Previously, I wrote a basic case of reptile --- introduction to glory heroes and skills of crawling king
python crawler ------ King glory hero and skills crawl and save information to excel https://blog.csdn.net/knighthood2001/article/details/119514336?spm=1001.2014.3001.5501 Sharp eyed people can find that the data they climb is incomplete (heroes lack).
https://blog.csdn.net/knighthood2001/article/details/119514336?spm=1001.2014.3001.5501 Sharp eyed people can find that the data they climb is incomplete (heroes lack).
import requests
import re
import pandas as pd
base_url = 'https://pvp.qq.com/web201605/herolist.shtml'
headers = {
'referer': 'https://pvp.qq.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(base_url, headers=headers)
response.encoding = 'gbk'
r = response.text
# print(response.text)
# The output is all the source code of the web page
# Because the hero's website is out of order, re is used
wangzhi = re.compile(r'<a href="herodetail/(\d*).shtml" target="_blank"')
hero_xuhao_list = re.findall(wangzhi, r)
# print(hero_xuhao_list)
df = []
# Title Block
columns = ['hero', 'passive', 'Skill 1', 'Skill 2', 'Skill 3', 'Skill 4']
for id in hero_xuhao_list:
detail_url = 'https://pvp.qq.com/web201605/herodetail/{}.shtml'.format(id)
# print(detail_url)
response1 = requests.get(detail_url, headers=headers)
response1.encoding = 'gbk'
