[source code analysis] how PyTorch implements backward propagation (4) -- specific algorithm
0x00 summary
In the previous article, we introduced the dynamic logic of the back propagation engine. Because the specific back propagation algorithm is completed in the device thread, we will explain it in a separate chapter.
Other articles in this series are as follows:
Automatic differentiation of deep learning tools (1)
Automatic differentiation of deep learning tools (2)
[Source code analysis] automatic differentiation of deep learning tools (3) -- example interpretation
[Source code analysis] how PyTorch implements forward propagation (1) -- basic class (I)
[Source code analysis] how PyTorch implements forward propagation (2) -- basic classes (Part 2)
[Source code analysis] how PyTorch implements forward propagation (3) -- specific implementation
[Source code analysis] how pytoch implements backward propagation (1) -- call engine
[Source code analysis] how pytoch implements backward propagation (2) -- engine static structure
[Source code analysis] how pytoch implements backward propagation (3) -- engine dynamic logic
0x01 worker thread body
thread_main is the main function of the working thread. The main logic is to execute a while loop around ReadyQueue. The working thread is blocked in ReadyQueue - > pop. If the main thread or other threads insert a NodeTask, pop will return and take out a NodeTask. The working thread processes the NodeTask and completes a link of backward calculation, If necessary, continue to insert a new NodeTask into a ReadyQueue to drive the engine to continue to perform other backward computing links.
thread_main is called in the following way:
- The autograd threads of CUDA and XLA devices will be called.
- The back propagation main thread on the CPU will call.
- The first two case s are also called for reentrant back propagation.
1.1 thread body code
The calculation of the working thread starts from the GraphRoot function of the dynamic graph. The back-propagation takes the edge of the Node as the link, calculates from front to back layer by layer until it comes to the leaf Node, and finally completes the back-propagation calculation, as follows:
- local_graph_task represents the graph we retrieved from the queue_ task. External graph_ The task represents the overall graph of reentrant execution that we need to perform_ Mission.
- Take the NodeTask instance from your ReadyQueue and use local_graph_task is the parameter to execute evaluate_function.
- outstanding_tasks minus 1.
- If this local_ graph_ The task has ended (reentrant backpropagation will run multiple graphtasks), namely:
- Perform subsequent operations exec_post_processing, and then use future_ result_-> markCompleted.
- If the task comes from another worker thread, that is, the worker_device != base_owner, send a dummy function task to the queue of the worker thread to let the worker thread execute.
The specific codes are as follows:
// thread_main is used by:
// 1). autograd threads for devices (i.e. CUDA, XLA)
// 2). the caller/owning thread of the backward call on CPU (sync mode)
// 3). Renetrant backward that invoked by either 1) or 2)
// The exit conditions are different for the above three cases.
// For 1), we are spinning on running the thread_main on device autograd
// threads throughout the Engine lifetime, thread_main will get
// terminated during Engine destruction by pushing shutdown tasks
// For 2), the owning thread of the backward call drives the thread_main
// synchronously until the graph_task of that owning thread is
// completed and exit the thread_main to continue executing the
// result of caller's code.
// For 3), the reentrant backward that invokes
// thread_main, either from 1) or 2), will not spin and will exit as
// long as graph_task is completed and notify the owning thread as
// needed.
auto Engine::thread_main(const std::shared_ptr<GraphTask>& graph_task) -> void {
// When graph_task is nullptr, this is a long running thread that processes
// tasks (ex: device threads). When graph_task is non-null (ex: reentrant
// backwards, user thread), this function is expected to exit once that
// graph_task complete.
// local_ready_queue should already been initialized when we get into thread_main
while (graph_task == nullptr || !graph_task->future_result_->completed()) {
// local_graph_task represents the graph_task we retrieve from the queue.
// The outer graph_task represents the overall graph_task we need to execute
// for reentrant execution.
std::shared_ptr<GraphTask> local_graph_task;
{
// Scope this block of execution since NodeTask is not needed after this
// block and can be deallocated (release any references to grad tensors
// as part of inputs_).
NodeTask task = local_ready_queue->pop(); // Blocking wait
// This will only work if the worker is running a non backward task
// TODO Needs to be fixed this to work in all cases
if (task.isShutdownTask_) {
break;
}
if (!(local_graph_task = task.base_.lock())) {
// GraphTask for function is no longer valid, skipping further
// execution.
continue;
}
if (task.fn_ && !local_graph_task->has_error_.load()) {
// Using grad_mode_ To configure AutoGradMode. The code during the whole reverse calculation depends on GradMode::is_enabled() to determine whether grad is to be calculated
AutoGradMode grad_mode(local_graph_task->grad_mode_);
try {
// The guard sets the thread_local current_graph_task on construction
// and restores it on exit. The current_graph_task variable helps
// queue_callback() to find the target GraphTask to append final
// callbacks.
GraphTaskGuard guard(local_graph_task);
NodeGuard ndguard(task.fn_);
// Perform backward calculation
evaluate_function(local_graph_task, task.fn_.get(), task.inputs_, local_graph_task->cpu_ready_queue_);
} catch (std::exception& e) {
thread_on_exception(local_graph_task, task.fn_, e);
}
}
}
// Decrement the outstanding tasks.
