Inheritance in js
(1) Prototype chain inheritance
-
Principle: point to an instance of a class by modifying the prototype pointer of the constructor
-
Insufficient: cannot pass arguments to the parent constructor, reference type properties in the parent class are shared
function SuperType() { this.property = true; } SuperType.prototype.getSuperValue = function () { return this.property; }; function SubType() { this.subproperty = false; } // Inherit SuperType SubType.prototype = new SuperType(); // The prototype becomes an instance of SuperType // This is equivalent to adding a method to the SuperType instance SubType.prototype.getSubValue = function () { return this.subproperty; } let instance = new SubType(); console.log(instance);
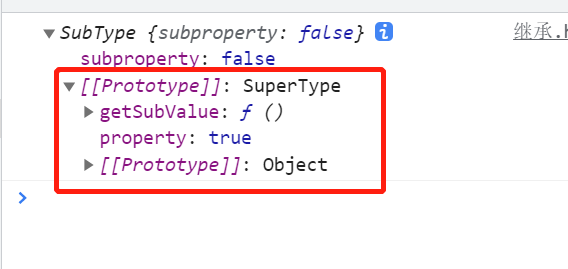
Analysis: the prototype of the subType points to the superType instance
(2) Stealing constructor inheritance
- Principle: by calling the constructor of the target class in a constructor of a class and passing this as the this of the current class.
- Features: you can pass parameters to the constructor of the target class, and the properties of the parent class will not be shared, but you cannot access the prototype of the target class. You can only obtain the properties defined in the constructor of the target class and save them to the instance of the current class
// Embezzle constructor
function SuperType(name) {
this.name = name;
this.sayName = function(){
console.log(name);
}
}
// Prototype
SuperType.prototype.foo = function(){
console.log('foo');
}
function SubType() {
// Inherit SuperType and pass parameters
SuperType.call(this, "Nicholas");
// The properties and methods on the SuperType instance will be copied to this instance, but those on the prototype will not
// Instance properties
this.age = 29;
}
let instance = new SubType();
console.log(instance);
console.log(instance.name); // "Nicholas";
console.log(instance.age); // 29
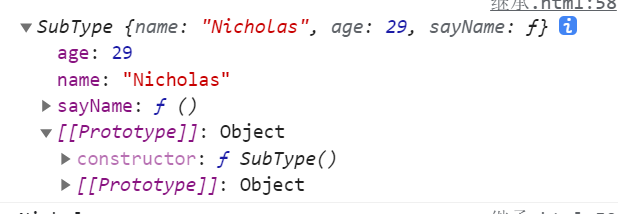
Analysis: subType embezzles the constructor of superType, copies the attributes of the object itself and saves them in its own instance, while the foo of superType prototype is not "embezzled" (copied)
(3) Prototype embezzlement combined inheritance
-
Principle: combined with the use of 1 and 2
-
Features: you can pass parameters and access the prototype of the parent class, but the parent class will create two instances
function SuperType(name) { this.name = name; this.colors = ["red", "blue", "green"]; } SuperType.prototype.sayName = function () { console.log(this.name); }; function SubType(name, age) { SuperType.call(this, name); // The second call to SuperType() this.age = age; } SubType.prototype = new SuperType(); // SuperType() called for the first time SubType.prototype.constructor = SubType;// There is no such attribute if you do not write SubType.prototype.sayAge = function () { console.log(this.age); }; let instance = new SubType('abc',29); console.log(instance);