# print(response1.text) # Get all the source code of the specific website
names = re.compile('<label>(.*?)</label>')
name = names.findall(response1.text)[0]
# Without this [0], the data in excel will be ['yunzhongjun'], that is, there are quotation marks and [] outside the Chinese name
skills = re.compile('<p class="skill-desc">(.*?)</p>', re.S)
skill = skills.findall(response1.text)
# print(skill)
beidong = skill[0]
# print(beidong)
jineng1 = skill[1]
jineng2 = skill[2]
jineng3 = skill[3]
jineng4 = skill[4]
b = df.append([name, beidong, jineng1, jineng2, jineng3, jineng4])
d = pd.DataFrame(df, columns=columns)
# index=False indicates that the output does not display the index value
d.to_excel("King glory heroes and skills.xlsx", index=False)
This is the link inside the source code, easy to read.
1, Difference between web page source code and elements
1. Examples
First open the website where all heroes of the glory of the king are located
Hero information list page - Hero introduction - King glory official website - Tencent game
Right click to see the view web page source code and check - Review element options.
View web page source code (the following figure is a partial screenshot)

Check -- elements
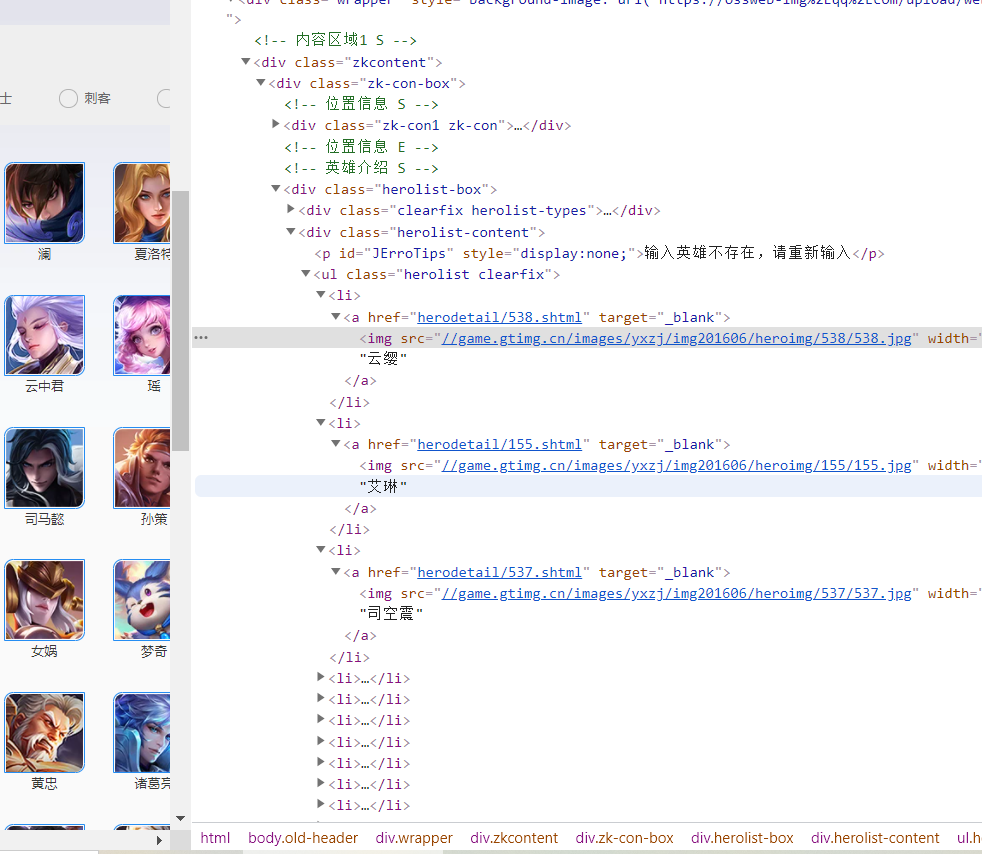
Looking at the web page source code and the page of check review elements look the same, but if you count them in detail, you will find that the information about Yunying Yao's hero is missing in the web page source code.
