2021SC@SDUSC
The last chapter roughly analyzes the implementation of AES in high-level programming language. Here we give the complete source code of AES in c + + to help understand.
#include <iostream>
#include <cstdlib>
#include <stdio.h>
using namespace std;
typedef unsigned char byte;
struct word
{
byte wordKey[4];
};
class AES
{
public:
AES(){
initRcon();
};
// ~AES();
void setCipherKey(byte key[]);
void setPlainText(byte plain[]);
//
void keyExpansion(byte key[], word w[]);
word rotWord(word w);
word subWord(word w);
word wordXOR(word w1, word w2);
//functions in encryption and decryption
void encryption();
void processEncryption();
void addRoundKey(word in[], int round);
void subByte(word in[]);
void shiftRows(word in[]);
void mixColumn(word in[]);
byte GFMultiplyByte(byte L, byte R);
void decryption();
void processDecryption();
void invShiftRows(word in[]);
void invSubByte(word in[]);
void invMixColumn(word in[]);
void initRcon();
void showWord(word w[], int len);
void showMesage();
private:
byte cipherKey[16];
word plainText[4];
word cipherText[4];
word deCipherText[4];
static const int Nb=4, Nk=4, Nr=10;
word Rcon[11];
word wordKey[44];
static const byte SBox[16][16];
static const byte invSBox[16][16];
static const byte mixColumnMatrix[4][4];
static const byte invmixColumnMatrix[4][4];
};
void AES::showWord(word w[], int len){
int i,j;
for(i=0; i<len; i++){
for(j=0; j<4; j++){
printf("%x ", w[i].wordKey[j]);
}
}
cout<<endl;
}
void AES::showMesage(){
cout<<"plainText:"<<endl;
showWord(plainText, 4);
cout<<"wordKey:"<<endl;
showWord(wordKey, Nb*(Nr+1));
cout<<"cipherText:"<<endl;
showWord(cipherText, 4);
cout<<"deCipherText:"<<endl;
showWord(deCipherText, 4);
}
// initialize the plainText--trans plaintext from vector to state_matrix
void AES::setPlainText(byte plain[]){
int i;
for(i=0; i<16; i++){
plainText[i/4].wordKey[i%4] = plain[i];
}
}
//initialize the key--from vector to state_matrix
void AES::setCipherKey(byte key[]){
int i;
for(i=0; i<16; i++){
cipherKey[i] = key[i];
}
keyExpansion(cipherKey, wordKey);
}
//initialize the Rcon
void AES::initRcon(){
int i,j;
for(i=0; i<4; i++)
for(j=0; j<4; j++){
Rcon[i].wordKey[j] = 0x0;
}
Rcon[1].wordKey[0] = 0x01;
Rcon[2].wordKey[0] = 0x02;
Rcon[3].wordKey[0] = 0x04;
Rcon[4].wordKey[0] = 0x08;
Rcon[5].wordKey[0] = 0x10;
Rcon[6].wordKey[0] = 0x20;
Rcon[7].wordKey[0] = 0x40;
Rcon[8].wordKey[0] = 0x80;
Rcon[9].wordKey[0] = 0x1b;
Rcon[10].wordKey[0] = 0x36;
}
//initialize the const of mixColumn and invMixColumn
const byte AES::mixColumnMatrix[4][4] = {
{0x02, 0x03, 0x01, 0x01},
{0x01, 0x02, 0x03, 0x01},
