Before we explain our crawler, we will first outline the simple concept of crawler (after all, it is a zero foundation tutorial)
Reptile
Web crawler (also known as web spider, web robot) is a program that simulates the browser to send web requests and receive request responses. It is a program that automatically grabs Internet information according to certain rules.
In principle, as long as the browser (client) can do anything, the crawler can do it.
Why do we use reptiles
In the era of Internet big data, we are given the convenience of life and the explosive emergence of massive data in the network.
In the past, through books, newspapers, television and radio, we may have information. The amount of this information is limited, and after certain screening, the information is relatively effective, but the disadvantage is that the information surface is too narrow. Asymmetric information transmission, so that our vision is limited and we can't understand more information and knowledge.
In the era of Internet big data, we suddenly have free access to information. We have obtained a large amount of information, but most of them are invalid junk information.
For example, Sina Weibo generates hundreds of millions of status updates a day, while Baidu search engine randomly searches one - 100000000 information on weight loss.
In such a large amount of information fragments, how can we obtain useful information for ourselves?
The answer is screening!
The relevant contents are collected through a certain technology, and the information we really need can be obtained after analysis and selection.
This work of information collection, analysis and integration can be applied to a wide range of fields. Whether it is life services, travel, financial investment, product market demand of various manufacturing industries, etc., we can use this technology to obtain more accurate and effective information.
Although web crawler technology has a strange name, and its first reaction is that kind of soft crawling creature, it is a sharp weapon that can move forward in the virtual world.
Reptile preparation
We usually talk about Python crawlers. In fact, there may be a misunderstanding here. Crawlers are not unique to python. There are many languages that can be used as crawlers, such as PHP,JAVA,C#,C++,Python. Python is chosen as a crawler because Python is relatively simple and has complete functions.
First, we need to download python. I downloaded the latest official version 3.8.3
Secondly, we need an environment to run Python. I use pychram

It can also be downloaded from the official website,
We also need some libraries to support the running of crawlers (some Python libraries may come with them)
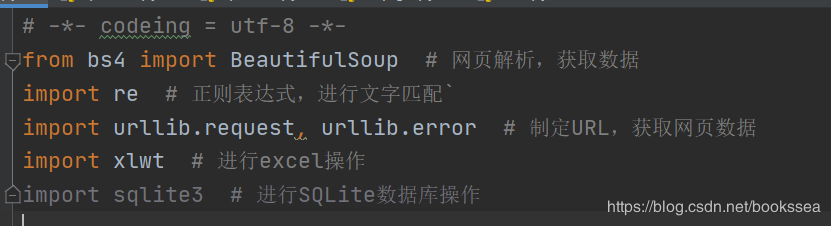
It's almost these libraries. Conscience, I've written notes later

(in the process of running the crawler, you don't need only the above libraries. It depends on the specific writing method of your crawler. Anyway, if you need a library, we can install it directly in setting.)
Explanation of reptile project
What I do is crawl the crawler code of Douban scoring film Top250
This is the website we want to climb: https://movie.douban.com/top250
I've finished crawling here. Let's see the renderings. I save the crawled content in xls

