This paper mainly refers to the teacher's teaching, the teacher's course learning, memory and notes.
Original link
There is a road to the mountain of books. Diligence is the path. There is no end to learning. It is hard to make a boat.

Zero. Draught does not forget the well digger
Please support the teacher's original text
Original link
1, Search engine
1. Retrieve text information
The search engine will traverse all web pages, give different weights to the content information of the title, time and text in the obtained web pages, construct an index in advance and store it in the database.
When users are searching, search engines will only search in their own database. However, when the web page is updated, the spider will regularly climb to the web page and update it.
2.2 retrieving pictures and video information
When in-depth learning has not been popularized, most of the information of pictures and videos is recorded through text, and retrieval is realized by labeling the information of pictures and videos.
Today's deep learning provides a new idea to extract digital information that can be recognized by computer from non-verbal information by using model.
Multimodal search: convert the user's input text information into digital information and match it with the digital information of pictures and videos. Compare the correlation between the two numbers to find the most similar content.
Disadvantages of deep learning: due to its complex network, it is time-consuming, laborious and inefficient.
2.3 inverted index (quick search)
NLP can realize the computer's understanding of human language.
Inverted index can realize computer, and can quickly retrieve the required information without understanding human language.
Inverted index is a batch recall technology, which can quickly recall the information required by basic composite retrieval in massive data.
- Forward index
Search all the file information to find the information of composite requirements.

- Inverted index
When you get all the materials first, read through all the materials and build the corresponding relationship between keywords and articles. When the user retrieves a specific word, all articles under the keyword are returned between.
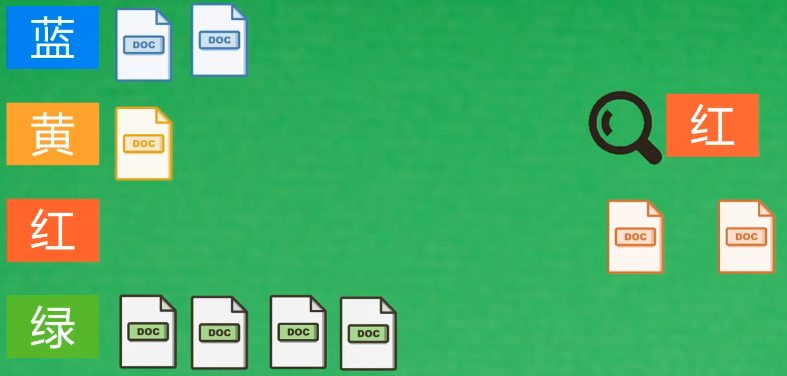
In front of massive data, the articles found in the inverted index may still be massive, so we also need to sort the articles and obtain the top article list.
The most famous algorithm for processing matching sorting: TF-IDF
2.4 matching sorting TF-IDF
2.4.1 TF-IDF principle
The batch recalled data may still be massive, so the data needs to be filtered.
The recalled content is sorted by the similarity between the problem and the content, and only the content of the header is returned. Similarity scoring

TFIDF
When comparing the user's keywords with the keywords in the article, we need to find the keywords in the article. What words are important and what words can be used in the article.
We need to use TFIDF to filter and extract article keywords:
TF: the more important it is, the more frequently it appears, but some colloquial words appear frequently.
IDF discrimination is needed to distinguish words.
IDF: the implementation distinguishes which words are important and which words are not important in the global.

Combine the two to express an article
Keywords of global articles

2.4.2 implementation of TFIDF in retrieval
During the retrieval, the machine will use the thesaurus to calculate the TFIDF value of the questions asked by the user
Then calculate the question and the COS distance from each article.
It is to project questions and articles into a vector space to calculate the similarity of articles.