{0x01, 0x01, 0x02, 0x03},
{0x03, 0x01, 0x01, 0x02}
};
const byte AES::invmixColumnMatrix[4][4] = {
{0x0e, 0x0b, 0x0d, 0x09},
{0x09, 0x0e, 0x0b, 0x0d},
{0x0d, 0x09, 0x0e, 0x0b},
{0x0b, 0x0d, 0x09, 0x0e}
};
//initialize SBox
const byte AES::SBox[16][16] = {
{0x63, 0x7c, 0x77, 0x7b, 0xf2, 0x6b, 0x6f, 0xc5, 0x30, 0x01, 0x67, 0x2b, 0xfe, 0xd7, 0xab, 0x76},
{0xca, 0x82, 0xc9, 0x7d, 0xfa, 0x59, 0x47, 0xf0, 0xad, 0xd4, 0xa2, 0xaf, 0x9c, 0xa4, 0x72, 0xc0},
{0xb7, 0xfd, 0x93, 0x26, 0x36, 0x3f, 0xf7, 0xcc, 0x34, 0xa5, 0xe5, 0xf1, 0x71, 0xd8, 0x31, 0x15},
{0x04, 0xc7, 0x23, 0xc3, 0x18, 0x96, 0x05, 0x9a, 0x07, 0x12, 0x80, 0xe2, 0xeb, 0x27, 0xb2, 0x75},
{0x09, 0x83, 0x2c, 0x1a, 0x1b, 0x6e, 0x5a, 0xa0, 0x52, 0x3b, 0xd6, 0xb3, 0x29, 0xe3, 0x2f, 0x84},
{0x53, 0xd1, 0x00, 0xed, 0x20, 0xfc, 0xb1, 0x5b, 0x6a, 0xcb, 0xbe, 0x39, 0x4a, 0x4c, 0x58, 0xcf},
{0xd0, 0xef, 0xaa, 0xfb, 0x43, 0x4d, 0x33, 0x85, 0x45, 0xf9, 0x02, 0x7f, 0x50, 0x3c, 0x9f, 0xa8},
{0x51, 0xa3, 0x40, 0x8f, 0x92, 0x9d, 0x38, 0xf5, 0xbc, 0xb6, 0xda, 0x21, 0x10, 0xff, 0xf3, 0xd2},
{0xcd, 0x0c, 0x13, 0xec, 0x5f, 0x97, 0x44, 0x17, 0xc4, 0xa7, 0x7e, 0x3d, 0x64, 0x5d, 0x19, 0x73},
{0x60, 0x81, 0x4f, 0xdc, 0x22, 0x2a, 0x90, 0x88, 0x46, 0xee, 0xb8, 0x14, 0xde, 0x5e, 0x0b, 0xdb},
{0xe0, 0x32, 0x3a, 0x0a, 0x49, 0x06, 0x24, 0x5c, 0xc2, 0xd3, 0xac, 0x62, 0x91, 0x95, 0xe4, 0x79},
{0xe7, 0xc8, 0x37, 0x6d, 0x8d, 0xd5, 0x4e, 0xa9, 0x6c, 0x56, 0xf4, 0xea, 0x65, 0x7a, 0xae, 0x08},
{0xba, 0x78, 0x25, 0x2e, 0x1c, 0xa6, 0xb4, 0xc6, 0xe8, 0xdd, 0x74, 0x1f, 0x4b, 0xbd, 0x8b, 0x8a},
{0x70, 0x3e, 0xb5, 0x66, 0x48, 0x03, 0xf6, 0x0e, 0x61, 0x35, 0x57, 0xb9, 0x86, 0xc1, 0x1d, 0x9e},
{0xe1, 0xf8, 0x98, 0x11, 0x69, 0xd9, 0x8e, 0x94, 0x9b, 0x1e, 0x87, 0xe9, 0xce, 0x55, 0x28, 0xdf},
{0x8c, 0xa1, 0x89, 0x0d, 0xbf, 0xe6, 0x42, 0x68, 0x41, 0x99, 0x2d, 0x0f, 0xb0, 0x54, 0xbb, 0x16}
};
const byte AES::invSBox[16][16] = {
0x52, 0x09, 0x6a, 0xd5, 0x30, 0x36, 0xa5, 0x38, 0xbf, 0x40, 0xa3, 0x9e, 0x81, 0xf3, 0xd7, 0xfb,
0x7c, 0xe3, 0x39, 0x82, 0x9b, 0x2f, 0xff, 0x87, 0x34, 0x8e, 0x43, 0x44, 0xc4, 0xde, 0xe9, 0xcb,
0x54, 0x7b, 0x94, 0x32, 0xa6, 0xc2, 0x23, 0x3d, 0xee, 0x4c, 0x95, 0x0b, 0x42, 0xfa, 0xc3, 0x4e,
0x08, 0x2e, 0xa1, 0x66, 0x28, 0xd9, 0x24, 0xb2, 0x76, 0x5b, 0xa2, 0x49, 0x6d, 0x8b, 0xd1, 0x25,
0x72, 0xf8, 0xf6, 0x64, 0x86, 0x68, 0x98, 0x16, 0xd4, 0xa4, 0x5c, 0xcc, 0x5d, 0x65, 0xb6, 0x92,
0x6c, 0x70, 0x48, 0x50, 0xfd, 0xed, 0xb9, 0xda, 0x5e, 0x15, 0x46, 0x57, 0xa7, 0x8d, 0x9d, 0x84,
0x90, 0xd8, 0xab, 0x00, 0x8c, 0xbc, 0xd3, 0x0a, 0xf7, 0xe4, 0x58, 0x05, 0xb8, 0xb3, 0x45, 0x06,
0xd0, 0x2c, 0x1e, 0x8f, 0xca, 0x3f, 0x0f, 0x02, 0xc1, 0xaf, 0xbd, 0x03, 0x01, 0x13, 0x8a, 0x6b,