Our crawling content is: film details link, picture link, Film Chinese name, film foreign name, score, evaluation number, overview and relevant information.
code analysis
First release the code, and then I analyze it step by step according to the code
Let me explain and analyze the code from bottom to bottom
# -*- codeing = utf-8 -*-
from bs4 import BeautifulSoup # Web page analysis and data acquisition
import re # Regular expressions for text matching`
import urllib.request, urllib.error # Make URL and get web page data
import xlwt # excel operation
#import sqlite3 # Perform SQLite database operations
findLink = re.compile(r'<a href="(.*?)">') # Create regular expression objects, auction rules, rules for movie details links
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S)
findTitle = re.compile(r'<span class="title">(.*)</span>')
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
findJudge = re.compile(r'<span>(\d*)Human evaluation</span>')
findInq = re.compile(r'<span class="inq">(.*)</span>')
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
def main():
baseurl = "https://movie.douban.com/top250?start = "# page link to crawl
# 1. Crawl web pages
datalist = getData(baseurl)
savepath = "Douban film Top250.xls" #Create a new XLS in the current directory and store it
# dbpath = "movie.db" #Create a new database in the current directory and store it
# 3. Save data
saveData(datalist,savepath) #Only one of the two storage methods can be selected
# saveData2DB(datalist,dbpath)
# Crawl web pages
def getData(baseurl):
datalist = [] #Used to store crawled web page information
for i in range(0, 10): # Call the function to obtain page information, 10 times
url = baseurl + str(i * 25)
html = askURL(url) # Save the obtained web page source code
# 2. Analyze the data one by one
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="item"): # Find a string that meets the requirements
data = [] # Save all information about a movie
item = str(item)
link = re.findall(findLink, item)[0] # Find by regular expression
data.append(link)
imgSrc = re.findall(findImgSrc, item)[0]
data.append(imgSrc)
titles = re.findall(findTitle, item)
if (len(titles) == 2):
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/", "") #Eliminate escape characters
data.append(otitle)
else:
data.append(titles[0])
data.append(' ')
rating = re.findall(findRating, item)[0]
data.append(rating)
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum)
inq = re.findall(findInq, item)
if len(inq) != 0:
inq = inq[0].replace(". ", "")
data.append(inq)
else:
data.append(" ")
bd = re.findall(findBd, item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?', "", bd)
bd = re.sub('/', "", bd)
data.append(bd.strip())
datalist.append(data)
return datalist
# Get the web page content with a specified URL
def askURL(url):
head = { # Simulate the browser header information and send a message to the Douban server
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
# User agent means telling Douban server what kind of machine and browser we are (essentially telling the browser what level of file content we can receive)
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# Save data to table
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #Create workbook object
sheet = book.add_sheet('Douban film Top250', cell_overwrite_ok=True) #Create worksheet
col = ("Movie details link","pictures linking","Chinese name of the film","Film foreign name","score","Number of evaluations","survey","Relevant information")
for i in range(0,8):
sheet.write(0,i,col[i]) #Listing
for i in range(0,250):
# print("The first%d strip" %(i+1)) #Output statements for testing
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #data
book.save(savepath) #preservation
# def saveData2DB(datalist,dbpath):
# init_db(dbpath)
# conn = sqlite3.connect(dbpath)
# cur = conn.cursor()
# for data in datalist:
# for index in range(len(data)):
# if index == 4 or index == 5:
# continue
# data[index] = '"'+data[index]+'"'
# sql = '''
# insert into movie250(
# info_link,pic_link,cname,ename,score,rated,instroduction,info)
# values (%s)'''%",".join(data)
# # print(sql) #Output query statements for testing
# cur.execute(sql)
# conn.commit()
# cur.close
# conn.close()
# def init_db(dbpath):
# sql = '''
# create table movie250(
# id integer primary key autoincrement,
# info_link text,
# pic_link text,
# cname varchar,
# ename varchar ,
# score numeric,
# rated numeric,
# instroduction text,
# info text
# )
#
#
# ''' #Create data table
# conn = sqlite3.connect(dbpath)
# cursor = conn.cursor()
# cursor.execute(sql)
# conn.commit()
# conn.close()
# Save data to database
if __name__ == "__main__": # When the program is executed
# Call function
main()
# init_db("movietest.db")
print("Climb over!")
--Coding = utf-8 -- the first one is to set the code to utf-8 and write it at the beginning to prevent random code.
Then below Import is to import some libraries and make preparations. (I didn't use sqlite3, so I annotated it).
The following regular expressions starting with find are used to filter information.
(regular expressions can be used in the re library or not. It is not necessary.)
The general process is divided into three steps:
1. Crawl web pages
2. Analyze the data one by one
3. Save web page
First analyze process 1. Crawl the web page. The baseurl is the web address of the web page we want to crawl. Go down and call getData (baseurl),
Let's look at the getData method
for i in range(0, 10): # Call the function to obtain page information, 10 times
url = baseurl + str(i * 25)You may not understand this paragraph. In fact, it is like this:
Because the movie score is top 250, each page only displays 25, so we need to visit the page 10 times, 25 * 10 = 250.
baseurl = "https://movie.douban.com/top250?start="
As long as we add a number after the baseurl, we will jump to the corresponding page, such as when i=1
https://movie.douban.com/top250?start=25
I put a hyperlink, you can click to see which page you will jump to. After all, practice makes true knowledge.