--local_graph_task->outstanding_tasks_;
// Check if we've completed execution.
if (local_graph_task->completed()) { // It's over. Follow up
local_graph_task->mark_as_completed_and_run_post_processing();
auto base_owner = local_graph_task->owner_; // The following is the owner of GraphTask_ handle
// The current worker thread finish the graph_task, but the owning thread
// of the graph_task might be sleeping on pop() if it does not have work.
// So we need to send a dummy function task to the owning thread just to
// ensure that it's not sleeping, so that we can exit the thread_main.
// If it has work, it might see that graph_task->outstanding_tasks_ == 0
// before it gets to the task, but it's a no-op anyway.
//
// NB: This is not necessary if the current thread is the owning thread.
if (worker_device != base_owner) {
// Synchronize outstanding_tasks_ with queue mutex
std::atomic_thread_fence(std::memory_order_release);
// Get the queue of follow-up work
ready_queue_by_index(local_graph_task->cpu_ready_queue_, base_owner)
->push(NodeTask(local_graph_task, nullptr, InputBuffer(0)));
}
}
}
}
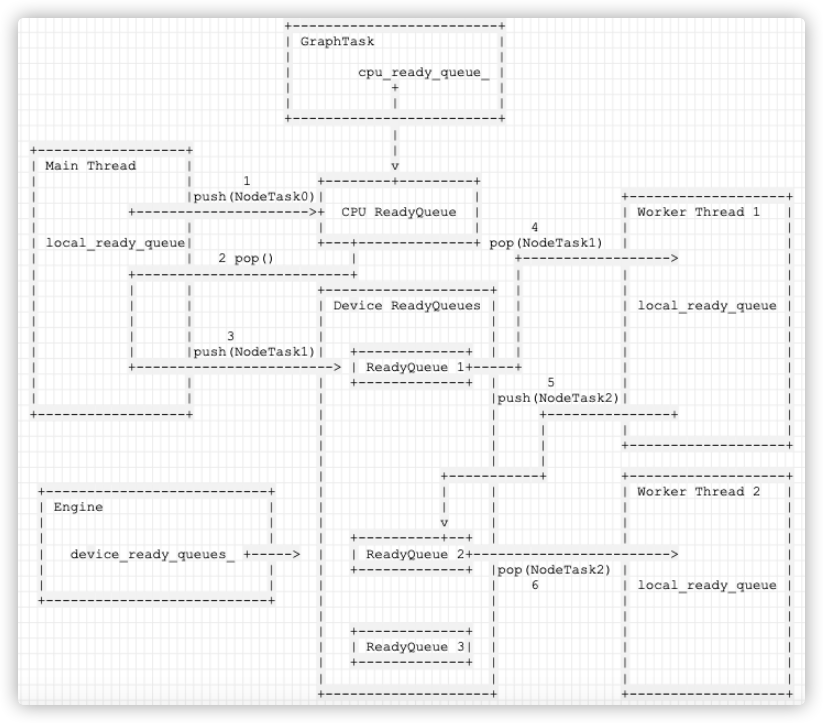
1.2 using Ready Queue
In the above code, finally use ready_queue_by_index gets the queue corresponding to the subsequent work.
ready_queue_by_index(local_graph_task->cpu_ready_queue_, base_owner)
->push(NodeTask(local_graph_task, nullptr, InputBuffer(0)));
How to get Ready Queue? The specific strategies are:
- If the next device to be executed is CPU, select cpu_ready_queue.
- Otherwise, from device_ready_queues_ Select the ReadyQueue corresponding to a GPU.
The code is as follows:
auto Engine::ready_queue_by_index(std::shared_ptr<ReadyQueue> cpu_ready_queue, int device_index) -> std::shared_ptr<ReadyQueue> {
if (device_index == CPU_DEVICE) {
// return the cpu ready queue passed in
TORCH_INTERNAL_ASSERT(cpu_ready_queue);
return cpu_ready_queue;
} else {
// Static cast is ok here as the number of device should never overflow an int.
TORCH_INTERNAL_ASSERT(0 <= device_index && device_index < static_cast<int>(device_ready_queues_.size()));
// See Note [Allocating GPUs to autograd threads]
// NB: This function would become obsolete if we truly allocated a CPU thread
// per device, rather than colocate.
return device_ready_queues_.at(device_index);
}
}
The logic is as follows:
+---------------------------------------------------------------------+
| Main Thread |
| |
| push(NodeTask)+--------------+ |
| | |
+---------------------------------------------------------------------+
|
|
v
+------+-----+
| |
| ReadyQueue |
| |
+------+-----+
|
|
|
+---------------------------------------------------------------------+
| Worker Thread 1 | |
| | |
| thread_main{ | |
| v |
| NodeTask task = local_ready_queue->pop() |
| |
| evaluate_function(task.fn_.get(),task.inputs_) |
| } |
+---------------------------------------------------------------------+
0x02 reverse calculation of overall logic
evaluate_function method completes the logic of reverse calculation. The overall logic is as follows:
- Preparatory work: if Exec_ If info needs to be processed, process captured_vars_.
