Chapter 4 concurrent programming
This chapter discusses concurrent programming, introduces the concept of parallel computing, and points out the importance of parallel computing; The sequential algorithm and parallel algorithm, parallelism and concurrency are compared; The principle of thread and its advantages over process are explained; This paper introduces the thread operation in Pthread through examples, including thread management functions, thread synchronization tools such as mutex, connection, condition variables and barriers; Through concrete examples, this paper demonstrates how to use threads for concurrent programming, including matrix calculation, quick sorting and solving linear equations with concurrent threads; This paper explains the deadlock problem and explains how to prevent the deadlock problem in concurrent programs; Semaphores are discussed and their advantages over conditional variables are demonstrated; It also explains the unique way to support threads in Linux. Programming projects are designed to implement user level threads. It provides a basic system to help readers get started. This basic system supports the dynamic creation, execution and termination of concurrent tasks, which is equivalent to executing threads in the same address space of a process. Readers can realize thread connection, mutex and semaphore of thread synchronization through this project, and demonstrate their usage in concurrent programs. This programming project will give readers a deeper understanding of the principles and methods of multitasking, thread synchronization and concurrent programming.
Introduction to parallel computing
- In the early days, most computers had only one processing component, called a processor or central processing unit (CPU). Limited by this hardware condition, computer programs are usually written for serial computing. To solve a problem, we must first design an algorithm to describe how to solve the problem step by step, and then use the computer program to realize the algorithm in the form of serial instruction stream. When there is only one CPU, only one instruction and step of an algorithm can be executed in sequence at a time. However, algorithms based on the divide and conquer principle (such as binary tree search and quick sorting) often show a high degree of parallelism, which can improve the computing speed by using parallel or concurrent execution. Parallel computing is a computing solution that attempts to solve problems more quickly using multiple processors executing parallel algorithms.
Sequential algorithm and parallel algorithm
- Sequential algorithm: begin end code block lists algorithms. It can include multiple steps. All steps are executed successively through a single task, one step at a time. All steps are executed and the algorithm ends.
- Parallel algorithm: cobegin coend code block is used to specify independent tasks. All tasks are executed in parallel. The next step of the code block will be executed only after all these tasks are completed.

Parallelism and concurrency
The parallel algorithm only identifies tasks that can be executed in parallel, but it does not specify how to map tasks to processing components. Ideally, all tasks in parallel algorithms should be executed in real time at the same time. However, real parallel execution can only be implemented in systems with multiple processing components, such as multi-core processors or multi-core systems. In a single CPU system, only one task can be executed at a time. In this case, different multitasking can only be executed concurrently, that is, logically in parallel. In a single CPU system, concurrency is achieved by multitasking.
thread
principle
- Thread is the smallest unit that the operating system can schedule operations. It is included in the process and is the actual operation unit in the process. A thread refers to a single sequential control flow in a process. Multiple threads can be concurrent in a process, and each thread executes different tasks in parallel. In Unix System V and SunOS, it is also called lightweight processes, but lightweight processes refer more to kernel thread s and user thread s to threads.
Thread is the basic unit of independent scheduling and dispatching. Threads can be kernel threads scheduled for the operating system kernel, such as Win32 threads; User threads scheduled by user processes, such as POSIX Thread on Linux platform; Alternatively, the kernel and user processes, such as Windows 7 threads, perform mixed scheduling. - Multiple threads in the same process will share all system resources in the process, such as virtual address space, file descriptor, signal processing and so on. However, multiple threads in the same process have their own call stack, their own register context, and their own thread local storage.
A process can have many threads, and each thread performs different tasks in parallel. - The benefits of using multithreaded programming on multi-core or multi CPUs, or CPUs that support hyper threading, are obvious, that is, it improves the execution throughput of the program. On a single CPU and single core computer, using multithreading technology, you can also separate the often blocked part in the process responsible for I/O processing and human-computer interaction from the part of intensive computing, and write a special workhorse thread to perform intensive computing, so as to improve the execution efficiency of the program.
advantage
- Faster thread creation and switching
- Faster response
- More suitable for parallel computing
shortcoming
- Due to address space sharing, threads need explicit synchronization from users.
- Many library functions may not be thread safe. For example, the traditional strtok() function divides a string into a series of tokens. Generally, any function that uses global variables or relies on static content is not thread safe. In order to adapt the library functions to the threaded environment, a lot of work needs to be done.