0x3a, 0x91, 0x11, 0x41, 0x4f, 0x67, 0xdc, 0xea, 0x97, 0xf2, 0xcf, 0xce, 0xf0, 0xb4, 0xe6, 0x73,
0x96, 0xac, 0x74, 0x22, 0xe7, 0xad, 0x35, 0x85, 0xe2, 0xf9, 0x37, 0xe8, 0x1c, 0x75, 0xdf, 0x6e,
0x47, 0xf1, 0x1a, 0x71, 0x1d, 0x29, 0xc5, 0x89, 0x6f, 0xb7, 0x62, 0x0e, 0xaa, 0x18, 0xbe, 0x1b,
0xfc, 0x56, 0x3e, 0x4b, 0xc6, 0xd2, 0x79, 0x20, 0x9a, 0xdb, 0xc0, 0xfe, 0x78, 0xcd, 0x5a, 0xf4,
0x1f, 0xdd, 0xa8, 0x33, 0x88, 0x07, 0xc7, 0x31, 0xb1, 0x12, 0x10, 0x59, 0x27, 0x80, 0xec, 0x5f,
0x60, 0x51, 0x7f, 0xa9, 0x19, 0xb5, 0x4a, 0x0d, 0x2d, 0xe5, 0x7a, 0x9f, 0x93, 0xc9, 0x9c, 0xef,
0xa0, 0xe0, 0x3b, 0x4d, 0xae, 0x2a, 0xf5, 0xb0, 0xc8, 0xeb, 0xbb, 0x3c, 0x83, 0x53, 0x99, 0x61,
0x17, 0x2b, 0x04, 0x7e, 0xba, 0x77, 0xd6, 0x26, 0xe1, 0x69, 0x14, 0x63, 0x55, 0x21, 0x0c, 0x7d
};
//keyExpansion-get the round key
void AES::keyExpansion(byte key[], word w[]){
int i=0;
int j,k;
word temp;
while(i < Nk){
for(j=0; j<4; j++){
w[j].wordKey[i] = key[j+4*i];
}
i++;
}
i = Nk;
while(i < Nb*(Nr+1)){
temp = w[i-1];
if((i%Nk) == 0){
temp = rotWord(temp);
temp = subWord(temp);
temp = wordXOR(temp, Rcon[i / Nk]);
}
else if(Nk > 6 && (i%Nk) == 4){
temp = subWord(temp);
}
w[i] = wordXOR(w[i - Nk], temp);
i++;
}
}
// some sector in keyExpansion
word AES::rotWord(word w){
int i;
word temp;
for(i=0; i<4; i++){
temp.wordKey[(i+3) % 4] = w.wordKey[i];
}
return temp;
}
word AES::subWord(word w){
int i;
byte L, R;
for(i=0; i<4; i++){
L = w.wordKey[i] >> 4;
R = w.wordKey[i] & 0x0f;
w.wordKey[i] = SBox[L][R];
}
return w;
}
word AES::wordXOR(word w1, word w2){
int i;
word temp;
for(i=0; i<4; i++){
temp.wordKey[i] = w1.wordKey[i] ^ w2.wordKey[i];
}
return temp;
}
//encryption
void AES::encryption(){
int i, j ,k;
for(i=0; i<4; i++){
for(j=0; j<4; j++){
cipherText[i].wordKey[j] = plainText[i].wordKey[j];
}
}
// round function
addRoundKey(cipherText, 0);
for(i=1; i<10; i++){
subByte(cipherText);
shiftRows(cipherText);
mixColumn(cipherText);
addRoundKey(cipherText, i);
}
subByte(cipherText);
shiftRows(cipherText);
addRoundKey(cipherText, 10);
}
void AES::subByte(word in[]){
int i,j;
byte L, R;
for(i=0; i<4; i++){
for(j=0; j<4; j++){
L = in[i].wordKey[j] >> 4;
R = in[i].wordKey[j] & 0x0f;
in[i].wordKey[j] = SBox[L][R];
}
}
}
void AES::shiftRows(word in[]){
int i,j;
word temp[4];
for(i=0; i<4; i++){
for(j=0; j<4; j++){
temp[i].wordKey[j] = in[(i+j)%4].wordKey[j];
}
}
for(i=0; i<4; i++){
for(j=0; j<4; j++){
in[i].wordKey[j] = temp[i].wordKey[j];
}
}
}
void AES::mixColumn(word in[]){
word result[4];
int i, j, k;
for(i=0; i<4; i++){
for(j=0; j<4; j++){