- Reverse calculation: call_function(graph_task, func, inputs), which is the core logic related to calculation in back propagation:
- Call pre hooks.
- Call fn for calculation.
- Call post hooks.
- Finishing work:
- If keep graph is not required, fn.release_variables();
- According to call_function outputs to calculate num_outputs = outputs.size(), get num_ The number of elements in outputs (which is equal to the number of elements in the list returned by next_edge() of the current fn).
- Prepare for the next step, specifically to find the NodeTask and num to be calculated later_ Outputs are used here. This part is complicated.
The overall code is as follows:
void Engine::evaluate_function(
std::shared_ptr<GraphTask>& graph_task,
Node* func, // Derivative calculation method
InputBuffer& inputs, // Input gradient of current Node
const std::shared_ptr<ReadyQueue>& cpu_ready_queue) {
// Make preparations
// If exec_info_ is not empty, we have to instrument the execution
auto& exec_info_ = graph_task->exec_info_;
if (!exec_info_.empty()) {
auto& fn_info = exec_info_.at(func); // Take out the current for processing
if (auto* capture_vec = fn_info.captures_.get()) {
// Lock mutex for writing to graph_task->captured_vars_.
std::lock_guard<std::mutex> lock(graph_task->mutex_);
for (const auto& capture : *capture_vec) {
// captured_grad is a temporary storage. Every node calculation will be updated and finally output to the caller, which is equivalent to a reference
// 1. captured_grad refers to captured_vars_[capture.output_idx_],
auto& captured_grad = graph_task->captured_vars_[capture.output_idx_];
// 2. To captured_vars_[capture.output_idx_] assignment inputs[capture.input_idx_]
captured_grad = inputs[capture.input_idx_];
// Traverse hooks, chain call hook for calculation, captured_grad keeps flowing in the pipeline as input and output
// It's for captured_vars_[capture.output_idx_] after continuous calculation, the final result is captured_ vars_ [capture. Output IDX].
for (auto& hook : capture.hooks_) {
captured_grad = (*hook)(captured_grad);
}
}
}
if (!fn_info.needed_) {
// Skip execution if we don't need to execute the function.
return;
}
}
// Set the ThreadLocalState before calling the function.
// NB: The ThreadLocalStateGuard doesn't set the grad_mode because GraphTask
// always saves ThreadLocalState without grad_mode.
at::ThreadLocalStateGuard tls_guard(graph_task->thread_locals_);
// Switches to a function's CUDA stream (if applicable) before calling it
const auto opt_parent_stream = (*func).stream(c10::DeviceType::CUDA);
c10::OptionalStreamGuard parent_stream_guard{opt_parent_stream};
// Reverse calculation
auto outputs = call_function(graph_task, func, inputs);
// If you do not need to maintain the calculation chart, this node releases the variables
auto& fn = *func;
if (!graph_task->keep_graph_) {
fn.release_variables();
}
// Get num_ The number of elements in outputs (the number is equal to the number of elements in the list returned by next_edge() of the current fn), which will be used when traversing the output of this node
int num_outputs = outputs.size();
if (num_outputs == 0) { // Note: doesn't acquire the mutex
// Records leaf stream (if applicable)
// See note "Streaming backwards"
if (opt_parent_stream) {
std::lock_guard<std::mutex> lock(graph_task->mutex_);
graph_task->leaf_streams.emplace(*opt_parent_stream);
}
return;
}
if (AnomalyMode::is_enabled()) {
AutoGradMode grad_mode(false);
for (int i = 0; i < num_outputs; ++i) {
auto& output = outputs[i];
at::OptionalDeviceGuard guard(device_of(output));
if (output.defined() && isnan(output).any().item<uint8_t>()) {
std::stringstream ss;
}
}
}
// Prepare for the next step
// Lock mutex for the accesses to GraphTask dependencies_, not_ready_ and cpu_ready_queue_ below
std::lock_guard<std::mutex> lock(graph_task->mutex_);
for (int i = 0; i < num_outputs; ++i) {
auto& output = outputs[i];
const auto& next = fn.next_edge(i); // next_edge is the input of the node in the forward propagation graph and the output of the node in the back propagation, so next is the next possible operation node
if (!next.is_valid()) continue;
// Check if the next function is ready to be computed
bool is_ready = false;
auto& dependencies = graph_task->dependencies_;
auto it = dependencies.find(next.function.get()); // Find the dependency of the next node
if (it == dependencies.end()) {
auto name = next.function->name();
throw std::runtime_error(std::string("dependency not found for ") + name);
} else if (--it->second == 0) {
dependencies.erase(it);
is_ready = true; // If the next node has no penetration, it means that other node gradients on which the node gradient depends have been calculated
}
// Going to not_ Check in ready to see if it has been stored
auto& not_ready = graph_task->not_ready_;
auto not_ready_it = not_ready.find(next.function.get());
if (not_ready_it == not_ready.end()) {
// The gradient of the next node has not been calculated
// Skip functions that aren't supposed to be executed
// Skip nodes that do not need calculation
if (!exec_info_.empty()) {
auto it = exec_info_.find(next.function.get());
if (it == exec_info_.end() || !it->second.should_execute()) {
continue;
}
}
// No buffers have been allocated for the function
InputBuffer input_buffer(next.function->num_inputs()); // The buffer of the pre gradient of the next node is the input gradient of the next node
// Accumulates into buffer
// The input gradient of the next node is the output of the current node, so copy it
const auto opt_next_stream = next.function->stream(c10::DeviceType::CUDA);
input_buffer.add(next.input_nr,
std::move(output),
opt_parent_stream,
opt_next_stream);
if (is_ready) {
auto queue = ready_queue(cpu_ready_queue, input_buffer.device());
// Now that the dependency is complete, it is inserted into ReadyQueue
queue->push(
NodeTask(graph_task, next.function, std::move(input_buffer)));
} else {
// If the input dependency of the next node has not been completed, put it in not_ready.
