Scene reproduction
Today, the weather is fine. My girlfriend suddenly wants to buy a bra, but I don't know what color is more beautiful. So I ordered me to analyze what color buyers benefit the public, discuss it, and reward it afterwards.
Keywords in this paper
Concurrent process 😊, IP blocked 😳, IP proxy 😏, Agent blocked 😭, A plant 🌿
Pick a "soft persimmon"
Open jd.com, directly search [bra] and select the one with the most comments
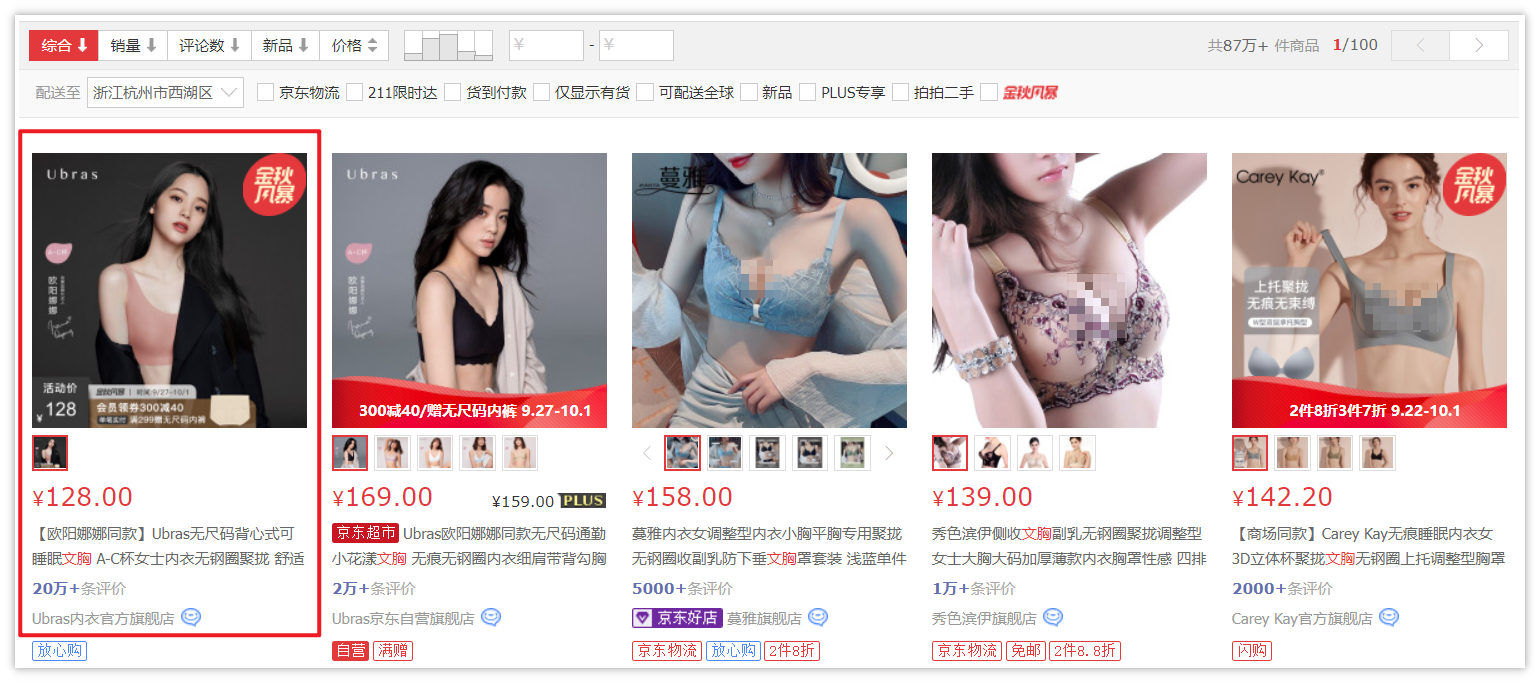
Enter the details page and slide down to see the product introduction and product evaluation.
