1. Gradually construct convolution network
The basic network architecture built this time:
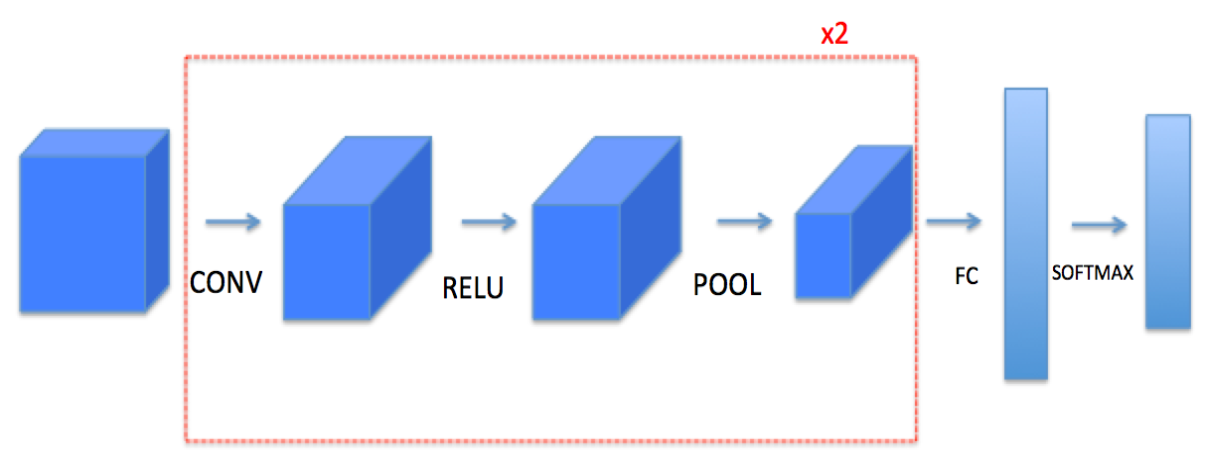
Note: for each forward propagation operation, there will be corresponding backward propagation. The parameters of forward propagation will be stored, and these parameters will be used to calculate the gradient in the backward propagation process.
2. Convolutional neural network
2.1 zero value filling
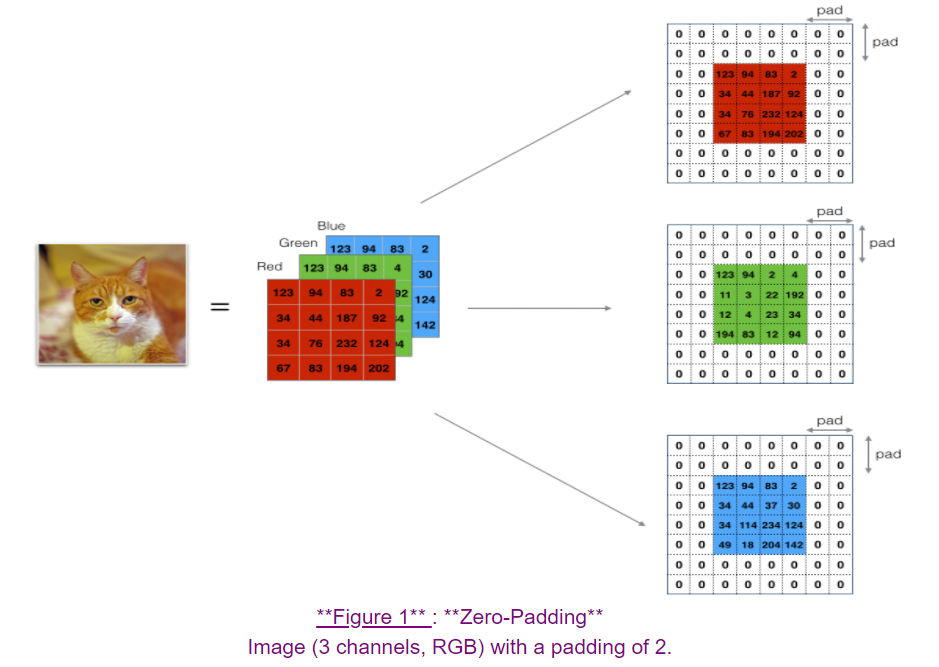
Benefits of zero padding:
- Filling helps you use the convolution layer without shrinking the height and width of the input data, which is very important in the depth network;
- Help preserve picture edge information
Introduction to using function numpy.pad:
numpy.pad(array, pad_width, mode='constant', **kwargs)
Array: array to fill
pad_width:(before,after) simply means filling in the front and the back. For example, (2,3) means filling in 2 before filling in 3
"Constant": it is a constant by default, and you can choose another one
2.2 one step in convolution
In this section, a single step of convolution is implemented, and the filter is applied to a single position of the input. This will be used to build the convolution unit.