not_ready.emplace(next.function.get(), std::move(input_buffer));
}
} else {
// If the calculation of the next node has been started but not completed (that is, it depends on the gradient), it should be in not at this time_ In ready
// The function already has a buffer
auto &input_buffer = not_ready_it->second;
// Accumulates into buffer
const auto opt_next_stream = next.function->stream(c10::DeviceType::CUDA);
input_buffer.add(next.input_nr,
std::move(output),
opt_parent_stream,
opt_next_stream);
// The output of each node (fn) in the Graph is the input of the next node (fn). The following four sentences of code are used to convert the output of the previous fn into the input of the next fn
if (is_ready) {
// If there are no input dependencies at this time, put in a new NodeTask, which is the next NodeTask to calculate the gradient
auto queue = ready_queue(cpu_ready_queue, input_buffer.device());
queue->push(
NodeTask(graph_task, next.function, std::move(input_buffer)));
//The pre gradient calculation of the next node has been completed from not_ Remove the corresponding buffer from ready
not_ready.erase(not_ready_it);
}
}
}
}
Because this part of the code is very complex, we analyze it one by one.
0x03 preparation
First, let's look at the preparations, as follows:
- Get the ExecInfo of the current Node.
- Take out its captures_, Traverse each of them.
- Traverse the hooks of Capture and chain call hook for calculation.
- captured_grad keeps flowing in the pipeline as input and output_ vars_ [capture. Output_idx_] calculated successively.
- The final results are saved in captured_ vars_ [capture. Output IDX].
One detail in the code is captured_grad is only temporary storage. It will be updated every node calculation and finally output to the caller, which is equivalent to a reference.
void Engine::evaluate_function(
std::shared_ptr<GraphTask>& graph_task,
Node* func, // Derivative calculation method
InputBuffer& inputs, // Input gradient of current Node
const std::shared_ptr<ReadyQueue>& cpu_ready_queue) {
// Make preparations
// If exec_info_ is not empty, we have to instrument the execution
auto& exec_info_ = graph_task->exec_info_;
if (!exec_info_.empty()) {
auto& fn_info = exec_info_.at(func); // Take out the current for processing
if (auto* capture_vec = fn_info.captures_.get()) {
// Lock mutex for writing to graph_task->captured_vars_.
std::lock_guard<std::mutex> lock(graph_task->mutex_);
for (const auto& capture : *capture_vec) {
// captured_grad is a temporary storage. Every node calculation will be updated and finally output to the caller, which is equivalent to a reference
// 1. captured_grad refers to captured_vars_[capture.output_idx_],
auto& captured_grad = graph_task->captured_vars_[capture.output_idx_];
// 2. To captured_vars_[capture.output_idx_] assignment inputs[capture.input_idx_]
captured_grad = inputs[capture.input_idx_];
// Traverse hooks, chain call hook for calculation, captured_grad keeps flowing in the pipeline as input and output
// It's for captured_vars_[capture.output_idx_] after continuous calculation, the final result is captured_ vars_ [capture. Output IDX].
for (auto& hook : capture.hooks_) {
captured_grad = (*hook)(captured_grad);
}
}
}
if (!fn_info.needed_) {
// Skip execution if we don't need to execute the function.
return;
}
}
0x04 core logic
call_function is the core logic related to computation in back propagation.
- Call pre registered on this node_ hooks;
- Call node itself, such as MeanBackward0, MulBackward0, etc.
- The input is InputBuffer::variables(std::move(inputBuffer)), a set of instances of variables. When the dynamic graph begins to perform reverse calculation, the engine first executes the root node of the graph - graph_root, whose input is task.inputs -- InputBuffer(0).
- apply() of fn is called. apply is a polymorphic implementation. For different operations, it will be dispatch ed to the application implementation corresponding to the operation.
- The output is also an instance of a group of variables. outputs = fn(std::move(inputs_copy)), and outputs should be used as the input of the next fn.
- Call post hooks registered on node.
- Returns the derivative corresponding to the current node, which is a variable_list.