- On a single CPU system, using threads to solve problems is actually slower than using sequential programs, which is caused by the overhead of creating threads and switching contexts at run time.
Thread operation
Threads can execute in kernel mode or user mode
Thread management function
The Pthread library provides the following API s for thread management


Create a new thread
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*start_routine) (void *), void *arg);
Thread termination
void pthread_exit(void *retval);
Wait for the thread to end
int pthread_join(pthread_t thread, void **retval);
Return thread ID
pthread_t pthread_self(void);
Cancel a thread
int pthread_cancel(pthread_t thread);
Detach a thread from a process
int pthread_detach(pthread_t thread);
Thread synchronization
Because threads execute in the same address space of the process, they share all global variables and data structures in the same address space. When multiple threads attempt to modify the same shared variable or data structure, if the modification result depends on the execution order of the threads, it is called race condition. In concurrent programs, there must be no race conditions. Otherwise, the results may be inconsistent. In addition to connection operations, threads executing concurrently usually need to cooperate with each other. To prevent race conditions and support thread collaboration, threads need to be synchronized. Generally, synchronization is a mechanism and rule to ensure the integrity of shared data objects and the coordination of concurrent execution entities. It can be applied to processes in kernel mode or threads in user mode.
mutex
The synchronization tool is a lock, which allows the executing entity to execute only when there is a lock. Locks are called mutexes
Mutually exclusive variables are pthread_mutex_t type declaration must be initialized before use.
- Static method:
pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER;
Define mutex m and initialize it with default properties. - Dynamic method:
pthread_mutex_init(pthread_mutex_t *m,pthread_mutexattr_t,*attr);
Generally, the attr parameter can set bit NULL as the default attribute.
After initialization, threads can use mutexes through the following functions.

Threads use mutexes to protect shared data objects.
Deadlock prevention
- Mutex uses blocking protocol. There are many methods to solve possible deadlock problems, including deadlock defense, deadlock avoidance, deadlock detection and recovery. In practice, the only feasible method is deadlock prevention. Trying to design parallel algorithms is to prevent deadlock.
- A simple deadlock prevention method sorts mutexes and ensures that each thread requests mutexes in only one direction, so that there will be no loops in the request sequence.
- Conditional locking and backoff to prevent deadlock

Conditional variable
As a lock, mutex is only used to ensure that threads can only access shared data objects in critical areas. Conditional variables provide a way for threads to collaborate. In Pthread, use othread_cond_t to declare condition variables, and must be initialized before use.
- Static method
pthread_cond_t con = PTHREAD_COND_INITALLIZER; - Dynamic method
Using pthread_ cond_ The init() function sets the condition variable through the attr parameter.
Semaphore
Semaphores are the general mechanism of process synchronization. A semaphore is a data structure
struct sem{
int value;
struct process *queue
}s;
The most famous semaphore operations are P and V

a barrier
Thread connection allows a thread (usually the main thread) to wait for other threads to terminate. In some cases, it is better to keep threads active, but they should be required not to continue active until all threads have reached the specified synchronization point. In Pthreads, barriers and a series of barrier functions can be used.
First, the main thread creates a barrier object
pthread_barrier_init(&barrier NULL,nthreads);
Initialize it with the number of synchronization threads in the mask. The main thread then creates a worker thread to perform the task.
