When I first entered the world of mortals, I didn't know the suffering of the world,
When I look back, I am already a bitter man.
One third of the wine in this glass,
This wine is sad.
Shut it down, shut it down,
It's hard every night.
May love and hatred in this world melt into wine,
Turn this dust into wine
A drink to relieve your worries!
This is a sentence from the poetry book on the pillow. When I read it roughly, there was a breath of "net suppressing cloud", which scared me to open my collection and observe it. Sure enough, it was pleasant to see beautiful women

what! You have no collection! I'll teach you how to have your own collection today.
Today, let's climb the other shore website. This website is relatively simple and suitable for novices to practice (pay attention not to be too hard, this will still be sealed)
Let's talk about my development environment: Python 3.8
Computer system: Windows10
Development tool: pycharm
Packages to use: requests, os, re
website: https://pic.netbian.com/
Open the website and check it first. It is found that the pictures are stored in the img tag in the li tag, but the thumbnails are stored here. If you want a high-definition image, you need to crawl the link in the a tag. After entering, you can crawl the high-definition image
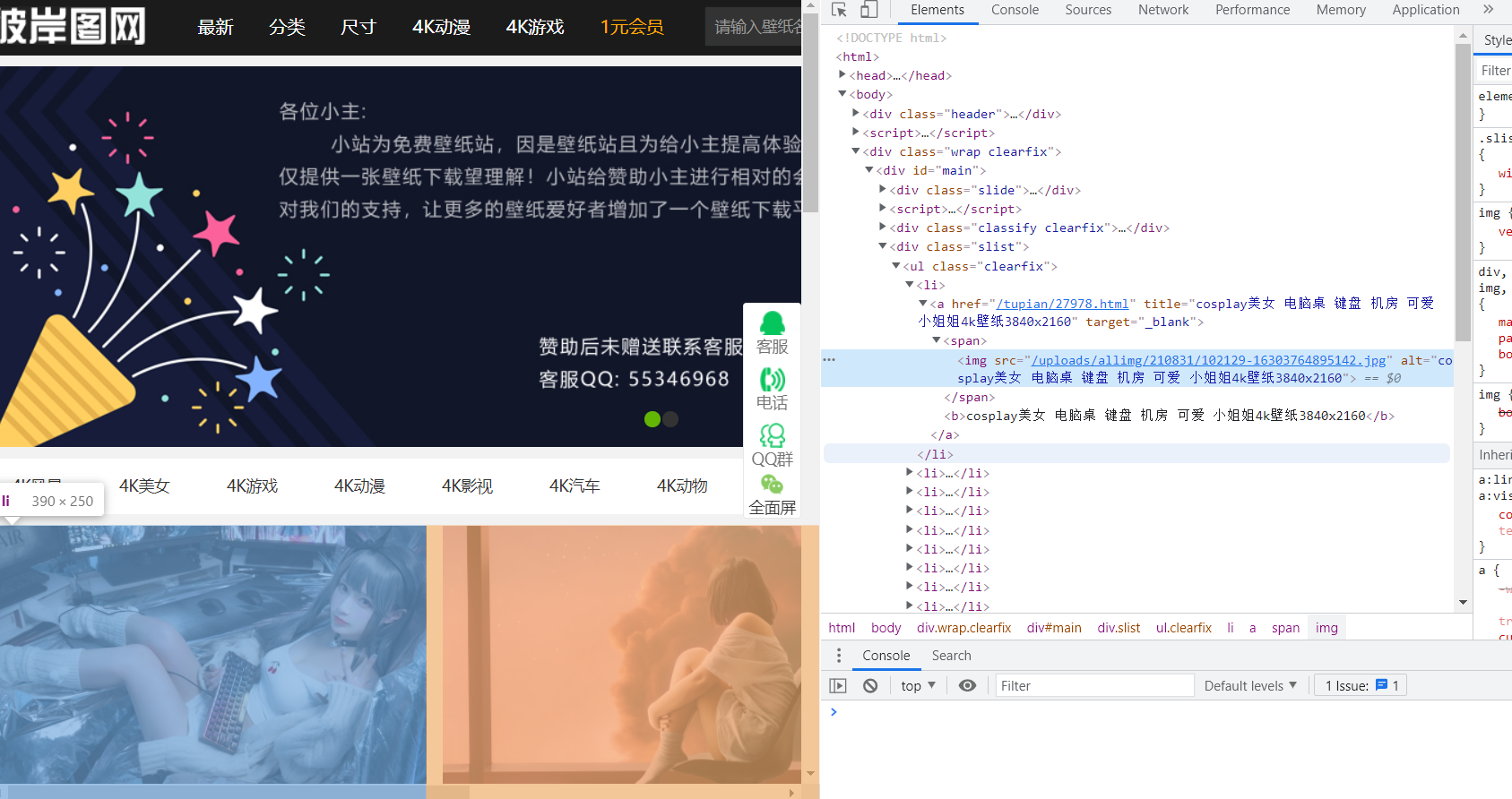
Get the data of this page first
import os
import re
import requests
def get_page(url, headers):
response = requests.get(url=url, headers=headers)
response.encoding = 'gbk' # Note here that the code of this website is gbk. If you set it