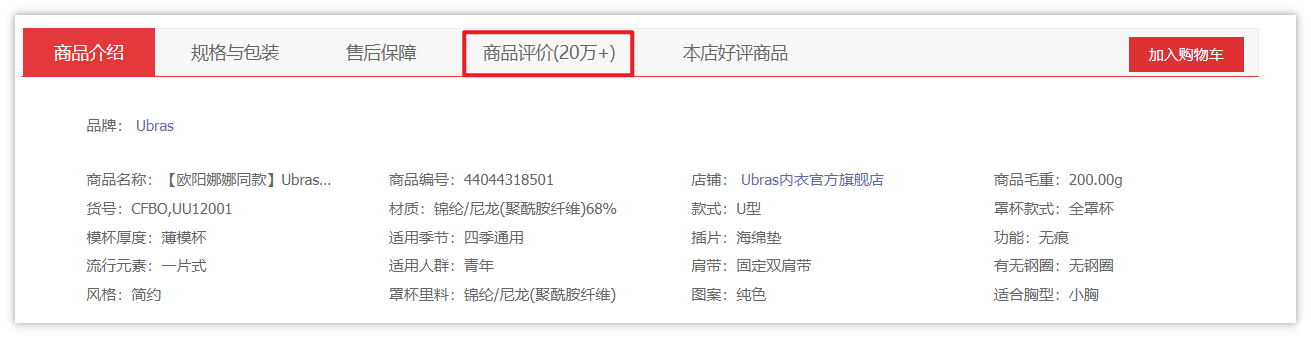
Next, F12 opens the developer tool, selects Network, and then clicks all comments to grab the data package.

Open the url and find that it is really comment data.

Single page crawling
Let's write a small demo to try to crawl the code on this page to see if there is any problem.
import requests
import pandas as pd
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36'
}
params = {
'callback':'fetchJSON_comment98',
'productId':'35152509650',
'score':'0',
'sortType':'6',
'page': '5',
'pageSize':'10',
'isShadowSku':'0',
'rid':'0',
'fold':'1'
}
url = 'https://club.jd.com/comment/productPageComments.action?'
page_text = requests.get(url=url, headers=headers, params=params).text
page_text
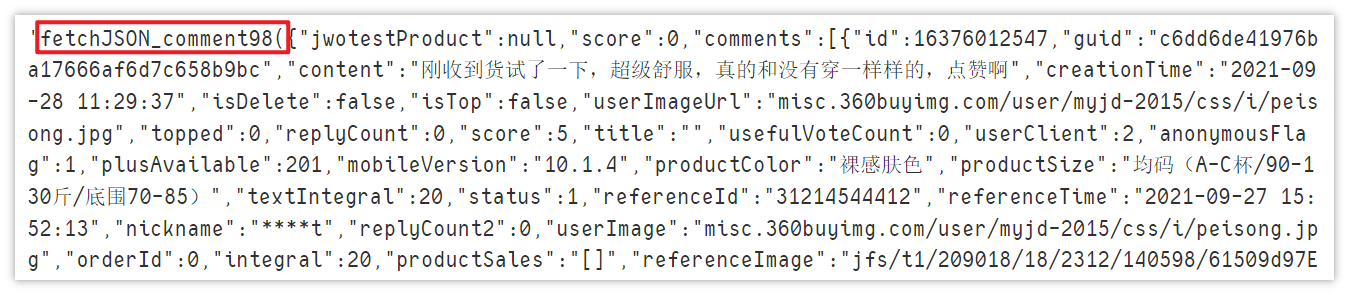
data processing
The data is obtained, but there are some useless characters in the front (there are also characters in the back). Obviously, it can't be directly converted into json format. It needs to be processed.