result[i].wordKey[j] = GFMultiplyByte(mixColumnMatrix[j][0], in[i].wordKey[0]);
for(k=1; k<4; k++){
result[i].wordKey[j] ^= GFMultiplyByte(mixColumnMatrix[j][k], in[i].wordKey[k]);
}
}
}
for(i=0; i<4; i++){
for(j=0; j<4; j++){
in[i].wordKey[j] = result[i].wordKey[j];
}
}
}
//forexample: 0xaf * 0x25 calculate the result of polynomial modular multiplication (operation in column confusion)
byte AES::GFMultiplyByte(byte L, byte R){
byte temp[8];
byte result = 0x00;
temp[0] = L;
int i;
// temp[0] = L, temp[1] = L*x(modm(x)), temp[2] = L*x^2(mod(m(x))), temp[3] = L*x^3(mod(m(x)))...
//First calculate, then save, and then select the required according to the actual situation of R
for(i=1; i<8; i++){
if(temp[i-1] >= 0x80){
temp[i] = (temp[i-1] << 1) ^ 0x1b;
}else{
temp[i] = temp[i-1] << 1;
}
}
for(i=0; i<8; i++){
if(int((R >> i) & 0x01) == 1){
result ^= temp[i];
}
}
return result;
}
void AES::addRoundKey(word in[], int round){
int i, j;
for(i=0; i<4; i++){
for(j=0; j<4; j++){
in[i].wordKey[j] ^= wordKey[i+4*round].wordKey[j];
}
}
}
//decryption
void AES::decryption(){
int i, j, k;
for(i=0; i<4; i++){
for(j=0; j<4; j++){
deCipherText[i].wordKey[j] = cipherText[i].wordKey[j];
}
}
addRoundKey(deCipherText, 10);
for(i=9; i>0; i--){
invShiftRows(deCipherText);
invSubByte(deCipherText);
addRoundKey(deCipherText, i);
invMixColumn(deCipherText);
}
invShiftRows(deCipherText);
invSubByte(deCipherText);
addRoundKey(deCipherText, 0);
}
void AES::invShiftRows(word in[]){
int i,j;
word temp[4];
for(i=0; i<4; i++){
for(j=0; j<4; j++){
temp[i].wordKey[j] = in[(i-j+4)%4].wordKey[j];
}
}
for(i=0; i<4; i++){
for(j=0; j<4; j++){
in[i].wordKey[j] = temp[i].wordKey[j];
}
}
}
void AES::invSubByte(word in[]){
int i,j;
byte L, R;
for(i=0; i<4; i++){
for(j=0; j<4; j++){
L = in[i].wordKey[j] >> 4;
R = in[i].wordKey[j] & 0x0f;
in[i].wordKey[j] = invSBox[L][R];
}
}
}
void AES::invMixColumn(word in[]){
word result[4];
int i, j, k;
for(i=0; i<4; i++){
for(j=0; j<4; j++){
result[i].wordKey[j] = GFMultiplyByte(invmixColumnMatrix[j][0], in[i].wordKey[0]);
for(k=1; k<4; k++){
result[i].wordKey[j] ^= GFMultiplyByte(invmixColumnMatrix[j][k], in[i].wordKey[k]);
}
}
}
for(i=0; i<4; i++){
for(j=0; j<4; j++){
in[i].wordKey[j] = result[i].wordKey[j];
}
}
}
int main(int argc, char const *argv[])
{
int i;
//Set plaintext and key
byte plain[16], key[16];
for(i=0; i<16; i++){
plain[i] = byte(i);
key[i] = 0x01;
}
AES aes;
aes.setPlainText(plain);
aes.setCipherKey(key);
aes.encryption();
aes.decryption();
aes.showMesage();
return 0;
}
The above code is mainly for the implementation of AES algorithm for 128bit plaintext and key.
