What is redis
Redis is an open source (BSD licensed) in memory data structure storage system, which can be used as database, cache and message middleware. It supports many types of data structures, such as strings, hashes, lists, sets, sorted sets And range query, bitmaps, hyperloglogs and geospatial Index radius query. Redis has built-in replication,Lua scripting, LRU event,transactions And different levels of Disk persistence , and passed Redis Sentinel And automatic Partition (Cluster) Provide high availability.
Test performance
Redis benchmark is a stress testing tool and an official performance testing tool.
Usage: redis benchmark [option] [option value]
The optional parameters of redis performance test tool are as follows:
| Serial number | option | describe | Default value |
|---|---|---|---|
| 1 | -h | Specify the server host name | 127.0.0.1 |
| 2 | -p | Specify server port | 6379 |
| 3 | -s | Specify server socket | |
| 4 | -c | Specifies the number of concurrent connections | 50 |
| 5 | -n | Specify the number of requests | 10000 |
| 6 | -d | Specifies the data size of the SET/GET value in bytes | 2 |
| 7 | -k | 1=keep alive 0=reconnect | 1 |
| 8 | -r | SET/GET/INCR uses random keys and Sadd uses random values | |
| 9 | -P | Pipeline requests | 1 |
| 10 | -q | Force to exit redis. Show only query/sec values | |
| 11 | –csv | Export in CSV format | |
| 12 | *-L * (lowercase letter of L) | Generate a loop and permanently execute the test | |
| 13 | -t | Run only a comma separated list of test commands. | |
| 14 | *-i * (capital letter of i) | Idle mode. Open only N idle connections and wait. |
Start the test:
#Test 100 concurrent connections 100000 requests redis-benchmark -h localhost -p 6379 -c 100 -n 100000
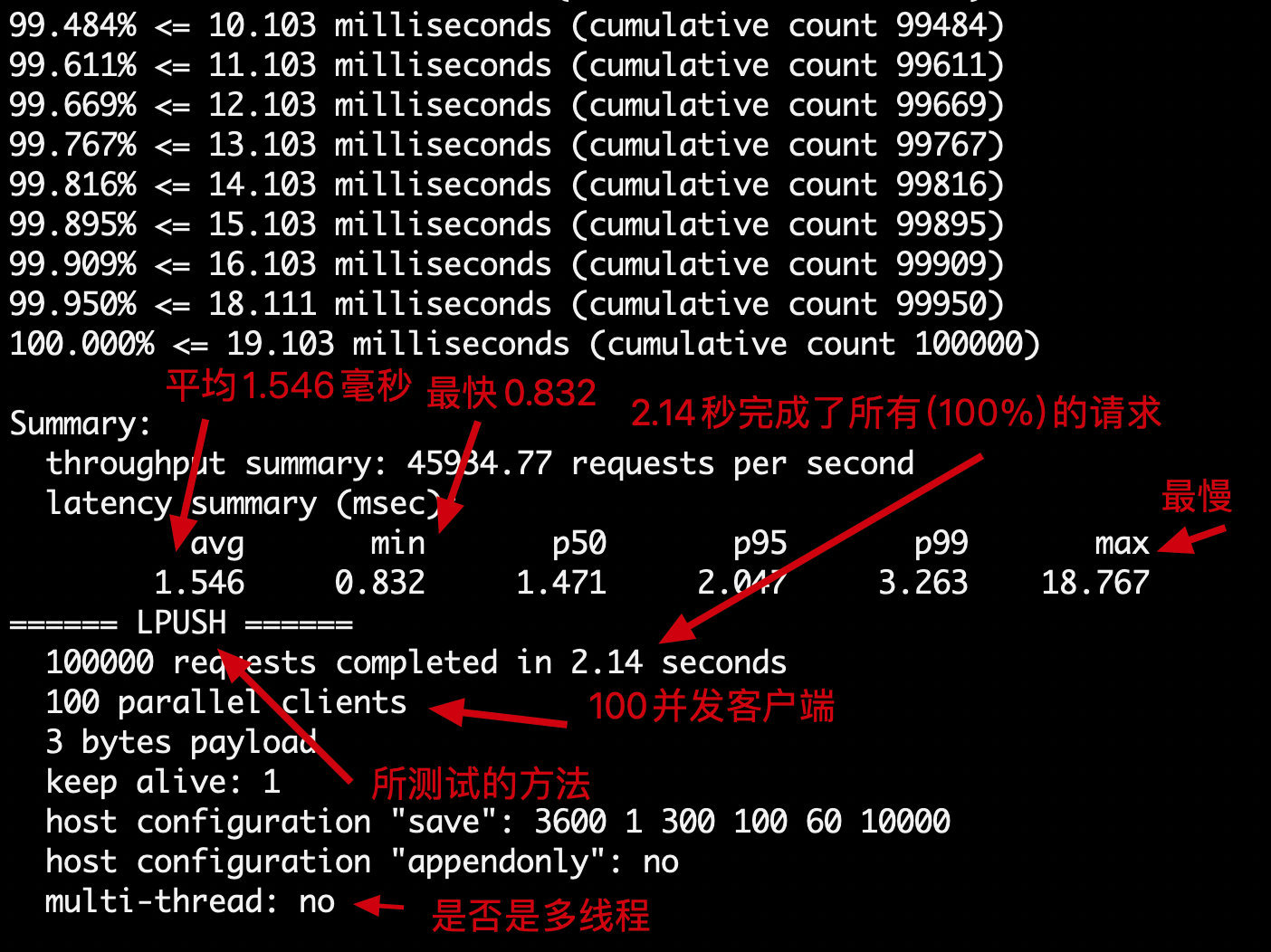
Introductory knowledge
redis has 16 databases by default, which can be found in the configuration file

The 0 database is used by default. You can use the select command to switch databases.
//View db size 127.0.0.1:6379> dbsize (integer) 4 //Switch database 127.0.0.1:6379> select 3 OK 127.0.0.1:6379[3]> dbsize (integer) 0
Different databases are independent of each other
127.0.0.1:6379[3]> set name lingg OK 127.0.0.1:6379[3]> dbsize (integer) 1 127.0.0.1:6379[3]> get name "lingg" 127.0.0.1:6379[3]> select 1 OK 127.0.0.1:6379[1]> get name (nil) 127.0.0.1:6379[1]>
redis is single threaded
Why?