The specific codes are as follows:
static variable_list call_function(
std::shared_ptr<GraphTask>& graph_task,
Node* func,
InputBuffer& inputBuffer) {
CheckpointValidGuard cpvguard(graph_task);
auto& fn = *func;
auto inputs =
call_pre_hooks(fn, InputBuffer::variables(std::move(inputBuffer)));
if (!graph_task->keep_graph_) {
fn.will_release_variables();
}
const auto has_post_hooks = !fn.post_hooks().empty();
variable_list outputs;
if (has_post_hooks) {
// In functions/accumulate_grad.cpp, there is some logic to check the
// conditions under which the incoming gradient can be stolen directly
// (which elides a deep copy) instead of cloned. One of these conditions
// is that the incoming gradient's refcount must be 1 (nothing else is
// referencing the same data). Stashing inputs_copy here bumps the
// refcount, so if post hooks are employed, it's actually still ok for
// accumulate_grad.cpp to steal the gradient if the refcount is 2.
//
// "new_grad.use_count() <= 1 + !post_hooks().empty()" in
// accumulate_grad.cpp accounts for this, but also creates a silent
// dependency between engine.cpp (ie, this particular engine
// implementation) and accumulate_grad.cpp.
//
// If you change the logic here, make sure it's compatible with
// accumulate_grad.cpp.
auto inputs_copy = inputs;
outputs = fn(std::move(inputs_copy));
} else {
outputs = fn(std::move(inputs));
}
validate_outputs(fn.next_edges(), outputs, [&](const std::string& msg) {
std::ostringstream ss;
return ss.str();
});
if(has_post_hooks){
return call_post_hooks(fn, std::move(outputs), inputs);
}
return outputs;
}
0x05 prepare for the next step
This part is the complexity of back propagation.
Call now_ Function, the backward propagation output is obtained and recorded in outputs.
auto outputs = call_function(graph_task, func, inputs);
Therefore, the second half is to find the nodes that can be calculated later from the outputs.
The general idea is to traverse the backward propagating output node (that is, the node connected by the input edge of the node in the forward calculation graph) and measure the output nodes one by one. The traversal loop is divided into two sections of code. For each output node, do the following:
- The first paragraph is to check the node based on dependency to get whether the node is ready. The core is to see whether the count of dependencies of this output node in GraphTask drops to 0.
- If it is 0, it means that the node is ready, which means that the node will not be dependent on future calculations.
- If it is not 0, it means that this node has multiple inputs, that is, it is connected by multiple nodes, and some inputs have not calculated the gradient.
- The second segment deals with the node according to whether it is ready, such as which queue to put in.
5.1 troubleshooting nodes by dependency
The function of the first code section is to check the node according to the dependency relationship to get whether the node is ready, as follows:
-
Assuming that a node is output, we get the corresponding edge and traverse the output edge.
-
Record one output edge as next each time. func is a function in NodeTask.
-
Leverage dependencies_ Whether next can be calculated. dependencies_ The dependencies of all nodes in the graph are recorded.
-
From dependencies_ Find the number of dependencies corresponding to next and reduce the number of dependencies by one (usually because there are multiple input s).
- If -- it - > second = = 0, it means that other node gradients that the front node depends on have been calculated. be
- Remove the information corresponding to the front node from GraphTask, that is, from GraphTask's dependencies (and then from GraphTask's not_ready member variable).
- Will be_ Set "ready" to "true" and follow-up will be based on this is_ Operate on the value of ready.
- If -- it - > second = = 0, it means that other node gradients that the front node depends on have been calculated. be
-
From not_ready_ Get the input buffer corresponding to the next (the subsequent code is to operate on this);
-
std::unordered_map<Node*, InputBuffer> not_ready_;
-
The code is as follows:
-
for (int i = 0; i < num_outputs; ++i) { // Traverse the output nodes and measure them one by one
auto& output = outputs[i];
const auto& next = fn.next_edge(i); // Get an output node
if (!next.is_valid()) continue;
// Check if the next function is ready to be computed
bool is_ready = false;
auto& dependencies = graph_task->dependencies_; // Get the dependencies of GraphTask
auto it = dependencies.find(next.function.get()); // Found dependencies for output node
if (it == dependencies.end()) {
auto name = next.function->name(); // Can't find
throw std::runtime_error(std::string("dependency not found for ") + name);
} else if (--it->second == 0) {
dependencies.erase(it); // Found and calculated
is_ready = true;
}
auto& not_ready = graph_task->not_ready_;
auto not_ready_it = not_ready.find(next.function.get()); // Find input buffer
Now you have found an output node and know whether it has been calculated (based on whether there are dependencies) and get its input buffer with "not ready queue" (if any).
5.2 processing this node
The second paragraph is to process the node according to whether it is ready. For example, which queue is put in? Is it a ready queue? Or not ready queue? The core is:
- If it is ready, it will be placed in the ReadyQueue corresponding to the node for processing.
- If it is not ready, create a new NodeTask and put it in the not of GraphTask_ Ready to wait for subsequent processing. Note that this new NodeTask is created in the worker thread.
- How do I find ReadyQueue? You need to see the input of this Node_ Buffer. Device (), that is, the new NodeTask should be sent to input_buffer.device() the ReadyQueue corresponding to that device.
Let's look at how to use is_ Use the value of ready for not_ready.
- If not in the ready queue, not_ Next not found in ready_ The element corresponding to edge, then:
- If exec_info_ If it is not empty, it is in exec_info_ Find next in_ For the element corresponding to edge, if there is an element and it is indicated that it does not need to be executed, skip to the next for loop.