Each article can be converted into vector form as follows:

Every article is a point in vector space, and questions are also a point in vector space.
2.4.3 mathematical expression of TFIDF
TFIDF uses digital vectors of words to represent a document. When comparing documents, it is comparing the similarity of these vectors.
All articles can be transformed into an N-dimensional vector in an N-dimensional space.
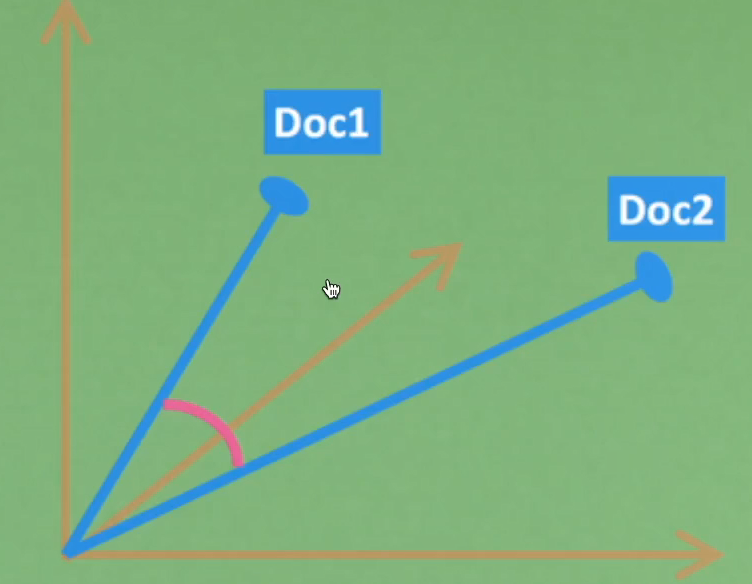
For example, there are three documents below. The words "don't bother", "Python" and "best" are repeated in each document. After calculating TF-IDF for each word, we can use these TF-IDF values to represent the three documents, that is, each document is a three-dimensional vector.

