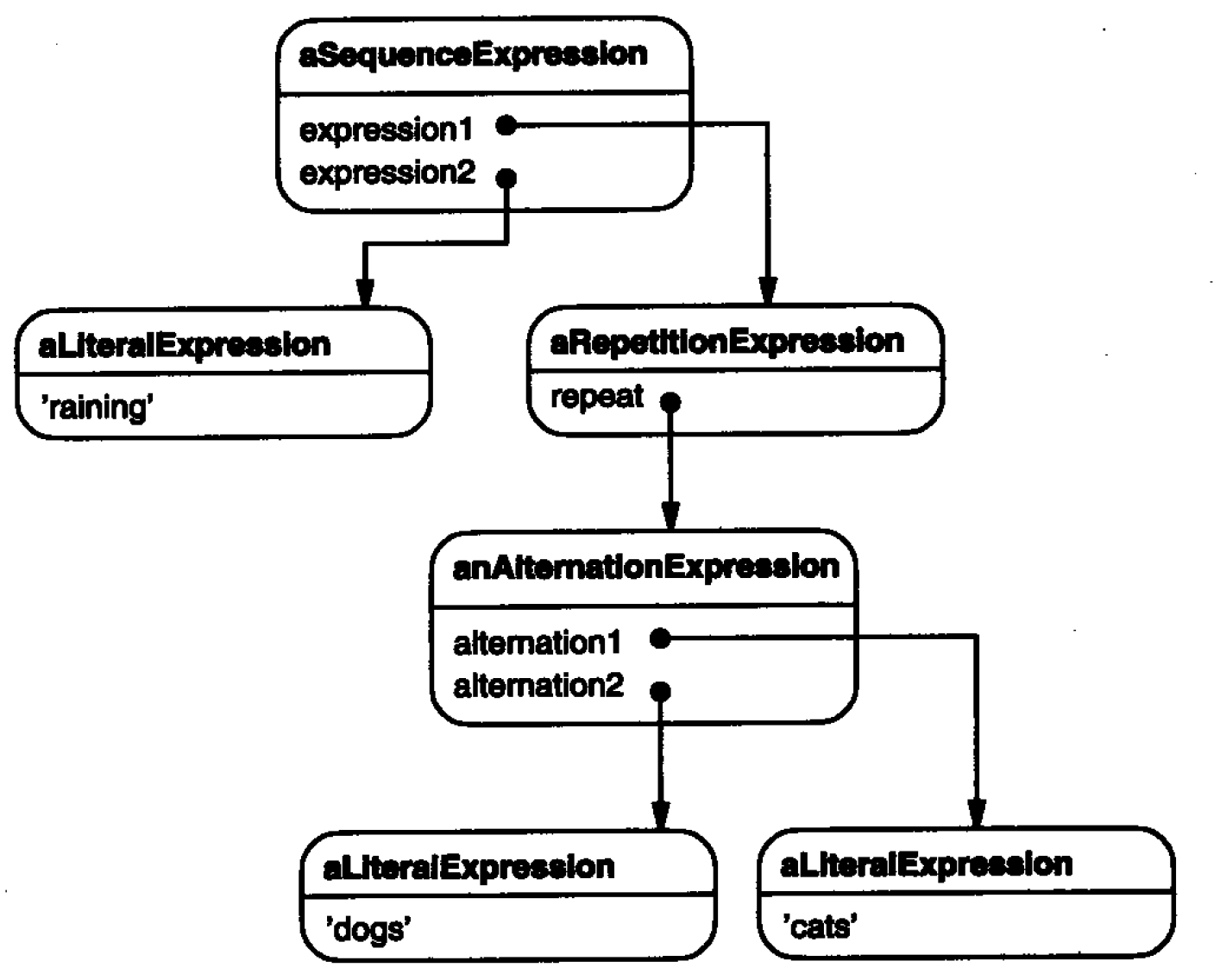
how to implement interpreter mode
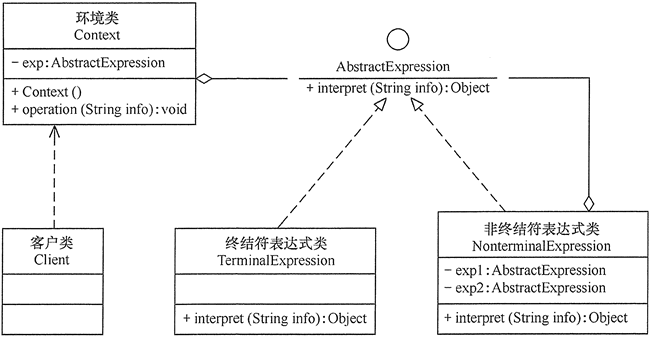
The Interpreter pattern contains the following main roles.
