preface
Recently, I systematically studied the basic knowledge of python once, and thought of whether there was a way to master knowledge quickly. The general normal logic is to practice cases while reading basic knowledge, which is a process from thick to thin.
But now the pace is so fast, especially Internet companies. Excluding the time to watch children at home on weekends, they have little time and energy to further study, so this article was born.
This paper starts with cases and directly combines python knowledge points, which can quickly master the basic knowledge points of python.
Case name
- Calculate circular area
- Input characters and output in reverse order
- Figure guessing game
- Output poetry in the form of verse
- Count the 10 words that appear most frequently in the text (txt)
- web page element extraction
- Text progress bar
Calculate circular area
Knowledge points: print combines the format () function to realize the output format.
Fixed formula:
print(<Output string template>.format(<Variable 1>,<Variable 2>,<Variable 3>))
Implementation code:
r = 25 # The radius of the circle is 25
area = 3.1415 * r * r #Formula of circle
print(area)
print('{:.2f}'.format(area) ) # Only two decimal places are output
Novice error prone points:
The string template format '{:. 2f}' before format is often written incorrectly, and one {} corresponds to a parameter in format.
Input characters and output in reverse order
Core idea: find the last element and output it.
Knowledge points:
- Input uses the input function
- The len() function is used to calculate the length
- End = '' is used at the end of the output function to add an empty string after the output character
#Enter text
s=input('Please enter a text:')
#Calculate the length of the input content and assign it to I = len (s) - 1
#Reverse cycle output
while i>=0:
print(s[i],end='')
i=i-1
Implementation effect: the code can be executed
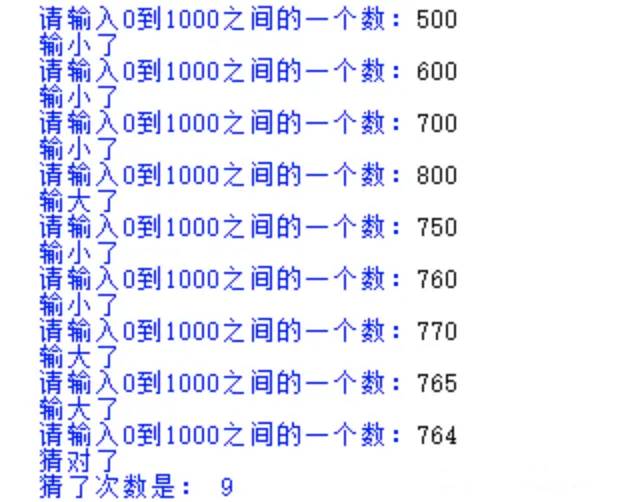
Figure guessing game
Randomly generate a number and judge the input number and the random number until the guess is successful.
Knowledge points:
- Use the random. Random() function to generate a random number
- while() loop. When the condition is not met, it will be executed all the time. If the condition is met, break will jump out of the loop
- The input number eval function, combined with input, converts the string type to an integer
- If three branch conditional judgment, if elif else format
Implementation code:
import random
#Generate random number
a=random.randint(0,1000)
#Statistical times
count=0
while True:
number=eval(input('Please enter a number between 0 and 1000:'))
count=count+1
#Judge and compare two numbers
if number>a:
print('I lost a lot')
elif number<a:
print('The loss is small')
else:
print('You guessed right')
break
print('The number of guesses is:',count)
Renderings: code can be executed
Output poetry in the form of verse
Original format:
When you are happy in life, don't make the golden cup empty to the moon.
I'm born to be useful. I'll come back after I've lost a thousand gold.
Output effect:
Life must be full of joy
Don't make the golden cup empty to the moon
I'm born to be useful
A thousand gold coins are scattered and come back
Design idea:
- Replace all punctuation marks with \ n
- Text centered display
Knowledge points:
- Replace function line.replace (variable name, value to be replaced)
- Center align line.center (width)
- Function call to pass the text variable txt into the replacement function linesplit
txt = '''
When you are happy in life, don't make the golden cup empty to the moon.
I'm born to be useful. I'll come back after I've lost a thousand gold.
'''
#Defines a function that implements the replacement of punctuation with \ n
def linesplit(line):
plist = [',', '!', '?', ',', '. ', '!', '?']
for p in plist:
line=line.replace(p,'\n')
return line.split('\n')
linewidth = 30 # Predetermined output width
#Define a function to achieve center alignment
def lineprint(line):
global linewidth
print(line.center(linewidth))
#Call function
newlines=linesplit(txt)
for newline in newlines:
lineprint(newline)
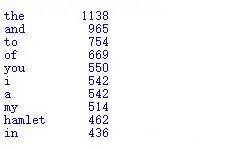
Count the 10 words that appear most frequently in the text
Let's look at the implementation effect:
Step split:
- First, unify the text content into lowercase and use the lower() function
- Again, replace the special characters in the text with spaces and use the replace() function
- Cut the text by space, using the split() function
- Count the number of words
- sort() function by frequency from large to small
- Output in a fixed format, using the format() function
Follow the steps above to implement the code.