- Use next_ Stream of edge, inut_nr and other information to build an input_buffer.
- If is_ If ready is True, use this GraphTask, next.function, input_ Buffer builds a NodeTask and puts it into ReadyQueue (use input_buffer.device() to get the corresponding queue). This will wake up the next worker thread.
- If is_ready is False, which usually indicates that the node has multiple inputs (connected by more nodes, and the number can be obtained by using num_inputs()), and it also indicates that the first input of the node is processed this time, and the next is needed later_ Edge, so this next_edge needs to be put into not_ready. next.function, input_ Put buffer into not_ In ready, this input_buffer is next_ Various inputs required for subsequent execution of edge.
- If not in the ready queue, not_ Next found in ready_ The element corresponding to edge, then:
- Take out the input corresponding to the element_ Buffer to accumulate information to input_ In the buffer. Other inputs of this node are accumulated this time. input_buffer.add(next.input_nr, std::move(output), opt_parent_stream, opt_next_stream) completes the accumulation operation, next.input_nr indicates that the current node is the first input of the node (next) to flow in the back propagation.
- If is_ If ready is True, use this GraphTask, next.function, input_buffer builds a NodeTask and puts it into ReadyQueue. This will wake up the next worker thread.
- From not_ To remove this element from ready is to remove it from the dependencies of GraphTask.
The code is as follows:
if (not_ready_it == not_ready.end()) {
// Skip functions that aren't supposed to be executed
if (!exec_info_.empty()) {
auto it = exec_info_.find(next.function.get());
if (it == exec_info_.end() || !it->second.should_execute()) {
continue;
}
}
// No buffers have been allocated for the function
InputBuffer input_buffer(next.function->num_inputs());
// Accumulates into buffer
const auto opt_next_stream = next.function->stream(c10::DeviceType::CUDA);
input_buffer.add(next.input_nr,
std::move(output),
opt_parent_stream,
opt_next_stream);
if (is_ready) {
// The queue of the next Node is found
auto queue = ready_queue(cpu_ready_queue, input_buffer.device());
queue->push( //
NodeTask(graph_task, next.function, std::move(input_buffer)));
} else {
not_ready.emplace(next.function.get(), std::move(input_buffer));
}
} else {
// The function already has a buffer
auto &input_buffer = not_ready_it->second;
// Accumulates into buffer
const auto opt_next_stream = next.function->stream(c10::DeviceType::CUDA);
input_buffer.add(next.input_nr,
std::move(output),
opt_parent_stream,
opt_next_stream);
if (is_ready) {
// The queue of the next Node is found
auto queue = ready_queue(cpu_ready_queue, input_buffer.device());
queue->push(
NodeTask(graph_task, next.function, std::move(input_buffer)));
not_ready.erase(not_ready_it);
}
}
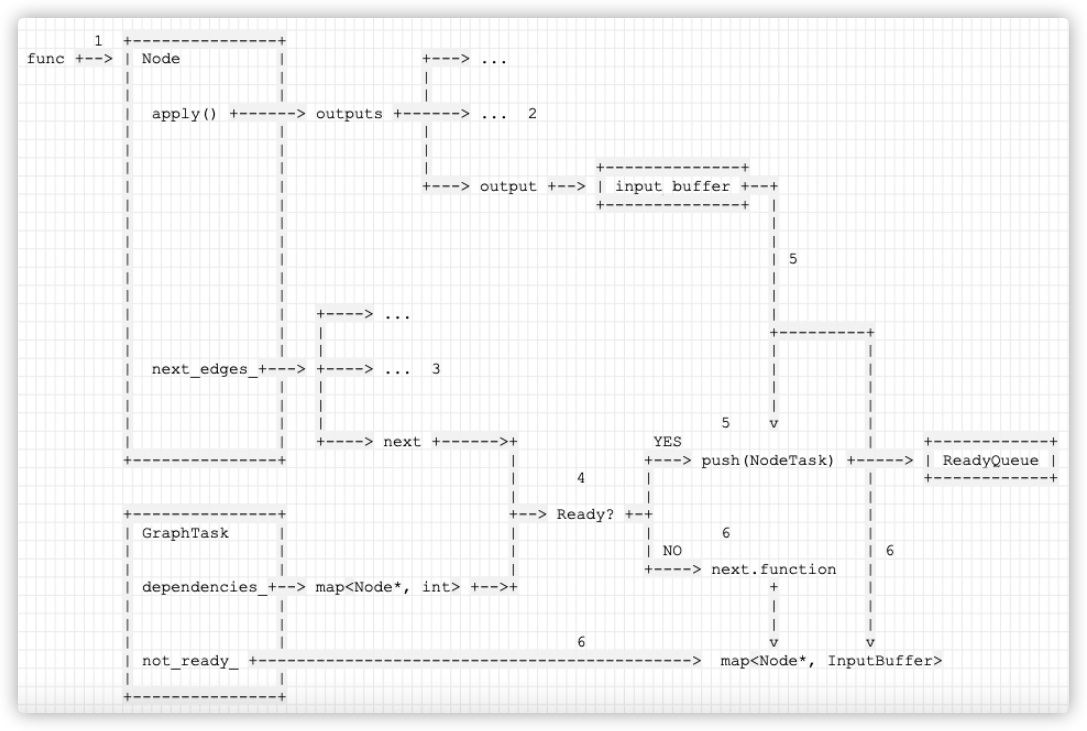
The specific logic diagram is as follows:
- func points to the Node currently undergoing reverse calculation.
