This article demonstrates how to use Selenium to crawl the account information of the treasure Pavilion (number of generals, name of generals, number of tactics, number of treasures, price, number of collections, etc.) of the land of lead. Because different information needs various clicks to obtain, Selenium, a dynamic web page automation tool, needs to be used. This article is for personal study only, not for commercial purposes.
Preparation tool python+ Selenium
This part is not the focus of this article. For Selenium installation and use tutorials, please refer to: Use of python selenium Library_ Kenai's blog - CSDN blog_ python selenium
Use Selenium to open the treasure house home page of "the land of the land"
This demo uses Firefox browser (it's OK to use other browsers).
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('https://stzb.cbg.163.com/cgi/mweb/pl/role?view_loc=all_list')Next, the Firefox browser can automatically open the treasure Pavilion home page of the land of the lead. If you find that you need to log in with an account, you can manually enter the account password to log in or log in automatically.
After logging in with your account and password, the list of products in the treasure Pavilion will appear on the web page.
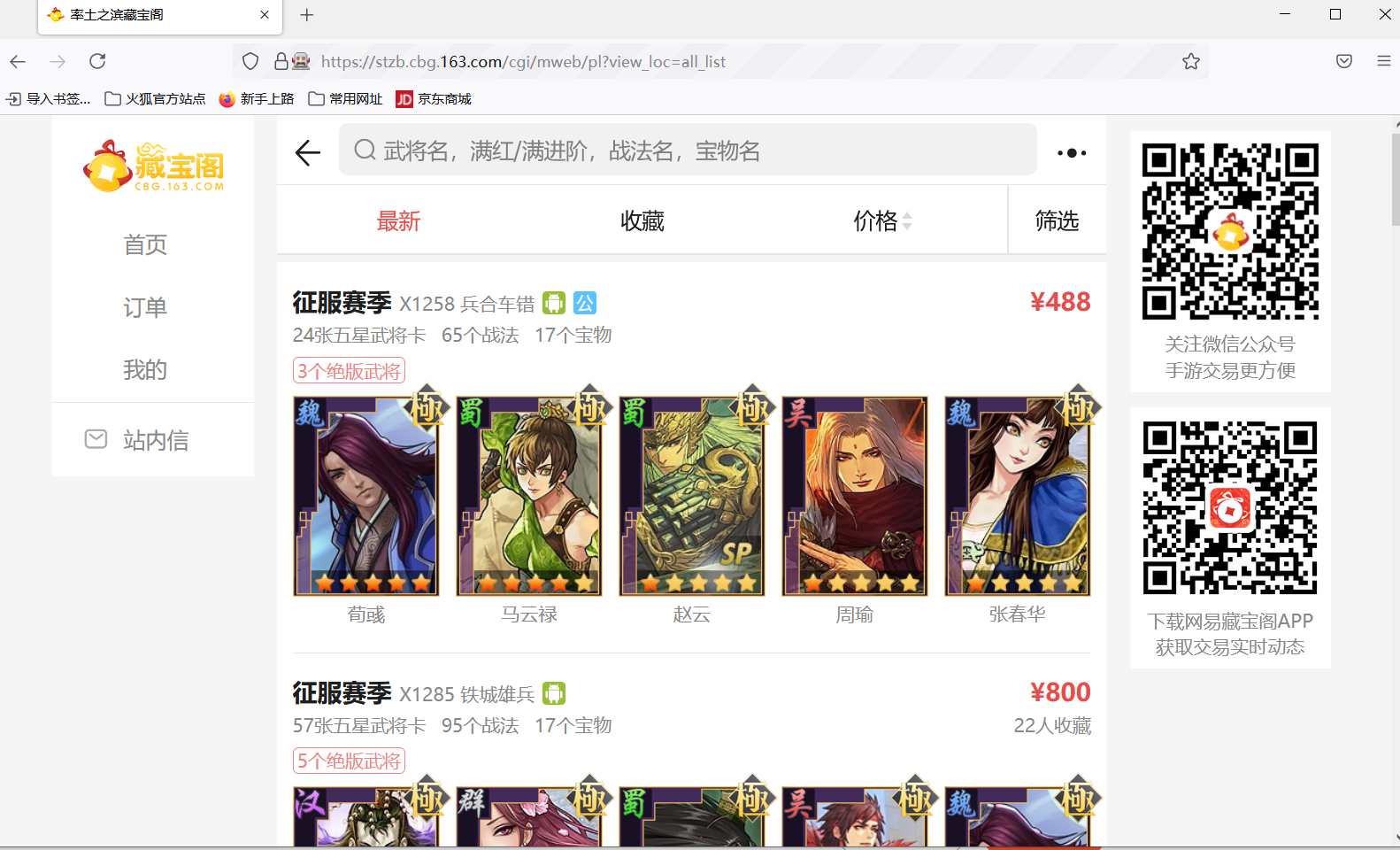
Crawl the information of the first product
Click the review element to view the area where the first product is clicked, and then automatically click to enter the first product using the click() function.