First, unify the text content into lowercase and use the lower() function:
def gettxt():
#read file
txt=open('hamlet.txt','r').read()
txt=txt.lower()
Again, replace the special characters in the text with spaces, and the replace() function:
for ch in ''!"#$%&()*+,-./:;<=>?@[\]^_'{|}~':'
txt=txt.replace('')
return txt
Cut the text by spaces, using the split() function:
hmlttxt=gettxt() words=hmlttxt.split()
Count the number of occurrences of words:
counts=0
for word in words:
counts[word]=counts.get(word,0)+1
#Count the frequency of word occurrence. When word is not in words, the return value is 0. When word is in words, it returns + 1 for cumulative counting
Sort items() sort() sort function by frequency from large to small:
items=list(counts.items()) items.sort(key=lambada x:x[1],reverse=True)
The above x can be any letter, reverse=True, in reverse order, in ascending order by default.
Output in a fixed format, using the format() function:
for i in range(10)
word,count=item[i]
print('{0:<10}{1:>5}'.format(word,count))
Full code:
# First, unify the text content into lowercase and use the lower() function
def gettxt():
txt=open('hamlet.txt','r').read()
txt=txt.lower()
# Replace special characters in text with spaces, and replace() function
for ch in '!"#$%&()*+,-./:;<=>?@[\]^_'{|}~':
txt=txt.replace(ch,'')
return txt
# Cut the text by space, using the split() function
hamlettxt=gettxt()
words=hamlettxt.split()
# Count words
counts={}
for word in words:
counts[word]=counts.get(word,0)+1
# sort() function by frequency from large to small
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
# Output in a fixed format, using the format() function
for i in range(10):
word, count=items[i]
print("{0:<10},{1:>5}".format(word,count))
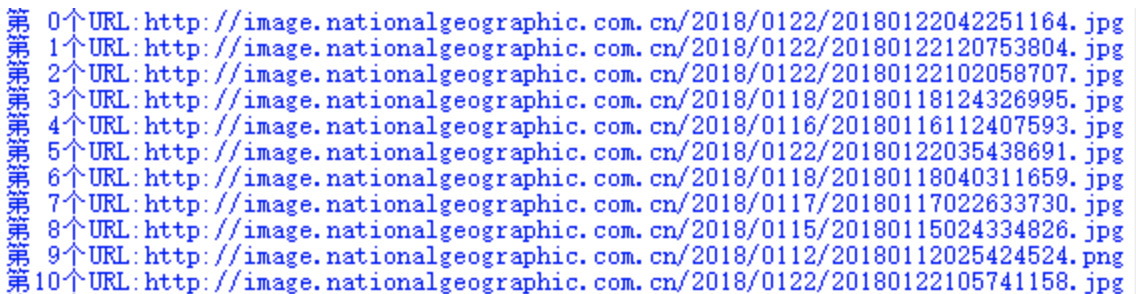
Extracting image url path information from web page elements
The purpose of this function is to replace functions and top-down design ideas.
Achieved results:
The whole function is divided into the following processes:
- First, extract all the elements of the page
- Secondly, extract the url path of the picture
- Then, the path information is output and displayed
- Finally, save these paths to a file
We encapsulate the above steps into a function, and finally call the main () function, in which the url path of the extracted image is the core.
- Extract all elements of the page
Knowledge points involved: file opening, reading and closing.
def gethtmllines(htmlpath): #file open f=open(r,'htmlpath',encoding='utf-8') #File reading ls=f.readlines() #File close f.close() return ls
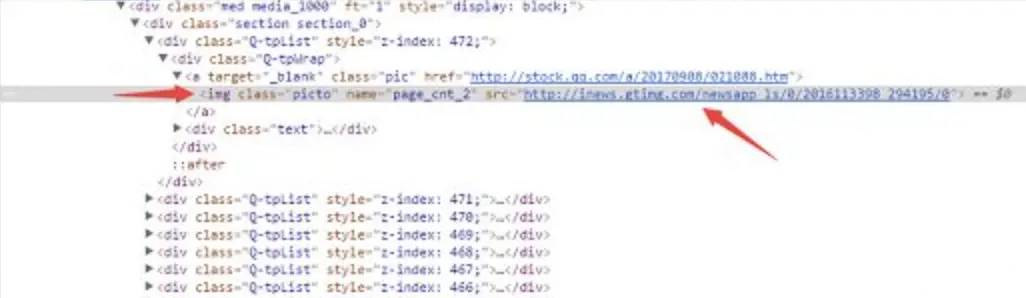
- Extract the url path of the picture
Source code:
Knowledge points:
- Store the intercepted address in list form
- Cut list, split() function
def geturl(ls):
urls=[]
for line in ls:
if 'img' in line:
url=line.split('src=')[-1].split('"')[1]
urls.append(url)
- Output path information to display
Knowledge point: the for loop outputs the path information.