Due to the knowledge practice course this week, together with other courses and the superposition of large and small things, it was originally planned to carry out the actual detection and comparative analysis of CPU and GPU for AES algorithm this week. But to sum up, we can only wait until next week.
This week's report is mainly to further understand the CPU and GPU in more detail to see where the GPU is strong in computing power?
1, Comparison of CPU and GPU (CPU)
When it comes to computing, we usually think of CPU. The full name of CPU is Central Processing Unit, while the full name of GPU is Graphics Processing Unit. In naming. The similarities between the two devices are that they are both processing units; The difference is that the CPU is "core", while the GPU is used for "image" processing. In our general understanding, these names are really in line with the public impression of their use - one is the "brain core" of the computer, and the other is the "processor" of the image. But smart people are not bound by simple names. They found that GPU can provide better computing power than CPU in some scenarios.
So someone will ask: isn't the CPU more powerful? This is a very good question. To explain this question, we need to start with the organizational structure of the CPU. Since the common newer architectures of Intel, such as broadwell and skylake, contain a GPU in the CPU, they can not be regarded as classic CPU architectures. Let's look at a relatively simple CPU profile.

This CPU has 8 processing cores, and other components include L3 cache and memory controller. It can be seen that the "Core" does not account for the vast majority of the CPU in physical space.
CPU is a master of all kinds of computing power. Just like the leaders of some companies, they may be proficient in various technical fields. But a company can't only have such leaders who can do everything, because the value of leaders is not only reflected in the front-line execution ability, but also in the scheduling ability.
Even if there is a domestic mobile phone with 8 cores and each core can reach 2GHz, it will get stuck when opening two applications at present. Even the two cores of this low configuration, the highest REMAX 2.8GHz notebook, can easily run multiple applications. Regardless of the differences between systems and applications and the instruction set supported by the CPU, what makes Intel's CPU more and more fluent?
Some people may say that it is the dominant frequency. Let's take a look at the development diagram of CPU dominant frequency.
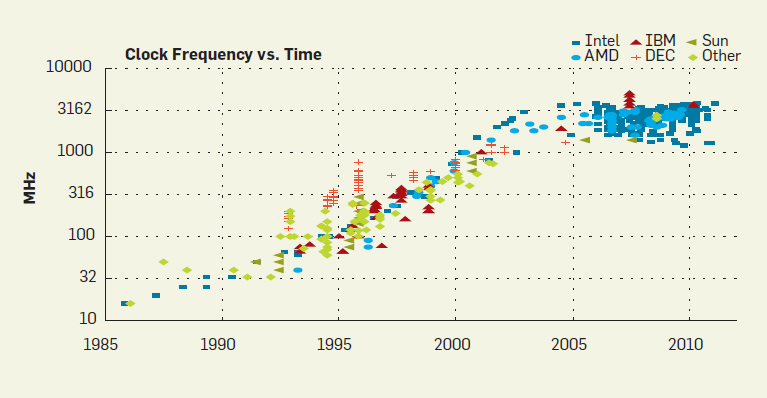
It can be seen from the above figure that the dominant frequency of CPU still conforms to Moore's law before 2000. However, around 2005, major manufacturers did not put in CPUs with higher dominant frequency (theoretically, the dominant frequency should now reach 10GHz), but some reduced the frequency. Why? First, the development of CPU's main frequency is close to the limit in the current environment, and the power consumption will increase with the increase of main frequency. But do we feel that the computer is getting slower and slower? Obviously not.
Some might say it's the core number. In the past 10 years, the desktop intel series CPU s on the market still focus on the number of 2, 4 and 8 cores. Compared with the 2005 Pentium D series dual core processor and the current core i3 dual core processor, Pentium D should be difficult to run Win10 smoothly (its execution efficiency is not as good as the Core 2 Duo released in 2006).
In addition to the above views, there are also cache access rate, cache size and other factors. But these factors, ARM Series CPU can also do, but why is it still not as fast as Intel? Next, only a few reasons that I think are more important are listed.
Branch predictor. Take the following code as an example:
int b = 3;
int c = 4;
bool a = memory_enough();
if (a) {
b *= c;
}
else {
b += c;
}According to the general idea, the process executed by the CPU is: after obtaining the value of a, select a branch to execute. If the logic of a may be time-consuming (for example, there is IO waiting operation), should the CPU wait all the time?