- Abstract Expression role: defines the interface of the interpreter and specifies the interpretation operation of the interpreter, mainly including the interpretation method interpret().
- Terminator expression (Terminal) Expression role: it is a subclass of abstract expression, which is used to realize the operations related to terminators in grammar. Each terminator in grammar has a specific terminator expression corresponding to it.
- Non terminal expression role: it is also a subclass of abstract expression, which is used to realize the operations related to non terminal in grammar. Each rule in grammar corresponds to a non terminal expression.
- Context role: it usually contains the data or public functions required by each interpreter. It is generally used to transfer the data shared by all interpreters. Subsequent interpreters can obtain these values from here.
- Client (Client): the main task is to translate the sentences or expressions that need analysis into the abstract syntax tree described by the interpreter object, then invoke the interpreter's interpretation method, and of course, can indirectly access the interpreter's interpretation method through the role of the environment.
Classic case of open source framework
EL expressions in Spring
Spring has its own set of EL expressions. Springel and spiel are powerful and concise ways to assemble beans. They can assemble values into our Properties or constructors through the expressions executed during runtime. They can also call the static constants provided in the JDK to obtain the configuration in the external Properties file. It supports querying and manipulating objects at runtime, but provides more extended functions, such as method calls and string templates. Spring el expressions support the following functions:
- Literal expression
- boolean and relational operators
- regular expression
- Class expression
- Access properties, arrays, collections
- Method call
- Relational operation
- Call constructor
- Bean reference
- Build array
- Inline list
- Inline map
- Ternary operation
- variable
- User defined function
- Set selection
- Template expression
For the entry of SpringEl expression, see if it feels like an interpreter and how to parse it. Because it is too long, it will not be described in detail here. You can take a detailed look at the InternalSpelExpressionParser class.
public class SpelExpressionParser extends TemplateAwareExpressionParser {
private final SpelParserConfiguration configuration;
public SpelExpressionParser() {
this.configuration = new SpelParserConfiguration();
}
public SpelExpressionParser(SpelParserConfiguration configuration) {
Assert.notNull(configuration, "SpelParserConfiguration must not be null");
this.configuration = configuration;
}
public SpelExpression parseRaw(String expressionString) throws ParseException {
return this.doParseExpression(expressionString, (ParserContext)null);
}
EL Expression parsing entry
protected SpelExpression doParseExpression(String expressionString, ParserContext context) throws ParseException {
return (new InternalSpelExpressionParser(this.configuration)).doParseExpression(expressionString, context);
}
}
InternalSpelExpressionParser Core processing logic
private SpelNodeImpl eatExpression() {
Get the expression structure, similar to a tree structure
SpelNodeImpl expr = this.eatLogicalOrExpression();
Recursive execution
if (this.moreTokens()) {
Token t = this.peekToken();
SpelNodeImpl ifTrueExprValue;
if (t.kind == TokenKind.ASSIGN) {
if (expr == null) {
expr = new NullLiteral(this.toPos(t.startPos - 1, t.endPos - 1));
}
this.nextToken();
ifTrueExprValue = this.eatLogicalOrExpression();
return new Assign(this.toPos(t), new SpelNodeImpl[]{(SpelNodeImpl)expr, ifTrueExprValue});
}
if (t.kind == TokenKind.ELVIS) {
if (expr == null) {
expr = new NullLiteral(this.toPos(t.startPos - 1, t.endPos - 2));
}
this.nextToken();
SpelNodeImpl valueIfNull = this.eatExpression();
if (valueIfNull == null) {
valueIfNull = new NullLiteral(this.toPos(t.startPos + 1, t.endPos + 1));
}
return new Elvis(this.toPos(t), new SpelNodeImpl[]{(SpelNodeImpl)expr, (SpelNodeImpl)valueIfNull});
}
if (t.kind == TokenKind.QMARK) {
if (expr == null) {
expr = new NullLiteral(this.toPos(t.startPos - 1, t.endPos - 1));
}
this.nextToken();
ifTrueExprValue = this.eatExpression();
this.eatToken(TokenKind.COLON);
SpelNodeImpl ifFalseExprValue = this.eatExpression();
return new Ternary(this.toPos(t), new SpelNodeImpl[]{(SpelNodeImpl)expr, ifTrueExprValue, ifFalseExprValue});
}
}
return (SpelNodeImpl)expr;
}Analysis of RoleMapperExpression expression of Elasticsearch
Elasticsearch defines a RoleMapperExpression for Role parsing. This class is very simple. According to the custom syntax rules, judge whether the Role request object meets the conditions, such as whether the Field field is satisfied, whether there is a username attribute, etc.