2. Reasons
View source code: the intact code sent by others to the browser.
Check - Review element: what you see is the final html code. Namely: source code + web page js rendering.
Therefore, viewing the web page source code and checking the content in the review element are not necessarily the same.
The response.text crawled by the requests module is actually the content in the web page source code and is not rendered by the web page js.
Therefore, the previous code was crawled according to the web page source code, and there was a lack of data.
2, Solution
1. Find data storage files
We need to find out which file the data exists in,
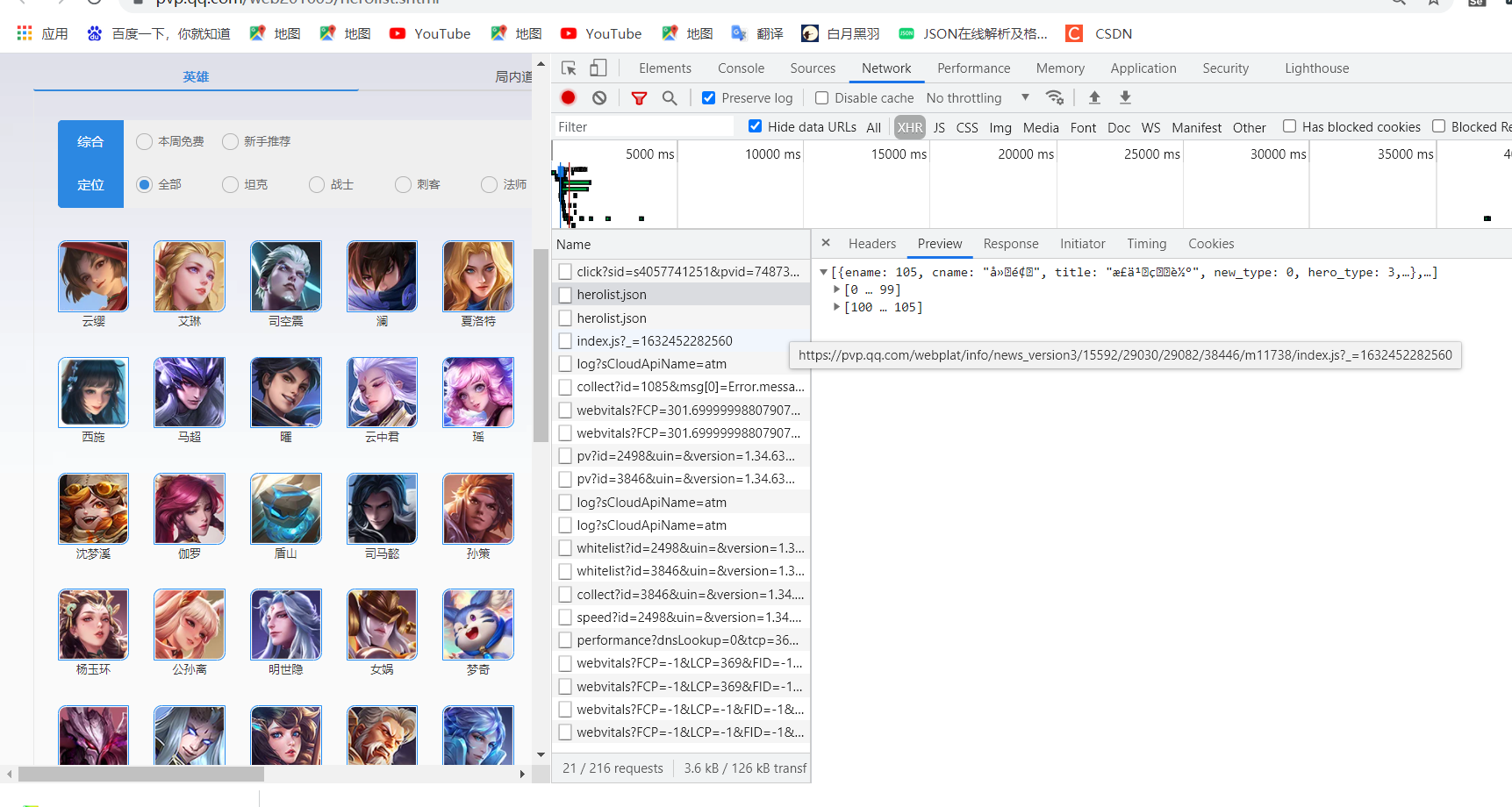
After searching, we found that the king's glory hero is stored in the herolist.json file.
2. Handle json files
The website of herolist.json is https://pvp.qq.com/web201605/js/herolist.json
The web page displays the garbled format. The Chinese in json can be displayed normally through the following code
import requests
url = 'https://pvp.qq.com/web201605/js/herolist.json'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)
print(response.text)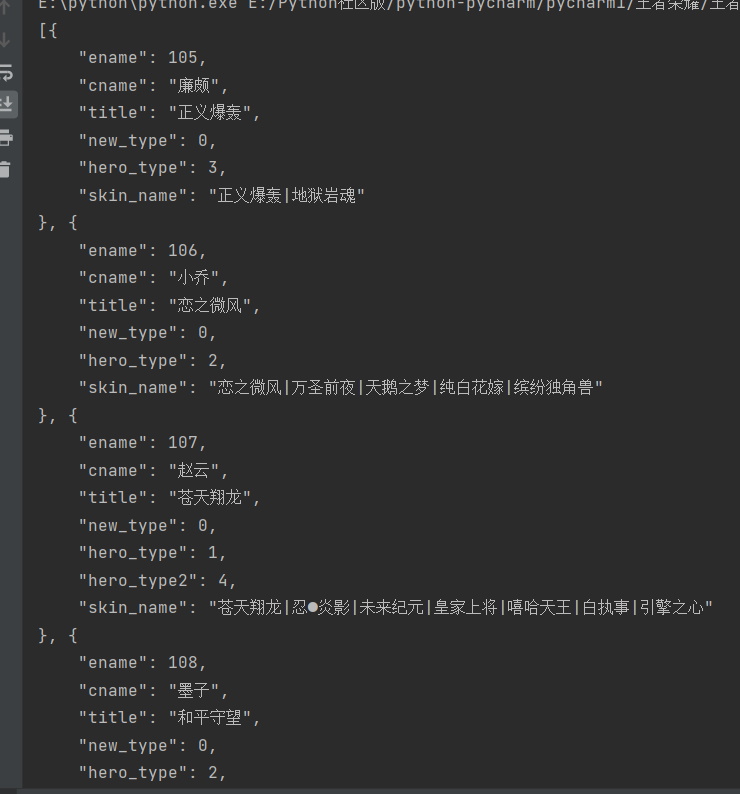
herolist = json.loads(response.text)
Convert other types of objects into python objects through json.loads() to facilitate subsequent processing.