Now the CPU is relatively intelligent. It will predict the value of a and execute the branch corresponding to the prediction. Then wait until the value of a returns and verify whether the guess is correct. If it is correct, we will save the waiting time for branch execution. If the guess is wrong, go back and execute the correct process.
One might wonder if the proportion of branches in code logic is so high? Need to independently design such a function to optimize? In fact, this proportion is quite high. You might as well look at your own code. As the basic logical structure, branch can be used in many occasions. Therefore, CPU prediction can greatly speed up the speed. Even if the prediction is wrong, it's better to execute again than to wait there and do nothing.
Having said so much, I just want to make one point: CPU is an excellent leader with multiple functions. Its strength lies in "scheduling" rather than pure computing. GPU can be regarded as an employee with "a lot of computing power" who accepts CPU scheduling.
2, Comparison of CPU and GPU (GPU)
Why does GPU have a lot of computing power. Let's take a look at the architecture of NV GPU.
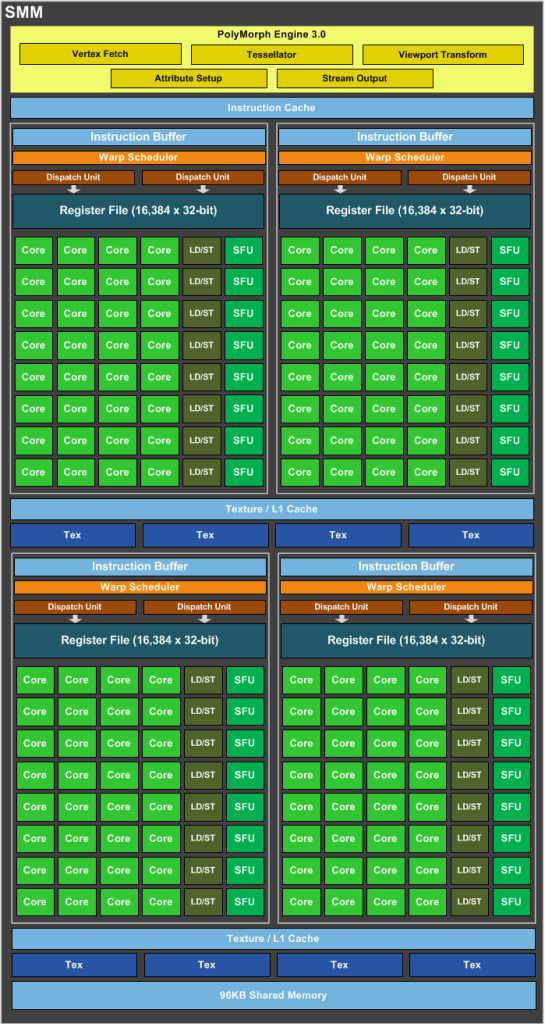
This GPU has four SM (streaming multiprocessor s), each SM has 4 * 8 = 32 cores, and a total of 4 * 4 * 8 = 128 cores (the Core here can not be equivalent to the Core in the CPU structure diagram, but can only be equivalent to an "execution unit" in the CPU microarchitecture. Later, we call the GPU Core cuda Core).
Compare the micro architecture and architecture diagram of CPU. Take FP mul "execution unit" as an example. There are 2 cores of one CPU and 12 six Core CPUs. Although we do not know the internal composition of GPU cuda Core, it can be considered that such a computing unit is at least equal to the number of cuda cores - 128. This directly produces a comparison, equivalent to 128 to 12.
Let's take a look at the data of the latest NV graphics card.

5120 is not the same order of magnitude as 12, and the gap is even wider.
If the number of cuda cores cannot represent the computing power of GPU. If we go back to the figure above, we can find that this GPU provides 640 Tensor cores, which provide floating-point computing capability. I don't know how many similar cores are in the CPU, but from a picture released by NV, we can see the gap between the two - an order of magnitude.