- func calls its own apply method to calculate and get the outputs. Suppose there are three outputs, traverse, and we choose the third as output.
- The side of func is next_edges_ Member variable, traversal, we select the third edge as next.
- Use next and the dependencies of GraphTask_ To determine whether next is ready.
- If ready, build output into an input_buffer, and then generate a NodeTask and insert it into the corresponding readyquiet.
- If not, build output into an input_buffer, which is put into the not of GraphTask together with next_ ready_, It will be used later.
1 +---------------+
func +--> | Node | +---> ...
| | |
| | |
| apply() +------> outputs +------> ... 2
| | |
| | |
| | | +--------------+
| | +---> output +--> | input_buffer +--+
| | +--------------+ |
| | |
| | |
| | | 5
| | |
| | |
| | +----> ... |
| | | +---------+
| | | | |
| next_edges_+---> +----> ... 3 | |
| | | | |
| | | | |
| | | 5 v |
| | +----> next +------>+ YES | +------------+
+---------------+ | +---> push(NodeTask) +-----> | ReadyQueue |
| 4 | | +------------+
| | |
+---------------+ +--> Ready? +-+ |
| GraphTask | | | 6 |
| | | | NO | 6
| | | +----> next.function |
| dependencies_+--> map<Node*, int> +-->+ + |
| | | |
| | | |
| | 6 v v
| not_ready_ +---------------------------------------------> map<Node*, InputBuffer>
| |
+---------------+
Mobile phones are as follows:
0x06 ending operation
In thread_ In main, if this task has ended, follow-up operations will be performed. The specific code is as follows.
auto Engine::thread_main(const std::shared_ptr<GraphTask>& graph_task) -> void {
// Ignore previous code
// Check if we've completed execution.
if (local_graph_task->completed()) { // Determine whether to end
// If it is over, follow up
local_graph_task->mark_as_completed_and_run_post_processing();
auto base_owner = local_graph_task->owner_;
// The current worker thread finish the graph_task, but the owning thread
// of the graph_task might be sleeping on pop() if it does not have work.
// So we need to send a dummy function task to the owning thread just to
// ensure that it's not sleeping, so that we can exit the thread_main.
// If it has work, it might see that graph_task->outstanding_tasks_ == 0
// before it gets to the task, but it's a no-op anyway.
//
// NB: This is not necessary if the current thread is the owning thread.
if (worker_device != base_owner) {
// Synchronize outstanding_tasks_ with queue mutex
std::atomic_thread_fence(std::memory_order_release);
ready_queue_by_index(local_graph_task->cpu_ready_queue_, base_owner)
->push(NodeTask(local_graph_task, nullptr, InputBuffer(0)));
}
}
We then analyze these outstanding work. Note that this is thread_ Finishing work in main.
6.1 end of judgment
The following code is used to judge whether the GraphTask is finished. In fact, it is whether there are nodetasks to be run in ReadyQueue.
outstanding_tasks_ Is the number of nodetasks to be processed. It is used to judge whether the GrapTask needs to be executed. Its value is always increased and then decreased. If the number is 0, the task is finished.
- When the GraphTask is created, this value is 0.
- If a NodeTask is sent to the ReadyQueue, it is out of standing_ tasks_ Add 1.
- If you execute evaluate once in the worker thread_ After function (task), standing_ Subtract 1 from the value of tasks.
- If the number is not 0, the GraphTask still needs to be run.
bool GraphTask::completed() {
// outstanding_tasks in evaluate_function may be changed
return outstanding_tasks_.load() == 0 ||
(exit_on_error_ && has_error_.load());
}
6.2 follow up & notice
mark_as_completed_and_run_post_processing is the subsequent processing.
Perform subsequent operations exec_post_processing, and then use future_ result_-> Markcompleted notifies the main thread.
void GraphTask::mark_as_completed_and_run_post_processing() {
// Allow only one thread one attempt to process this logic.
if (future_completed_.exchange(true)) {
// Future is already marked complete, or being marked as such.
// In case the marking complete is only in progress, we add a
// wait() to guarantee the future is marked complete on exit.
future_result_->wait();
return;
}
try {
// Run post processing, before marking the future as complete.
// Drop lock prior to completing, to avoid holding across callbacks.
std::unique_lock<std::mutex> lock(mutex_);
exec_post_processing(); // Follow up
std::vector<Variable> vars = std::move(captured_vars_);
// Need to unlock before we call markCompleted to avoid holding locks
// when the callbacks are called.
lock.unlock();
future_result_->markCompleted(std::move(vars)); // Notify main thread
} catch (std::exception& e) {
future_result_->setErrorIfNeeded(std::current_exception());
}
}
6.2.1 subsequent operation
For subsequent operations, if a callback has been registered before, it will be called. Stream synchronization is also performed.
void GraphTask::exec_post_processing() {
if (!not_ready_.empty()) {
throw std::runtime_error("could not compute gradients for some functions");
}
// set the thread_local current_graph_task_ as more callbacks can be installed
// by existing final callbacks.