if response.status_code == 200:
return response.text
Note here that the code of this website is gbk. If you set it
def main():
url = 'https://pic.netbian.com/'
headers = {
'User-Agent': 'Fiddler/5.0.20204.45441 (.NET 4.8; WinNT 10.0.19042.0; zh-CN; 8xAMD64; Auto Update; Full Instance; Extensions: APITesting, AutoSaveExt, EventLog, FiddlerOrchestraAddon, HostsFile, RulesTab2, SAZClipboardFactory, SimpleFilter, Timeline)'
}
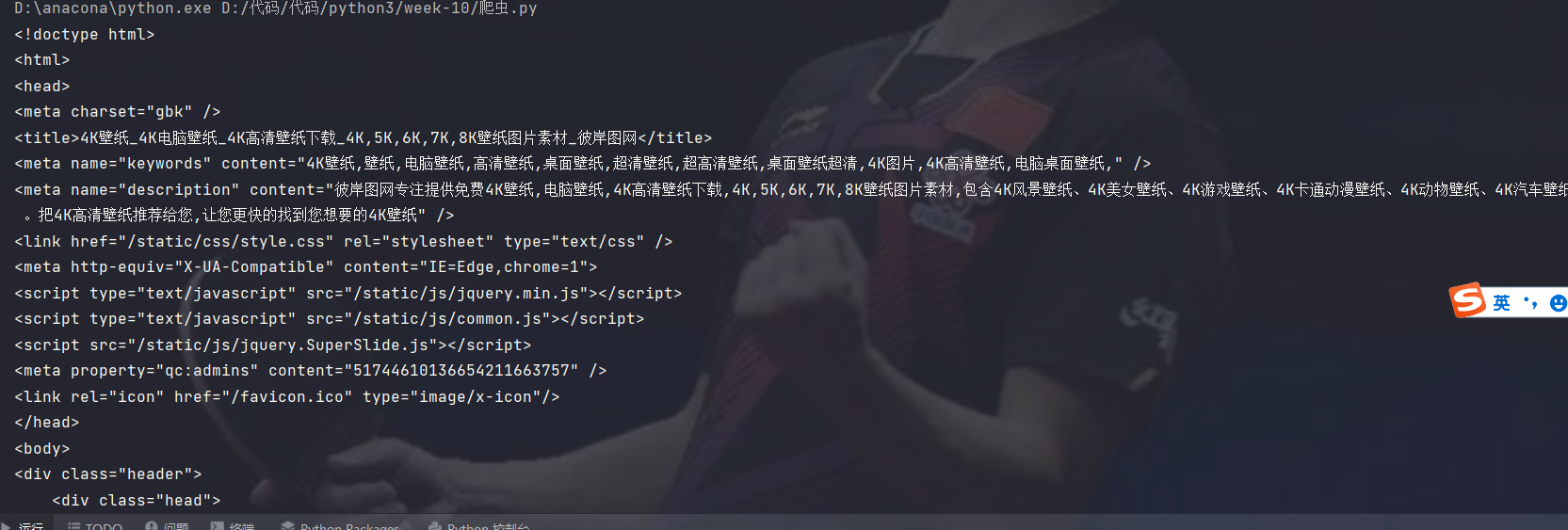
html = get_page(url,headers)
print(html)
if __name__ == '__main__':
main()
Remember to set up UA camouflage every time you write about reptiles
Open a web page F12 to check, click Network, click any one in the Name, slide down on the right, find the user agent, copy it, and change the format to dictionary type. For details, refer to the code above and the picture below
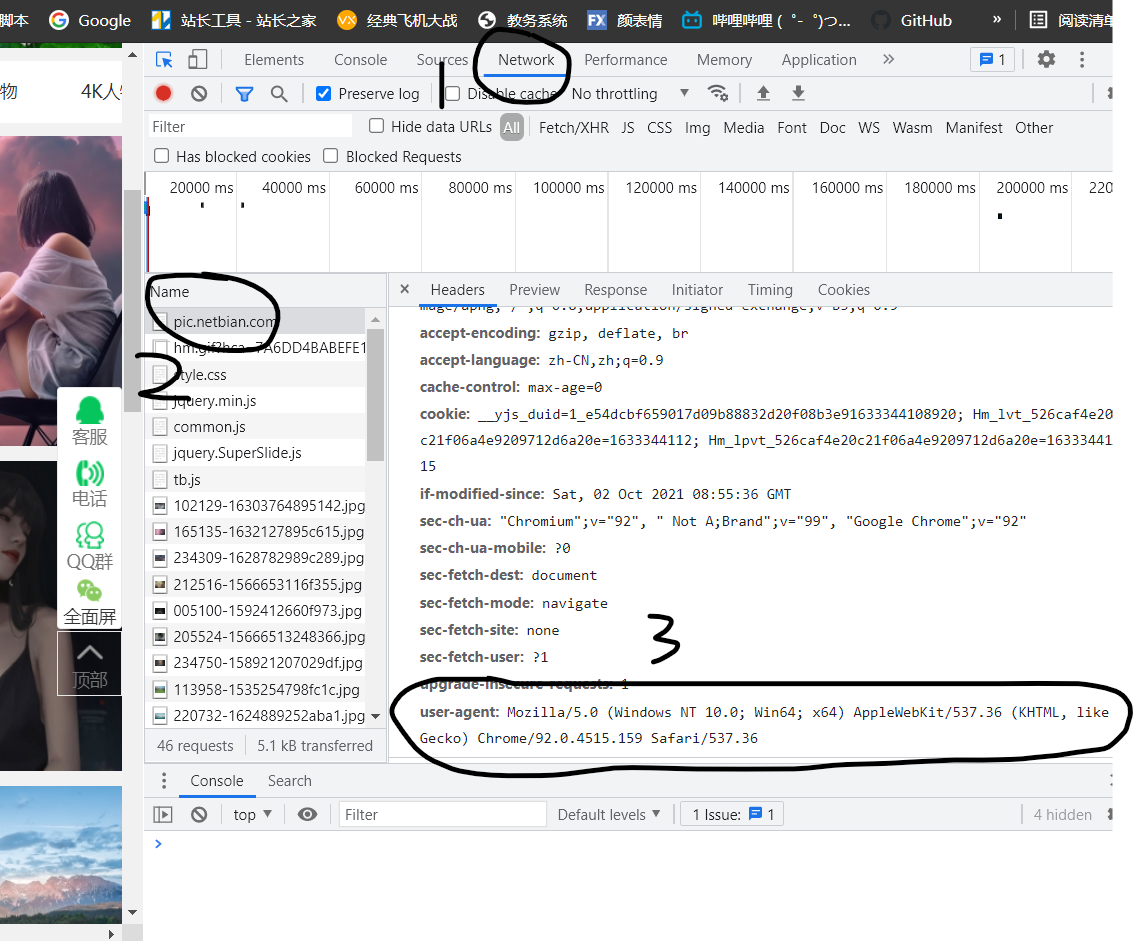
Run to get the source code of the web page
Because I want to get all the links in the a tag, I use re here to match the links with regular expressions
def analysis(html):
pattern = re.compile('<li><a href="(.*?)" title=')
links = re.findall(pattern, html)
print(links)

We can see that we have got all the links, but there are two uninvited visitors who can be divided by index. Another problem is that these links are incomplete. We have to splice them ourselves

You can see the missing content, as shown in the figure above. We can add it in front
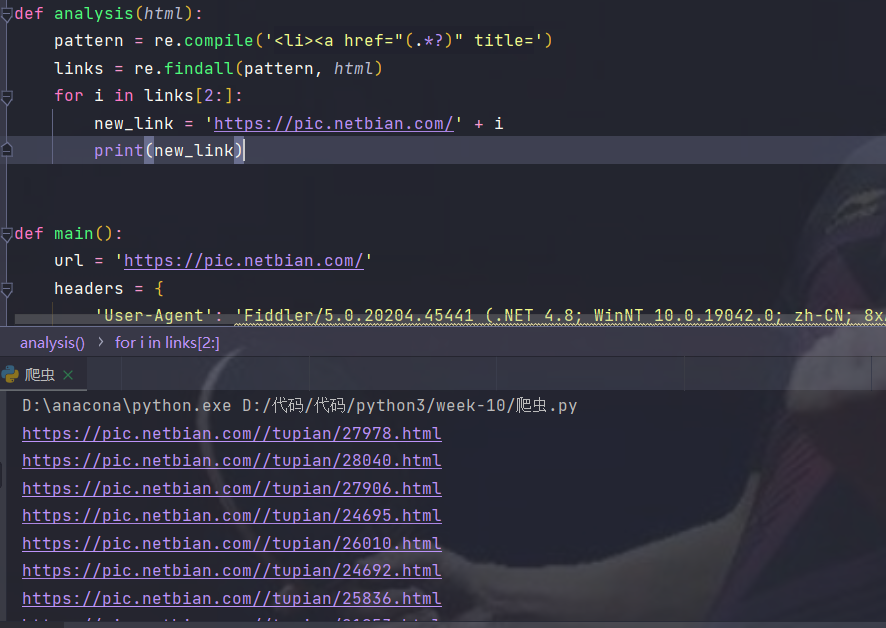