Look at its test cases to see the role of the parser.
public class RoleMapperExpressionParserTests extends ESTestCase {
public void testParseSimpleFieldExpression() throws Exception {
String json = "{ \"field\": { \"username\" : [\"*@shield.gov\"] } }";
FieldRoleMapperExpression field = checkExpressionType(parse(json), FieldRoleMapperExpression.class);
Judge whether there is username field
assertThat(field.getField(), equalTo("username"));
assertThat(field.getValues(), iterableWithSize(1));
assertThat(field.getValues().get(0), equalTo("*@shield.gov"));
assertThat(toJson(field), equalTo(json.replaceAll("\\s", "")));
}The parsing logic of RoleMapperExpressionParse first sees the request as an object, and then recursively parses the call.
private RoleMapperExpression parseRulesObject(final String objectName, final XContentParser parser)
throws IOException {
// find the start of the DSL object
final XContentParser.Token token;
find DSL And then get the current token,If the current one exists, the next one token
if (parser.currentToken() == null) {
token = parser.nextToken();
} else {
token = parser.currentToken();
}
if (token != XContentParser.Token.START_OBJECT) {
throw new ElasticsearchParseException("failed to parse rules expression. expected [{}] to be an object but found [{}] instead",
objectName, token);
}
final String fieldName = fieldName(objectName, parser);
Call syntax parsing class
final RoleMapperExpression expr = parseExpression(parser, fieldName, objectName);
if (parser.nextToken() != XContentParser.Token.END_OBJECT) {
throw new ElasticsearchParseException("failed to parse rules expression. object [{}] contains multiple fields", objectName);
}
return expr;
} There are various types of parsing modes here. Just list the field parsing logic
private RoleMapperExpression parseExpression(XContentParser parser, String field, String objectName)
throws IOException {
if (CompositeType.ANY.getParseField().match(field, parser.getDeprecationHandler())) {
final AnyRoleMapperExpression.Builder builder = AnyRoleMapperExpression.builder();
parseExpressionArray(CompositeType.ANY.getParseField(), parser).forEach(builder::addExpression);
return builder.build();
} else if (CompositeType.ALL.getParseField().match(field, parser.getDeprecationHandler())) {
final AllRoleMapperExpression.Builder builder = AllRoleMapperExpression.builder();
parseExpressionArray(CompositeType.ALL.getParseField(), parser).forEach(builder::addExpression);
return builder.build();
} else if (FIELD.match(field, parser.getDeprecationHandler())) {
return parseFieldExpression(parser);
} else if (CompositeType.EXCEPT.getParseField().match(field, parser.getDeprecationHandler())) {
return parseExceptExpression(parser);
} else {
throw new ElasticsearchParseException("failed to parse rules expression. field [{}] is not recognised in object [{}]", field,
objectName);
}
}
// Logic of field parsing
private RoleMapperExpression parseFieldExpression(XContentParser parser) throws IOException {
checkStartObject(parser);
final String fieldName = fieldName(FIELD.getPreferredName(), parser);
final List<Object> values;
if (parser.nextToken() == XContentParser.Token.START_ARRAY) {
values = parseArray(FIELD, parser, this::parseFieldValue);
} else {
values = Collections.singletonList(parseFieldValue(parser));
}
if (parser.nextToken() != XContentParser.Token.END_OBJECT) {
throw new ElasticsearchParseException("failed to parse rules expression. object [{}] contains multiple fields",
FIELD.getPreferredName());
}
return FieldRoleMapperExpression.ofKeyValues(fieldName, values.toArray());
}Parsing SQL by ShardingSphere
The parse logic of ShardingSphere for SQL calls the parse() method of SQLParser, which returns the ASTNode structure. Almost all SQL parsing is finally converted to an ASTNode.