page_text = page_text[20: len(page_text) - 2] data = json.loads(page_text) data
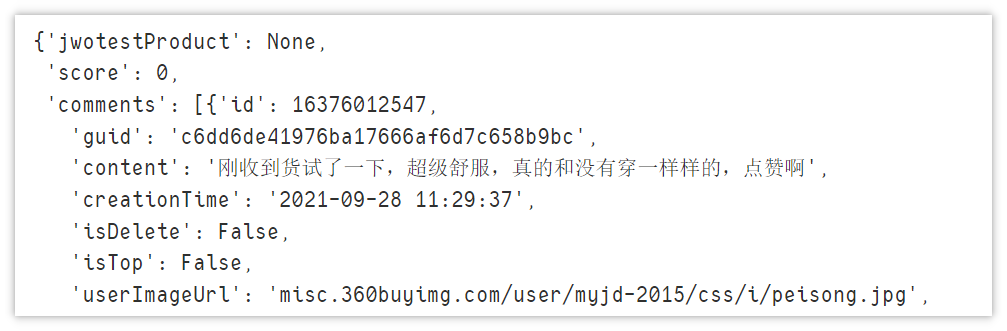
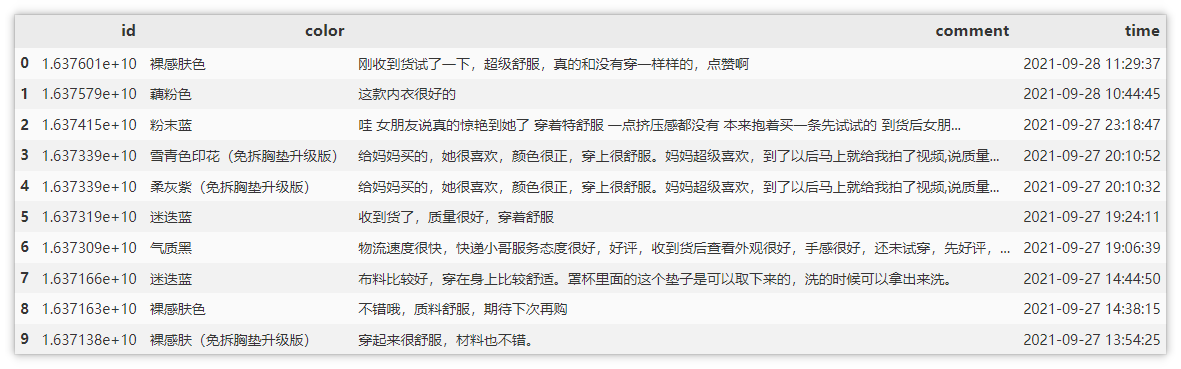
Now that the data format has been processed, we can start to analyze the data and extract the parts we need. Here, we only extract id, color, comment and time.
import pandas as pd
df = pd.DataFrame({'id': [],
'color': [],
'comment': [],
'time': []})
for info in data['comments']:
df = df.append({'id': info['id'],
'color': info['productColor'],
'comment': info['content'],
'time': info['creationTime']},
ignore_index=True)
df
Page turning operation
Next, we need to find the key to turning the page. Let's use the same method to obtain the URLs of the second and third pages for comparison.
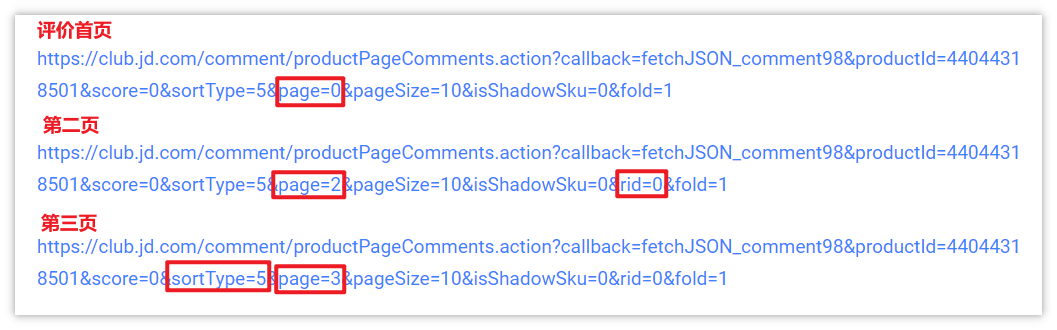
After a brief analysis, the page field is the number of pages, which will be used when turning pages. It is worth noting that sortType literally means sorting type. It is speculated that the sorting method may be: heat, time, etc. After testing, it is found that sortType=5 is definitely not sorted by time, but should be heat. We need to obtain the sorted by time, so that it is easier to deal with later. Then we try several values, and finally determine that when sortType=6, it is sorted by evaluation time. At the end of the figure, there is a rid=0. I don't know what role it plays. I crawl two identical URLs (one with rid and the other without), and the test results are the same, so don't worry about it.