You can see that these links have been spliced into complete links and can be accessed. Create an empty list and put the links in. The first part has been written. Let's write a cycle to access these links and get picture information from them
Parse the web page with the previously written get_page() is OK
The parsed page source code is then regularly matched to get the picture link and name to prepare for future storage
These links are still incomplete and need to be spliced. Before splicing, use '. join() to convert them to string type, because re.findall() returns a list
def analysis2(html):
name = re.compile('<h1>(.*?)</h1>')
new_name = re.findall(name, html)
pattern = re.compile('<a href="" id="img"><img src="(.*?)" data')
img = re.findall(pattern, html)
img = ''.join(img)
new_name = ''.join(new_name)
new_ink = 'https://pic.netbian.com' + img
return new_name, new_ink
Here, return returns a tuple and uses the index directly to get the desired content
For persistent storage, you need to create a folder first, otherwise it will be directly stored in your current folder
I created a new happy folder
if not os.path.exists('./happy'):
os.mkdir('./happy')
for i in inks:
html = get_page(i, headers)
ink = analysis2(html)
ee = requests.get(url=ink[1], headers=headers).content
new_img_name = 'happy/' + ink[0] + '.jpg'
with open(new_img_name, 'wb') as f:
f.write(ee)
print(new_img_name, 'Download succeeded')
Store with with and you're done


This is not very happy!!
These codes are relatively simple without comments (it's not that I don't want to write them)