for Loop to output path information
def show(urls):
count=0
for url in urls:
print('The first{:2}individual url{}'.format(count,url))
count+=1
- Save these paths to a file
Knowledge point: file writing.
def save(filepath,urls):
f=open(filepate,'w')
for url in urls:
f.write(url+'\n')
f.close()
- The main() function combines the above functions
def main():
inputfile = 'nationalgeographic.html'
outputfile = 'nationalgeographic-urls.txt'
htmlLines = getHTMLlines(inputfile)
imageUrls = extractImageUrls(htmlLines)
showResults(imageUrls)
saveResults(outputfile, imageUrls)
Final code: python
# Example_8_1.py
#1. Read all contents of the page by line
def getHTMLlines(htmlpath):
f = open(htmlpath, "r", encoding='utf-8')
ls = f.readlines()
f.close()
return ls
#2. Extract http path
def extractImageUrls(htmllist):
urls = []
for line in htmllist:
if 'img' in line:
url = line.split('src=')[-1].split('"')[1]
print
if 'http' in url:
urls.append(url)
return urls
#3. Output link address
def showResults(urls):
count = 0
for url in urls:
print('The first{:2}individual URL:{}'.format(count, url))
count += 1
#4. Save results to file
def saveResults(filepath, urls):
f = open(filepath, "w")
for url in urls:
f.write(url+"\n")
f.close()
def main():
inputfile = 'nationalgeographic.html'
outputfile = 'nationalgeographic-urls.txt'
htmlLines = getHTMLlines(inputfile)
imageUrls = extractImageUrls(htmlLines)
showResults(imageUrls)
saveResults(outputfile, imageUrls)
main()
One sentence summary: this small case can skillfully master the reading and writing operations of files, and can experience the idea of functions and the splitting of split() functions.
Text progress bar
Knowledge points:
- Import time library
- print() output format
- for i in range(): loop. At the end of the loop, the value in the loop is assigned to the slot through the format function.
Implementation code:
import time
def bar(scale):
print('===========Execution start============')
for i in range(scale + 1):
a = '*' * i
b = '.' * (scale - i)
c = (i / scale) * 100
print('\r{:^3.0f}%[{}->{}]'.format(c, a, b), end = '')
time.sleep(0.1)
print('\n===========end of execution============')
Rendering: output from 0% to 100%
summary
The above mainly introduces the basic functions of python. It is recommended that you master it. The main knowledge points are as follows:
- The input function implements input
- print combines the format () function to output the result
- len() function for calculating string length
- Use the random. Random() function to generate random numbers
- The eval function, combined with input, converts the string type to an integer
- If three branch conditional judgment, if elif else format
- Replace function line.replace (variable name, value to be replaced)
- The text content is uniformly lowercase, and the lower() function is used
- Replace special characters in text with spaces, replace() function
- Cut the text using the split() function
- sort() function from large to small
Why do software testers choose to learn Python instead of Java
Python syntax is concise and clear, and has a rich and powerful class library, which can easily realize many functions. For beginners, Python is the best entry language, not one of them.
Developing small tools with Python is fast and lightweight. In practical work, it is very suitable for the team to quickly develop test tools when test resources are insufficient. And it usually implements a function. The amount of code in Python is 1 / 3-1 / 5 of that in other languages, such as Java. At present, more and more large factories choose Python for the development of new tools and technology stacks. Therefore, it is the best choice for newcomers in the testing industry to enter the field of software testing and quality assurance by mastering Python automated testing technology.
If you want to complete the overall deployment of automated testing in the company, Python can help you easily:
- UI automation test (Python+Selenium, etc.)
- Interface test (Python requests, etc.)
- Performance test (Python, locust, etc.)
- Security test (Python, scapy, etc.)
- Compatibility test (Python+Selenium, etc.)
Imagine that when others are still struggling, busy and working overtime, you can earn money by eating hot pot, singing songs and standing
How will you feel?
How will the boss feel about you?
last
If the article is helpful to you, please help me like the collection, so that I have the motivation to continue to update! Also welcome to join my software testing exchange buckle group: 10796 36098 (technical exchange and resource sharing, advertising do not disturb), which shares testing resources from time to time, and peers exchange and learn together! I hope I can help you on the road of self-study.
- ✔️ I made official account programmer and I could get all the learning resources I came along.
- ✔️ See you next time! 👋👋👋