Lu code
Write the crawling results first: I started to want to climb 10000 evaluations. As a result, too many IP requests were cold. I adjusted the IP pool and agents, but I didn't resist. I worked hard to complete 1000. Time is not enough. If time and IP are sufficient, I can climb casually. After testing, it was found that the IP blocking time would not exceed one day. The next day, I ran and also had data. Let's look at the main code.
Main scheduling function
Set the url list of crawling. Remember to limit the concurrency in windows environment, or an error will be reported. Add the crawling task to tasks and suspend the task.
async def main(loop):
# Get url list
page_list = list(range(0, 1000))
# Limit concurrency
semaphore = asyncio.Semaphore(500)
# Create a task object and add it to the task list
tasks = [loop.create_task(get_page_text(page, semaphore)) for page in page_list]
# Pending task list
await asyncio.wait(tasks)
Page grab function
The capture method is basically the same as that described above, except that aiohttp is used for the request, and the authentication of SSL certificate has also been set. After the program is executed, it can be parsed and saved directly.
async def get_page_text(page, semaphore):
async with semaphore:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36'
}
params = {
'callback': 'fetchJSON_comment98',
'productId': '35152509650',
'score': '0',
'sortType': '6',
'page': f'{page}',
'pageSize': '10',
'isShadowSku': '0',
# 'rid': '0',
'fold': '1'
}
url = 'https://club.jd.com/comment/productPageComments.action?'
async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(ssl=False), trust_env=True) as session:
while True:
try:
async with session.get(url=url, proxy='http://' + choice(proxy_list), headers=headers, params=params,
timeout=4) as response:
# When an IO request is encountered, suspend the current task, wait for the code after the IO operation is completed. When the collaboration is suspended, the event loop can execute other tasks.
page_text = await response.text()
# When the data is not obtained successfully, replace the ip to continue the request
if response.status != 200:
continue
print(f"The first{page}Page crawl complete!")
break
except Exception as e:
print(e)
# Exception caught, continue request
continue
return parse_page_text(page_text)
Parse save function
Save json data parsing to csv in the form of append.
def parse_page_text(page_text):
page_text = page_text[20: len(page_text) - 2]
data = json.loads(page_text)
df = pd.DataFrame({'id': [],
'color': [],
'comment': [],
'time': []})
for info in data['comments']:
df = df.append({'id': info['id'],
'color': info['productColor'],
'comment': info['content'],
'time': info['creationTime']},
ignore_index=True)
header = False if Path.exists(Path('Evaluation information.csv')) else True
df.to_csv('Evaluation information.csv', index=False, mode='a', header=header)
print('Saved')
visualization
Color distribution
The top three are grayish pink, black and nude skin color. If you don't say much, you can experience it yourself.

Cloud map of evaluation words
It can be seen that the key words of evaluation are mostly some descriptions of upper body feeling, and comfortable wearing is of course the first~

After scattering flowers, it's time to report to your girlfriend~
⭐ The past is wonderful and can't be missed ⭐ ️
Conclusion
❤️ 20000 words, 50 pandas, high frequency operation [pictures and texts, worth collecting] ❤️
❤️ Hematemesis summary Mysql from getting started to being possessed, with pictures and texts (recommended Collection) ❤️
Tools
⭐ Making cool two-dimensional code of Python practical gadgets (with interface and source code) ⭐ ️
❤️ Production certificate photo of Python utility (with interface and source code) ❤️
❤️ Girlfriend desktop files messy? I was so angry that I made her a file sorting tool in Python ❤️
❤️ Source code acquisition method ❤️
Don't forget to like it~