practice
Quick sorting with concurrent threads
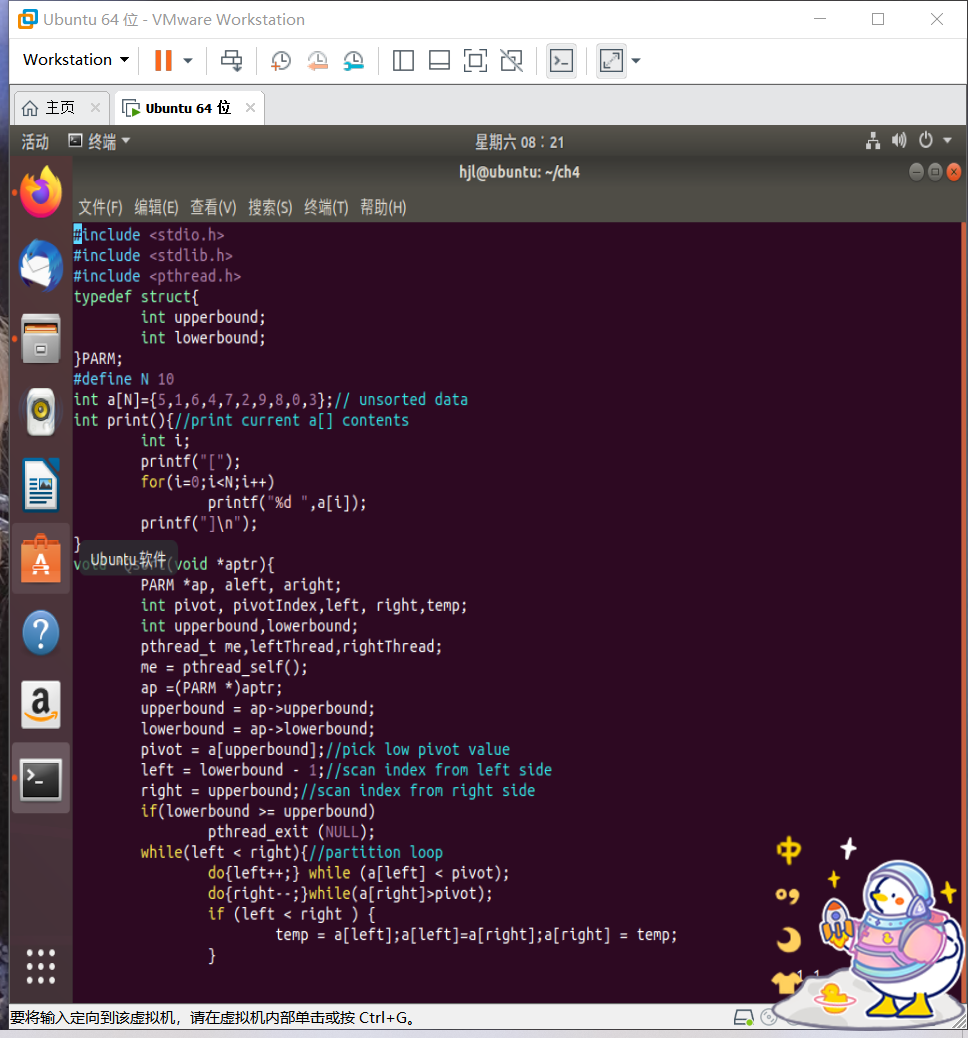
Click to view the code#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
typedef struct{
int upperbound;
int lowerbound;
}PARM;
#define N 10
int a[N]={5,1,6,4,7,2,9,8,0,3};// unsorted data
int print(){//print current a[] contents
int i;
printf("[");
for(i=0;i<N;i++)
printf("%d ",a[i]);
printf("]\n");
}
void *Qsort(void *aptr){
PARM *ap, aleft, aright;
int pivot, pivotIndex,left, right,temp;
int upperbound,lowerbound;
pthread_t me,leftThread,rightThread;
me = pthread_self();
ap =(PARM *)aptr;
upperbound = ap->upperbound;
lowerbound = ap->lowerbound;
pivot = a[upperbound];//pick low pivot value
left = lowerbound - 1;//scan index from left side
right = upperbound;//scan index from right side
if(lowerbound >= upperbound)
pthread_exit (NULL);
while(left < right){//partition loop
do{left++;} while (a[left] < pivot);
do{right--;}while(a[right]>pivot);
if (left < right ) {
temp = a[left];a[left]=a[right];a[right] = temp;
}
}
print();
pivotIndex = left;//put pivot back
temp = a[pivotIndex] ;