GraphTaskGuard guard(shared_from_this());
// Lock mutex during each iteration for accessing final_callbacks.size()
// Unlocking is necessary, because the callback can register
// more callbacks (or they can be registered from other threads
// while it's waiting.
std::unique_lock<std::mutex> cb_lock(final_callbacks_lock_);
// WARNING: Don't use a range-for loop here because more callbacks may be
// added in between callback calls, so iterators may become invalidated.
for (size_t i = 0; i < final_callbacks_.size(); ++i) {
cb_lock.unlock();
final_callbacks_[i]();
cb_lock.lock();
}
// Syncs leaf streams with default streams (if necessary)
// See note "Streaming backwards"
for (const auto& leaf_stream : leaf_streams) {
const auto guard = c10::impl::VirtualGuardImpl{c10::DeviceType::CUDA};
const auto default_stream = guard.getDefaultStream(leaf_stream.device());
if (leaf_stream != default_stream) {
auto event = c10::Event{c10::DeviceType::CUDA};
event.record(leaf_stream);
default_stream.wait(event);
}
}
}
6.2.2 notify the main thread
Previously, in execute, we used fut - > wait() to wait for the task to complete. We have omitted some of the code below.
auto Engine::execute(const edge_list& roots,
const variable_list& inputs,
bool keep_graph,
bool create_graph,
bool accumulate_grad,
const edge_list& outputs) -> variable_list {
// Queue the root
if (skip_dummy_node) {
execute_with_graph_task(graph_task, graph_root, std::move(input_buffer));
} else {
execute_with_graph_task(graph_task, graph_root, InputBuffer(variable_list()));
}
auto& fut = graph_task->future_result_;
fut->wait();
return fut->value().toTensorVector();
}
In mark_as_completed_and_run_post_processing notifies the main thread with the following code.
future_result_->markCompleted(std::move(vars)); // Notify main thread
6.3 notify other threads
If this task comes from other work thread s, i.e. workers_ device != base_ Owner, send a dummy function task to the queue of the worker thread to let the worker thread execute.
local_graph_task represents the graph we retrieved from the queue_ task. External graph_ The task represents the overall graph of reentrant execution that we need to perform_ Mission.
In thread_ In main, there is a work around. That is: the current worker thread completes the graph_task, but at this time, you have a graph_ The thread of task may be waiting for hibernation on pop(). Therefore, we need to send a fake function task to the thread to wake it up, so that we can exit the thread_main.
This occurs in the case of reentrant back propagation.
// If worker_device is any devices (i.e. CPU, CUDA): this is a re-entrant // backward call from that device. graph_task->owner_ = worker_device;
The specific codes are as follows:
// Check if we've completed execution.
if (local_graph_task->completed()) {
local_graph_task->mark_as_completed_and_run_post_processing();
auto base_owner = local_graph_task->owner_; // Current equipment
if (worker_device != base_owner) {
// Not the same device
// Synchronize outstanding_tasks_ with queue mutex
std::atomic_thread_fence(std::memory_order_release);
ready_queue_by_index(local_graph_task->cpu_ready_queue_, base_owner)
->push(NodeTask(local_graph_task, nullptr, InputBuffer(0))); // dummy task
}
}
After receiving the dummy task, other threads will not process it, because function is nullptr, and then call local_ ready_ Queue - > pop () continues to read the next task from its own queue.
The details are as follows:
- The main thread waits.
- If the worker thread finds that the GraphTask has ended, it notifies the main thread.
- If you need to wake up other threads, insert NodeTask into the queue corresponding to the thread.
- The corresponding thread takes out NodeTask for execution.
+------------------------------------------------+
| Worker Thread 1 |
| |
| thread_main{ |
| |
| mark_as_completed_and_run_post_processing |
2 markCompleted() | { |
+-------------------+ |
| | } |
| | |
+---------------+ | | push(NodeTask) +-----+ |
| Main Thread | | | | |
| | | | } | |
| | | | | |
| | | +------------------------------------------------+
| | | |
| | | 3 |
| | v v
| | +-------+-------+
| | 1 +----------------+ | |
| | wait() | | | ReadyQueue |
| +------------> | future_result_ | | |
| | | | +-------+-------+
| | +----------------+ |
| | |
| | 4 | pop(NodeTask)
| | |
| | v
| | +--------+---------------------+
| | | Worker Thread 2 |
| | | |
| | | |
+---------------+ | |
| |
| |
+------------------------------+
So far, the analysis of backward propagation has been completed. Starting from the next article, we officially enter PyTorch distributed training.
0xFF reference
https://www.zhihu.com/column/gemfield
[PyTorch] talk about the code behind backward
pytorch notes (calculation diagram + autograd)-Node(1)
Explain the network structure in pytoch in detail
Dynamic diagram of PyTorch (Part 2)
Dynamic diagram of PyTorch (Part 1)
PyTorch Internals 5: implementation of Autograd
A GENTLE INTRODUCTION TO TORCH.AUTOGRAD
PyTorch learning notes (12) -- Introduction to Autograd mechanism in PyTorch