If the vector is displayed on the graph, it will look like the following pattern. With a way to calculate the vector similarity, such as cosine distance, we can judge which documents are similar in this three-dimensional space. The closer the two blue vectors are, the more similar they are.
2, Code implementation
2.1 preliminary assumptions 15 articles
import numpy as np
from collections import Counter
import itertools
docs = [
"it is a good day, I like to stay here",
"I am happy to be here",
"I am bob",
"it is sunny today",
"I have a party today",
"it is a dog and that is a cat",
"there are dog and cat on the tree",
"I study hard this morning",
"today is a good day",
"tomorrow will be a good day",
"I like coffee, I like book and I like apple",
"I do not like it",
"I am kitty, I like bob",
"I do not care who like bob, but I like kitty",
"It is coffee time, bring your cup",
]
Convert the word of the document into ID form, which is convenient for subsequent statistics through ID.
docs_words = [d.replace(",", "").split(" ") for d in docs]
vocab = set(itertools.chain(*docs_words))
v2i = {v: i for i, v in enumerate(vocab)}
i2v = {i: v for v, i in v2i.items()}
2.2 TF-IDF
Construct the representation of each document, that is, its TF-IDF vector representation
When calculating TF-IDF, we will separate it for calculation, because in fact, the IDF value can be reused. After calculating the IDF in a large database, we can take the IDF with the database data distribution to other places for use, which is a bit like the meaning of and training model in machine learning.
For example, if there is a NLP pre training model specially trained on financial data or science and technology data, of course, the science and technology pre training model is what we want to use in science and technology documents. If we use the financial pre training model on science and technology, there will be deviation in data distribution. Similarly, IDF pre calculation table also means the same.
The IDF essence of word w calculates IDF = log (the number of all documents / the number of words w in all documents). Of course, there are many variant calculation methods. The code is as follows:
idf_methods = {
"log": lambda x: 1 + np.log(len(docs) / (x+1)),
"prob": lambda x: np.maximum(0, np.log((len(docs) - x) / (x+1))),
"len_norm": lambda x: x / (np.sum(np.square(x))+1),
}
def get_idf(method="log"):
# inverse document frequency: low idf for a word appears in more docs, mean less important
df = np.zeros((len(i2v), 1))
for i in range(len(i2v)):
d_count = 0
for d in docs_words:
d_count += 1 if i2v[i] in d else 0
df[i, 0] = d_count
idf_fn = idf_methods.get(method, None)
if idf_fn is None:
raise ValueError
return idf_fn(df) # [n_vocab, 1]
There are many methods for IDF calculation. Here I provide three options. If the IDF value of a word in a document is about small, it means that it is meaningless and appears frequently in other documents. The final IDF table is a table of importance of all words, shape=[n_vocab, 1]. Next, we will calculate the TF value in each document.
The word W is in the TF essence of document d. calculate TF = the total number of words w in document d
tf_methods = {
"log": lambda x: np.log(1+x),
"augmented": lambda x: 0.5 + 0.5 * x / np.max(x, axis=1, keepdims=True),
"boolean": lambda x: np.minimum(x, 1),
"log_avg": lambda x: (1 + safe_log(x)) / (1 + safe_log(np.mean(x, axis=1, keepdims=True))),
}
def get_tf(method="log"):
# term frequency: how frequent a word appears in a doc
_tf = np.zeros((len(vocab), len(docs)), dtype=np.float64) # [n_vocab, n_doc]
for i, d in enumerate(docs_words):
counter = Counter(d)
for v in counter.keys():
_tf[v2i[v], i] = counter[v] / counter.most_common(1)[0][1]
weighted_tf = tf_methods.get(method, None)
if weighted_tf is None:
raise ValueError
return weighted_tf(_tf) # [n_vocab, n_doc]
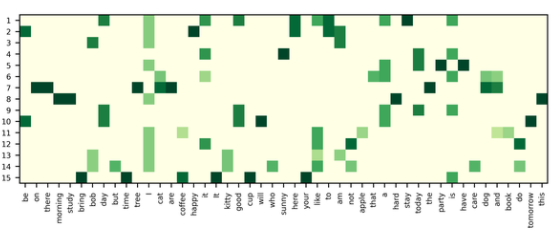
TF is the vector representation of each document composed of all words. shape=[n_vocab, n_doc]. The TF-IDF vector representation of each document can be obtained through the product of TF-IDF.
tf = get_tf() # [n_vocab, n_doc] idf = get_idf() # [n_vocab, 1] tf_idf = tf * idf # [n_vocab,
The TF-IDF finally calculated is actually a matrix of words and articles, representing articles represented by word vectors
2.3 problem Vectorization
With these vector representations, when we search, we only need to quantify the search problem and calculate the distance between the search vector and the document vector to calculate which documents are closer to the search vector.
Try to search I get a coffee cup and return the first 3 documents most similar to this search among the 15 documents.
def cosine_similarity(q, _tf_idf):
unit_q = q / np.sqrt(np.sum(np.square(q), axis=0, keepdims=True))
unit_ds = _tf_idf / np.sqrt(np.sum(np.square(_tf_idf), axis=0, keepdims=True))
similarity = unit_ds.T.dot(unit_q).ravel()
return similarity
def docs_score(q):
... To highlight the point, I'll omit the processing section, see Github Full code in
q_vec = q_tf * _idf # [n_vocab, 1]
q_scores = cosine_similarity(q_vec, _tf_idf)
... To highlight the point, I'll omit the processing section, see Github Full code in
return q_scores
q = "I get a coffee cup"
scores = docs_score(q)
d_ids = scores.argsort()[-3:][::-1]
print("\ntop 3 docs for '{}':\n{}".format(q, [docs[i] for i in d_ids]))
3, Other applications of TFIDF
3.1 selection of article keywords
TF-IDF is a document display method that converts the importance of words into vectors. In these vectors, there must be dominant elements, and these elements are actually very important keywords in this document.
We can select keywords for these documents. The following function is to select two keywords for the first three documents.
def get_keywords(n=2):
for c in range(3):
col = tf_idf[:, c]
idx = np.argsort(col)[-n:]
print("doc{}, top{} keywords {}".format(c, n, [i2v[i] for i in idx]))