All codes are as follows:
import os
import re
import requests
if not os.path.exists('./happy'):
os.mkdir('./happy')
def get_page(url, headers):
response = requests.get(url=url, headers=headers)
response.encoding = 'gbk'
if response.status_code == 200:
return response.text
def analysis(html):
list_links = []
pattern = re.compile('<li><a href="(.*?)" title=')
links = re.findall(pattern, html)
for i in links[2:]:
new_link = 'https://pic.netbian.com' + i
list_links.append(new_link)
return list_links
def analysis2(html):
name = re.compile('<h1>(.*?)</h1>')
new_name = re.findall(name, html)
pattern = re.compile('<a href="" id="img"><img src="(.*?)" data')
img = re.findall(pattern, html)
img = ''.join(img)
new_name = ''.join(new_name)
new_ink = 'https://pic.netbian.com' + img
return new_name, new_ink
def main():
url = 'https://pic.netbian.com/'
headers = {
'User-Agent': 'Fiddler/5.0.20204.45441 (.NET 4.8; WinNT 10.0.19042.0; zh-CN; 8xAMD64; Auto Update; Full Instance; Extensions: APITesting, AutoSaveExt, EventLog, FiddlerOrchestraAddon, HostsFile, RulesTab2, SAZClipboardFactory, SimpleFilter, Timeline)'
}
html = get_page(url, headers)
inks = analysis(html)
for i in inks:
html = get_page(i, headers)
ink = analysis2(html)
ee = requests.get(url=ink[1], headers=headers).content
new_img_name = 'happy/' + ink[0] + '.jpg'
with open(new_img_name, 'wb') as f:
f.write(ee)
print(new_img_name, 'Download succeeded')
if __name__ == '__main__':
main()
Just 57 lines of code to achieve happiness, is the happiness of men so simple!!