2.3 forward propagation of convolutional neural network
In this section, a single filter is used for convolution, and the result is 2D. The results are superimposed to generate a 3D result.
Process:
1. Select a slice 2 * 2
Tip: a_slice_prev = a_prev[0:2,0:2,: ] “a_prev” (shape (5,5,3))
2. Define a slice
Four corners need to be defined: vert_start, vert_end, horiz_start ,horiz_end
vert_start = h * stride
vert_end = vert_start + f
horiz_start = w * stride
horiz_end = horiz_start + f
Define 3D slices:
a_slice_prev = a_prev_pad[vert_start : vert_end, horiz_start : horiz_end, :]
2.4 pool layer
2.4.1 forward pooling
Design maximum pool layer and average pool layer
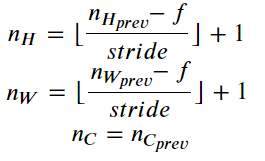
2.5 backward propagation (optional)
2.5.1 convolution network inversion method
Formula:
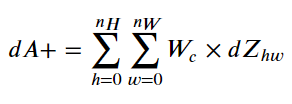
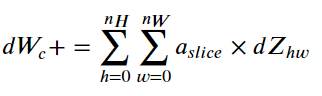
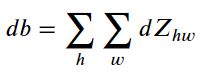
2.5.2 reverse extrapolation method of pool layer
2.5.2.1 maximum pooling
Before starting to maximize the pool, first construct an auxiliary function create_mask_from_window(), whose function is to maximize pooling. The maximum element position is displayed as 1, and the rest are set to 0. A similar method will be used for average pooling after that, but the "Mask" used is different.
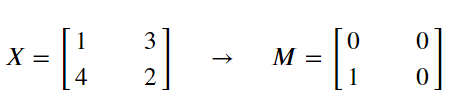
Note: multiple maximum values are not considered temporarily.
Why do we track max's position? This is because it will affect the final cost. BackProp calculates the gradient relative to the cost, so anything that affects the final cost should have a non-zero gradient. Therefore, BackProp "propagates" the gradient back to the specific input value (i.e. the maximum value) that affects the cost.
Maximum pooling:
mask = (x == np.max(x))
Note: not only the maximum value should be found, but also the result of 1 / 0 should be given by comparison.
2.5.2.2 average pooling
The difference between average pooling and maximum pooling is that each element affects the output value. Unlike maximum pooling, only the maximum value needs to be considered.
Construct auxiliary functions for average pooling.
Function Description:
numpy.ones(shape, dtype=None, order='C')
Returns an array filled with 1 according to the given type.
np.ones(5) array([ 1., 1., 1., 1., 1.])
The default number type is floating point number, which can be set.
np.ones((5,), dtype=np.int) array([1, 1, 1, 1, 1])
s = (2,2)
np.ones(s)
array([[ 1., 1.],
[ 1., 1.]])
The final realization is as follows:
def distribute_value(dz, shape):
"""
Distributes the input value in the matrix of dimension shape
Arguments:
dz -- input scalar
shape -- the shape (n_H, n_W) of the output matrix for which we want to distribute the value of dz
Returns:
a -- Array of size (n_H, n_W) for which we distributed the value of dz
"""
### START CODE HERE ###
# Retrieve dimensions from shape (≈1 line)
(n_H, n_W) = shape#shape is a tuple and cannot perform the functions of. shape
# Compute the value to distribute on the matrix (≈1 line)
average = dz/(n_H*n_W)
# Create a matrix where every entry is the "average" value (≈1 line)
a = average*np.ones(shape)
### END CODE HERE ###
return a
Use np.ones(shape) to arrange the generated average values into an array with the same format as the input.
2.5.2.3 push the pool back together
Records of key steps:
1. Set dA_prev
dA_prev[i, vert_start:vert_end, horiz_start:horiz_end, c] += np.multiply(mask , dA[i, h, w, c])