browser.find_element_by_xpath('//div[@class="infinite-scroll list-block border"]/div/div/div[1]').click()
xmlps = etree.HTML(browser.page_source) # Save page xml
Collect the number of generals, tactics and treasures
Find the area showing the number of generals, tactics and treasures, and open the review element.
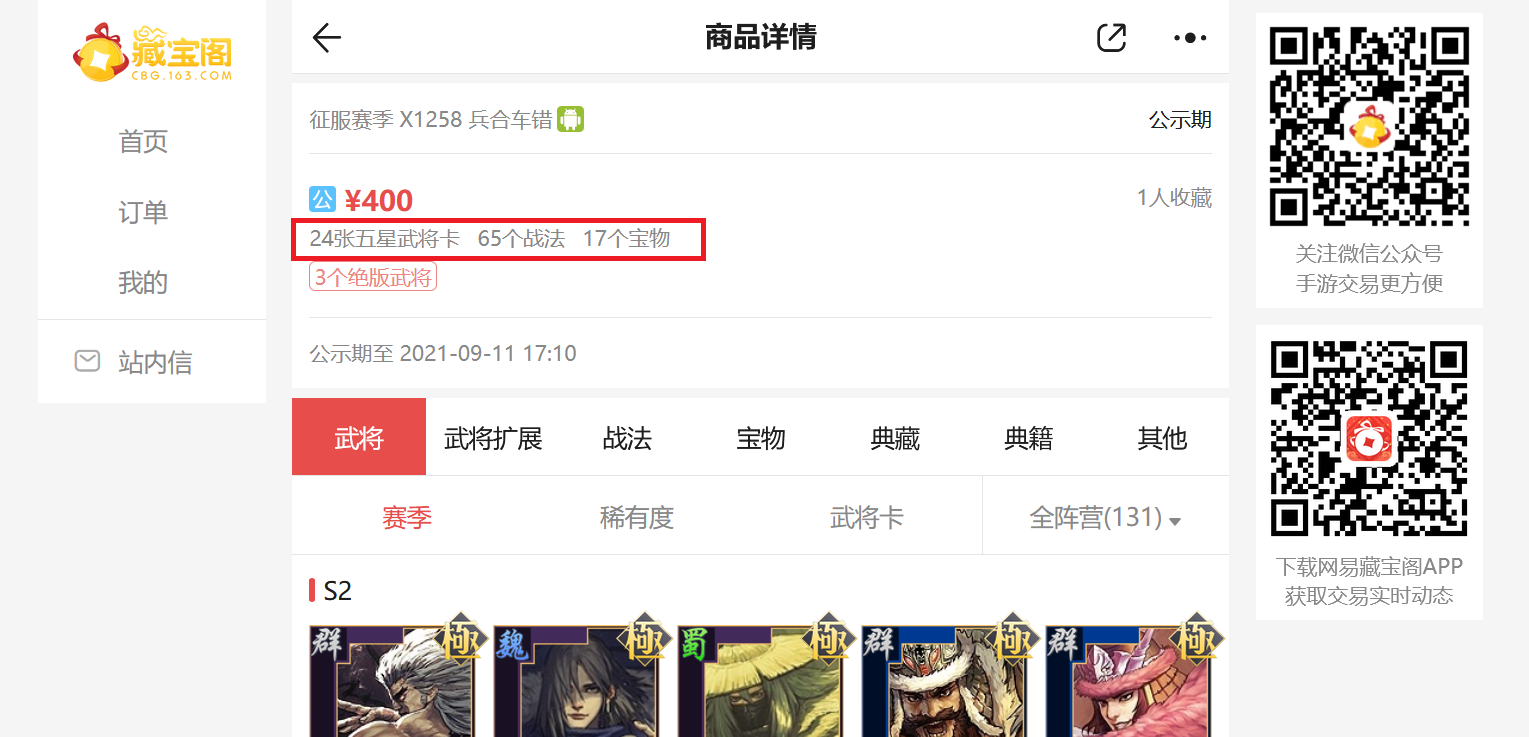
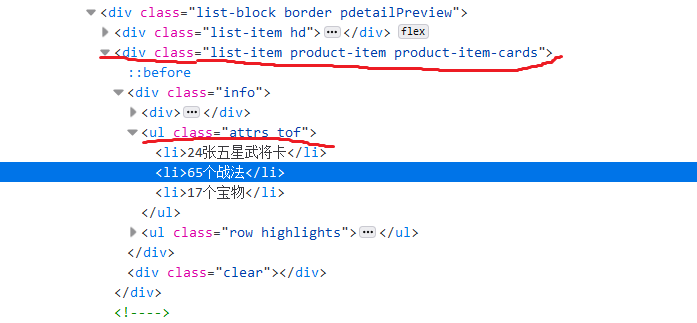
Find div tag class = list item product item cards and ul tag class=attrs tof to locate the area of the number of generals, tactics and treasures.