a[pivotIndex] = pivot;
a[upperbound] = temp;
//start the "recursive threads"
aleft.upperbound = pivotIndex - 1;
aleft.lowerbound = lowerbound;
aright.upperbound = upperbound;
aright.lowerbound = pivotIndex + 1;
printf("%lu: create left and right threadsln", me) ;
pthread_create(&leftThread,NULL,Qsort,(void * )&aleft);
pthread_create(&rightThread,NULL,Qsort,(void *)&aright);
//wait for left and right threads to finish
pthread_join(leftThread,NULL);
pthread_join(rightThread, NULL);
printf("%lu: joined with left & right threads\n",me);
}
int main(int argc, char *argv[]){
PARM arg;
int i, *array;
pthread_t me,thread;
me = pthread_self( );
printf("main %lu: unsorted array = ", me);
print( ) ;
arg.upperbound = N-1;
arg. lowerbound = 0 ;
printf("main %lu create a thread to do QS\n" , me);
pthread_create(&thread,NULL,Qsort,(void * ) &arg);//wait for Qs thread to finish
pthread_join(thread,NULL);
printf ("main %lu sorted array = ", me);
print () ;
}
Operation results

Using threads to calculate the sum of matrices
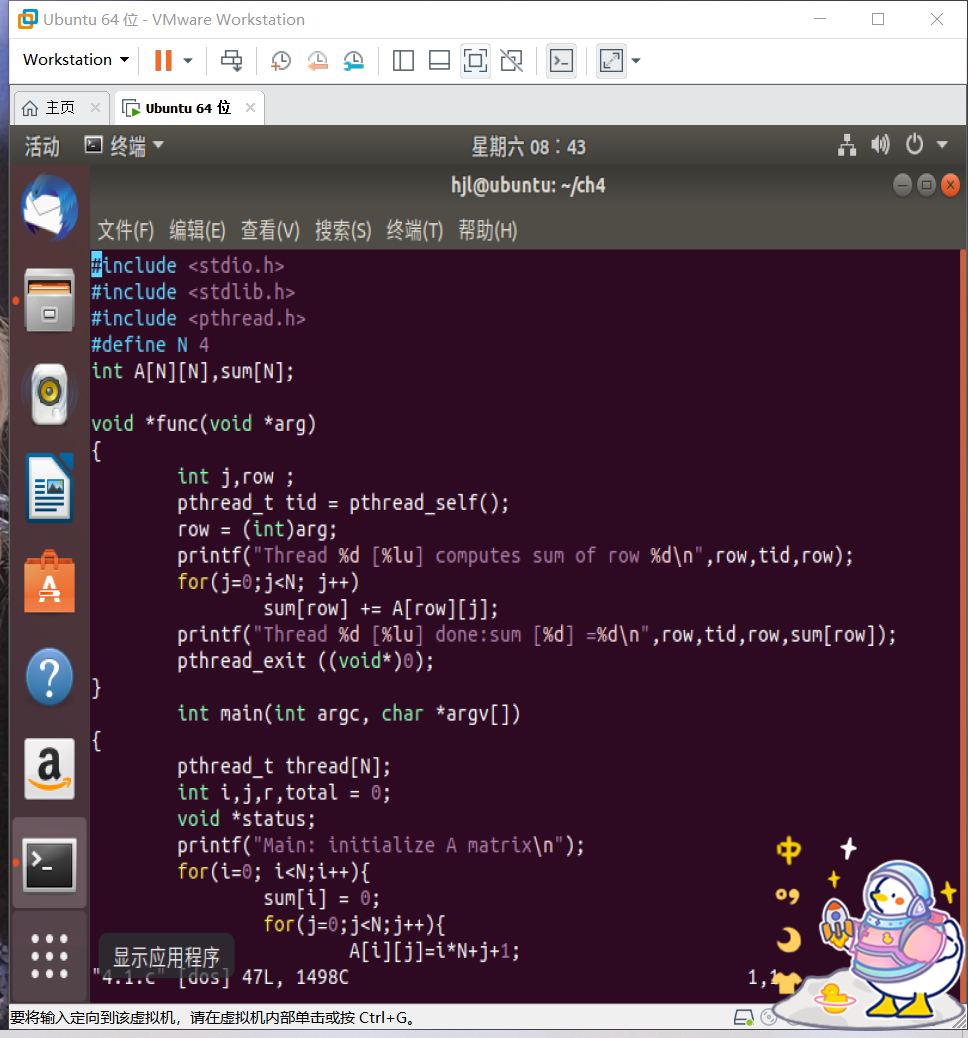