Then the askURL is called to request the web page. This method is the main method of requesting the web page,
Afraid of the trouble of turning the page, I'll copy the code again to give you an intuitive feeling
def askURL(url):
head = { # Simulate the browser header information and send a message to the Douban server
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
# User agent means telling Douban server what kind of machine and browser we are (essentially telling the browser what level of file content we can receive)
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return htmlThis askURL is used to send requests to the web page. What old fellow asked, why do I write a head here?

This is because if we don't write, we will be recognized as crawlers and display errors and error codes when visiting some websites
418
This is a stem. You can baidu,
418 I'm a teapot
The HTTP 418 I'm a teapot client error response code indicates that
the server refuses to brew coffee because it is a teapot. This error
is a reference to Hyper Text Coffee Pot Control Protocol which was an
April Fools' joke in 1998.
I am a teapot

So we need to "pretend" that we are a browser so that we won't be recognized,
Disguise an identity.

Come on, let's keep going,
html = response.read().decode("utf-8")
This section is what we read from the web page and set the code to utf-8 to prevent random code.
After the successful visit, we come to the second process:
2. Analyze the data one by one
Here we use the beautiful soup library to analyze data. This library is almost a necessary library for crawlers, no matter what you write.
Now let's start to find the data that meets our requirements, using the beautiful soup method and the re library
Regular expressions to match,
findLink = re.compile(r'<a href="(.*?)">') # Create regular expression objects, auction rules, rules for movie details links findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) findTitle = re.compile(r'<span class="title">(.*)</span>') findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>') findJudge = re.compile(r'<span>(\d*)Human evaluation</span>') findInq = re.compile(r'<span class="inq">(.*)</span>') findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
Match the data that meets our requirements, and then save it dataList , therefore dataList There is the data we need in the.
Last process:
3. Save data
# 3. Save data
saveData(datalist,savepath) #Only one of the two storage methods can be selected
# saveData2DB(datalist,dbpath)You can choose to save the data to the xls table, which needs to be supported by the xlwt library
You can also choose to save the data to sqlite database, which needs to be supported by sqlite3 library
Here I choose to save to the xls table, which is why I annotate a lot of code. The annotated part is the code saved to the sqlite database. Choose one of the two
The main method of saving to xls is saveData (the following saveData2DB method is to save to sqlite database):
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #Create workbook object
sheet = book.add_sheet('Douban film Top250', cell_overwrite_ok=True) #Create worksheet
col = ("Movie details link","pictures linking","Chinese name of the film","Film foreign name","score","Number of evaluations","survey","Relevant information")
for i in range(0,8):
sheet.write(0,i,col[i]) #Listing
for i in range(0,250):
# print("The first%d strip" %(i+1)) #Output statements for testing
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #data
book.save(savepath) #preservationCreate worksheets and columns (they will be created in the current directory),
sheet = book.add_sheet('Douban film Top250', cell_overwrite_ok=True) #Create worksheet
col = ("Movie details link","pictures linking","Chinese name of the film","Film foreign name","score","Number of evaluations","survey","Relevant information")Then save the data in the dataList one by one.
Finally, after successful operation, such a file will be generated on the left

Open it and see if it's the result we want

Yes, yes!
As a passer-by, I would like to talk to you about my self-study experience, hoping to help you avoid detours and stepping on pits.
More Python, crawler, artificial intelligence supporting video tutorials + books can be + v free of charge.
If you have problems in direction selection, learning planning, learning route and career development, you can add a group: 809160367