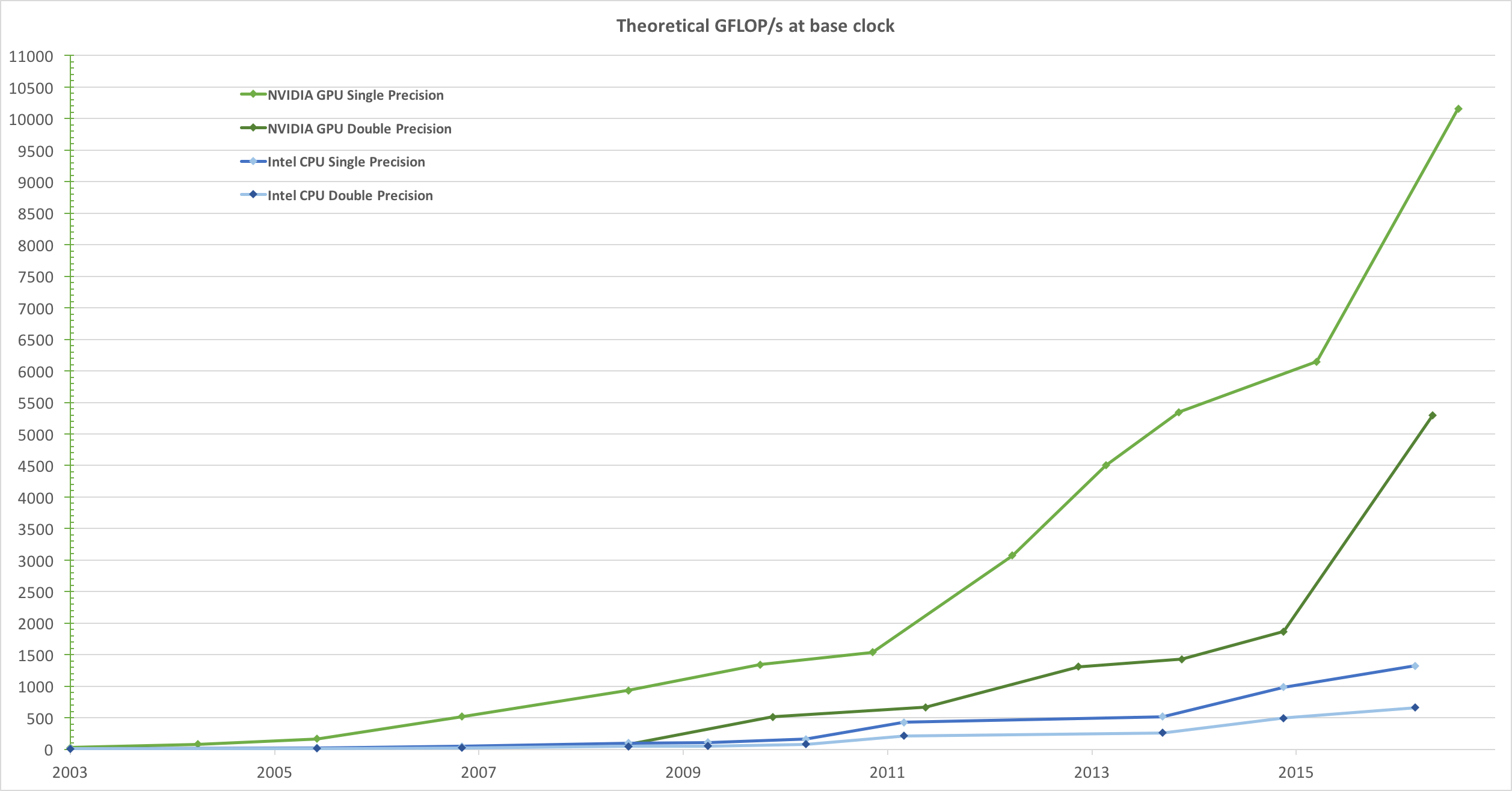
To sum up, the computing power of GPU far exceeds that of CPU in terms of the number and capacity of "computing power units".
In addition to computing power, another important consideration is the rate of memory access. When we do a lot of calculations, it is often not enough to use registers and L1, L2 and L3 caches.
At present, Intel CPUs are designed with three-level cache. Their access speed relationship is L1 > L2 > L3, while their volume relationship is the opposite: L1 < L2 < L3. Taking the Intel Core i7 5960X in the figure as an example, its L3 cache size is only 20M. Obviously, the cache size of the CPU is too small to carry all systems. So you need to use memory to supplement. The CPU supports a maximum of 64G memory, and its maximum memory bandwidth is 68GB/s.