Note the difference between load and loads. Loads () operates on strings, while load () operates on file streams.
https://pvp.qq.com/web201605/herodetail/538.shtml
https://pvp.qq.com/web201605/herodetail/155.shtml
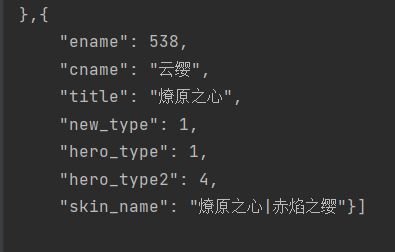
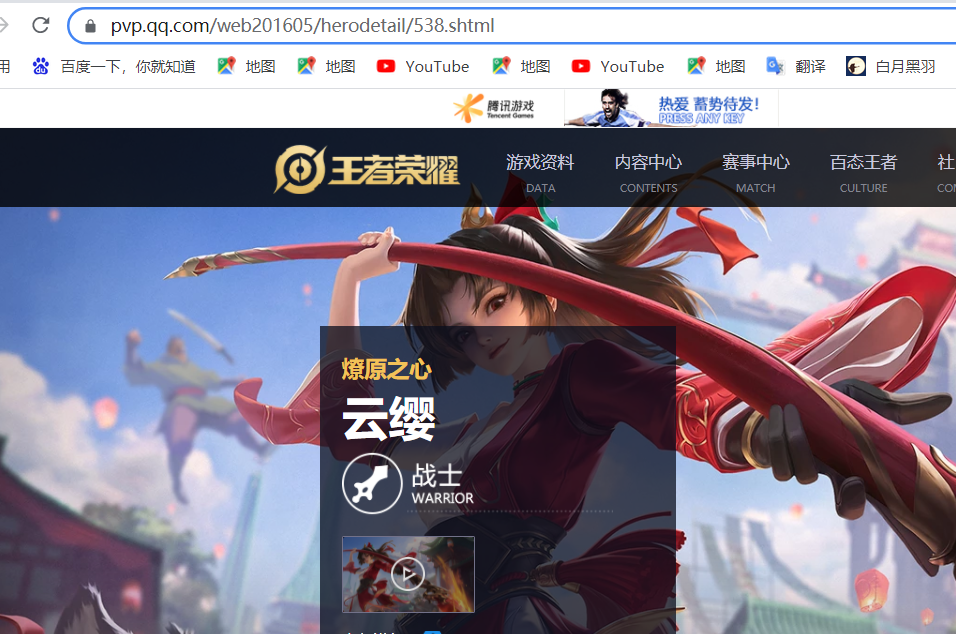
It can be found that the number of ename in the json file is the number that constitutes the specific hero web page, so we need ename,
ename = []
for item in herolist:
herolist_ename = item["ename"]
ename.append(herolist_ename)The purpose of this code is to traverse herolist and store the value of ename in the ename list.

The upper line is the content of herolist, and the lower line is the content of the ename list.