MySQLParser inherits the syntax parser MySQLStatementParser generated automatically from antlr. In the parse method, the execute method called MySQLStatementParser gets the ExecuteContext returned by antlr, and then creates ParseASTNode object to return.
Here, MySQLStatementParser is automatically built in, so it can't be seen in the idea source code.
/**
* SQL parser for MySQL.
*/
public final class MySQLParser extends MySQLStatementParser implements SQLParser {// MySQLStatementParser is a syntax parser generated by antlr based on. g4 files
public MySQLParser(final TokenStream input) {
super(input);
}
@Override
public ASTNode parse() {
return new ParseASTNode(execute());
}// Create a ParseASTNode object according to the ExecuteContext returned by antlrMeal: ASTNode version evolution in ShardingSphere
ShardingSphere has evolved through several versions before it has the current ASTNode parsing logic. Please refer to ShardingSphere design from source code Description of the.
Abstract syntax tree (AST) is an abstract representation of the syntax structure of source code. It represents the syntax structure of the programming language in the form of a tree, and each node on the tree represents a structure in the source code.
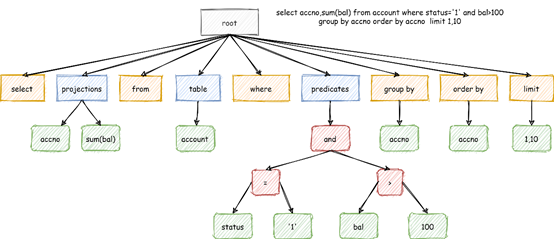
ShardingSphere's parsing engine has undergone three versions of evolution:
-
First generation SQL parser:
Sharding JDBC uses alibaba's Druid in versions before 1.4.x( https://github.com/alibaba/druid), , druid) druid contains a handwritten SQL parser. The advantage is fast, but the disadvantage is that it is not very convenient to expand. It can only be modified by modifying the source code. -
Second generation SQL parser
Starting with version 1.5.x, ShardingSphere has re implemented a simplified SQL parsing engine. ShardingSphere does not need to convert SQL into a complete AST like druid, so it uses the method of semi understanding SQL to extract only the context that needs attention in data segmentation. On the premise of meeting the needs, the performance and compatibility of SQL parsing have been further improved. -
Third generation SQL parser
Since version 3.0.x, ShardingSphere has uniformly replaced the SQL parser with the implementation based on antlr4. The purpose is to support SQL more conveniently and completely, such as complex expressions, recursion, sub queries and other statements, because the positioning of ShardingSphere in the later stage is not only the function of data fragmentation.
antlr4 parses lexical and grammatical rules through. G4 file definitions. Lexical and grammatical files are separated and defined in ShardingSphere. For example, G4 files corresponding to mysql. Lexical rule files include Alphabet.g4, Comments.g4, Keyword.g4, Literals.g4, MySQLKeyword.g4 and Symbol.g4. Grammatical rule files include BaseRule.g4, DALStatement.g4, dclststatement.g4 DDLStatement.g4, dmlststatement.g4, RLStatement.g4 and TCLStatement.g4. Each file defines a type of keyword or SQL type rule.
Usage scenario
- When you need to implement a simple language, use an interpreter.
- The interpreter can be used for SQL syntax analysis, DSL parsing, and custom rules.
Comparison of advantages and disadvantages
advantage
- Each grammar rule represents a class, which is easy to change and expand grammar. Because the pattern uses classes to represent grammar rules, inheritance can be used to change or expand the grammar.
- The existing expression can be changed incrementally, while the new expression can be defined as a variant of the old expression.
- It is easy to implement the grammar definition. The class implementation of each node in the abstract syntax tree is roughly similar. These classes are easy to write directly, and usually they can also be generated automatically by a compiler or parser generator.
- A new way of interpreting expressions is added. The interpreter mode makes it easy to implement the "calculation" of new expressions. For example, you can define a new operation on the expression class to support graceful printing or expression type checking.
shortcoming
- Complex grammars are difficult to maintain. The Interpreter pattern defines at least one class for each rule in the grammar (grammar rules defined with BNF need more classes). Therefore, a grammar containing many rules may be difficult to manage and maintain. Other design patterns can be applied to alleviate this problem. However, when the grammar is very complex, other technologies such as parser or compiler generator are more suitable.
reference material
ShardingSphere design from the source code - Overview
ShardingSphere design - analysis engine from the source code
Gof design pattern: the basic collection of Reusable Object-Oriented Software