Analysis: stealing constructors can pass parameters when creating prototype instances. However, in order to make up for the inability to steal prototype properties and methods, it is also applicable to the method of creating superType instances and setting prototype. Although now it makes up for the above shortcomings, it will create more properties of the prototype itself and waste memory space.
(4) Prototype inheritance
- Principle: still use the prototype for inheritance, just encapsulate the process into a function and return a user-defined object
- Features: same as prototype chain inheritance
function subType(superObj) {
function F() { }
F.prototype = superObj;
return new F();
}
function superType(name, friends) {
this.name= name,
this.friends= friends
};
let subInstance = subType(superType("Nicholas",["Shelby", "Court", "Van"])); // Prototype parameter instantiation
subInstance.age = 18; // Target object, adding attributes manually
console.log(subInstance);
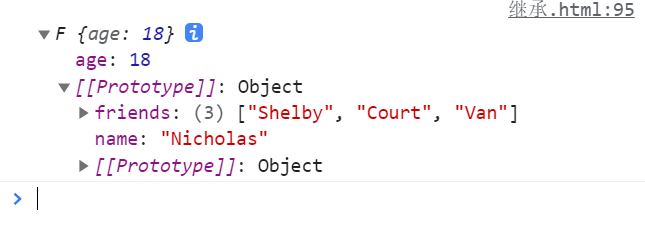
Analysis: compared with method 1, the advantage is that you can pass in a definition instance as a prototype (the prototype can be instantiated by passing parameters), but you can't have both fish and bear's paw. Now the target object can't pass parameters to create an instance at one time, but you can only add an instance manually.
(5) Parasitic inheritance
- Principle: on the basis of prototype, add new attributes and methods for user-defined objects in functions
- Features: same as prototype chain inheritance
function subType(superObj) {
function F() { }
F.prototype = superObj;
return new F();
}
function superType(name, friends) {
this.name= name,
this.friends= friends
};
// The properties and methods of the prototype and instance are passed in
function createSubType(superObj, {age, sayHi}){
let sub = subType(superObj);
sub.age = age;
sub.sayHi = sayHi;
return sub;
}
let subInstance = createSubType(new superType("Nicholas",["Shelby", "Court", "Van"]), {age:18, sayHi(){
console.log('hi, I am ' + this.age + " years old.");
}});
subInstance.sayHi();
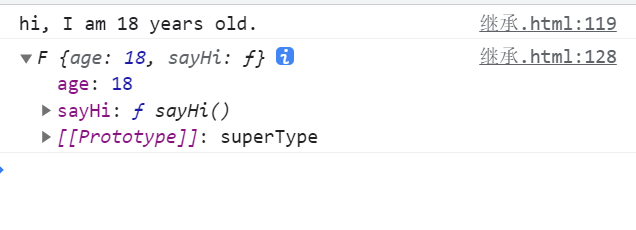
Analysis: in fact, on the basis of method 4, it encapsulates another layer, changing the original manual writing method after creating an instance into passing an object parameter to the createSubType factory function to create it. Instead, it becomes more and more complicated
(6) Parasitic combinatorial inheritance
- Principle: it combines the principle of parasitic and embezzling constructor
- Features: before the class appears, the best inheritance method can pass parameters to the parent class constructor, access the prototype of the parent class, and create only one parent class instance
function object(o) {
function F() { }
F.prototype = o;
return new F();
}
// Return the three-layer prototype chain of subtype - > Object - > supertype.prototype
function inheritPrototype(subType, superType) {
//It is equivalent to creating a superType instance, but it is created indirectly. There are no attributes on the superType instance, but there are attributes on the prototype
let prototype = object(superType.prototype); // Create an object with the prototype of superType as the target instance prototype
prototype.constructor = subType; // Enhancement object,
subType.prototype = prototype; // Assign an object, and set the subtype prototype to the object returned by object()
}
function SuperType(name) {
this.name = name;
this.colors = ["red", "blue", "green"];
}
SuperType.prototype.sayName = function () {
console.log(this.name);
};
function SubType(name, age) {
SuperType.call(this, name); //Embezzle constructor
this.age = age;
}
inheritPrototype(SubType, SuperType);
SubType.prototype.sayAge = function () {
console.log(this.age);
};
let instance = new SubType('kobe', 29);

Analysis: this method combines ① stealing the constructor to copy the supertype attribute to the subtype, ② parasitic inheritance to create an intermediate instance of supertype.prototype, and ③ setting the intermediate instance to subtype.prototype to form a three-layer prototype chain of subtype - > Object - > supertype.prototype, This method is perfect, but it will be more complex.
(7) class keyword inheritance syntax
Class can inherit through the extends keyword, which is much clearer and more convenient than that of ES5 by modifying the prototype chain
class Point{
constructor(x,y){
this.x = x;
this.y = y;
}
toString(){
return `(${this.x}, ${this.y})`
}
}
class ColorPoint extends Point{
constructor(x,y,color){
super(x,y); // Call the parent class constructor
this.color = color;
}
toString(){
return this.color + ' ' + super.toString(); // Call the toString method of the parent class
}
}
const colorPoint = new ColorPoint(2,3,'red');
console.log(colorPoint);

Analysis: the class keyword is inherited by using the extends keyword. The super() method of the constructor of the subclass calls the constructor of the parent class and copies the attributes of the parent class to the subclass instance. This feature is the same as stealing the constructor call() method. When the methods of the parent class are the same as those of the subclass, you want to call the constructor of the parent class, You can use the super. Method name to call. Super refers to the prototype object of the parent class. See the inheritance method of the specific class Ruan Yifeng's class inheritance article of ES6