3, Crawling related data
After crawling to ename, you can traverse it and construct a url for crawling. The crawling steps are the same as before.
python crawler ------ King glory hero and skills crawl and save information to excel
base_url = "https://pvp.qq.com/web201605/herodetail/{}.shtml"
df = []
# Title Block
columns = ['hero', 'passive', 'Skill 1', 'Skill 2', 'Skill 3', 'Skill 4']
a = 1
for i in ename:
# print(i)
true_url = base_url.format(i)
r = requests.get(true_url, headers=headers)
r.encoding = "gbk"
names = re.compile('<label>(.*?)</label>')
name = names.findall(r.text)[0]
# Used to display the number of heroes
print(str(a) + name)
a += 1
# Without this [0], the data in excel will be ['yunzhongjun'], that is, there are quotation marks and [] outside the Chinese name
skills = re.compile('<p class="skill-desc">(.*?)</p>', re.S)
skill = skills.findall(r.text)
# Data cleaning
beid = skill[0]
beidong = beid.replace("Passive:", "")
jineng1 = skill[1]
jineng2 = skill[2]
jineng3 = skill[3]
jineng4 = skill[4]
b = df.append([name, beidong, jineng1, jineng2, jineng3, jineng4])
d = pd.DataFrame(df, columns=columns)