count0 = xmlps.xpath('//div[@class="list-item product-item product-item-cards"]//ul[@class="attrs tof"]/li/text()')
counts = re.findall("\d+",str(count0)) # Find the number in the string
WJcount = int(counts[0]) # The first number represents the number of generals
ZFcount = int(counts[1]) # The second number represents the number of tactics
if counts.__len__()==2: # The third number represents the number of treasures
BWcount = 0
else:
BWcount = counts[2]Collection price, number of collectors, client type, collection quantity, and battle method name
Basically according to the above method
# Price
Price = xmlps.xpath('//div[@class="list-item product-item product-item-cards"]//div[@class="price-wrap"]/div[@class="price icon-text"]/span/text()')
#Number of collectors
Favorites = xmlps.xpath('//div[@class="list-item product-item product-item-cards"]//span[@class="collect pull-right"]/text()')
# client
Port = browser.find_element_by_xpath('//div[@class="color-gray"]/span[2]').get_attribute('class')
# Number of collections
browser.find_element_by_xpath('//div[@class="hair-tab"]/div/a[5]').click()
xmlps = etree.HTML(browser.page_source)
DCcount = xmlps.xpath('//div[@class="content"]//div[@class="product-content content-dian-cang"]/ul/li[@class="tab-item selected"]/text()')
# Tactics name
browser.find_element_by_xpath('//div[@class="hair-tab"]/div/a[3]').click()
xmlps = etree.HTML(browser.page_source)
ZFname = xmlps.xpath('//div[@class="product-content content-card-extend"]/div[@class="module"]/ul[@class="skills"]/li/p[2]/text()')Collect military general information
The collection of generals' information is slightly different. Generals' information includes generals' names, forces and advanced numbers, and the total number of generals owned by different accounts is also different. You need to obtain the general information in the account through a cycle.
browser.find_element_by_xpath('//div[@class="hair-tab"]/div/a[1]').click()
xmlps = etree.HTML(browser.page_source)
shili = list() # Forces of generals
WJname = list() # General name
WJStars = list() #Advanced number of generals
for i in range(WJcount):
j = i+1
shili0 = xmlps.xpath('//div[@class="cards"]/div[1]/ul/li[%d]//div[@class="wrap"]/div[2]/i/text()'% j)
WJname0 = xmlps.xpath('//div[@class="cards"]/div[1]/ul/li[%d]/div/div[@class="name tC"]/text()'% j)
WJname0 = [XX.replace('\n','') for XX in WJname0] #Remove \ n
WJname0 = [XX.strip() for XX in WJname0]
WJStars0 = xmlps.xpath('count(//div[@class="cards"]/div[1]/ul/li[%d]//div[@class="stars"]/div[@class="stars-wrap"]/span[@class="star up"])'% j)
shili.append(shili0)
WJname.append(WJname0)
WJStars.append(WJStars0)Save collected data
Finally, put all the collected data into a list and save it as a json file.
ACCOUNT0 = list() ACCOUNT0.append(counts) ACCOUNT0.append(Price) ACCOUNT0.append(Favorites) ACCOUNT0.append(Port) ACCOUNT0.append(DCcount) ACCOUNT0.append(shili) ACCOUNT0.append(WJname) ACCOUNT0.append(WJStars) ACCOUNT0.append(ZFname)

Crawling information of multiple products
You need to slide the mouse to expand the information of multiple commodities (this can be realized through Selenium). The complete code is posted below.