However, the video memory bandwidth corresponding to GPU is one order of magnitude higher than that corresponding to CPU! As shown below:
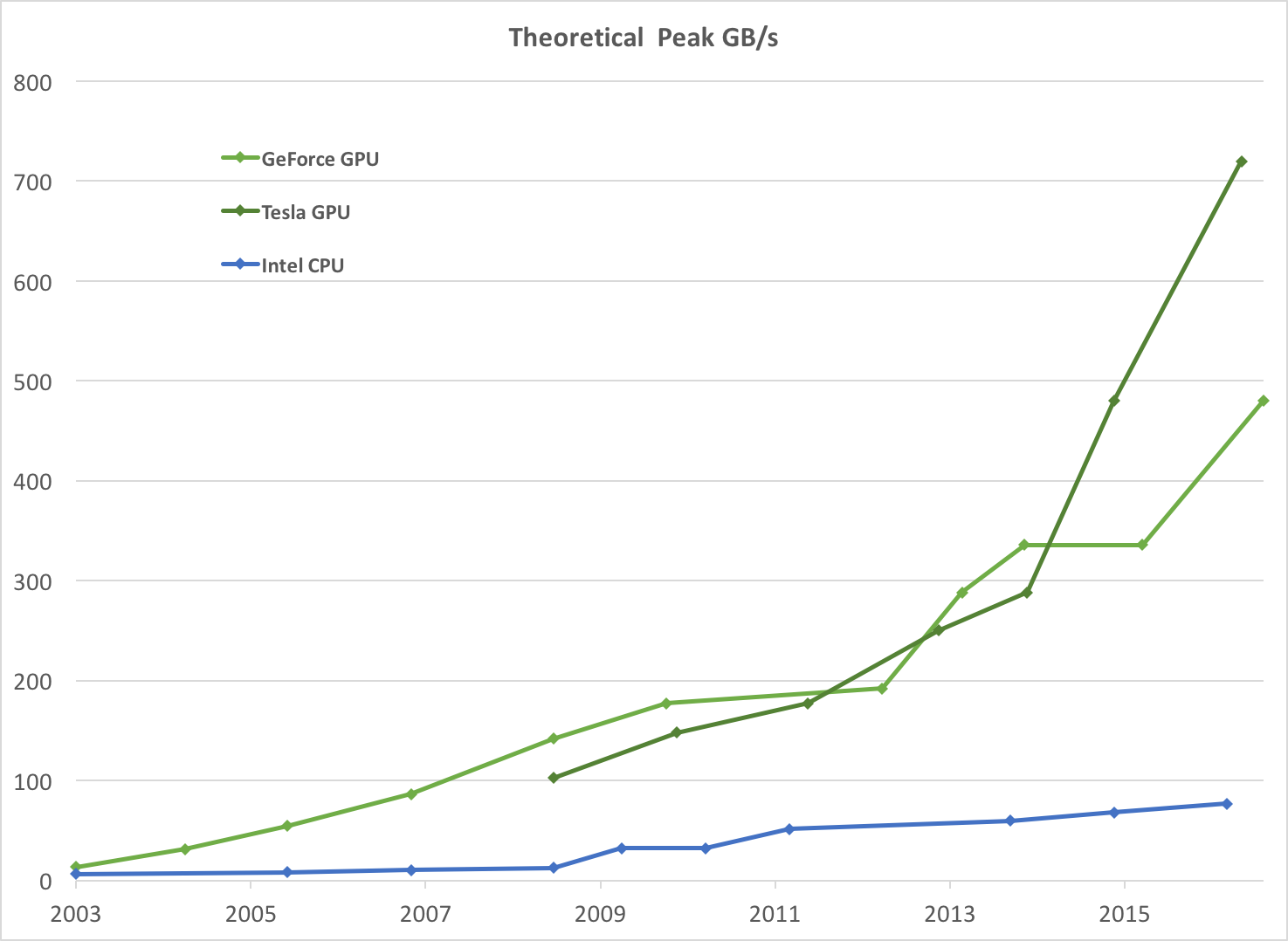
3, Comparison of CPU and GPU (summary)
To sum up, GPU is stronger than CPU in computing power. Whether it is the number or capacity of "force units". Or the rate of memory access is better than CPU. If the CPU is compared to a master in scheduling, similar to the boss, the GPU is a professional employee specialized in "computing". CUDA Programming is an essential part of learning GPU.
Reference blog: Analysis of gpu computing -- selection of CPU and gpu_ Fang Liang's column - CSDN blog_ gpu calculation
aes algorithm code implementation (complete C + + source code)_ CSDN blog_ aes code implementation