Click to view the code#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define N 4
int A[N][N],sum[N];
void *func(void *arg)
{
int j,row ;
pthread_t tid = pthread_self();
row = (int)arg;
printf("Thread %d [%lu] computes sum of row %d\n",row,tid,row);
for(j=0;j<N; j++)
sum[row] += A[row][j];
printf("Thread %d [%lu] done:sum [%d] =%d\n",row,tid,row,sum[row]);
pthread_exit ((void*)0);
}
int main(int argc, char *argv[])
{
pthread_t thread[N];
int i,j,r,total = 0;
void *status;
printf("Main: initialize A matrix\n");
for(i=0; i<N;i++){
sum[i] = 0;
for(j=0;j<N;j++){
A[i][j]=i*N+j+1;
printf("%4d ",A[i][j]);
}
printf( "\n" );
}
printf ("Main: create %d threads\n",N);
for(i=0;i<N;i++) {
pthread_create(&thread[i],NULL,func,(void *)i);
}
printf("Main: try to join with thread\n");
for(i=0; i<N; i++) {
pthread_join(thread[i],&status);
printf("Main: joined with %d [%lu]: status=%d\n",i,thread[i],
(int)status);
}
printf("Main: compute and print total sum:");
for(i=0;i<N;i++)
total += sum[i];
printf ("tatal = %d\n",total );
pthread_exit(NULL);
}
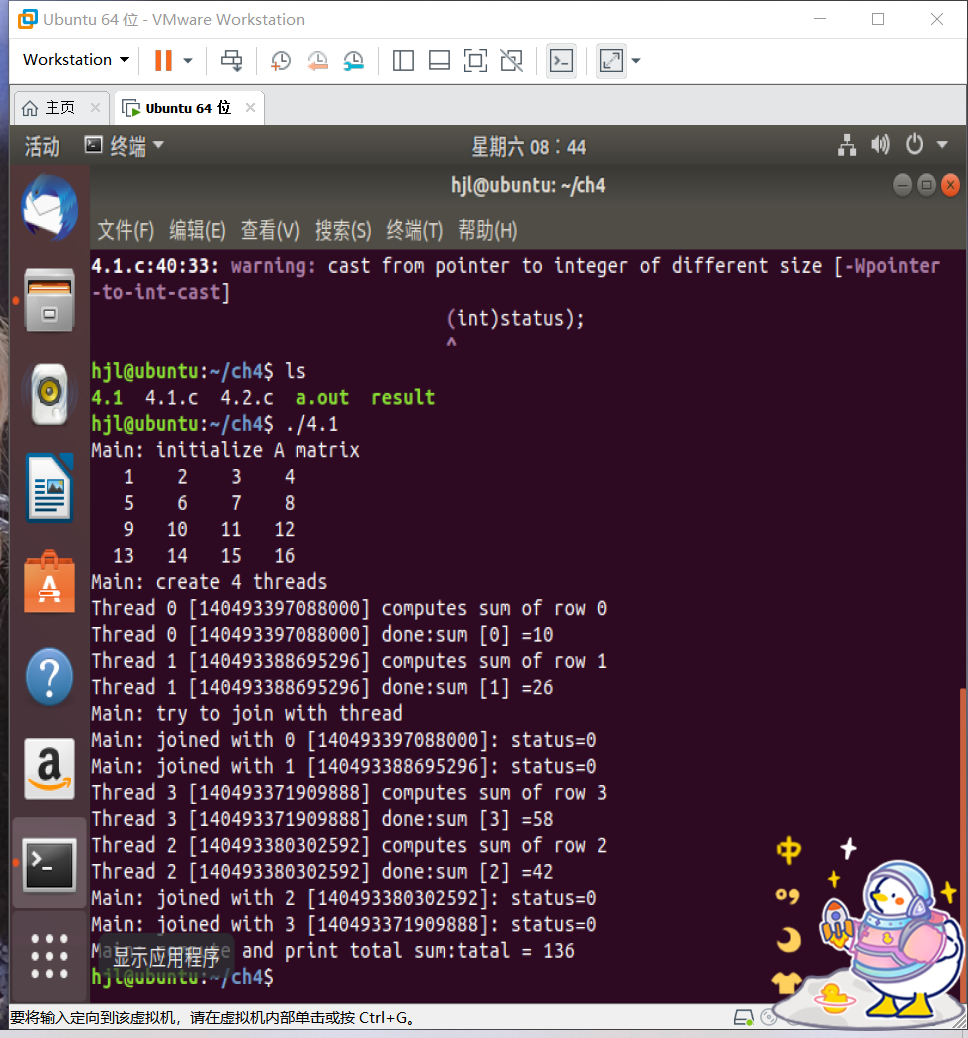
Operation results