from selenium import webdriver
import lxml.etree as etree
import re
import json
import os
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import numpy as np
import pandas as pd
browser = webdriver.Firefox()
browser.get('https://stzb.cbg.163.com/cgi/mweb/pl/role?view_loc=all_list')
#Slide to the bottom to get the total number of accounts
Accounts_num = 0
for i in range(40):
# js="window.scrollTo(0,document.body.scrollHeight)"
browser.execute_script('window.scrollTo(0,1000000)')
xmlps = etree.HTML(browser.page_source)
Accounts_num0 = xmlps.xpath('count(//div[@class="infinite-scroll list-block border"]/div/div/div[@class="product-item product-item-cards list-item list-item-link"])')
print('Accounts_num0:',Accounts_num0)
print('Accounts_num:',Accounts_num)
if Accounts_num0 > Accounts_num :
Accounts_num = Accounts_num0
else:
break
time.sleep(0.45)
# A function to collect account information
def getDATA(index):
browser.find_element_by_xpath('//div[@class="infinite-scroll list-block border"]/div/div/div[%d]' % index).click()
# xmlps = etree.HTML(browser.page_source)
# Test whether the web page is loaded
try:
element = WebDriverWait(browser, 10).until(
EC.presence_of_element_located((By.XPATH, '//div[@class="list-item product-item product-item-cards"]'))
)
xmlps = etree.HTML(browser.page_source)
finally:
print('Page loading completed')
# Number of generals, number of tactics, number of treasures
count0 = xmlps.xpath('//div[@class="list-item product-item product-item-cards"]//ul[@class="attrs tof"]/li/text()')
print(count0)
counts = re.findall("\d+", str(count0))
WJcount = int(counts[0])
ZFcount = int(counts[1])
if counts.__len__() == 2:
BWcount = 0
else:
BWcount = counts[2]
# Price
Price = xmlps.xpath(
'//div[@class="list-item product-item product-item-cards"]//div[@class="price-wrap"]/div[@class="price icon-text"]/span/text()')
# Number of collectors
Favorites = xmlps.xpath(
'//div[@class="list-item product-item product-item-cards"]//span[@class="collect pull-right"]/text()')
# ios or Android
Port = browser.find_element_by_xpath('//div[@class="color-gray"]/span[2]').get_attribute('class')
print(Port, index)
# Remaining time for sale
RestDays = xmlps.xpath('//div[@class="ft clearfix"]/p//span/text()')
# Capture generals card data
# browser.find_element_by_xpath('//div[@class="hair-tab"]/div/a[1]').click()
# xmlps = etree.HTML(browser.page_source)
shili = list()
WJname = list()
WJStars = list()
for ji in range(WJcount):
j = ji + 1
shili0 = xmlps.xpath('//div[@class="cards"]/div[1]/ul/li[%d]//div[@class="wrap"]/div[2]/i/text()' % j)
WJname0 = xmlps.xpath('//div[@class="cards"]/div[1]/ul/li[%d]/div/div[@class="name tC"]/text()' % j)
WJname0 = [XX.replace('\n', '') for XX in WJname0] # Remove \ n
WJname0 = [XX.strip() for XX in WJname0]
WJStars0 = xmlps.xpath(
'count(//div[@class="cards"]/div[1]/ul/li[%d]//div[@class="stars"]/div[@class="stars-wrap"]/span[@class="star up"])' % j)
shili.append(shili0)
WJname.append(WJname0)
WJStars.append(WJStars0)
# Tactics name
browser.find_element_by_xpath('//div[@class="hair-tab"]/div/a[3]').click()
xmlps = etree.HTML(browser.page_source)
ZFname = xmlps.xpath(
'//div[@class="product-content content-card-extend"]/div[@class="module"]/ul[@class="skills"]/li/p[2]/text()')
# Number of collections
browser.find_element_by_xpath('//div[@class="hair-tab"]/div/a[5]').click()
xmlps = etree.HTML(browser.page_source)
DCcount = xmlps.xpath(
'//div[@class="content"]//div[@class="product-content content-dian-cang"]/ul/li[@class="tab-item selected"]/text()')
ACCOUNT0 = list()
ACCOUNT0.append(counts)
ACCOUNT0.append(Price)
ACCOUNT0.append(Favorites)
ACCOUNT0.append(Port)
ACCOUNT0.append(RestDays)
ACCOUNT0.append(DCcount)
ACCOUNT0.append(shili)
ACCOUNT0.append(WJname)
ACCOUNT0.append(WJStars)
ACCOUNT0.append(ZFname)
# Data saving
index = index + numAccount
with open('data003/account%d.json' % index, 'w') as Account:
json.dump(ACCOUNT0, Account)
print("The first%d Data saved" % index)
browser.back() #Return to previous page
time.sleep(0.2) #Waiting for page load time
# Obtain multiple account information through circulation
for i in range(Accounts_num):
index = i + 1
getDATA(index)After collecting the data, we can analyze the data. For example, we can analyze the value of different generals by using random deep forest analysis, XGBoost, linear regression and other methods, which will be shown in the next article.