According to the official FAQ, because Redis is a memory based operation, the CPU is not the bottleneck of Redis. The most likely bottleneck of Redis is the size of machine memory or network bandwidth. Since single thread is easy to implement and the CPU will not become a bottleneck, it is logical to adopt the single thread scheme (after all, using multithreading will have a lot of trouble!).
Question: why is single thread so fast?
- Memory based operation: firstly, the I/O speed of traditional database is slow due to the slow multithreading, while most redis operations are carried out in memory.
- After optimization: redis's own data structure is specially designed. The data structure is simple, and the operation for the data structure is also simple
- Reduce overhead: because redis is single threaded, the overhead of context switching required by multithreaded cpu time slice rotation lock is avoided. There are no problems with all kinds of locks, and there are no operations to add and release locks.
- Multiplexing I/O: epoll model and non blocking I/O model in the multiplexing I/O model using linux. See here for the introduction of IO model
- Self built VM: the underlying implementation method and the application protocol for communication with the client are different. redis has built its own VM because there is a certain time overhead when calling system functions through system calls.
However, we can't give full play to the performance of multi-core CPU by using single thread, but we can improve it by opening multiple Redis instances on a single machine!
Core: redis Put all the data in memory, so using single thread to operate is the most efficient, multi-threaded( CPU Context switching: time-consuming). For memory, if there is no context switching, the efficiency is the highest. The same context is used for multiple reads and writes CPU,In the case of memory, the efficiency of single thread is the highest.
Basic operation
View all keys: Keys*
127.0.0.1:6379> keys * 1) "mylist" 2) "key:__rand_int__" 3) "myhash" 4) "counter:__rand_int__"
Empty the current database: flushdb
127.0.0.1:6379[3]> select 0 OK 127.0.0.1:6379> keys * 1) "mylist" 2) "key:__rand_int__" 3) "myhash" 4) "counter:__rand_int__" 127.0.0.1:6379> flushdb OK 127.0.0.1:6379> keys * (empty array)
Clear all databases: flush
127.0.0.1:6379> select 0 OK 127.0.0.1:6379> keys * (empty array) 127.0.0.1:6379> set name "lingg" OK 127.0.0.1:6379> get name "lingg" 127.0.0.1:6379> select 2 OK 127.0.0.1:6379[2]> flushall OK 127.0.0.1:6379[2]> select 0 OK 127.0.0.1:6379> keys * (empty array) 127.0.0.1:6379>