# index=False indicates that the output does not display the index value
d.to_excel("King glory heroes and skills.xlsx", index=False)Since most of the hero's passive texts contain passive:, while a small part do not have these contents, it is necessary to
beidong = beid.replace("passive:", "") this code is used for data collation.
4, All code display
import requests
import json
import re
import pandas as pd
url = 'https://pvp.qq.com/web201605/js/herolist.json'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)
# print(response.text)
herolist = json.loads(response.text)
# print(herolist)
ename = []
for item in herolist:
herolist_ename = item["ename"]
ename.append(herolist_ename)
# print(ename)
base_url = "https://pvp.qq.com/web201605/herodetail/{}.shtml"
df = []
# Title Block
columns = ['hero', 'passive', 'Skill 1', 'Skill 2', 'Skill 3', 'Skill 4']
a = 1
for i in ename:
# print(i)
true_url = base_url.format(i)
r = requests.get(true_url, headers=headers)
r.encoding = "gbk"
names = re.compile('<label>(.*?)</label>')
name = names.findall(r.text)[0]
# Used to display the number of heroes
print(str(a) + name)
a += 1
# Without this [0], the data in excel will be ['yunzhongjun'], that is, there are quotation marks and [] outside the Chinese name
skills = re.compile('<p class="skill-desc">(.*?)</p>', re.S)
skill = skills.findall(r.text)
# Data cleaning
beid = skill[0]
beidong = beid.replace("Passive:", "")
jineng1 = skill[1]
jineng2 = skill[2]
jineng3 = skill[3]
jineng4 = skill[4]
b = df.append([name, beidong, jineng1, jineng2, jineng3, jineng4])
d = pd.DataFrame(df, columns=columns)
# index=False indicates that the output does not display the index value
d.to_excel("King glory heroes and skills.xlsx", index=False)
5, Result display
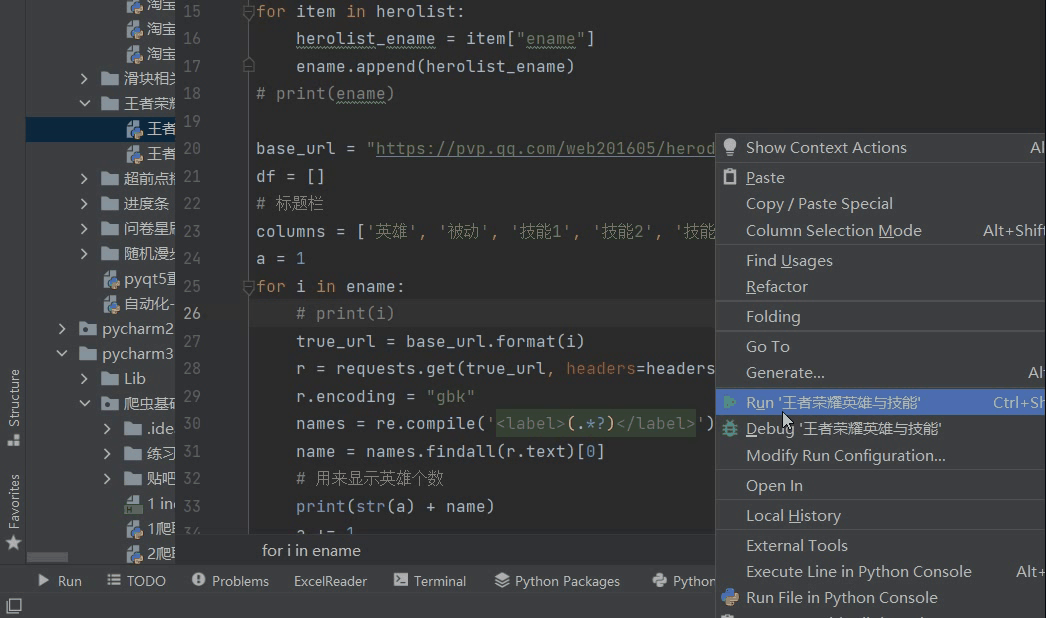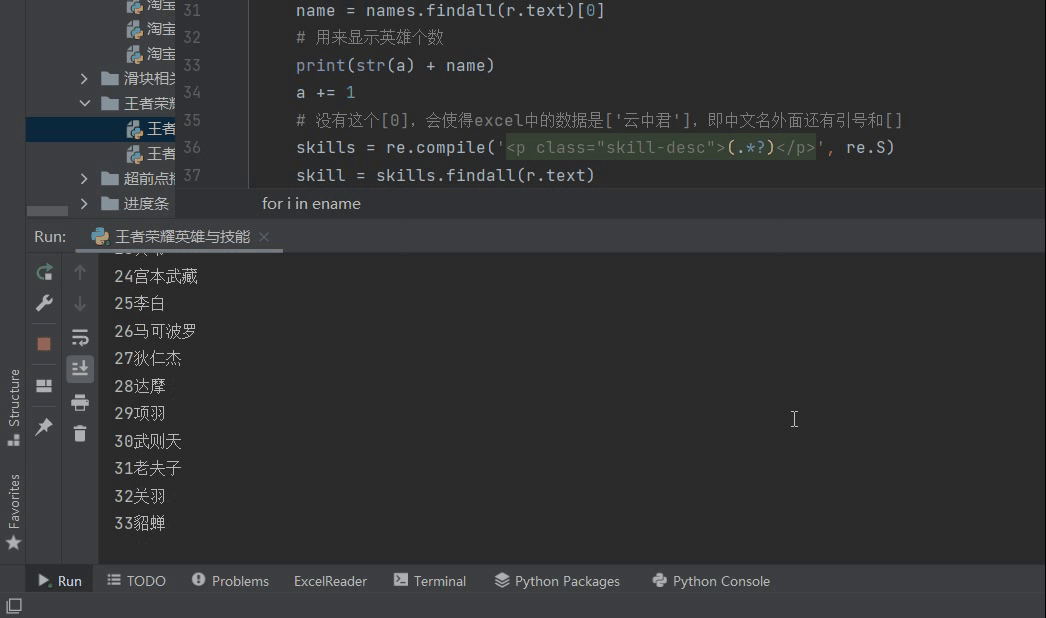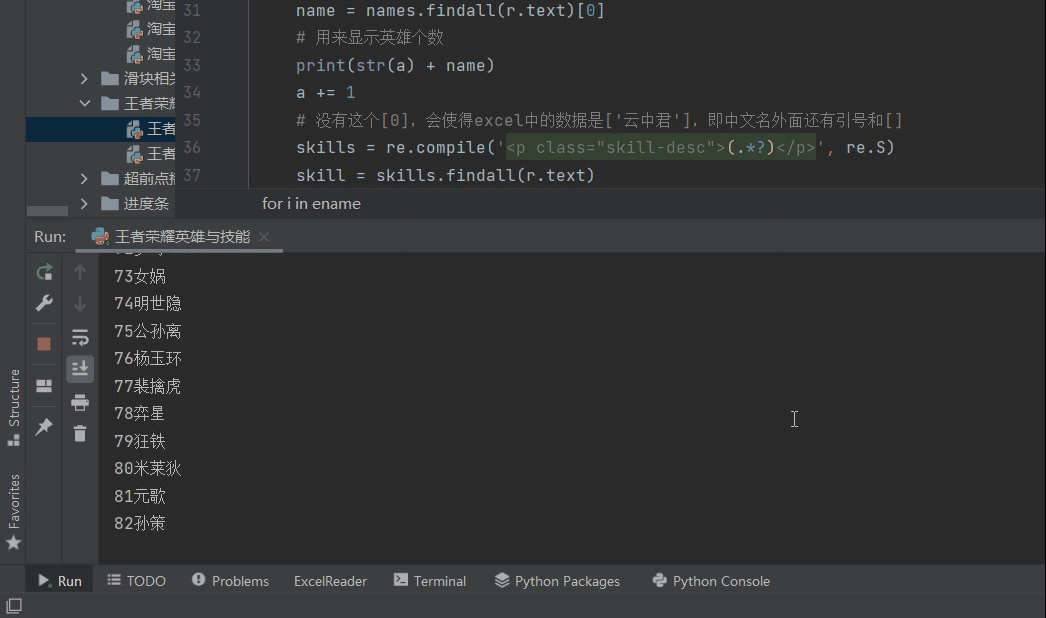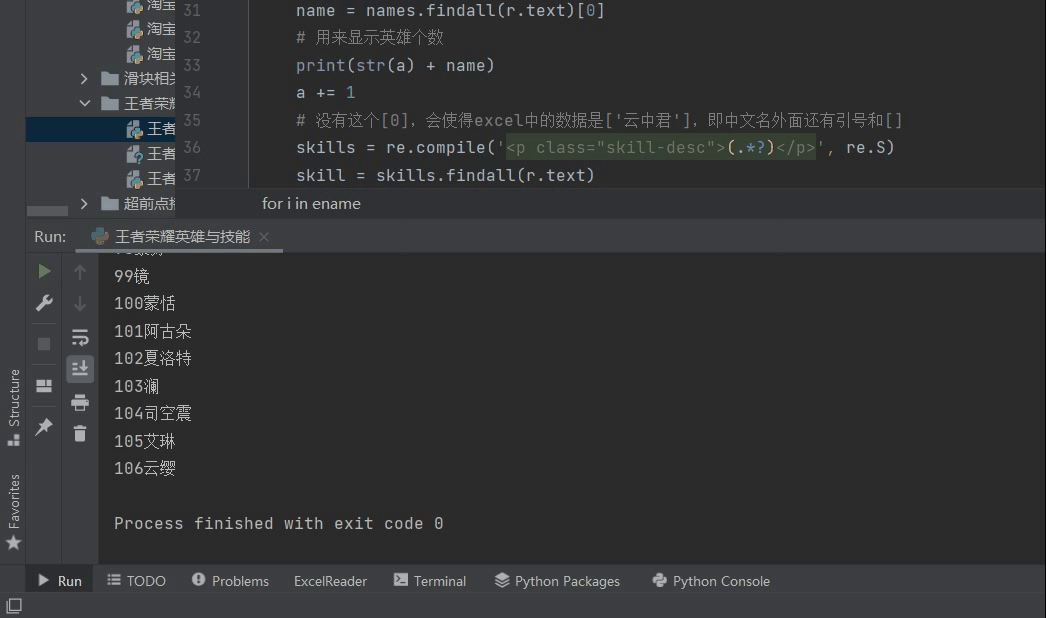
6, Summary
When the data is hidden in a json file, first find the corresponding file. Next, perform a series of operations such as parsing.
I tried lxml and bs4 parsing, and found that the steps are very cumbersome. Lxml is often parsed as [].
So be honest and practical
After climbing, I found that there are 106 heroes in the glory of the king. I don't care about them when I go on the number 👀👀.
❤ If you think it's helpful, give it to the third company!!! ❤